来自吴恩达深度学习,仅为本人学习所用。
文章目录
- 神经网络的表示
- 计算神经网络的输出
- 激活函数
- tanh
- 选择激活函数
- 为什么需要非激活函数
- 双层神经网络的梯度下降法
- 随机初始化
神经网络的表示
对于简单的Logistic回归,使用如下的计算图。

如果是多个神经元组合起来构成一个神经网络,计算图如下
输入特征
x
1
,
x
2
,
x
3
x1, x2, x3
x1,x2,x3所在的层是输入层;中间的三个圆圈所在的层是隐藏层,在训练集中找不到隐藏层的数据;最后的一个圆圈所在的层是输出层,直接输出
y
^
\hat{y}
y^。
使用上标 [ 1 ] [1] [1]、 [ 2 ] [2] [2]表示第一层,第二层的神经网络。之前使用 X \mathbf{X} X表示输入的特征值,也可以使用 a [ 0 ] \mathbf{a}^{[0]} a[0]表示网络中的输入层;中间的隐藏层使用 a [ 1 ] \mathbf{a}^{[1]} a[1]表示,从上往下的圆圈分别为 a 1 [ 1 ] 、 a 2 [ 1 ] 、 a 3 [ 1 ] 、 a 4 [ 1 ] a^{[1]}_1、a^{[1]}_2、a^{[1]}_3、a^{[1]}_4 a1[1]、a2[1]、a3[1]、a4[1],有 a [ 1 ] = [ a 1 [ 1 ] a 2 [ 1 ] a 3 [ 1 ] a 4 [ 1 ] ] \mathbf{a}^{[1]}=\begin{bmatrix} a^{[1]}_1\\ a^{[1]}_2\\ a^{[1]}_3\\ a^{[1]}_4 \end{bmatrix} a[1]= a1[1]a2[1]a3[1]a4[1] ;最后产生 a [ 2 ] \mathbf{a}^{[2]} a[2]。
该神经网络是个2层的神经网络(隐藏层+输出层),一般不把输入层看作一个标准的层。隐藏层及最后的输出层是带有参数的。

在上面的计算图中,先计算第一层的Logistic回归,然后将计算出的
a
[
1
]
a^{[1]}
a[1]作为下一层的
X
X
X继续计算第二层的Logistic回归,最后计算到损失函数,完成一次正向传播;接着求导完成反向传播。
计算神经网络的输出

分别计算
a
1
[
1
]
a^{[1]}_1
a1[1]和
a
2
[
1
]
a^{[1]}_2
a2[1]

隐藏层的每一个神经元的公式为
有
Z
[
1
]
=
[
z
1
[
1
]
z
2
[
1
]
z
3
[
1
]
z
4
[
1
]
]
=
[
—
w
1
[
1
]
T
—
—
w
2
[
1
]
T
—
—
w
3
[
1
]
T
—
—
w
4
[
1
]
T
—
]
[
x
1
x
2
x
3
]
+
[
b
1
[
1
]
b
2
[
1
]
b
3
[
1
]
b
4
[
1
]
]
=
W
[
1
]
X
+
b
[
1
]
\mathbf{Z}^{[1]}=\begin{bmatrix} z^{[1]}_1\\ z^{[1]}_2\\ z^{[1]}_3\\ z^{[1]}_4\end{bmatrix}=\begin{bmatrix} —w^{[1]T}_1—\\ —w^{[1]T}_2—\\ —w^{[1]T}_3—\\ —w^{[1]T}_4—\end{bmatrix}\begin{bmatrix} x_1\\ x_2\\ x_3\end{bmatrix}+\begin{bmatrix} b^{[1]}_1\\ b^{[1]}_2\\ b^{[1]}_3\\ b^{[1]}_4\end{bmatrix}=\mathbf{W}^{[1]}\mathbf{X}+\mathbf{b}^{[1]}
Z[1]=
