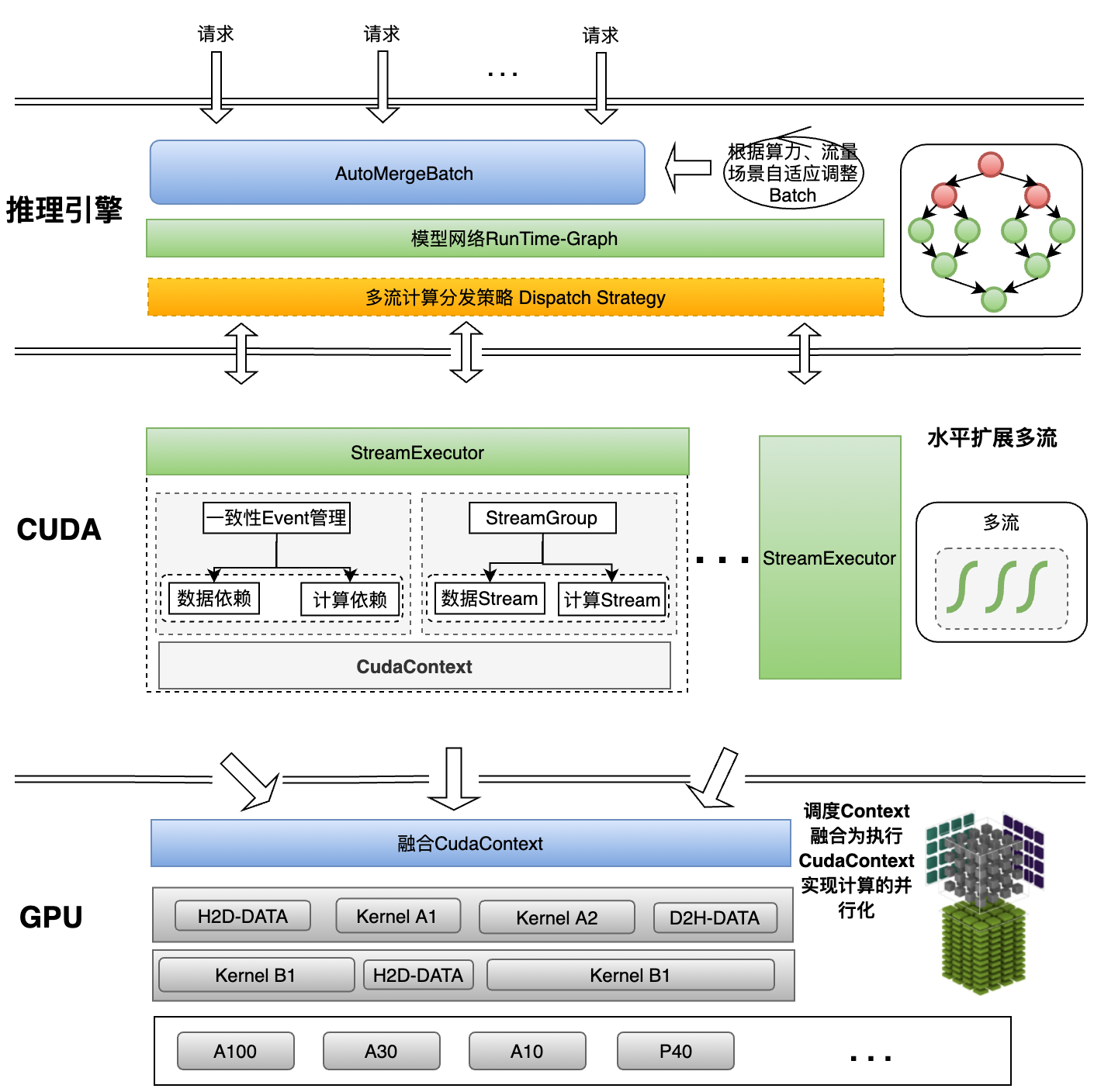
我们在之前使用了很多缓冲了:颜色缓冲、深度缓冲、模板缓冲。这些缓冲结合起来叫做帧缓冲,
其实也能从名字理解,每一帧屏幕都需要不断更新画面,对应的缓冲也需要更新。
不过上面这些都是在默认的缓冲里面做的,现在我们可以自定义帧缓冲方式。
创建帧缓冲
和之前的VBO一样,我们生成VBO需要通过glGenBuffer,帧缓冲也一样
unsigned int fbo;
glGenFramebuffers(1, &fbo);//生成
glBindFramebuffer(GL_FRAMEBUFFER, fbo);//绑定不过还不能用,一个完整的帧缓冲需要满足以下的条件:
- 附加至少一个缓冲(颜色、深度或模板缓冲)。
- 至少有一个颜色附件(Attachment)。
- 所有的附件都必须是完整的(保留了内存)。
- 每个缓冲都应该有相同的样本数。
在完成了所有附加之后可以调用一个检查函数来检查是否完整。
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE)
// 执行胜利的舞蹈不过还记得我们有个默认的帧缓冲吗,我们自定义的叫做离屏渲染off-screen rendering,要保证所有的渲染操作在主窗口中有视觉效果,我们需要再次激活默认帧缓冲,将它绑定到0。
glBindFramebuffer(GL_FRAMEBUFFER, 0);
。。。glDeleteFramebuffers(1, &fbo);用完之后记得删除。
添加一个纹理附件
和之前创建一个纹理差不多
