👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:JAVASE进阶:内存原理剖析(1)——数组、方法、对象、this关键字的内存原理
📚订阅专栏:JAVASE进阶
希望文章对你们有所帮助
String类型的变量是我们非常常用的,它是属于java.lang包下的,属于java核心包下的,直接可以使用。
这一部分的内容也是会出一点面经的,所以我需要重新梳理一下。
同时给了一个可能比较少见的问题,也就是用户输入的字符串,其底层是怎么执行的?这部分内容我会跟踪源码来做解析。
引入
先看下面语句:
String name = "哈哈哈";
name = "哈哈";
这里虽然只用了一次String语句进行声明,但是实际上还是创建了2个字符串,都创建在了字符串常量池中。因此第一句只是将字符串常量池中的"哈哈哈"的地址赋值给了左边的name,第二句是将常量池中的"哈哈"的地址赋值给了左边的name。这其中,并不存在"哈哈哈"字符串变为"哈哈"字符串的说法,即——字符串一旦创建成功,无法进行修改。
字符串常量池
实际上,上述的创建方式一直都是最常用的创建方式,而且也是最推荐的方式,在这里进行一下比较。
创建String对象的两种方式:
1、直接赋值
String name = “哈哈哈”;
2、new关键字
| 构造方法 | 说明 |
|---|---|
| public String() | 创建空白字符串 |
| public String(String s) | 根据传入的字符串创建字符串对象(很少用) |
