一、HBase简介
1.1、HBase是什么
Google在200-2006发表了GFS、MapReduce、BigTable三篇
论文
,号称“三驾马车”,开启了大数据的时代。
GFS是Google File System,开源实现是HDFS(Hadoop File System)。
MapReduce计算框架的开源实现是Hadoop MapReduce。
BigTable的开源实现的实现是HBase(Hadoop DataBase)。
Hadoop解决了海量数据的存储问题,HBase底层存储基于Hadoop,除了可以存储海量数据外,还解决了海量数据的随机查询问题。
1.2、HBase优缺点
1)HBase优点
- 海量存储:HBase单表可以存储千亿行、百万列的数据规模,数据容量可以达到TB甚至PB。
- 支持动态扩缩容:主要包括存储节点和读写服务节点扩展。HBase底层存储基于Hadoop,存储节点可以通过增加DataNode实现扩展。读写服务节点可以通过增加RegionServer实现扩展。
- 列式存储:每个列族会有多个列,每个列族单个文件存储,可独立权限控制和查询。
- 无模式:HBase的列可以根据需求动态增加,同一个表不同行可以有截然不同的列。
- 数据自动过期:HBase列族可设置TTL,超过TTL的数据就会自动清理
- 数据多版本:HBase支持多版本特性,用户可以根据需要选择最新版本或者历史版本
2)HBase缺点
- HBase只支持简单分页。可通过scan的startRow和limit实现简单分页,但因为需要startRow,所以只支持上一页和下一页,不支持直接跳到某一页。
- HBase不支持复杂的聚合运算,比如说Join、GroupBy、查询总数等。
- HBase不支持事务。
- HBase不支持二级索引,HBase只支持rowkey精确查询或者前缀查询走索引,其它都是全表扫描。如果需要实现这种功能,需要引入第三方方案(Phoenix等)。
1.3、HBase数据模型
1)HBase表逻辑结构

2)HBase表物理存储结构
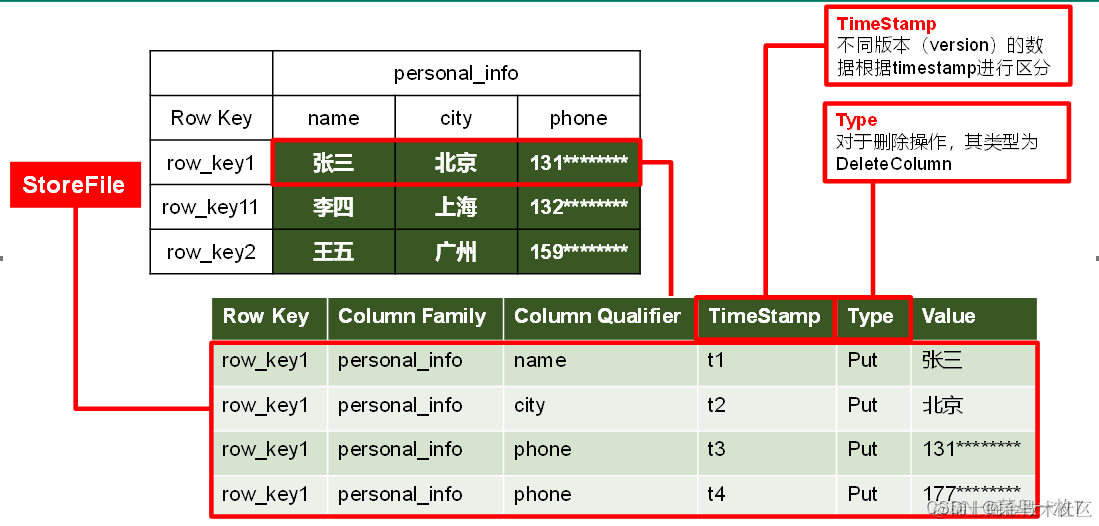
3)HBase数据模型
- Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
- Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此和关系型数据库相比,HBase能够轻松应对字段变更的场景。
- Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
- Column
HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
- Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。
- Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元
1.4、HBase、MongoDB、Redis、ES对比

