在正常的自动化过程中,如果整篇代码中没有加等待时间的话,有时候可能页面跳转或者还没开始点击就执行到下一个流程了,这时候因为页面没有加载完毕,所以有可能会导致找不到对应的元素而报错,因此我们需要在整个代码流程中间合适的位置加上等待时间,使其等待页面加载完毕后,在进行后续代码流程。
Selenium中有三种等待方式,分别为:强制等待、隐式等待、显示等待。
1、强制等待。
强制等待顾名思义就是按着设置的等待时间进行等待,设置的多久就是多久,无论元素是有有加载出来,都必须到设置的时间才会进行下面的操作,这种方式相比其他两种在自动化中不是特别灵活。
强制等待使用的是time模块的sleep(),在sleep()括号中填入数字即可,单位为秒。
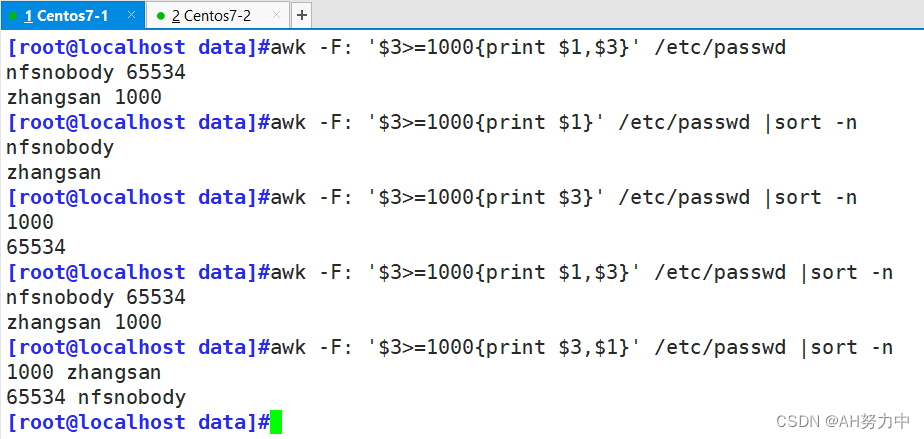
from selenium import webdriver #导入selenium模块的webdriver
from time import sleep #导入Time模块的sleep
driver = webdriver.Chrome() #webdriver.Chrome()是启动谷歌浏览器然后定义成变量driver
driver.get("http://www.baidu.com") #打开百度浏览器
sleep(5) #等待5秒
driver.maximize_window() #全屏显示上面的这段就能明显的看出来,打开浏览器后,等待了5s浏览器才全屏显示的。
2、隐式等待
隐式等待相比较强制等待比较灵活,隐式等待就是设置一个全局的等待时间即可,定义一次就行,不用在特定的步骤写了,设置完后,就是会在等待时间里,如果页面加载完成(浏览器整个页面元素都加载完毕,一般看浏览器上没有loading的那个小圈圈就行),就可以执行下一步了,不用说是非得等到时间到才执行,如果超过设置的时间还没有加载完成,就不等了去执行下一步。 ![]()
隐式等待用得是implicitly_wait()方法,在括号里填上时间即可。从下面的代码中就可以看出,不到5S时就对浏览器执行了全屏操作。
from selenium import webdriver #导入selenium模块的webdriver
from time import sleep #导入Time模块的sleep
driver = webdriver.Chrome() #webdriver.Chrome()是启动谷歌浏览器然后定义成变量driver
driver.get("http://www.baidu.com") #打开百度浏览器
driver.implicitly_wait(5) #最多等待5s,如果页面加载完毕开始后续代码执行,设置一次后,后面都会按着这个规则去执行
driver.maximize_window() #全屏显示3、显示等待
显示等待相比较隐式等待更加灵活。显示等待是会加一个判断条件,如果我在规定时间里找到了这个元素,我就开始往下执行了,有时候可能页面里咱们需要的元素已经加载出来了,但是别的元素还在加载中,这时候如果我们用隐式等待的话,他会等都加载出来才执行,但是显示等待发现有我需要的元素了,就停止等待,往下执行代码了。
显示等待除了要设置等待时间还需要设置一下条件,在使用是需要导入WebDriverWait模块(时间)和expected_conditions模块(条件)。
(1)WebDriverWait()
对于WebDriverWait()方法来说,需要在括号中填入以下内容:
WebDriverWait(driver,timeout,poll_frequency,ignore_exception)
#driver:浏览器驱动
#timeout:设置的最长等待时间
#poll_frequency:检查元素是否存在的时间间隔
#ignore_exception:超时没找到元素后抛出的异常信息一般来说只填入driver和timeout即可,其他的为默认值可以不进行填写,如:WebDriverWait(driver,5) ,就是最长等待5S,每500ms检测一次元素是否加载出来了,如果没有加载出来报默认的异常NoSuchElementException。
(2)until()和not_until()
WebDriverWait()大部分都是配合until()和not_until()使用。下面可以看下具体用法:
until()的用法是直到后面的条件返回内容为Ture,否则就报错错误信息,一般括号里填写为until(method:判断的方法,message=“报错信息”)。用于跟着expected_conditions()方法来判断元素是否加载出来了。
not_until()的用法和until()正好相反,not_until()是直到后面的条件返回的内容为False,否则就报出错误信息,括号里填写的与until()一样。not_until()一般是用于判断某个元素是否消失了。
