目录
一.项目介绍
二.卷积神经网络构造
2.1.判断是否是channels first的back end
2.2.卷积层构造
2.3.添加激活函数
2.4.池化层构造
2.5.全连接FC层构造
三.完整代码
3.1.学习率衰减设置
四.首次运行结果
五.数据增强对结果的影响
六.BatchNormalization对结果的影响
七.加载模型进行测试
一.项目介绍
用Keras工具包搭建训练自己的一个卷积神经网络(Simple_VGGNet,简单版VGGNet),用来识别猫/狗/羊三种图片。
数据集:



二.卷积神经网络构造

查看API文档
Convolution layers (keras.io)![]() https://keras.io/api/layers/convolution_layers/
https://keras.io/api/layers/convolution_layers/
# 导入所需模块
from keras.models import Sequential
from keras.layers import BatchNormalization
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.initializers import TruncatedNormal
from keras.layers import Activation
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers import Dense
from keras import backend as K
class SimpleVGGNet:
@staticmethod
def build(width, height, depth, classes): # 长 宽 深度(特征图的个数)
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape, kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same", kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same", kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Dropout(0.25))
# (CONV => RELU) * 3 => POOL
model.add(Conv2D(128, (3, 3), padding="same", kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same", kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same", kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Dropout(0.25))
# FC层
model.add(Flatten())
model.add(Dense(256, kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization())
# model.add(Dropout(0.6))
# softmax 分类
model.add(Dense(classes, kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("softmax"))
return model
2.1.判断是否是channels first的back end
不同backend的颜色通道设置的位置可能不同,tensorflow的颜色通道在最后一个参数,有些backend的颜色通道则在第一个参数,所以需要进行一次判断。
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1如果判断为真,则重新设置参数的顺序。
2.2.卷积层构造
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape,kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Conv2D(64, (3, 3), padding="same",kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Conv2D(64, (3, 3), padding="same",kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Conv2D(128, (3, 3), padding="same",kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Conv2D(128, (3, 3), padding="same",kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Conv2D(128, (3, 3), padding="same",kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))拿第一层卷积层的构造为例:32是输出层的维度(即特征图个数,每个特征图大小为最开始设置height x weight)。(3,3)是卷积核的大小,即一次性读取3x3大小的特征值。padding是边界填充,padding=same表示有padding,且padding大小与步长相同,padding=valid则表示没有padding。最后再设置权重初始化方式为截断初始化。
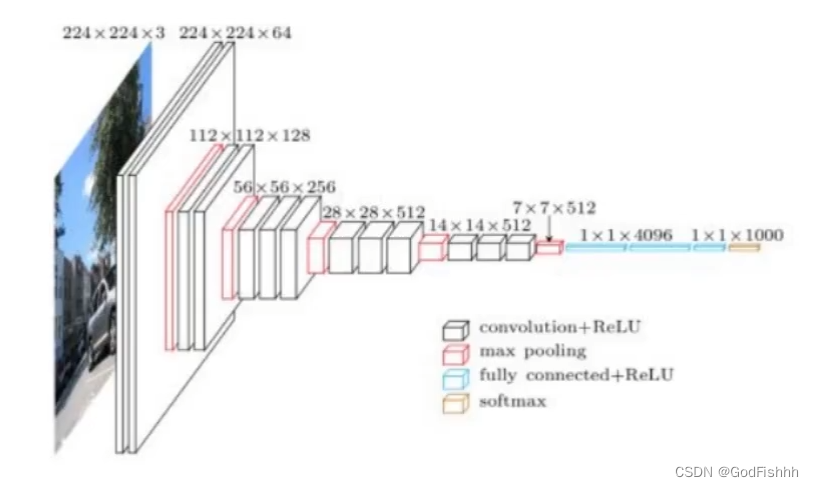
对于卷积神经网络,需要经过池化层对数据进行压缩,而在每次经过池化层压缩后,我们希望数据的特征图个数可以翻倍。(与传统神经网络的减少不同)
如上图所示:数据的特征图个数由32→64→128.(每个特征图都是height x weight x 1的大小)
2.3.添加激活函数
model.add(Activation("relu"))除去池化层因为只是对参数进行压缩而不进行计算,不需要添加激活函数,其他对参数进行计算了的层,例如卷积层和全连接层都需要添加一个激活函数。
2.4.池化层构造

model.add(MaxPooling2D(pool_size=(2, 2)))此处调用的池化层是MaxPooling,表示对每个2x2大小的区域进行池化,只取出其中最大的那个权重值。