z1[1]z2[1]z3[1]z4[1]
=
—w1[1]T——w2[1]T——w3[1]T——w4[1]T—
x1x2x3
+
b1[1]b2[1]b3[1]b4[1]
=W[1]X+b[1]
a
[
1
]
=
[
a
1
[
1
]
a
2
[
1
]
a
3
[
1
]
a
4
[
1
]
]
=
σ
(
Z
[
1
]
)
\mathbf{a}^{[1]}=\begin{bmatrix} a^{[1]}_1\\ a^{[1]}_2\\ a^{[1]}_3\\ a^{[1]}_4 \end{bmatrix}=\sigma(\mathbf{Z}^{[1]})
a[1]=
a1[1]a2[1]a3[1]a4[1]
=σ(Z[1])下一层表示为
Z
[
2
]
=
W
[
2
]
X
+
b
[
2
]
\mathbf{Z}^{[2]}=\mathbf{W}^{[2]}\mathbf{X}+\mathbf{b}^{[2]}
Z[2]=W[2]X+b[2]
a
[
2
]
=
[
a
1
[
2
]
a
2
[
2
]
a
3
[
2
]
a
4
[
2
]
]
=
σ
(
Z
[
2
]
)
\mathbf{a}^{[2]}=\begin{bmatrix} a^{[2]}_1\\ a^{[2]}_2\\ a^{[2]}_3\\ a^{[2]}_4 \end{bmatrix}=\sigma(\mathbf{Z}^{[2]})
a[2]=
a1[2]a2[2]a3[2]a4[2]
=σ(Z[2])
激活函数
tanh
tanh 函数,即双曲正切函数,其数学表达式为:
tanh
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
\tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}
tanh(x)=ex+e−xex−e−x
- 值域: t a n h ( x ) tanh(x) tanh(x) 的值域是 ( − 1 , 1 ) (-1, 1) (−1,1)。当 (x) 趋于正无穷大时, t a n h ( x ) tanh(x) tanh(x)趋近于 1 1 1;当 x x x 趋于负无穷大时, t a n h ( x ) tanh(x) tanh(x) 趋近于 − 1 -1 −1;当 x = 0 x = 0 x=0 时, t a n h ( x ) = 0 tanh(x)=0 tanh(x)=0。
- 形状:它是一个 S 型函数,形状类似于
sigmoid函数,但它的输出范围是(-1, 1),而不是sigmoid函数的(0, 1)。 - 导数: t a n h tanh tanh 函数的导数可以根据其函数形式计算得到, t a n h ′ ( x ) = 1 − tanh 2 ( x ) tanh'(x)=1-\tanh^{2}(x) tanh′(x)=1−tanh2(x),这个性质在反向传播算法中计算梯度时非常有用,因为导数的计算相对简单,并且在x = 0时导数最大,为 1 1 1,随着 x x x 趋于正负无穷,导数趋近于 0 0 0。
好处如下:
- 解决梯度消失问题:相比
sigmoid函数, t a n h tanh tanh函数在一定程度上可以缓解梯度消失问题。因为sigmoid函数在输入绝对值较大时,梯度趋近于 0,导致梯度更新非常缓慢,而 t a n h tanh tanh函数的输出范围更广,其梯度在远离 0 0 0的位置相对sigmoid函数来说更不容易趋近于 0 0 0,在某些情况下可以帮助神经网络更快地收敛。 - 中心化输出:
t
a
n
h
tanh
tanh函数的输出是零均值的,即输出的平均值接近0,这有助于下一层的学习,因为下一层的输入的平均值不会总是正数,避免了