from selenium import webdriver #导入selenium的webdriver模块
from selenium.webdriver.support.wait import WebDriverWait #导入selenium的WebDriverWait模块
from selenium.webdriver.support import expected_conditions as EC #导入selenium的expected_conditions模块并命名为EC
from selenium.webdriver.common.by import By #导入导入selenium的by模块并命名为By
driver = webdriver.Chrome() #webdriver.Chrome()是启动谷歌浏览器然后定义成变量driver
driver.get("https://www.baidu.com") #打开百度浏览器
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,"kw"))).send_keys("3333") #设置强制等待10面,每500ms检查一次元素是否存在,检查方式为持续检查,知道发现了ID为kw的元素,然后返回True给until,之后执行输入"3333"的命令(3)expected_conditions()
对于expected_conditions()方法来说,使用时需要在括号里面填上具体的判断条件即可,详细内容见下面。

| title_is("预期title") | 网页的title是否完全等于预期(返回布尔值) |
| title_contains("预期") | 网页的title是否包含预期结果(返回布尔值) |
| url_to_be("url") | 网页的网址是否完全等于预期结果(返回布尔值) |
| url_contains("url") | 网页的网址是否包含预期结果(返回布尔值) |
| url_matches("正则表达式") | 网页的网址是否满足于正则表达式匹配的网址(返回布尔值) |
| presence_of_element_located("元素") | 判断元素是否存在于页面DOM树中(元素不一定可见)(返回元素对象) |
| visibility_of_element_located("元素") | 判断元素是否可见(返回元素对象)(locator定位) |
| visibility_of("元素") | 判断元素是否可见(返回元素对象)(element定位)(关于locator定位和element定位方式大家自行百度下吧) |
| text_to_be_present_in_elemen(元素,"文本") | 判断文本是否存在于元素中(返回布尔值) |
| number_of_windows_to_be(数字) | 判断打开的窗口数是否于实际一致(返回布尔值) |
| element_to_be_clickable(元素) | 判断元素是否可点击(返回布尔值) |
| new_window_is_opened(handle) | 判断是否打开了一个新的窗口(返回布尔值) |
| element_to_be_selected(元素) | 判断元素是否被选中(一般用于下拉框)(返回布尔值)(element定位) |
| element_located_to_be_selected(元素) | 判断元素是否被选中(一般用于下拉框)(返回布尔值)(locator定位) |
| element_selection_state_to_be(元素,布尔值) | 判断元素的选中状态是否符合预期(返回布尔值)(element定位) |
| element_located_selection_state_to_be(元素,布尔值) | 判断元素的选中状态是否符合预期(返回布尔值)(locator定位) |
| alert_is_present() | 判断页面是否有alert对话框(如果存在切换到alert,如果不存在返回False) |
这里就不对expected_conditions常用方法一一举例了,记住整体的使用方式,配合我们需要的场景进行使用即可。
如果大家在使用过程中遇到了问题,可以在文章下留言,或者关注公众号:刘阿童木的进化记录,进行留言
下图为公众号二维码,内容会同步发出,大家可以关注一起学习!



![[力扣 Hot100]Day20 旋转图像](https://img-blog.csdnimg.cn/direct/c286c3e66fb64dd9be08f15b7f2f59a5.png)