unsigned int texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);这里注意,没有给纹理的data参数传东西。也就是分配了内存但是没有填充他。而填充纹理将会在我们渲染到帧缓冲中进行。同样注意我们并不关心环绕方式或多级渐远纹理,我们在大多数情况下都不会需要它们。
创建完最后一件事就是附加到帧缓冲上。
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texture, 0);
渲染缓冲对象附件
渲染缓冲对象(Renderbuffer Object)是在纹理之后引入到OpenGL中,作为一个可用的帧缓冲附件类型的,所以在过去纹理是唯一可用的附件。和纹理图像一样,渲染缓冲对象是一个真正的缓冲,即一系列的字节、整数、像素等。渲染缓冲对象附加的好处是,它会将数据储存为OpenGL原生的渲染格式,它是为离屏渲染到帧缓冲优化过的。
渲染缓冲对象直接将所有的渲染数据储存到它的缓冲中,不会做任何针对纹理格式的转换,让它变为一个更快的可写储存介质。然而,渲染缓冲对象通常都是只写的,所以你不能读取它们(比如使用纹理访问)。当然你仍然还是能够使用glReadPixels来读取它,这会从当前绑定的帧缓冲,而不是附件本身,中返回特定区域的像素。因为它的数据已经是原生的格式了,当写入或者复制它的数据到其它缓冲中时是非常快的。所以,交换缓冲这样的操作在使用渲染缓冲对象时会非常快。我们在每个渲染迭代最后使用的glfwSwapBuffers,也可以通过渲染缓冲对象实现:只需要写入一个渲染缓冲图像,并在最后交换到另外一个渲染缓冲就可以了。渲染缓冲对象对这种操作非常完美。
创建一个渲染缓冲对象吧
unsigned int rbo;
glGenRenderbuffers(1, &rbo);
..
