在大数据分析领域,Apache Doris 作为广受认可的开源实时数据仓库,已经在越来越多行业用户的真实业务场景中得到广泛应用,成为许多企业数据分析基础设施的重要基座。尤其在过去一年多的时间里,越来越多企业选择基于 Apache Doris 进行升级,将过去基于 Hadoop 体系的离线数据仓库进行实时化改造,或者基于 Apache Doris 统一 OLAP 技术栈。
在这一过程中,如何将海量历史数据进行高效迁移成为用户的痛点所在。基于这一目标,我们启动了名为“百川入海”的专项开发任务,开发了一站式海量数据迁移工具 X2Doris,集自动建表和数据迁移于一体、提供了对 Apache Hive、ClickHouse、Apache Kudu 以及 StarRocks 等多个数据源的支持,全程界面化、可视化操作,仅通过鼠标操作即可完成大规模数据同步至 Doris 中,并提供了极速和稳定的迁移体验。在经过数个月的公开测试和近百家企业的打磨后,今天我们很高兴地宣布, X2Doris 正式发布、面向所有社区用户免费下载使用,数据迁移至 Apache Doris 从未变得如此简单。
-
官网地址:https://www.selectdb.com/tools/x2doris
-
文档地址:https://docs.selectdb.com/docs/ecosystem/x2doris/x2doris-deployment-guide
-
交流学习:https://www.selectdb.com/blog/160
X2Doris 核心特性
多源支持