| public String(char[] chs) | 根据字符数组,创建字符串对象 |
| public String(byte[] chs) | 根据字节数组,创建字符串对象 |
字符串常量池(串池,StringTable)在之前一直都是在方法区(元空间)中的,而在jdk7开始,从方法区挪到了堆内存,但是底层的实现方式还是不变的。
查看下面语句:
String s1 = "abc";
String s2 = "abc";
第一条语句先从常量池中查看是否有这条字符串,没有就创建一个,并把地址赋值给s1,第二条语句在常量池中查找到这条字符串,直接返回地址给s2(复用),也就是说s1和s2指向了常量池中的同一条字符串了。
再看下面语句:
char[] chs = {'a', 'b', 'c'};
String s1 = new String(chs);
String s2 = new String(chs);
因为有new关键字,所以创建的过程全部在堆内存(不包括常量池)进行的,这时候会创建出两条字符串,并且s1和s2的地址是不一样的,即不会复用,显然更耗费空间。
所以,字符串常量池不仅代码简单,还因为复用机制更省内存。
字符串比较底层机理
分别分析下面语句的运行结果:
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
true
String s1 = "aaa";
String s2 = "bbb";
System.out.println(s1 == s2);
false
String s1 = new String("abc");
String s2 = "abc";
System.out.println(s1 == s2);
false
在第三个例子中,值一样的字符串,比较结果却是false,所以需要搞明白==到底比较的是啥。
实际上,如果是基本数据类型,直接比较的就是真实值,而字符串由于涉及到了常量池和堆内存,显然是引用数据类型,而引用数据类型比较的是地址值,由于new出来的是在堆空间的,直接赋值的方式是在字符串常量池的,因此它们根本不可能是同一个地址,因此返回false。
因此,==的方式并不适合用来比较字符串,实际比较最好使用字符串比较函数:
boolean equals()
boolean equalsIgnoreCase(): 忽略大小写比较,比如验证码
字符串输入源码分析
真实场景下,字符串可能不是直接赋值的,而是要用户自己去输入的,那么用户自己输入的字符串到底是放在常量池中的还是放在堆内存中的呢?可以验证并跟踪源码分析。
查看下列语句:
Scanner sc = new Scanner(System.in);
String s1 = sc.next();
String s2 = "abc";
System.out.println(s1 == s2);
用户输入abc,但最终输出的是false,可以猜想到,用户输入字符串后,其创建是在堆空间中进行的,进行源码分析:
1、Ctrl+鼠标进入next方法查看一下,其返回的内容是一个token,token的来源是getCompleteTokenInBuffer方法:
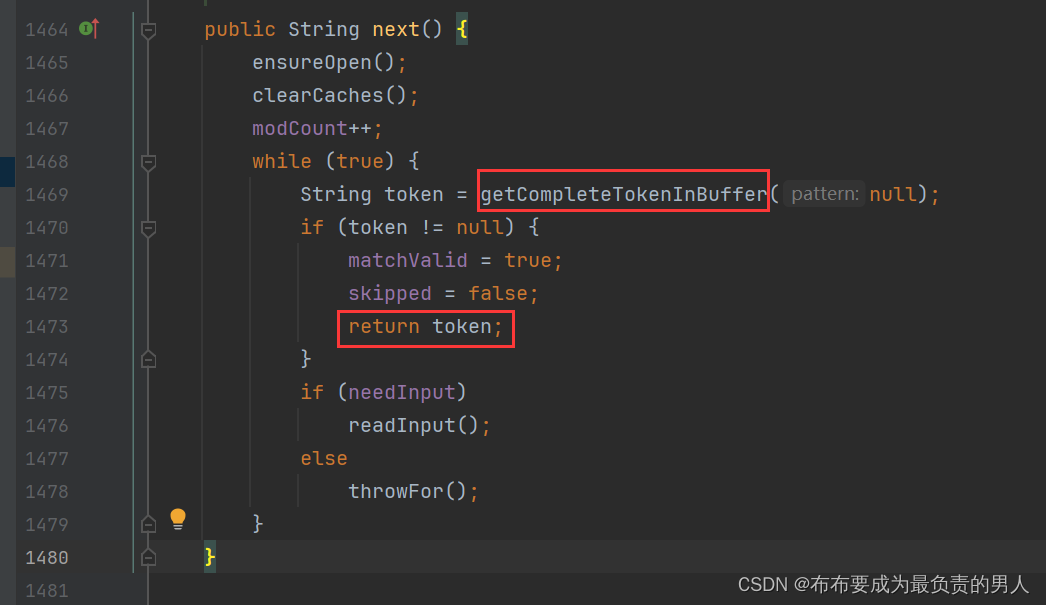
2、跟踪getCompleteTokenInBuffer方法,可以看到源码非常长:
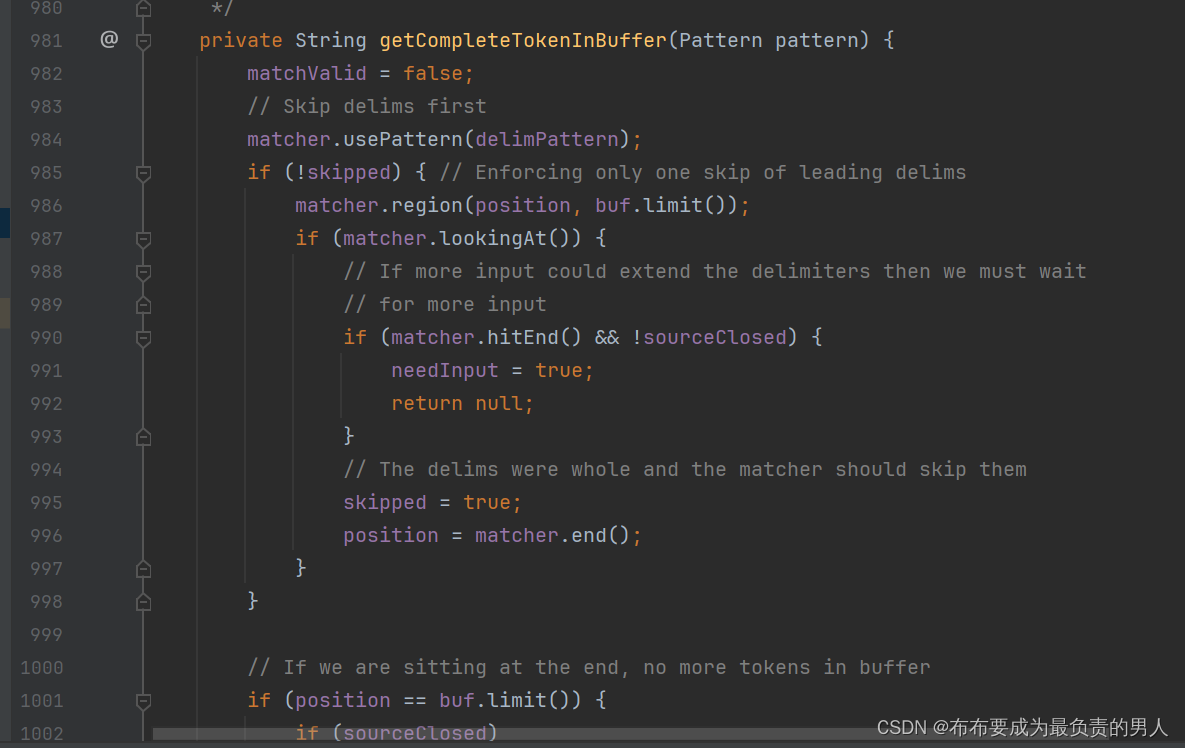
但是其实只要看关键的信息,也就是return的真实信息,那些return null的其实肯定不是我们重点关注的,因此定位到正确位置:
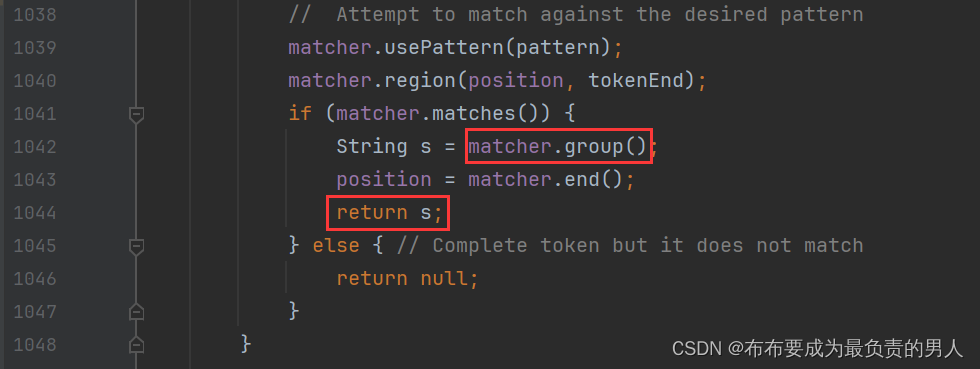
3、ctrl+左键跟踪进入group:
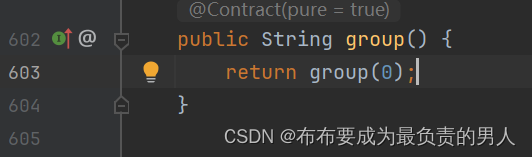
4、继续跟踪group(0):
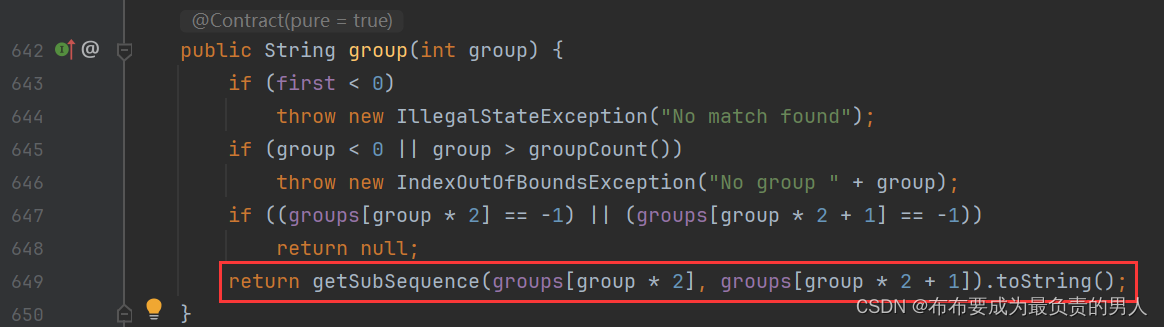
5、再跟踪:

6、继续跟踪,发现没有返回值了,就是一个定义好的接口:
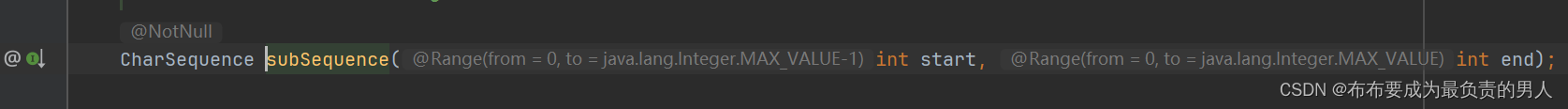
这其实就是java设计模式的原则了,用父类去替代子类,说明这个接口的实现类还是很多的,因此没办法从这里进行分析,回到上一层的subSequence。
7、右键点击subSequence方法,并点击go to,选择Implementation,即可找到其中的所有实现类:
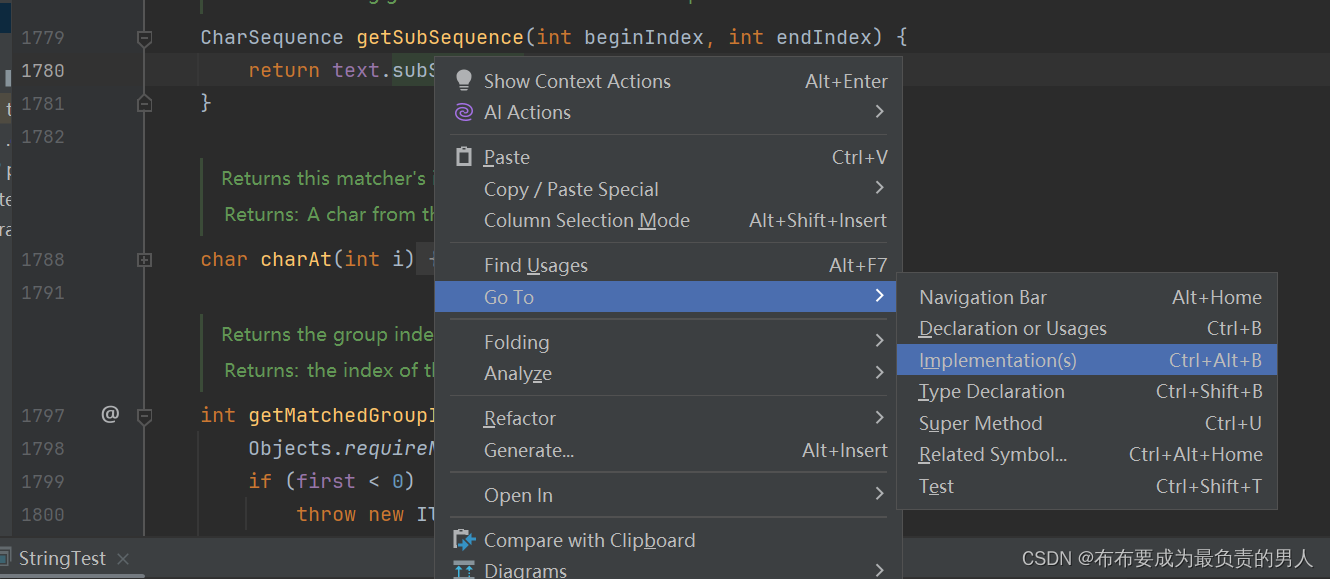