glBindRenderbuffer(GL_RENDERBUFFER, rbo);//绑定然后对于深度和模板缓冲来说,我们不需要去读取值,我们只是应用和写入缓冲。刚刚也说了渲染缓冲对象一般是只写的,所以很适合深度和模板。现在来给我们的渲染缓冲加上深度和模板缓冲。
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);//生成
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);//附加渲染缓冲对象能为你的帧缓冲对象提供一些优化,但知道什么时候使用渲染缓冲对象,什么时候使用纹理是很重要的。通常的规则是,如果你不需要从一个缓冲中采样数据,那么对这个缓冲使用渲染缓冲对象会是明智的选择。如果你需要从缓冲中采样颜色或深度值等数据,那么你应该选择纹理附件。性能方面它不会产生非常大的影响的。
实战
我们将会将场景渲染到一个附加到帧缓冲对象上的颜色纹理中,之后将在一个横跨整个屏幕的四边形上绘制这个纹理。这样视觉输出和没使用帧缓冲时是完全一样的,但这次是打印到了一个四边形上。
首先在main中创建framebuffer和rbo
//生成并绑定
unsigned int framebuffer;
glGenFramebuffers(1, &framebuffer);
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);
//生成纹理并作为一个颜色附件加到帧缓冲上
unsigned int texColorBuffer;
glGenTextures(1, &texColorBuffer);
glBindTexture(GL_TEXTURE_2D, texColorBuffer);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glBindTexture(GL_TEXTURE_2D, 0);//解绑
//附加到帧缓冲对象上
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texColorBuffer, 0);
//创建RBO 并且给他一个深度缓冲和模板缓冲
unsigned int rbo;
glGenRenderbuffers(1, &rbo);
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8,800,600);
glBindRenderbuffer(GL_RENDERBUFFER, 0);//为渲染缓冲对象分配了足够的内存之后,我们可以解绑这个渲染缓冲
//最后把完成的rbo加到帧缓冲上
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
//检查
if (glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)
std::cout << "ERROR::FRAMEBUFFER:: Framebuffer is not complete!" << std::endl;
glBindFramebuffer(GL_FRAMEBUFFER, 0);然后给我们的帧缓冲新写一套shader
#version 330 core
layout(location = 0) in vec2 aPos;
layout(location = 1) in vec2 aTexCoords;
out vec2 TexCoords;
void main(){
gl_Position = vec4( aPos.x , aPos.y , 0.0 , 1.0 );
TexCoords = aTexCoords;
}
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D screenTexture;
void main(){
FragColor = texture(screenTexture,TexCoords);
}给新场景绑上VAO