定位于一站式数据迁移工具, X2Doris 目前已支持了 Apache Hive、Apache Kudu、ClickHouse、StarRocks 以及 Apache Doris 自身作为数据源端,Greenplum、Druid 等更多数据源正在开发中,后续将陆续发布。其中 Hive 版本已支持 Hive 1.x 和 2.x 版本,Doris、StarRocks、Kudu 等数据源也同时支持了多个不同版本。
而目标端已支持 Apache Doris 和 SelectDB,包含 SelectDB Cloud 和 SelectDB Enterprise。基于 X2Doris 用户可以构建从其他 OLAP 系统到 Apache Doris 的整库迁移链路,并可以实现不同 Doris 集群间的数据备份和恢复。
自动建表
在项目立项之初,我们深入调研和分析了用户对于数据迁移的痛点以及业内同类数据集成工具,其中首当其冲的便是如何将待迁移的源表在 Apache Doris 中创建对应的目标表,在实际业务场景中,存储在 Hive 或 ClickHouse 中动辄上千张表,让用户手动创建目标表并转换对应的 DDL 语句效率显得过于低下,不具备实际操作可能性。
X2Doris 特为此场景做了适配,在此以 Hive 表迁移为例。在迁移 Hive 表的时候,X2Doris 会在 Apache Doris 中自动创建 Duplicate Key 模型表(也可手动修改)并读取 Hive 表的元数据信息,通过字段名和字段类型自动识别分区字段,如果识别到分区则会提示进行分区映射,最后会直接生成对应的 Doris 目标表 DDL。
在上游数据源为 Doris/StarRocks 时,X2Doris 会自动根据源表信息解析出表模型,自动根据源表字段类型映射对应的目标字段类型,针对上游的 Properties 参数也会识别处理,转换成对应目标表的属性参数。除此以外,X2Doris 还对复杂类型进行了增强,实现了对 Array、Map、Bitmap 类型的数据迁移。
极速稳定
在数据写入方面,X2Doris 特别针对读取数据进行了优化。通过优化数据攒批逻辑进一步减小了内存的使用,同时对 Stream Load 写入请求进行了大量改进和增强,对内存使用和释放进行优化,进一步提升数据迁移的速度和稳定性。
在单机 1G 内存情况下,我们对 DataX 和 X2Doris 进行了对比测试,5000w 条采取 DataX 进行全量数据同步,耗时约为 90s,而 X2Doris 仅需 50s 不到、性能提升接近 100%。而对比其他同类型的迁移工具,X2Doris 性能约比同类工具快 2-10 倍。
在此我们以国内某头部行业公司 POC 效果为例,在大规模日志数据迁移场景中,单条数据 1kb 大小、单表数据接近 1 亿条、总存储空间约 90 G,基于 X2Doris 仅需 2 分钟即可完成全表迁移,平均写入速度近 800 MB/s
X2Doris 安装使用
X2Doris 非常简单易用,解包启动即可,可在分钟内迅速使用起来。在部署 X2Doris 之前,需要确保机器可以连接要迁移的数据源和目标端,主要操作如下:
选择安装包
X2Doris 底层采用 Spark 实现,推荐部署到有 Yarn 的大数据环境中,可以充分利用大数据集群的能力,提高数据迁移的效率和速度,如果没有大数据环境也可以采取单机部署即可,下载与 Scala 版本对应的 X2Doris 安装包即可(没有 Spark 环境可以直接选择安装 Scala 2.12 的 X2Doris 版本)
初始化元数据
1. 将系统的数据库类型改成 mysql
进入到 conf 下,修改 application.yml 将 spring.profiles.action 改成 mysql,注意默认的 h2 是内存数据库,系统重启会导致数据丢失。
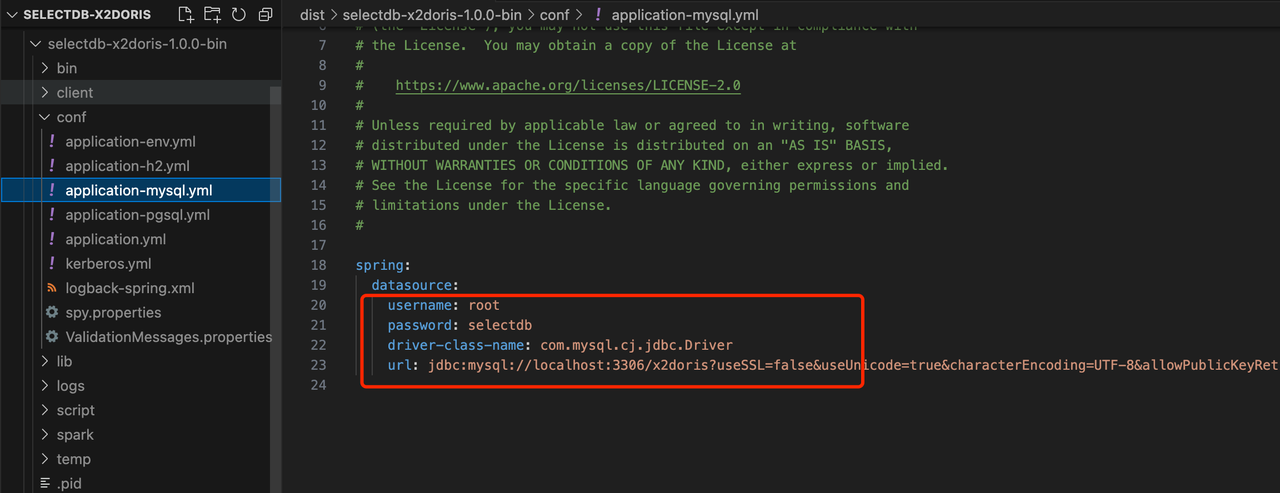
2. 修改conf/application-mysql.yml文件,指定 MySQL 的连接信息
3. 执行脚本
进入到 script 下有两个目录,分别是 schema 和 data:
- 先执行
schema下的mysql-schema.sql完成表结构的初始化 - 再执行
data下的mysql-data.sql完成元数据初始化
进入到 bin 目录下,执行 startup.sh
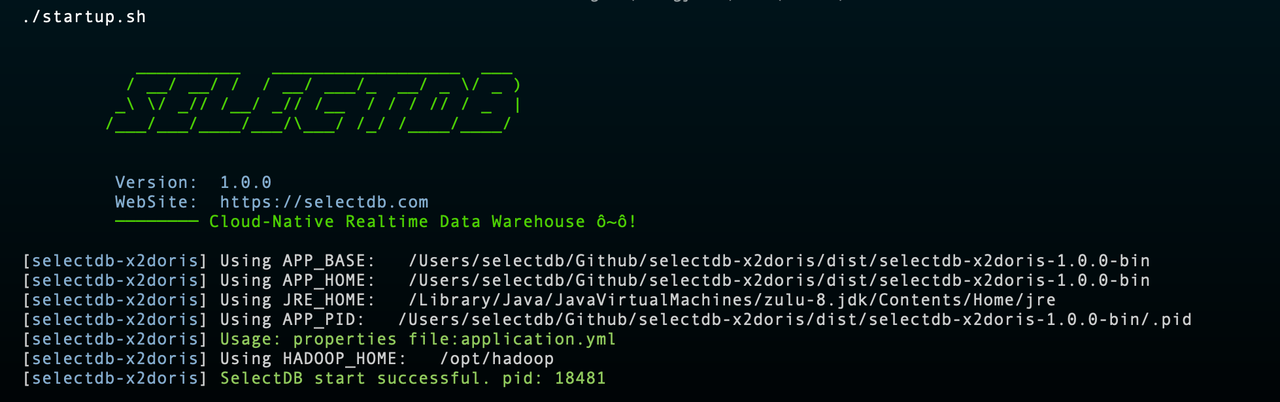
完成启动后即可登录到 X2Doris 中,访问地址: http://$host:9091 用户户名密码: admin/selectdb

Hive 数据迁移实践
在此我们以 Hive 迁移至 Doris 中作为示例,介绍 X2Doris 的完整使用流程。
前置要求
- 部署 X2Doris 的机器必须可以连接 Hadoop 集群,是 Hadoop 集群的一个节点或至少有 Hadoop Gateway 环境。(可以在该机器上执行 Hadoop/Hive 命令,能正常连接访问 Hadoop/Hive 集群)
- 部署 X2Doris 的机器必须配置了 Hadoop 环境变量,必须配置
HADOOP_HOME,HADOOP_CONF_DIR,HIVE_CONF_DIR,如:
export HADOOP_HOME=/opt/hadoop #hadoop 安装目录