sigmoid函数输出总是正的问题,这可以加快网络的收敛速度。
选择激活函数
到目前为止,如果输出的是0,1之类的二元分类问题,激活函数可以选择sigmoid函数做输出层的激活函数、其他所有单元使用ReLU函数;如果不知道隐藏层使用哪个激活函数,ReLU函数一般默认做隐藏层的激活函数; t a n h tanh tanh函数相对于sigmoid函数更好。
为什么需要非激活函数
如果只是使用线性激活函数,不论一个神经网络有多少层,合并化简后的表达式与单层神经网络的激活函数表达式相同,导致隐藏层没什么作用。

双层神经网络的梯度下降法
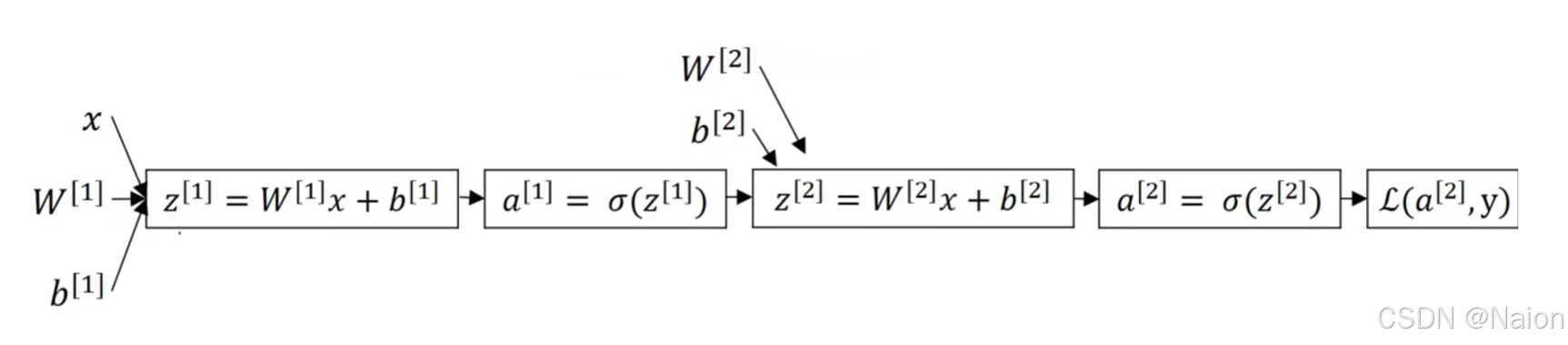
给出上述笔记的双神经网络计算图,反向传播进行计算,有
d
a
[
2
]
=
d
L
d
a
[
2
]
=
−
y
a
[
2
]
+
1
−
y
1
+
a
[
2
]
\mathrm{d}a^{[2]}=\frac{\mathrm{d}L}{\mathrm{d}a^{[2]}}=-\frac{y}{a^{[2]}}+\frac{1-y}{1+a^{[2]}}
da[2]=da[2]dL=−a[2]y+1+a[2]1−y
d
a
[
2
]
d
z
[
2
]
=
e
−
x
(
1
+
e
−
x
)
2
=
a
[
2
]
(
1
−
a
[
2
]
)
\frac{\mathrm{d}a^{[2]}}{\mathrm{d}z^{[2]}}=\frac{e^{-x}}{(1+e^{-x})^2}=a^{[2]}(1-a^{[2]})
dz[2]da[2]=(1+e−x)2e−x=a[2](1−a[2])
d
z
[
2
]
=
d
L
d
z
[
2
]
=
d
L
d
a
[
2
]
d
a
[
2
]
d
z
[
2
]
=
a
[
2
]
−
y
dz^{[2]}=\frac{\mathrm{d}L}{\mathrm{d}z^{[2]}}=\frac{\mathrm{d}L}{\mathrm{d}a^{[2]}}\frac{\mathrm{d}a^{[2]}}{\mathrm{d}z^{[2]}}=a^{[2]}-y
dz[2]=dz[2]dL=da[2]dLdz[2]da[2]=a[2]−y
d
w
[
2
]
=
d
L
d
w
[
2
]
=
d
L
d
a
[
2
]
d
a
[
2
]
d
z
[
2
]
d
z
[
2
]
d
w
[
2
]
=
(
a
[
2
]
−
y
)
(
w
[
2
]
x
+
b
[
2
]
)
′
=
(
a
[
2
]
−
y
)
x
T
=
(
a
[
2
]
−
y
)
(
a
[
1
]
)
T
\mathrm{d}w^{[2]}=\frac{\mathrm{d}L}{\mathrm{d}w^{[2]}}=\frac{\mathrm{d}L}{\mathrm{d}a^{[2]}}\frac{\mathrm{d}a^{[2]}}{\mathrm{d}z^{[2]}}\frac{\mathrm{d}z^{[2]}}{\mathrm{d}w^{[2]}} =(a^{[2]}-y)(w^{[2]}x+b^{[2]})'=(a^{[2]}-y)x^T=(a^{[2]}-y)(a^{[1]})^T
dw[2]=dw[2]dL=da[2]dLdz[2]da[2]dw[2]dz[2]=(a[2]−y)(w[2]x+b[2])′=(a[2]−y)xT=(a[2]−y)(a[1])T
- 从计算图中可以看出, x x x实际上来自上一层的 a [ 1 ] a^{[1]} a[1]。