//screen quad VAO
unsigned int quadVAO, quadVBO;
glGenVertexArrays(1, &quadVAO);
glBindVertexArray(quadVAO);
glGenBuffers(1, &quadVBO);
glBindBuffer(GL_ARRAY_BUFFER, quadVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(quadVertices), &quadVertices, GL_STATIC_DRAW);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)0);
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)(2 * sizeof(float)));
然后就是主体循环中,
while (!glfwWindowShouldClose(window))
{
//Process Input
processInput(window);
//第一阶段,渲染自己建立的fbo
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);
//Clear Screen
glClearColor(0.0f, 0.0f, 0.0f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
....画方块部分...
//第二阶段渲染到默认的帧缓冲,绘制四边形
glBindFramebuffer(GL_FRAMEBUFFER, 0);//恢复默认
//glPolygonMode(GL_FRONT_AND_BACK, GL_LINE);
glClearColor(1.0f, 1.0f, 0.0f, 0.0f);
glClear(GL_COLOR_BUFFER_BIT);
screenShader->use();
glBindVertexArray(quadVAO);
glBindTexture(GL_TEXTURE_2D, texColorBuffer);
glDisable(GL_DEPTH_TEST);
glUniform1i(glGetUniformLocation(screenShader->ID, "screenTexture"), 0);
glDrawArrays(GL_TRIANGLES, 0, 6);
glEnable(GL_DEPTH_TEST);
//Clean up prepare for next render loop
glfwSwapBuffers(window);
glfwPollEvents();
//Recording the time
float currentFrame = glfwGetTime();
deltaTime = currentFrame - lastFrame;
lastFrame = currentFrame;
}当在画第二部分的时候开启线框模式
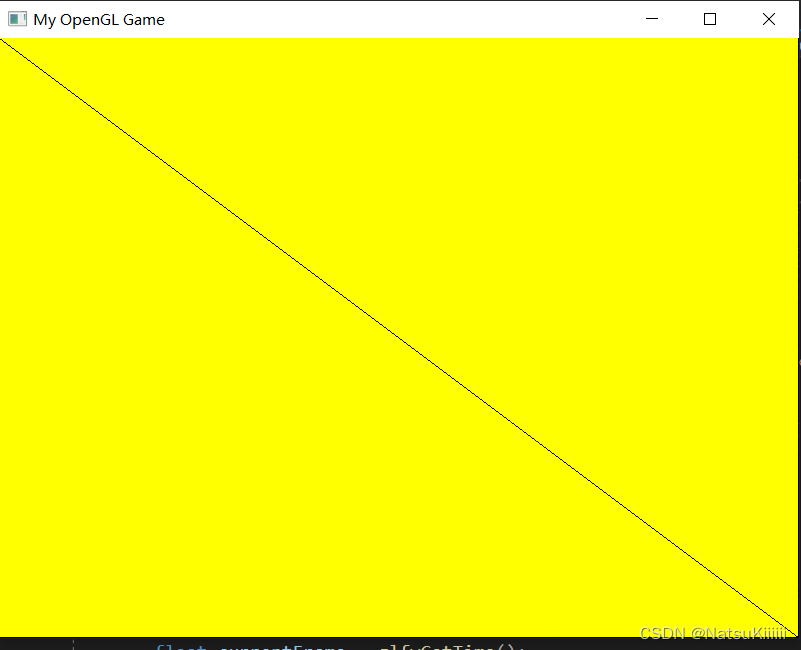
不开启的时候就是之前的场景。
要注意一些事情。第一,由于我们使用的每个帧缓冲都有它自己一套缓冲,我们希望设置合适的位,调用glClear,清除这些缓冲。第二,当绘制四边形时,我们将禁用深度测试,因为我们是在绘制一个简单的四边形,并不需要关系深度测试。在绘制普通场景的时候我们将会重新启用深度测试
所以这个有什么用处呢?因为我们能够以一个纹理图像的方式访问已渲染场景中的每个像素,我们可以在片段着色器中创建出非常有趣的效果。这些有趣效果统称为后期处理(Post-processing)效果。
后期处理
既然整个场景都被渲染到了一个纹理上,我们可以简单地通过修改纹理数据创建出一些非常有意思的效果。在这一部分中,我们将会向你展示一些流行的后期处理效果,并告诉你改如何使用创造力创建你自己的效果。
让我们先从最简单的后期处理效果开始。
反相
把screen片段着色器里面修改一下