8、显然我们需要寻找有关于String的,所以点击String进入:
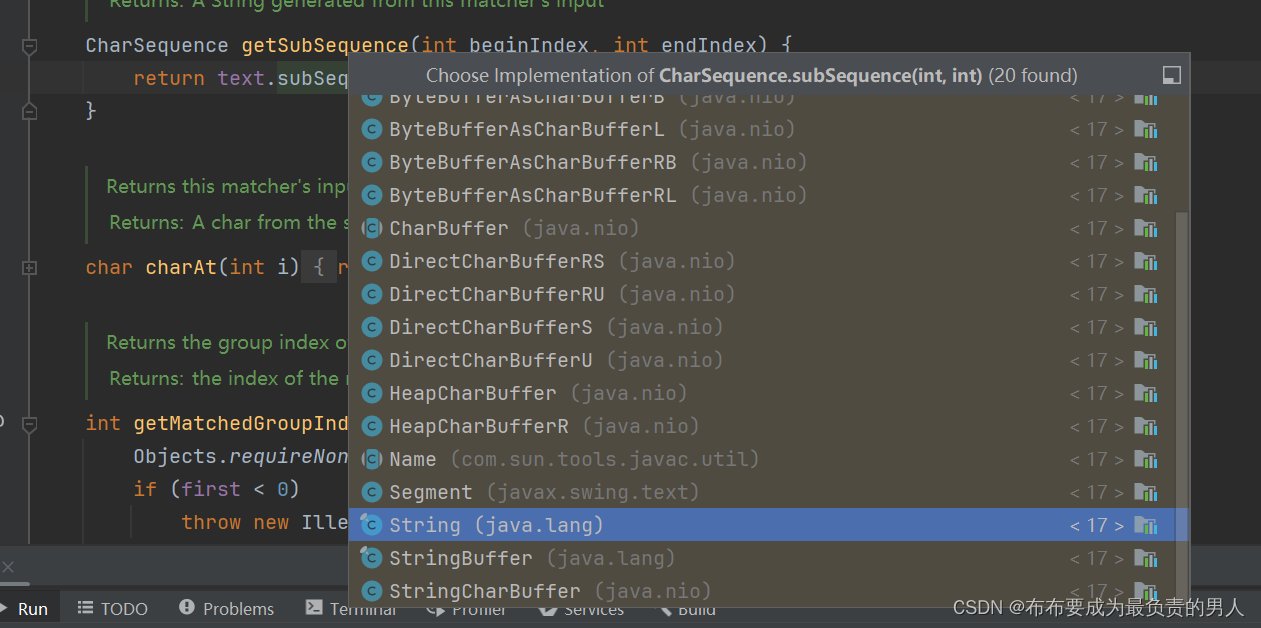

9、跟踪进入:
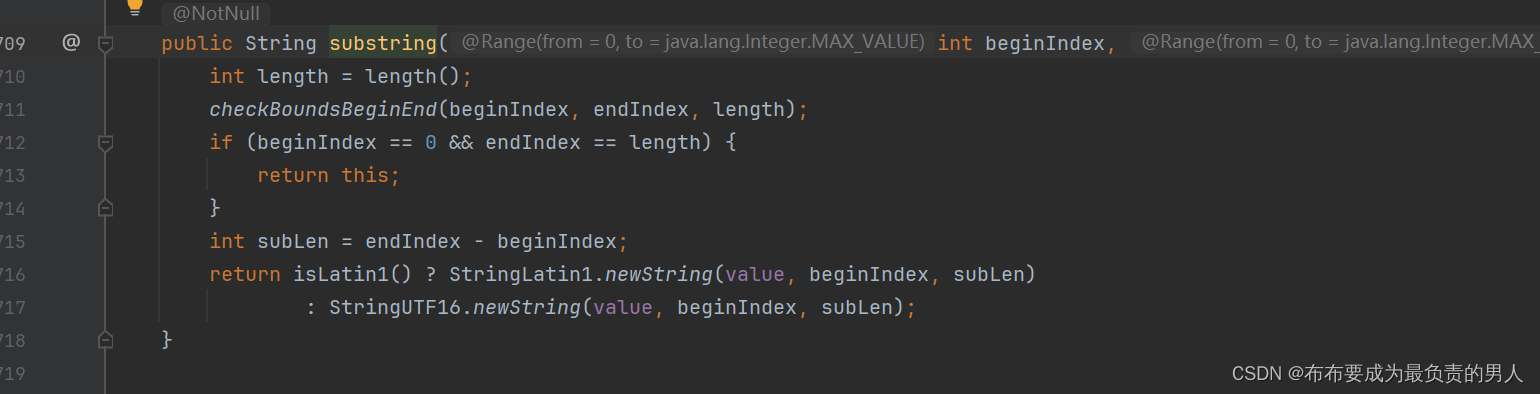
其实看到这个return里面带着的new的字样大致就能猜到它底层肯定是用到了new关键字了。
10、跟踪newString方法跟踪,看到了底层的new关键字:
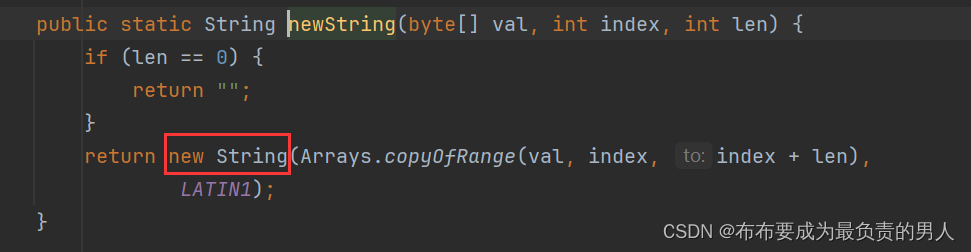
这就说明了,用户用键盘输入的字符串,即sc.next(),其底层是会用到new关键字,也就是说其创建在堆空间中,所以例子中的程序返回false。
跟踪源码心得
我不是第一次跟踪源码了,每次跟踪源码都会有一些不一样的心得,在这里讲一下我目前拥有的经验:
1、无所谓跟踪进去的方法有多么复杂,先查找return真实值的那部分,其是由哪个函数创建出来的,就跟踪那个函数
2、如果return真实值的情况有多种,可以快速筛查我们到底应该跟踪哪一个:
(1)看其中的英文注释
(2)看返回值和你的需求对不对得上
(3)看函数名称,自己翻译了猜一下
3、如果跟踪到没办法再跟踪的接口,说明是父类替代的子类,返回并右键查找正确的实现类(根据需求)









![[Visual Studio] vs 2022中如何创建空白的解决方案](https://img-blog.csdnimg.cn/direct/1cdc82dad6414237ba49f3b9eef51b39.png)