- x x x转置是为了满足矩阵运算的维度一致性以及遵循矩阵求导的规则。还记着前面说过,该计算图中, w [ 2 ] w^{[2]} w[2]和 b [ 2 ] b^{[2]} b[2]实际上是一个矩阵,对矩阵求导的时候要满足维度的一致。在单个神经元的场景下, w w w和 b b b实际上是标量,不存在维度一致性的问题。
d b [ 2 ] = d z [ 2 ] \mathrm{d}b^{[2]}=\mathrm{d}z^{[2]} db[2]=dz[2] d a [ 1 ] = d L d a [ 2 ] d a [ 2 ] d z [ 2 ] d z [ 2 ] d a [ 1 ] = ( a [ 2 ] − y ) ( w [ 2 ] ) T σ ′ ( z [ 1 ] ) = ( a [ 2 ] − y ) ( w [ 2 ] ) T \mathrm{d}a^{[1]}=\frac{\mathrm{d}L}{\mathrm{d}a^{[2]}}\frac{\mathrm{d}a^{[2]}}{\mathrm{d}z^{[2]}}\frac{\mathrm{d}z^{[2]}}{\mathrm{d}a^{[1]}}=(a^{[2]}-y)(w^{[2]})^{T}\sigma'(z^{[1]})=(a^{[2]}-y)(w^{[2]})^{T} da[1]=da[2]dLdz[2]da[2]da[1]dz[2]=(a[2]−y)(w[2])Tσ′(z[1])=(a[2]−y)(w[2])T
d z [ 1 ] = d L d a [ 1 ] d a [ 1 ] d z [ 1 ] = ( a [ 2 ] − y ) ( w [ 2 ] ) T ⊙ σ ′ ( z [ 1 ] ) \mathrm{d}z^{[1]}=\frac{\mathrm{d}L}{\mathrm{d}a^{[1]}}\frac{\mathrm{d}a^{[1]}}{\mathrm{d}z^{[1]}}=(a^{[2]}-y)(w^{[2]})^{T}\odot\sigma'(z^{[1]}) dz[1]=da[1]dLdz[1]da[1]=(a[2]−y)(w[2])T⊙σ′(z[1])
⊙ \odot ⊙:对于两个维度相同的向量 x = ( x 1 , x 2 , ⋯ , x n ) \mathbf{x}=(x_1,x_2,\cdots,x_n) x=(x1,x2,⋯,xn) 和 y = ( y 1 , y 2 , ⋯ , y n ) \mathbf{y}=(y_1,y_2,\cdots,y_n) y=(y1,y2,⋯,yn) ,它们的逐元素乘积 z = x ⊙ y = ( x 1 y 1 , x 2 y 2 , ⋯ , x n y n ) \mathbf{z}=\mathbf{x}\odot\mathbf{y}=(x_1y_1,x_2y_2,\cdots,x_ny_n) z=x⊙y=(x1y1,x2y2,⋯,xnyn) 。
随机初始化
对称性问题是指如果神经网络中多个神经元的权重初始值相同,就会出现对称性问题。例如,在一个多层神经网络中,若同一层的神经元初始权重都一样,那么在正向传播时,它们对输入的处理完全相同,反向传播时梯度更新也相同,这使得神经元无法学习到不同的特征,网络的表达能力受限。为避免这种情况,通常采用随机初始化权重的方法。
对于Logistic函数,将权重初始化为0是可以的,但是如果将神经网络的各参数全部初始化为0,导致隐藏单元一直在做同样的计算,对输出单元的影响一样大,多次迭代后两个隐藏单元一直在做重复的计算,也就是对称性问题。这个时候,多个隐藏单元是没有意义的,在使用梯度下降将会无效。
对于该问题,解决方案的随机初始化所有的参数。
w = np.random.randn((2,2)) * 0.01


