2.5.全连接FC层构造
# FC层
model.add(Flatten())
model.add(Dense(512,kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("relu"))
# model.add(BatchNormalization())
# model.add(Dropout(0.6))
# softmax 分类
model.add(Dense(classes,kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)))
model.add(Activation("softmax"))经过卷积后,要通过矩阵相乘得到相应类别的概率值,所以需要将三维的图片数据拉长成一维的特征值矩阵。同时增加一层全连接层,特征值矩阵经过该全连接层剩下512个特征值。
最后再添加一层全连接层,得到的类别数量与最开始设置的classes相同,并通过softmax激活函数来分类。
三.完整代码
# 导入所需工具包
from CNN_net import Simple_VGGNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from my_utlis import utlis_paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
import keras
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 读取数据和标签
print("------开始读取数据------")
data = []
labels = []
# 拿到图像数据路径,方便后续读取
imagePaths = sorted(list(utlis_paths.list_images('./dataset')))
random.seed(42)
random.shuffle(imagePaths)
# 遍历读取数据
for imagePath in imagePaths:
# 读取图像数据
image = cv2.imread(imagePath)
image = cv2.resize(image, (64, 64)) # 将图片resize为相同尺寸
data.append(image)
# 读取标签
label = imagePath.split(os.path.sep)[-2] # 根据文件夹获取标签
labels.append(label)
# 对图像数据做scale操作
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# 数据集切分
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.25, random_state=42)
# 转换标签为one-hot encoding格式(三分类及以上需要,二分类不需要)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 数据增强处理
"""
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
"""
# 建立卷积神经网络
model = Simple_VGGNet.SimpleVGGNet.build(width=64, height=64, depth=3, classes=len(lb.classes_))
# 设置初始化超参数
INIT_LR = 0.01
EPOCHS = 30
BS = 32
# 损失函数,编译模型
print("------准备训练网络------")
lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=INIT_LR,
decay_steps=10,
decay_rate=0.98)
opt = SGD(lr=lr_schedule) # 一开始的权重参数较好,可以把学习参数设置的较大,后续权重参数变差,学习参数也设置较低
# one-hot编码用loss="CategoricalCrossentropy" 数组编码用loss="SparseCategoricalCrossentropy"
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
# 训练网络模型
"""
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
"""
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=EPOCHS, batch_size=32)
# 测试
print("------测试网络------")
predictions = model.predict(testX, batch_size=32)
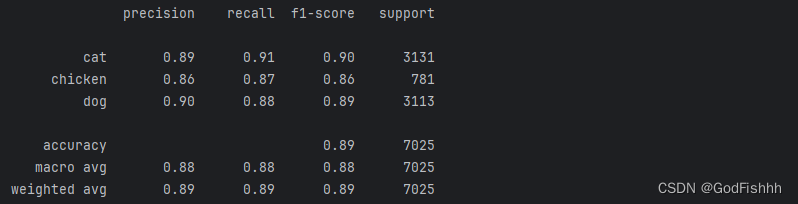
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
# 绘制结果曲线
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig('./output_cnn/cnn_plot.png')
# 保存模型
print("------正在保存模型------")
model.save('./output_cnn/cnn.model')
f = open('./output_cnn/cnn_lb.pickle', "wb")
f.write(pickle.dumps(lb))
f.close()3.1.学习率衰减设置

lr_schedule = keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=INIT_LR,
decay_steps=5,
decay_rate=0.9)
opt = SGD(lr=lr_schedule) # 一开始的权重参数较好,可以把学习参数设置的较大,后续权重参数变差,学习参数也设置较低decay_steps表示的是每几次迭代进行一次衰减,dacay_rate表示的是衰减的程度,上述代码中即为每五次迭代进行一次学习率的衰减,即 lr*0.9。
一开始的权重参数较好,可以把学习参数设置的较大,后续权重参数变差,学习参数也相应设置的较低。
四.首次运行结果
第一次运行结果如下:

发现数据异常,有两种类没有结果值,编译器warning:UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
出现上述warning的原因是有些样本是正确的,但是没有预测到。
博主认为出现这种warning的解决方法是修改数据集或者调整你的网络结构。
卷积神经网络的数据参数较少,所以当时有截断初始化、Dropout等操作时可能会导致结果出现异常。
此处博主删去了网络中卷积层和全连接层中的截断初始化,得到的结果:


五.数据增强对结果的影响
Data Augmentation ,基于有限的数据生成更多等价(同样有效)的数据,丰富训练数据的分布,使通过训练集得到的模型泛化能力更强。
# 数据增强处理
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
# 训练网络模型
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)加上数据增强的训练结果:


六.BatchNormalization对结果的影响
每次卷积层、全连接层后可以加上一个BatchNormalization层进行修正,使标准化。

BatchNormalization layer (keras.io)![]() https://keras.io/api/layers/normalization_layers/batch_normalization/
https://keras.io/api/layers/normalization_layers/batch_normalization/
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape, ))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))加上数据增强,BatchNormalization层的训练结果:


七.加载模型进行测试
编写一个predict.py程序来加载模型进行测试:
# 导入所需工具包
from keras.models import load_model
import argparse
import pickle
import cv2
# 加载测试数据并进行相同预处理操作
image = cv2.imread('./cs_image/dog.jpeg')
output = image.copy()
image = cv2.resize(image, (64, 64))
# scale图像数据
image = image.astype("float") / 255.0
# 对图像进行拉平操作
image = image.reshape((1, image.shape[0], image.shape[1],image.shape[2]))
# 读取模型和标签
print("------读取模型和标签------")
model = load_model('./output_cnn/cnn.model')
lb = pickle.loads(open('./output_cnn/cnn_lb.pickle', "rb").read())
# 预测
preds = model.predict(image)
# 得到预测结果以及其对应的标签
i = preds.argmax(axis=1)[0]
label = lb.classes_[i]
# 在图像中把结果画出来
text = "{}: {:.2f}%".format(label, preds[0][i] * 100)
cv2.putText(output, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)
# 绘图
cv2.imshow("Image", output)
cv2.waitKey(0)增加数据增强,BatchNormalization层并训练100EPOCH得到的训练结果:

使用上述得到的网络模型进行测试:


首次运行predict程序出现如下问题:
cv2.error: OpenCV(4.6.0) C:\b\abs_f8n1j3l9l0\croot\opencv-suite_1691622637237\work\modules\highgui\src\window.cpp:1267: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function 'cvShowImage'
解决方法:在对应环境中依次输入以下代码
安装opencv-python
pip install opencv-python安装opencv-contrib-python
pip install opencv-contrib-python 安装过慢可以使用国内的镜像源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple测试结果: