前置回顾
在实验2中,完成了增删查改、排序、分组、聚合、连接等基本操作,在已提供 sql 解析器的基础上,能够运行进本的 sql 语句。都是逻辑层的实现,没有涉及物理存储方面的内容。
实验目标
实现最简单的基于锁的transaction,事务是一组以原子方式执行的数据库操作(例如,插入、删除和读取),要么所有操作都完成,要么没有一个完成。
关系型数据库的事务 acid 特性:
-
Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
-
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
实现思路
Acid 支持
-
最重要的原子性用 golang 的锁实现,互斥锁。 lab3.readMe 中指出,建议锁的粒度是 Page, 而非表级。实际上页面粒度已经很大了,在 MySQL中,一些锁的粒度是到行级。
-
隔离性,因为采用 NO STEAL 策略,所以隔离级别是读提交
-
持久性,因为采用 FORCE 策略,所以有一定的持久性,但不是100%
-
因为保证上述三个特性,所以默认有一致性保障,但一些如外键,not null 等等约束没有实现
STEAL/FORCE
STEAL/FORCE 概念指的是数据库的缓冲池管理和事务提交策略, 本实验使用的是 NO STEAL & FORCE 策略。
关于 NO STEAL / STEAL:如果 Buffer Pool缓存区已满,应该逐出哪些页。
-
STEAL: 允许事务“偷取”未提交副本的缓冲区空间。也就是说,即使一些脏页还未提交,也可以将这些脏页从缓冲区中删除,刷到磁盘中。这是最常用的方法,因为它有效地利用了缓冲区空间,但会导致未提交的内容写入磁盘,需要使用WAL手段来保证一致性。
-
NO STEAL: 不允许事务“偷取”未提交副本的缓冲区空间。换句话说,一个事务修改的页在该事务提交之前不能被换出。这意味着需要足够的缓冲区来处理每个事务。
关于 NO FORCE/FORCE:指的是事务提交时是否立刻刷盘。
-
FORCE: 在事务提交时,立即将所有修改的页写入磁盘。这意味着事务一旦提交,所有的修改都必须持久化,从而简化了在系统崩溃时的恢复过程。然而,这可能会导致大量的磁盘I/O操作。
-
NO FORCE: 不要求事务提交时立即将其修改的页写入磁盘。这意味着即使事务已经提交,其修改的页可能仍然保留在内存中,并在以后的某个时间点写回磁盘。这减少了磁盘I/O的数量,但在崩溃恢复时增加了复杂性。
大多数现代的数据库系统实际上使用的是 STEAL + NO FORCE 策略,因为它提供了在运行时和恢复时的效率之间的一个良好的折衷。这种策略依赖于数据库的事务日志(Transaction Log)来在系统崩溃之后恢复未提交的事务。
锁
锁是实现原子性的关键手段。因为所有上层sql和事务等逻辑操作和底层存储操作之间的媒介都是通过 Buffer Pool,所以事务的实现在Buffer Pool中。按照实验提示锁的粒度是页面级的,所以我们可以在 pool 中采用一种数据结构维护某些事务涉及某些页面。
根据实验提示,事务需要的锁分为共享锁和排它锁,规则如下:
-
在事务可以读取对象之前,它必须拥有共享锁。
-
在事务可以写入对象之前,它必须拥有独占锁。
-
多个事务可以在一个对象上拥有共享锁。
-
只有一个事务可以对某个对象拥有独占锁。
-
如果事务 t 是在对象 o上持有共享锁的唯一事务, 则 t 可以 将 其对 o 的锁升级 为排他锁。
额外要注意的是死锁,关于死锁的概念涉及:
-
死锁形成的四个必要条件[可搜]
-
处理死锁的方法一般有死锁预防、检测和恢复。在实验中采取的是预防,即事务在加锁前先算一下如果加锁会不会导致死锁,如果会就当前回滚事务。
Exercise 1
根据实验手册,首先实现 Buffer Pool 的 GetPage 方法。根据上述实现思路,首先要搞清楚 Buffer Pool 和 事务、Page之间的关联关系。

基于上面的关系,采用 tidLockMap 和 waitTidLockMap 来维护对应的关系。
type BufferPool struct {
// TODO: some code goes here