二、HBase架构
2.1、HBase架构介绍


2.2、HBase物理存储
1)、Table在行的方向上分割为多个Region,每个Region分散在不同的RegionServer中。

2)、每个Region由多个Store构成,每个Store由一个memStore和0或多个StoreFile组成,每个Store保存一个列族。

HBase表和region关系总结

2.3、定位rowkey所在的region
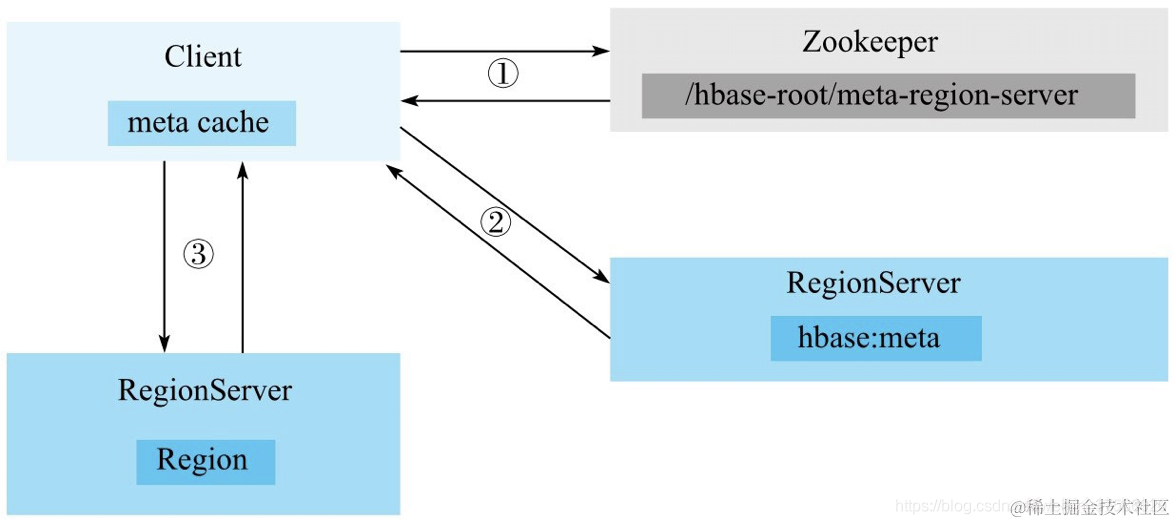
1)、先读取zk的/hbase/meta-region-server节点信息,获取meta表所在的RegionServer
meta表其实就是HBase表,但未分片(只有一个region)
meta表rowkey主要是table,startKey,列信息主要是Regionserver所在的在服务器及端口
2)、根据rowkey在meta表中查询所在的Regionserver服务器及端口
3)、客户端向该RegionServer发送真正的数据读写请求
2.4、HBase写过程
1)、根据rowkey在meta表中查询所在的Regionserver服务器及端口,向该RegionServer发送写请求
2)、先把数据写入到 HLog,以防止数据丢失。
3)、 然后将数据写入到 Memstore。
4)、如果memstore达到阈值,会把memstore中的数据flush到StoreFile 中
memstore刷新时机
a、单个memstroe大小达到阀值hbase.hregion.memstore.flush.size(默认值128M)
b、memstore总大小达到总内存的40%。hbase.regionserver.global.memstore.upperLimit(默认值0.4)
c、到达自动刷新时间hbase.regionserver.optionalcacheflushinterval(默认1小时)
5)、当Storefile越来越多,会触发合并操作
合并分两种:小合并和大合并
小合并:选取一些小的、相邻的Storefile将他们合并成一个更大的Storefile,这个过程还会清理部分TTL过期数据
大合并:合并Store中所有的Storefile为一个Storefile,这个过程还会清理所有TTL过期数据
6)、当Region 也会越来越大,达到阈值后,会触发 Split 操作,将 Region 一分为二。
region切分时机:min(256M*region数量^3 ,10G) 。具体的切分策略为:
第一次split:1^3 * 256 = 256MB
第二次split:2^3 * 256 = 2048MB
第三次split:3^3 * 256 = 6912MB
第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了。
三、HBase shell
- 创建表
create 'user_info', {NAME=>'base_info'}, {NAME=>'credit_info',TTL=>'86400'}
- 创建表
drop 'user_info'
- 更新表
alter 'user_info', {NAME=>'education_info'}
- 新增数据
put 'user_info', 'u001', 'base_info:name', 'zhang san'
- 删除数据
deleteall 'user_info', 'u001'
- 查询数据
get 'user_info','u001'
get 'user_info','u001','base_info'
get 'user_info','u001','base_info'
- 分页查询
scan 'user_info', {FILTER=>"PageFilter(10)", STARTROW=>''u0010}
四、HBase使用注意事项
4.1、rowkey设计
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了 scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于 scan读取。但也容易引发热点问题,比如说rowkey如果是递增的话,新增的数据会集中到一个region里面。所以rowkey设计要遵循以下原则
- 唯一原则:必须在设计上保证其唯一性
- 长度原则:100字节以内,8的倍数最好,可能的情况下越短越好
- 散列原则:高位散列,避免热点问题
高位散列如何做?
- 加盐:在rowkey的前面增加随机数,使得它和之前的rowkey的开头不同。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
- 反转:这样可以使得rowkey中经常改变的部分放在前面,这样可以有效的随机rowkey。以递增用户号为rowkey,这种情况是不能在用户号前面增加随机数,但可以将用户号反转后的字符串作为rowkey,这样的就避免了以递增用户号导致热点的问题
4.2、预分片
预分片可以解决以下问题
- 负载均衡。当一个table刚被创建的时候,HBase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个RegionServer的同一个region中,这个时候就达不到负载均衡的效果
- 避免region切分、自动平衡导致系统波动。
预分片如何做?
create 'user_info', {NAME=>'base_info'}, {NAME=>'credit_info',TTL=>'86400'} ,SPLITS => ['100000000','200000000','300000000','400000000']
4.3、namespace
HBase没有database概念,创建的表可以不指定namespace,默认会放在default的namespace,在HBase不共用的时候没有问题。但如果共用的话,授权就会比较麻烦。所以创建表的时候,需要指定自定义的namespace