目录
指针的使用
strlen的模拟实现
传值调用和传址调用
数组名的理解
使用指针访问数组
一维数组传参的本质
冒泡排序
个人主页(找往期文章):我要学编程(ಥ_ಥ)-CSDN博客
指针的使用
strlen的模拟实现
库函数strlen的功能是求字符串长度,统计的是字符串中 \0 之前的字符的个数。
函数原型:

知道了上面这些,我们就直接开是写代码 。
#include <stdio.h>
int my_strlen(const char* p)
{
int count = 0;
while (*p != '\0')
{
count++;
p++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}如果要真正相同的话,这个函数的返回类型也应该改一改。
#include <stdio.h>
size_t my_strlen(const char* p)
{
size_t count = 0;
while (*p != '\0')
{
count++;
p++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
size_t len = my_strlen(arr);
printf("%zd\n", len);
return 0;
}
因为函数返回类型改了,那么那个返回的值(count)的类型也应该变,接收的,打印的都要变。
传值调用和传址调用
学习指针的目的是使用指针解决问题,那什么问题,非指针不可呢?
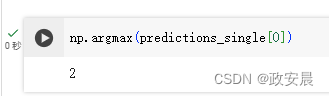
例如:写一个函数,交换两个整型变量的值
#include <stdio.h>
void swap(int a, int b)
{
int tmp = 0;
tmp = a;
a = b;
b = tmp;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d%d", &a, &b);
printf("交换前:a=%d,b=%d\n", a, b);
swap(a, b);
printf("交换后:a=%d,b=%d\n", a, b);
return 0;
}我们去运行这个代码会发现,交换前后a与b的值根本就没有发生变化。
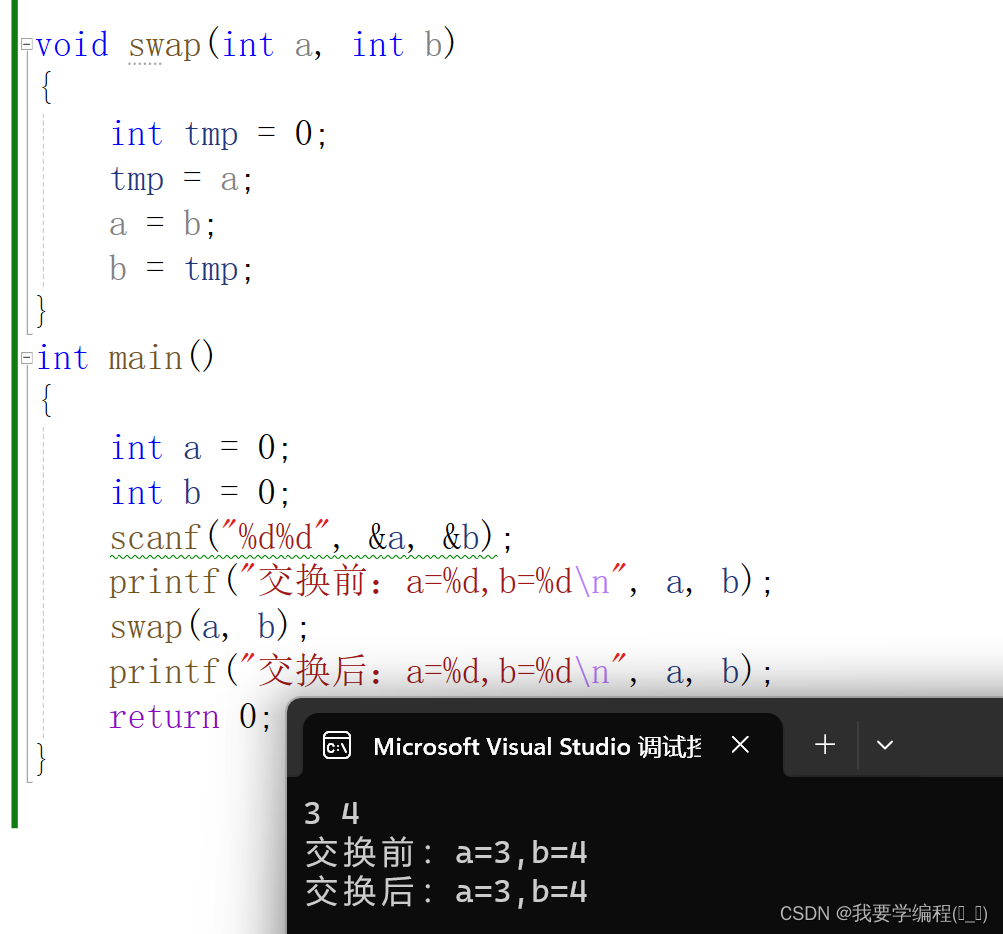
这到底是什么原因导致的呢?我们可以尝试调试一下(因为这里我形参和实参都是设置a和b,不好观察,我就把形参改成x和y了):
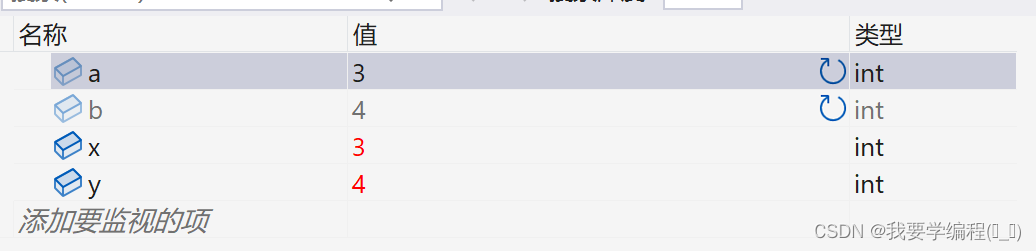

通过上面两幅图,我们可以看到x与y的值,虽然交换了,但是却没有影响到a与b。我们在通过指针来深入观察:
我们可以看到a,b与x,y的地址不是一样的,相当于x和y是独立的空间,那么在swap函数内部交换x和y的值, 自然不会影响a和b,当swap函数调用结束后回到main函数,a和b的没法交换。swap函数在使用的时候,是把变量本身直接传递给了函数,这种调用函数的方式我们之前在函数的时候就知道了,这种叫传值调用。
结论:实参传递给形参的时候,形参会单独创建一份临时空间来接收实参,对形参的修改不影响实 参。 所以swap函数是无效的。