FragColor = vec4(vec3(1.0-texture(screenTexture,TexCoords)),1.0);
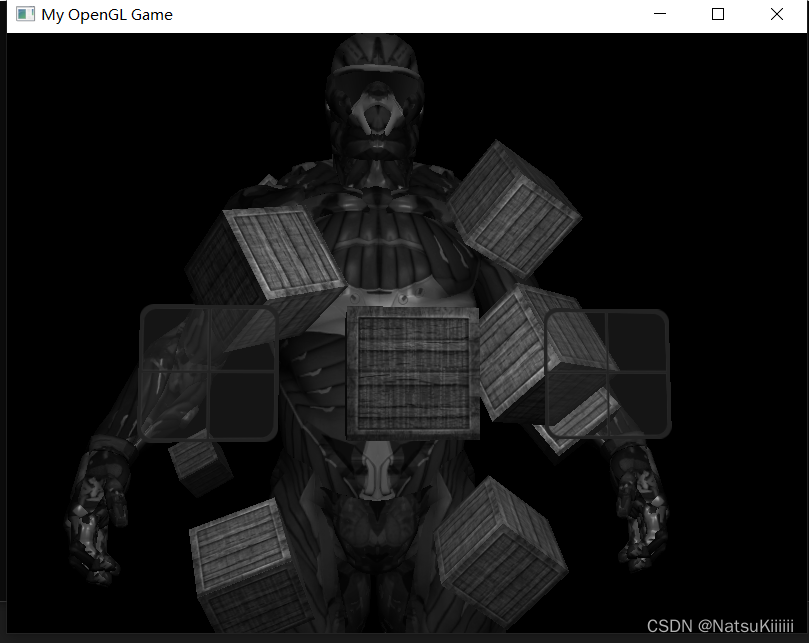
灰度
void main()
{
FragColor = texture(screenTexture, TexCoords);
float average = 0.2126 * FragColor.r + 0.7152 * FragColor.g + 0.0722 * FragColor.b;
FragColor = vec4(average, average, average, 1.0);
}
核效果
核效果其实就是类似与图像处理里面的卷积核效果,用一个3x3的方块去扫每一个像素点,然后把9个方块的像素rgb加权到中间的像素去。可以用来做模糊处理或者一些特性提取工作。

在片段着色器中,我们首先为周围的纹理坐标创建了一个9个vec2偏移量的数组。偏移量是一个常量,你可以按照你的喜好自定义它。之后我们定义一个核,在这个例子中是一个锐化(Sharpen)核,它会采样周围的所有像素,锐化每个颜色值。最后,在采样时我们将每个偏移量加到当前纹理坐标上,获取需要采样的纹理,之后将这些纹理值乘以加权的核值,并将它们加到一起。
//核函数
vec2 offsets[9] = vec2[](
vec2(-offset, offset), // 左上
vec2( 0.0f, offset), // 正上
vec2( offset, offset), // 右上
vec2(-offset, 0.0f), // 左
vec2( 0.0f, 0.0f), // 中
vec2( offset, 0.0f), // 右
vec2(-offset, -offset), // 左下
vec2( 0.0f, -offset), // 正下
vec2( offset, -offset) // 右下
);
float kernel[9] = float[](
-1, -1, -1,
-1, 9, -1,
-1, -1, -1
);
vec3 sampleTex[9];
for(int i = 0; i < 9; i++)
{
sampleTex[i] = vec3(texture(screenTexture, TexCoords.st + offsets[i]));
}
vec3 col = vec3(0.0);
for(int i = 0; i < 9; i++)
col += sampleTex[i] * kernel[i];
FragColor = vec4(col, 1.0); 
模糊
修改核函数可以实现不同的效果
float kernel[9] = float[](
1.0 / 16, 2.0 / 16, 1.0 / 16,
2.0 / 16, 4.0 / 16, 2.0 / 16,
1.0 / 16, 2.0 / 16, 1.0 / 16
);
也可以把时间加入到效果中,创造出玩家醉酒时的效果,或者在主角没带眼镜的时候增加模糊。模糊也能够让我们来平滑颜色值
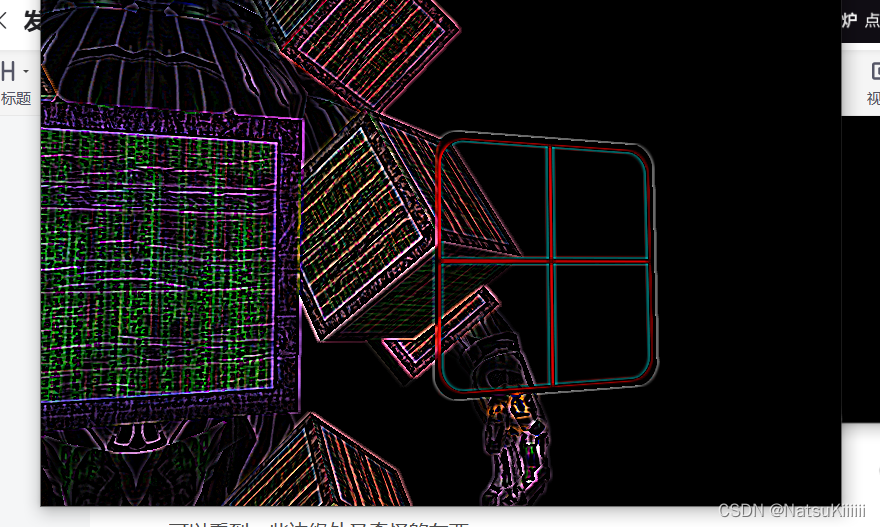
边缘检测


一些tips:
注意,核在对屏幕纹理的边缘进行采样的时候,由于还会对中心像素周围的8个像素进行采样,其实会取到纹理之外的像素。由于环绕方式默认是GL_REPEAT,所以在没有设置的情况下取到的是屏幕另一边的像素,而另一边的像素本不应该对中心像素产生影响,这就可能会在屏幕边缘产生很奇怪的条纹。为了消除这一问题,我们可以将屏幕纹理的环绕方式都设置为GL_CLAMP_TO_EDGE。这样子在取到纹理外的像素时,就能够重复边缘的像素来更精确地估计最终的值了。
我做了一些测试:当时默认的repeat的时候边缘是这样的

可以看到一些边缘处又奇怪的东西
改成clamp_to_edge 就没有了


![WebAssembly核心编程[1]:wasm模块实例化的N种方式](https://img-blog.csdnimg.cn/img_convert/43a2802e9d0fd08c6e4ebf1e472906e7.png)