pageNumber int // 有多少页 page, 是 map的逻辑容量
heapPageMap map[heapHash]*Page // 缓存的 page
mu sync.Mutex // 保证 map 不会并发的锁,也是 buffer pool 的整体锁
// You will want to allocate data structures that keep track of the shared and exclusive locks each transaction is currently holding
// 针对每一个事务,要维护他们所持有的锁list[对应页面list]
// 实验中提到,锁的粒度是 page, 一个 page 上可以有多个事务读锁,一个事务会锁住多个页面,value 如果是 list 的话会有性能问题
tidLockMap map[TransactionID]map[heapHash]pageLock
// 为了死锁的检测和预防,需要维护一个锁等待队列, 某个tid 在等待哪些其他 tid . value 如果是 list 的话会有性能问题
waitTidLockMap map[TransactionID]map[TransactionID]struct{}
}
// 实验中提到,锁的粒度是 page, 一个 page 上可以有多个读锁,一个锁也可以锁住多个页
type pageLock struct {
page *Page
pageNo int // 从 page 里面也能拿到,但需要强转类型
perm RWPerm // 读锁/写锁
pageKey heapHash // Abort事务的时候,需要将页面从Buffer Pool中删除,需要获取页面Key
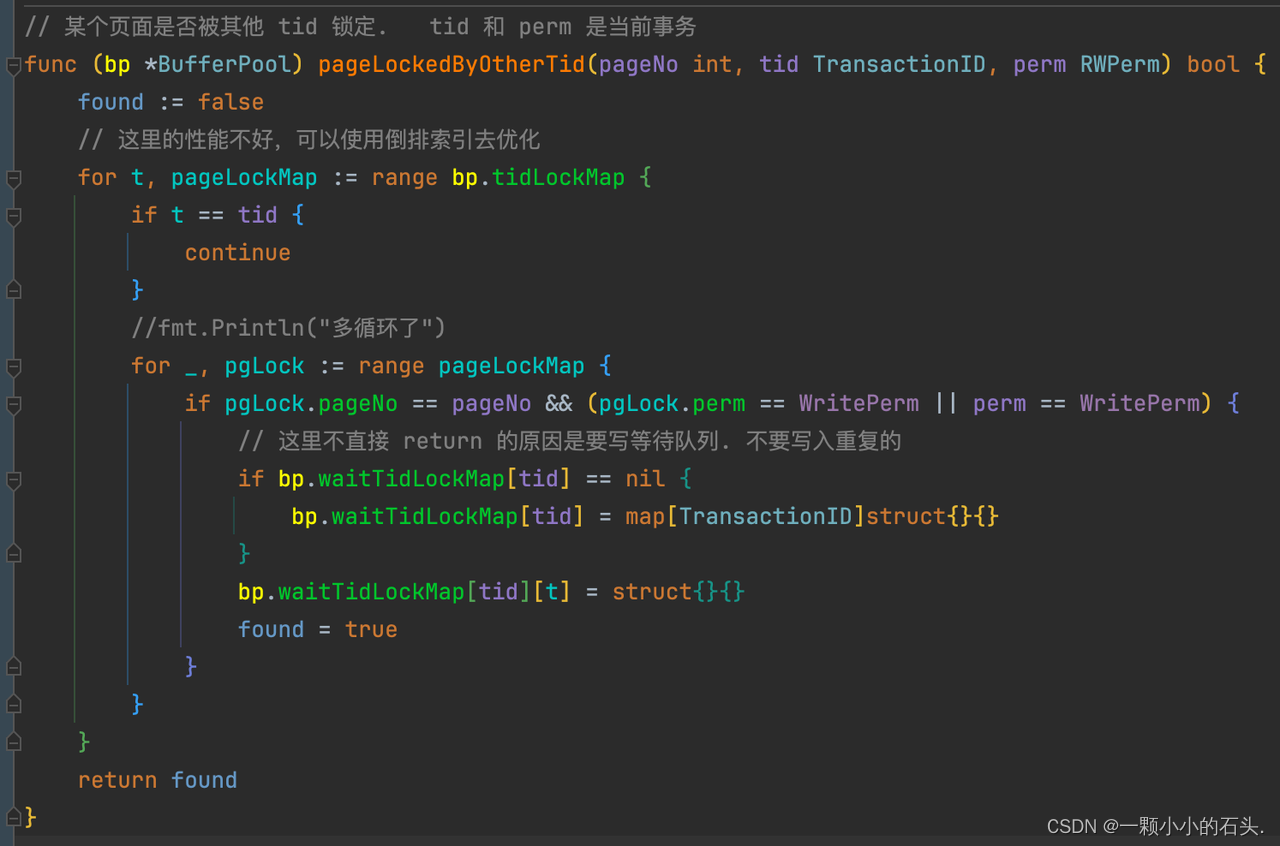
}基本上构思出 Buffer Pool 的数据结构,对于代码的逻辑就很简单了。 GetPage 函数的基本框架不变,只是在之前的逻辑中插入处理事务相关即可【左图】。如何处理事务【右图】,首先是判断一下当前页面上是否有其他事务加的锁,如果有进一步判断是否可能会形成死锁。在每次 for 循环之间需要 sleep 一下并且释放buffer pool的整体锁,减少和其他事务共同形成死锁的可能。


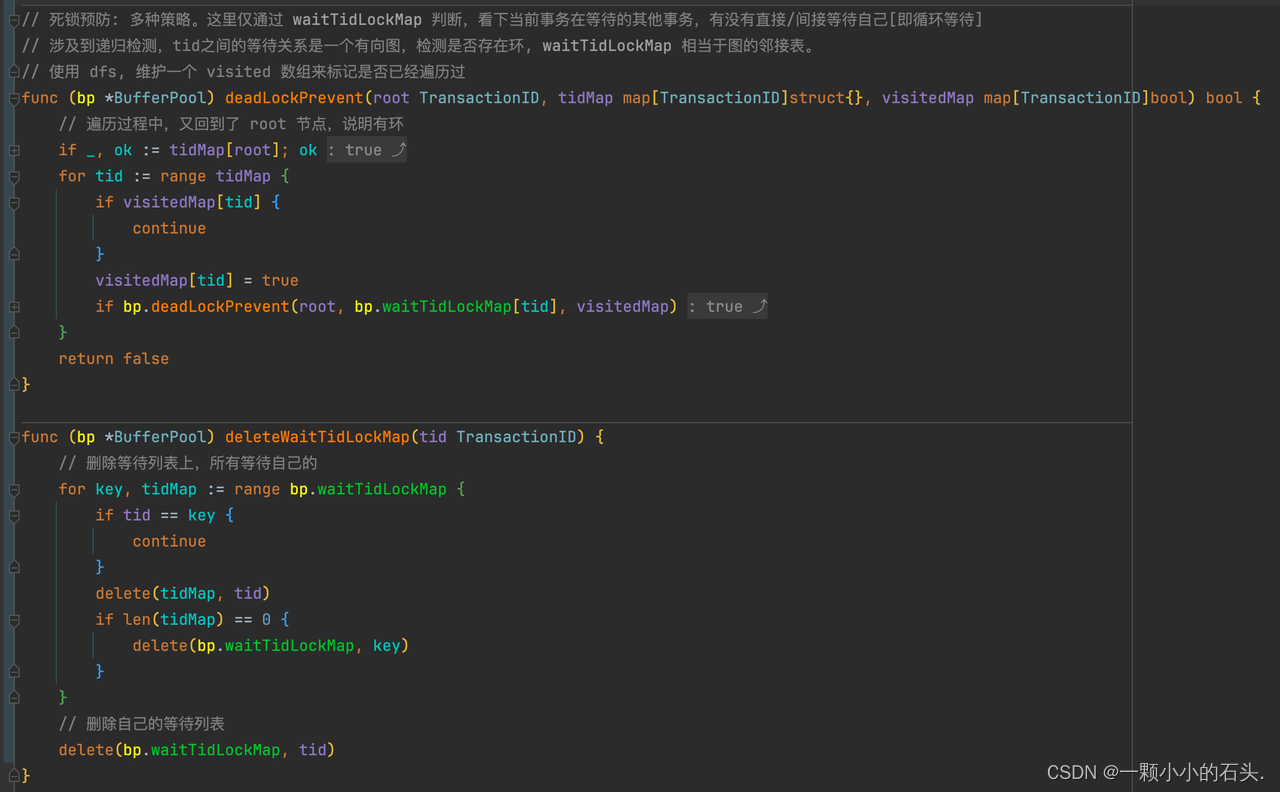
判断当前页面上是否有其他事务加的锁逻辑【左图】,死锁的检测逻辑【右图】。
Exercise 2
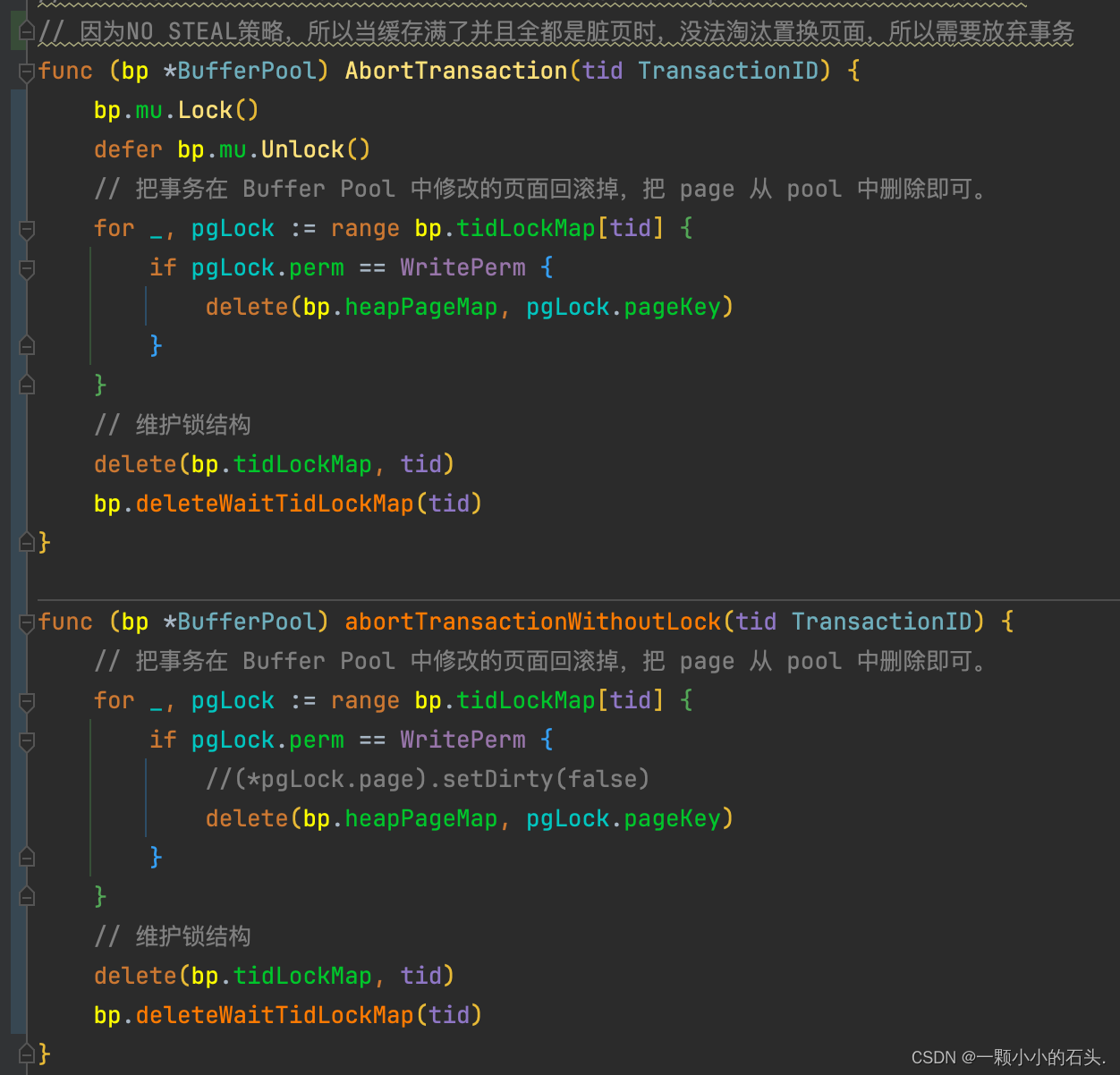
实现 BeginTransaction()、CommitTransaction() 和AbortTransaction()方法。
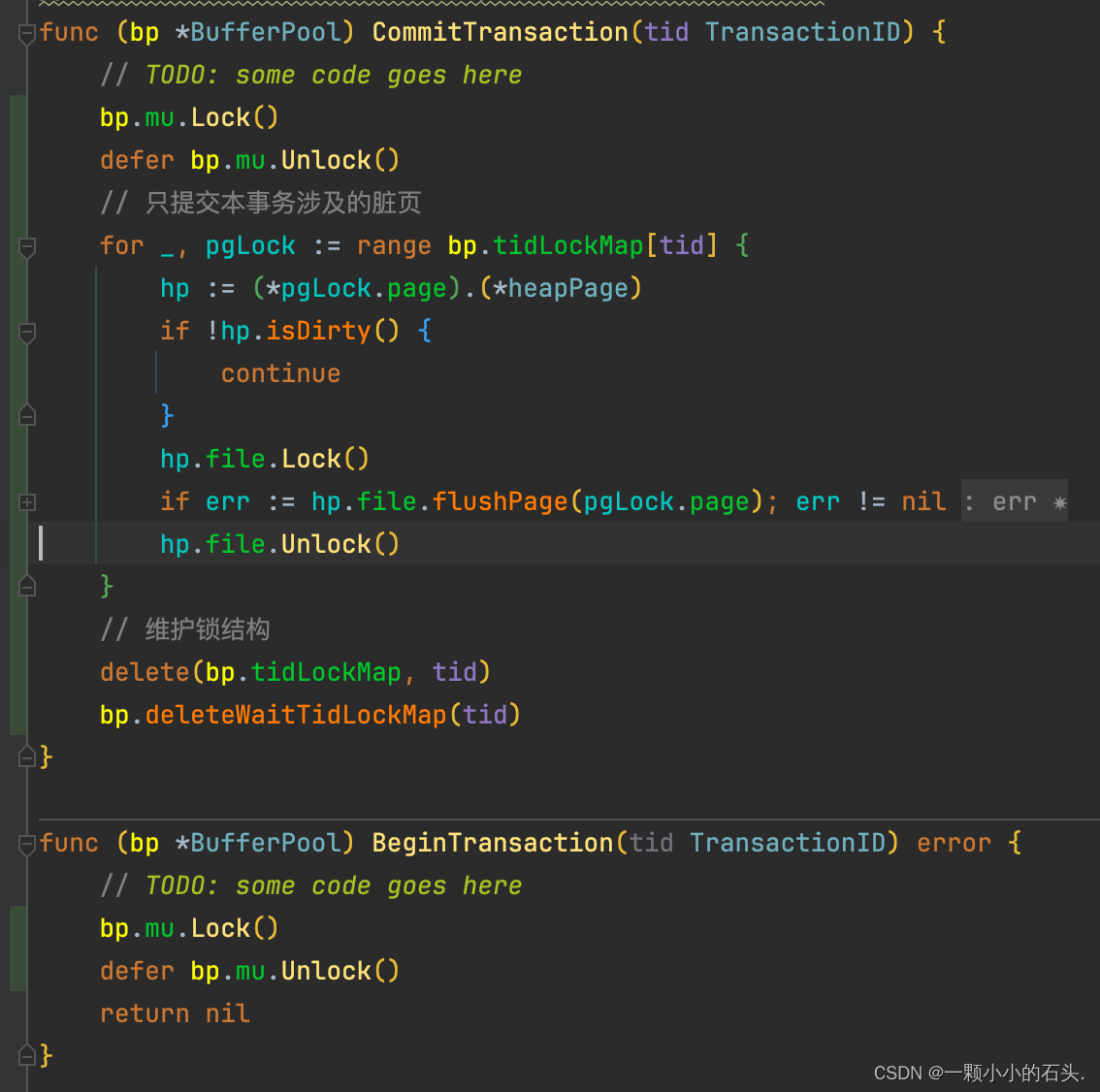