通过前面指针的学习,我们知道可以通过指针来寻找到它所指向的对象,并且可以修改这个对象的值。在main函数中将a和b的地址传递给swap函数,swap 函数里边通过地址间接的操作main函数中的a和b,并达到交换的效果就好了。
#include <stdio.h>
void swap(int* x, int* y)
{
int tmp = 0;
tmp = *x;
*x = *y;
*y = tmp;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d%d", &a, &b);
printf("交换前:a=%d,b=%d\n", a, b);
swap(&a, &b);
printf("交换后:a=%d,b=%d\n", a, b);
return 0;
}
上面代码是将a与b的地址传给了函数swap,这种叫做传址调用。
传址调用,可以让函数和主调函数之间建立真正的联系,在函数内部可以修改主调函数中的变量;所以未来函数中只是需要主调函数中的变量值来实现计算,就可以采用传值调用。如果函数内部要修改主调函数中的变量的值,就需要传址调用。
数组名的理解
在使用指针访问数组的内容时,有这样的代码:

上面两种写法都是对的,用代码验证一下。
&arr[0]的写法:
#include <stdiio.h>
void Print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}
int main()
{
int arr[] = { 1,2,3,4,5 };
int sz = sizeof(arr) / sizeof(arr[0]);
Print(&arr[0], sz);
return 0;
}
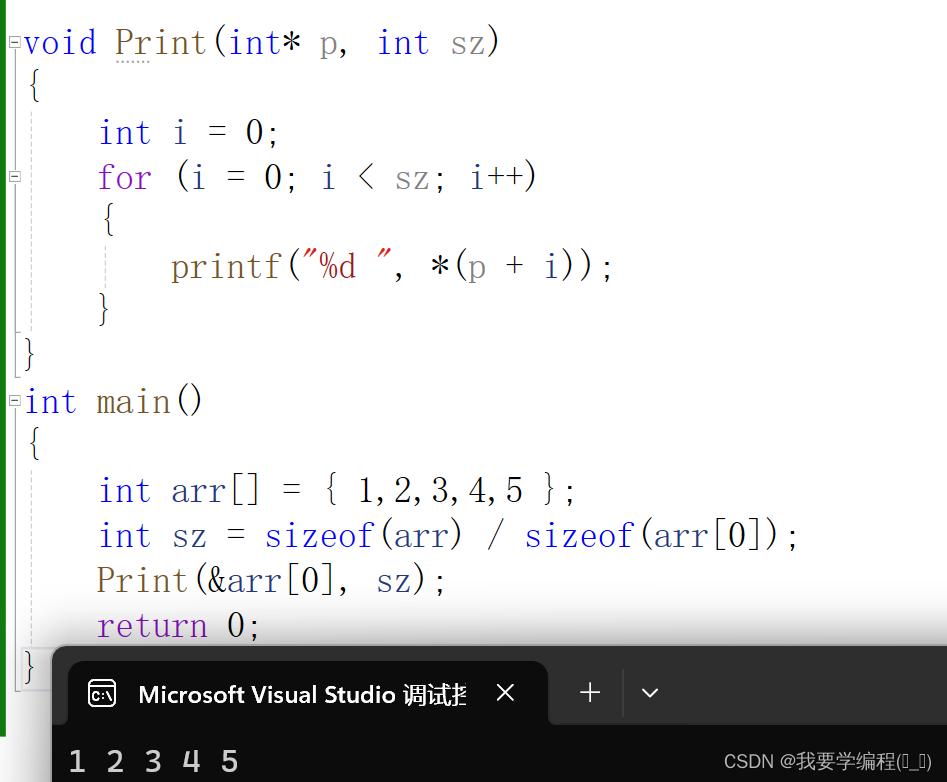
arr的写法:
#inlcude <stdio.h>
void Print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}
int main()
{
int arr[] = { 1,2,3,4,5 };
int sz = sizeof(arr) / sizeof(arr[0]);
Print(arr, sz);
return 0;
}
我们可以看到这两个代码的结果是一模一样的。就说明&arr[0]与arr是一样的。换句话说,数组名就是数组首元素的地址。但是有两种情况是例外:
• sizeof(数组名),sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小, 单位是字节
• &数组名,这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的) 除此之外,任何地方使用数组名,数组名都表示首元素的地址。

我们可以通过打印的结果知道: sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小。
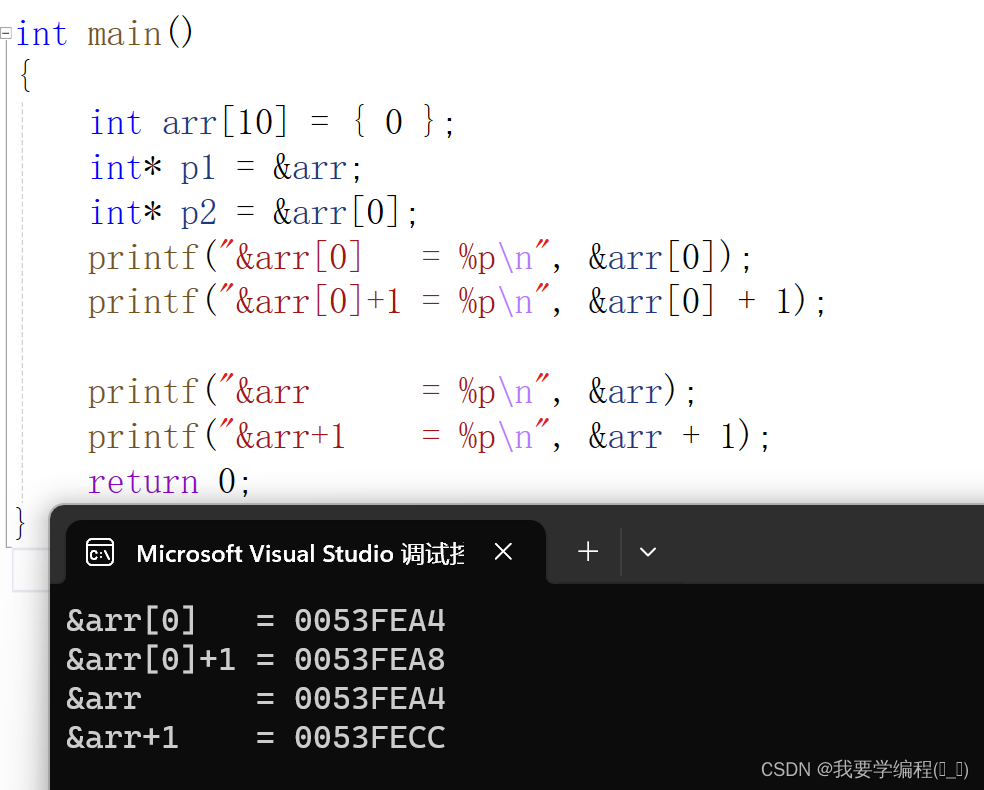
这些是十六进制,通过计算可以得知:&arr[0]和&arr[0]+1相差4个字节,是因为&arr[0] 都是首元素的地址,+1就是跳过一个元素。但是&arr 和 &arr+1相差40个字节,这就是因为&arr是数组的地址,+1 操作是跳过整个数组的。
但是在用代码证明时,有的小伙伴,可能会写成下面的代码,从而无法证明。

之所以会这样,是因为这个&arr,是指整个数组,而这个p1是一个指针变量,只能存放一个地址,不能将整个地址给存放。如果强行这样做,就导致整个p1,只是存了第一个元素的地址。达不到我们的预期。
使用指针访问数组
有了前面知识的支持,再结合数组的特点,我们就可以很方便的使用指针访问数组了。
练习:用指针实现数组的输入和输出。
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
int i = 0;
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
}
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}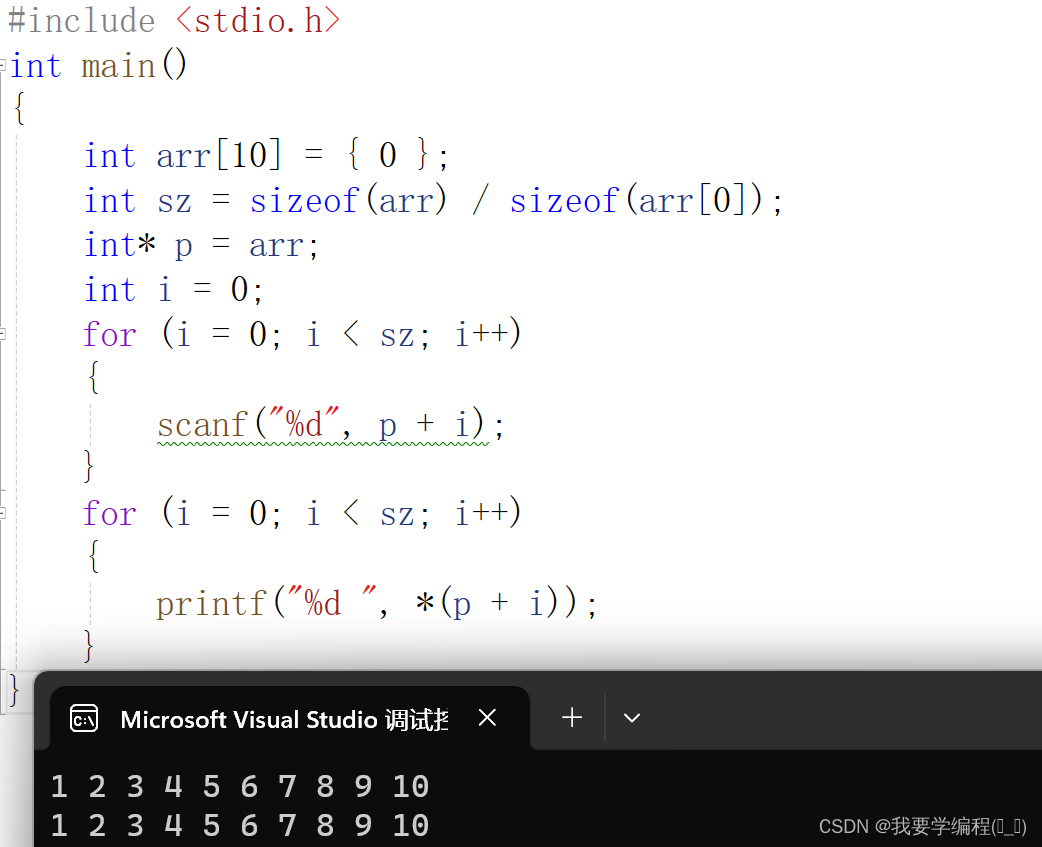
我们再分析一下,数组名arr是数组首元素的地址,可以赋值给p,其实数组名arr和p在这里是等价的。那我们可以使用arr[i]可以访问数组的元素,那p[i]是否也可以访问数组呢?
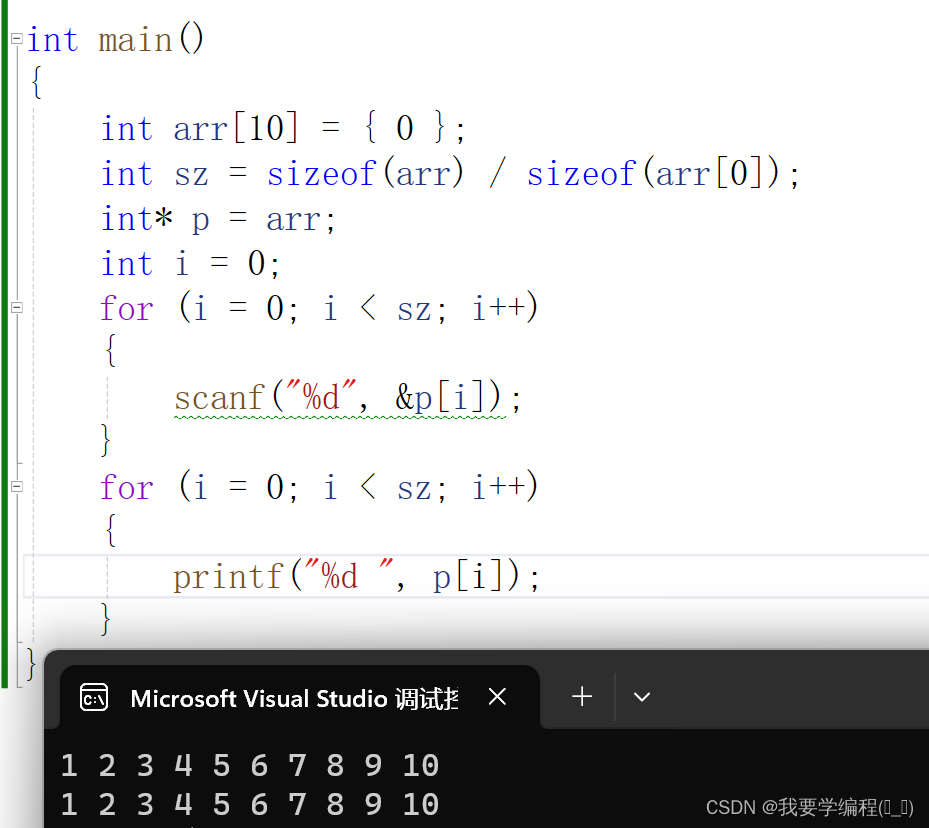
所以本质上p[i] 是等价于 *(p+i)。我们可以理解为[ ] == * 。
一维数组传参的本质
数组是可以传递给函数的,我们讨论一下数组传参的本质。 首先从一个问题开始,我们之前都是在函数外部计算数组的元素个数,那我们可以把数组传给一个函数后,函数内部求数组的元素个数吗?
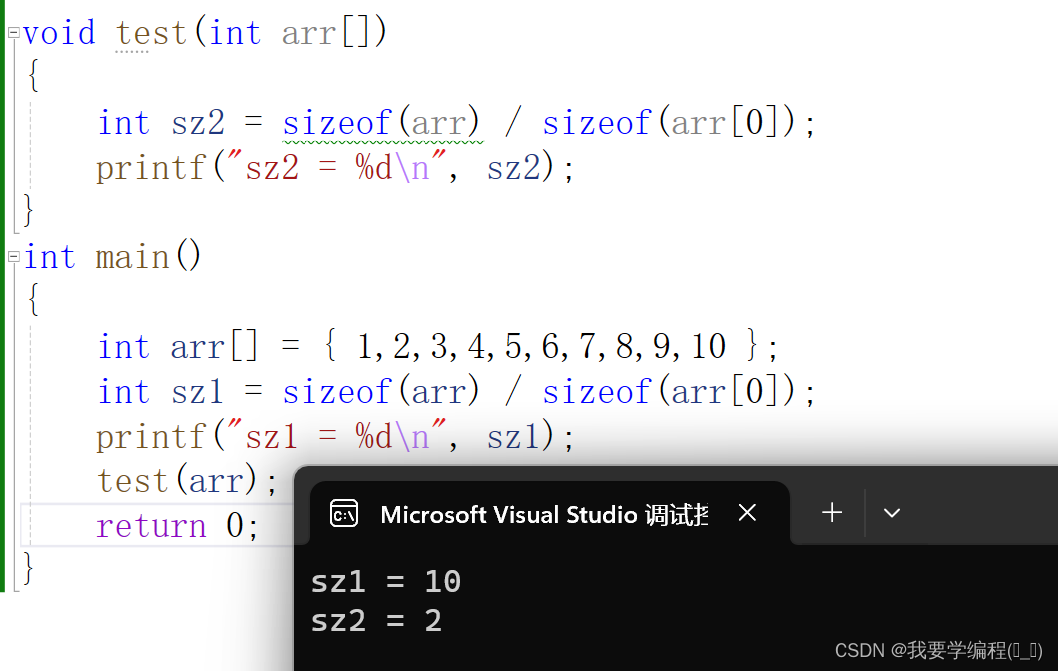
我们发现在函数内部是没有正确获得数组的元素个数。 这就要学习数组传参的本质了,上面验证了:数组名是数组首元素的地址;那么在数组传参的时候,传递的是数组名,也就是说本质上数组传参本质上传递的是数组首元素的地址。 所以函数形参的部分理论上应该使用指针变量来接收首元素的地址。那么在函数内部我们写 sizeof(arr) 计算的是一个指针的大小(单位字节)而不是数组的大小(单位字节)。正是因为函数的参数部分是本质是指针,所以在函数内部是没办法求的数组元素个数的。 而这个sz2的值是和32位平台还是64位有关。因为指针变量的大小在32位平台下是4个字节,64位是8个字节。
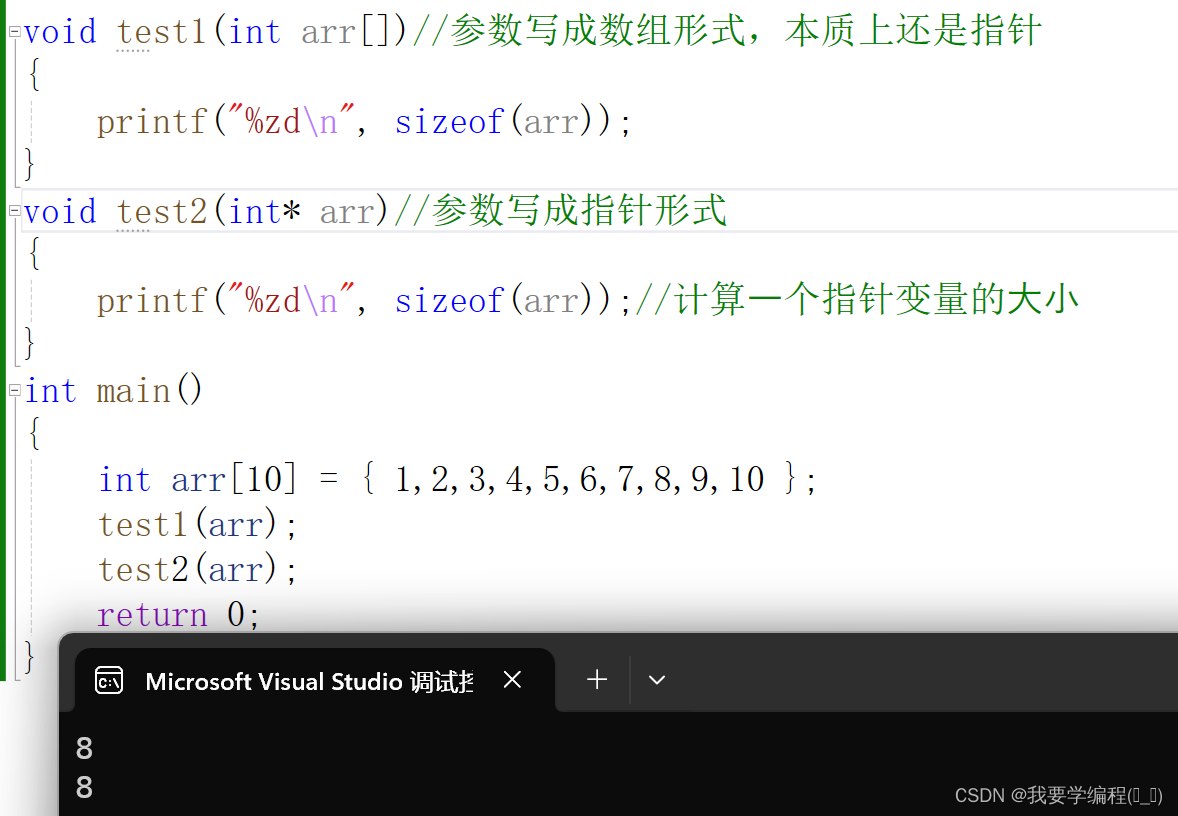
总结:一维数组传参,形参的部分可以写成数组的形式,也可以写成指针的形式。
冒泡排序
冒泡排序的核心思想就是:两两相邻的元素进行比较。
冒泡排序是一种算法,用来解决数组内部元素有序的问题。比如:有一个数组,内部元素杂乱无章,但是我们要的是一个降序的数组。这时就可以采用冒泡排序的方法。具体怎么实现呢?我就用画图的方式给大家展现出来。

到这里这个代码也就可以写出来了。
#include <stdio.h>
void bubble_sort(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)//趟数
{
int j = 0;
for (j = 0; j < sz - 1; j++)//每一趟
{
if (*(p + j) < *(p + j + 1))
{
int tmp = *(p + j);
*(p + j) = *(p + j + 1);
*(p + j + 1) = tmp;
}
}
}
}
void Print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
Init(arr, sz);
bubble_sort(arr, sz);//改成降序
Print(arr, sz);
return 0;
}但是如果我们再仔细分析的话,就会发现在每一趟的元素比较中,需要比较的元素个数是随着趟数的增加,变得越来越少。举例:第一趟要比较10个数,得出一个数是最小的之后,第二趟来比较时,就不需要和那个第一趟比较出的数再来比较了。因为第一趟比较出的数之所以最小,是因为它在这是个元素中是最小的,那么第二趟比较出的那个最小数,一定比那个第一趟比较出的那个数要大才行。以此类推,第二趟比较9个数就是j到7就可以了(j+1等于8,第九个数的下标是8),第三趟比较8个数就是j到6就可以了。那么最终的规律就是j<sz-1-i。