Exercise 3
在整个 GoDB 中添加同步控制块,对于本实现方法来说,就是在 heap_file.go 中的 insert 逻辑中添加互斥锁。另外,实验1中的实现已经不满足事务的性能要求,所以需要重写,代码和注释如下。
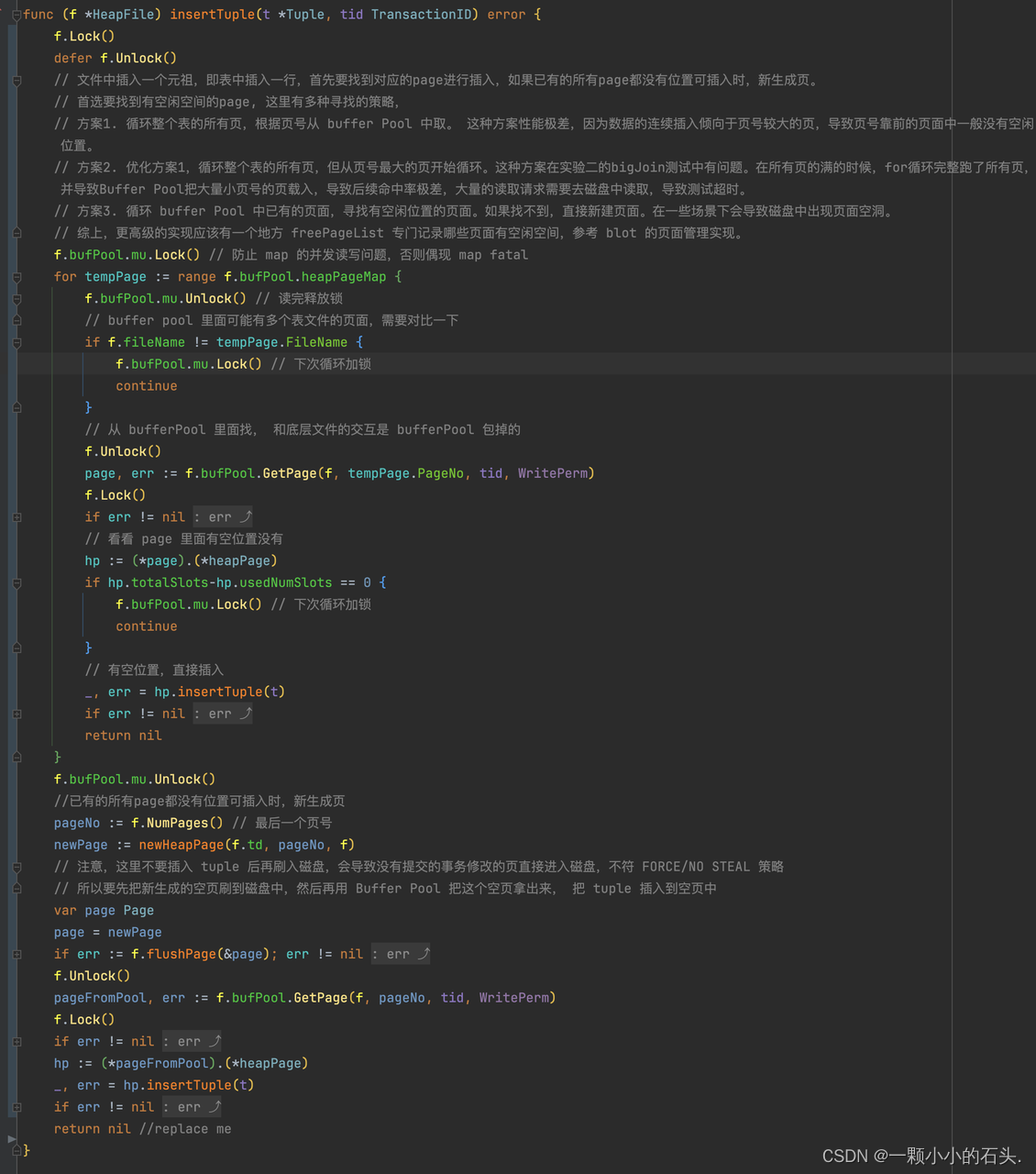
Exercise 4
不能驱逐脏页。在 Exercise 1 中的 buffer pool 的 GetPage 函数中已经实现。
Exercise 5
死锁的预防, 在 Exercise 1 中的 buffer pool 的 deadLockPrevent 函数已经实现。可以把 waitTidLockMap 看成是一个有向图的邻接表,每次需要使用 dfs 算法检测一下是否可能形成环。
总结
在完成所有Exercise代码之后, transaction_test.go deadlock_test.go 以及 locking_test.go 都能顺利通过。实际上事务的实现非常复杂,但很多小型精炼的数据库都对事务进行了简化,例如本次实验的事务的粒度只到 Page ,实际上会产生很多问题,有时候满足不可重读的隔离性有时候不满足。 例如同样是纯 go 实现的 kv 文件数据库 blot db 不支持并发写事务,就不存在各种锁、mvcc 等复杂点。
联系方式
francis_l@qq.com