改进的代码:
#include <stdio.h>
void bubble_sort(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)//趟数
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)//每一趟
{
if (*(p + j) < *(p + j + 1))
{
int tmp = *(p + j);
*(p + j) = *(p + j + 1);
*(p + j + 1) = tmp;
}
}
}
}
void Print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
Init(arr, sz);
bubble_sort(arr, sz);//改成降序
Print(arr, sz);
return 0;
}其实到这里了,这个代码还能够优化一点:如果我们的数组里,就只有一个元素不是有序的,其余的都是有顺序的,因此我们只需要比较一次就可以了。
如果这个数组是9 8 7 6 5 4 3 2 1 10,这个想要变成降序,就需要走9趟了。因为第一趟就只能把1和10换位置。还剩下其它的数要换,就只能走9趟
那么怎么判断这个数组比较过后是有序还是无序呢?
法一:可以定义一个flag变量,初始化为1。如果这个有序了,啥也不干,那么就令它为0;否则就是1。每走完一趟之后就可以根据flag的值,判断是否有序。如果是0,就说明这个数组有序,跳出循环。
#include <stdio.h>
//void init(int* p, int sz)
//{
// int i = 0;
// for (i = 0; i < sz; i++)
// {
// scanf("%d", (p + i));
// }
//}
void bubble_sort(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)//趟数
{
int flag = 1;//注意这个定义的位置。
int j = 0;
for (j = 0; j < sz - 1 - i; j++)//每一趟
{
if (*(p + j) < *(p + j + 1))
{
int tmp = *(p + j);
*(p + j) = *(p + j + 1);
*(p + j + 1) = tmp;
flag = 0;//一旦进入就变为0。
}
}
if (flag == 1)//等于1,代表if一次也没有执行。
{
break;
}
}
}
void print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}
int main()
{
int arr[10] = { 9,10,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
//init(arr, sz);
bubble_sort(arr, sz);//改成降序
print(arr, sz);
return 0;
}法二:可以定义一个变量count,如果这个一趟里面每没有执行一次,count就++。一趟走完之后,如果count==sz-1-i,那么说明这个数组已经有序,就跳出循环。
#include <stdio.h>
//void Init(int* p, int sz)
//{
// int i = 0;
// for (i = 0; i < sz; i++)
// {
// scanf("%d", (p + i));
// }
//}
void bubble_sort(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)//趟数
{
int j = 0;
int count = 0;//注意这个定义的位置,如果定义在趟数的外面,这个count就会累加
for (j = 0; j < sz - 1 - i; j++)//每一趟
{
if (*(p + j) < *(p + j + 1))
{
int tmp = *(p + j);
*(p + j) = *(p + j + 1);
*(p + j + 1) = tmp;
}
else
{
count++;
}
}
if (count == sz - 1 - i)如果count等于这个,就说明if一次也没有执行
{
break;
}
}
}
void Print(int* p, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
}
int main()
{
int arr[10] = { 9,10,8,7,6,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
//Init(arr, sz);
bubble_sort(arr, sz);//改成降序
Print(arr, sz);
return 0;
}上面有些代码被注释,是为了更好的调试观察。当然大家可以把那些注释去掉。
上面两种优化可以通过调试来观察是否优化成功(VS的调试方法在我往期的文章里,可以去主页里找) 。
感觉四篇文章可能写不完指针的所有内容。





![[C++]继承(续)](https://img-blog.csdnimg.cn/direct/362d3f06ef344ae4be6a0042dead03a1.png)