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HIVE_CONF_DIR=$HADOOP_HOME/conf
export HBASE_HOME=$HADOOP_HOME/../hbase
export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
注意: 在 HADOOP_CONF_DIR 或 HIVE_CONF_DIR 下 必须要有 hive-site.xml
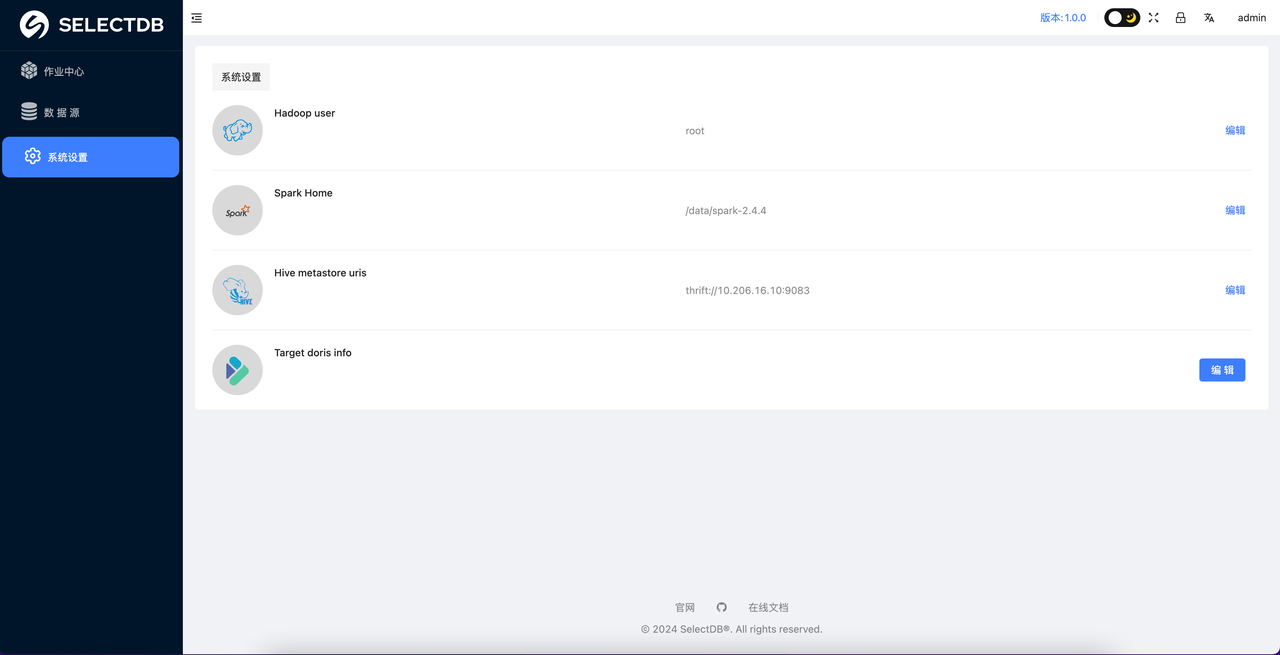
系统设置
Hive 需要设置以下信息,该部分参数都为必须要设置的参数, 具体如下:
Hadoop user: 该作业会访问 Hive 数据,该 Hadoop User 即为操作 Hive 表的 Hadoop 用户(日常 Hive 作业的操作用户即可);Spark Home: 指定部署机安装的 Spark 路径;Hive metastore Uri: Hive 的 Metastore uri,可以去 $HADOOP_CONF_DIR 下查找 hive-site.xml 的配置获取;目标 Doris/SelectDB: 要写入数据的目标端 Doris(SelectDB)信息
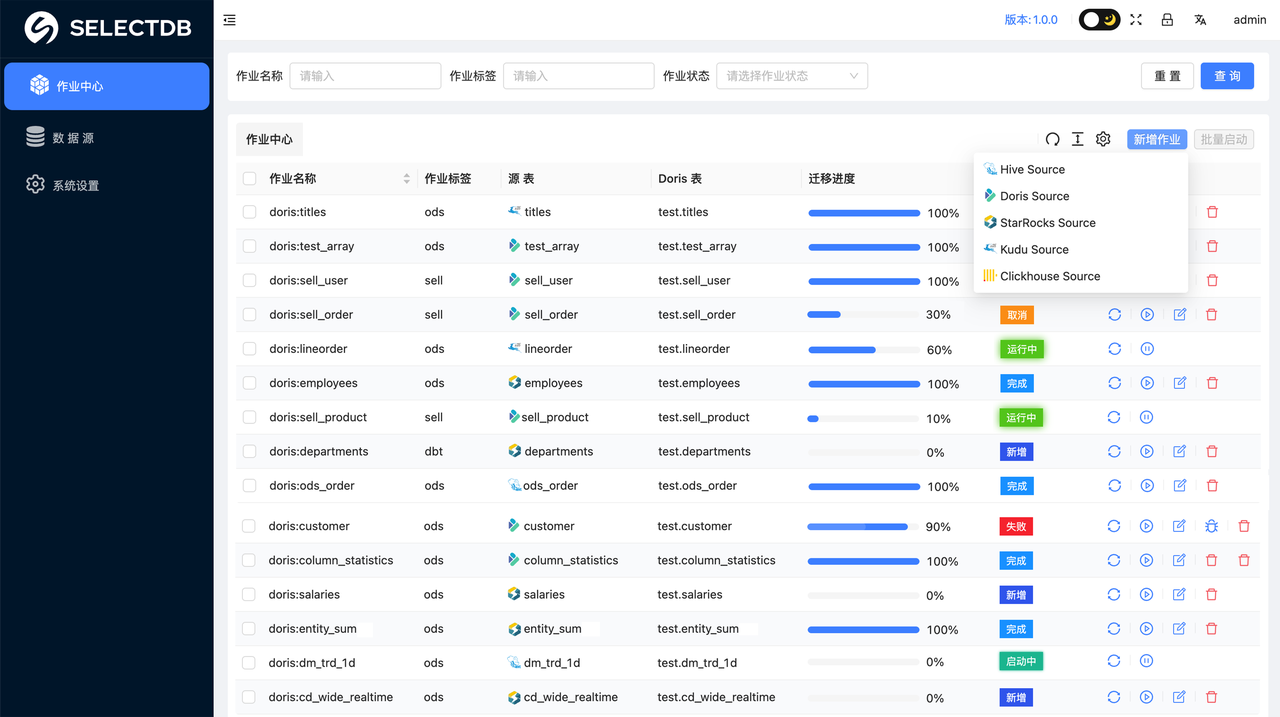
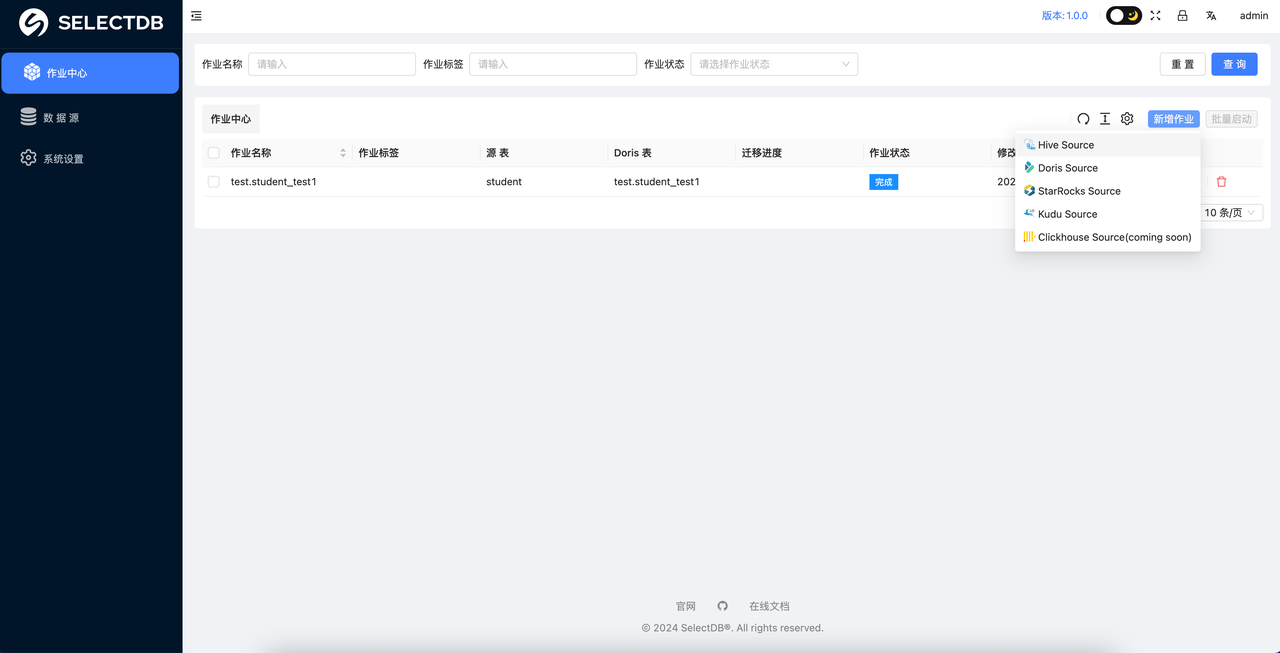
创建同步作业
系统设置完成之后,就可以进入到 作业中心 了,这里可以点击 添加 来创建一个作业:
在添加的时候会自动检测 Hive 环境的连接情况,如果 Hive 连接失败会告警:
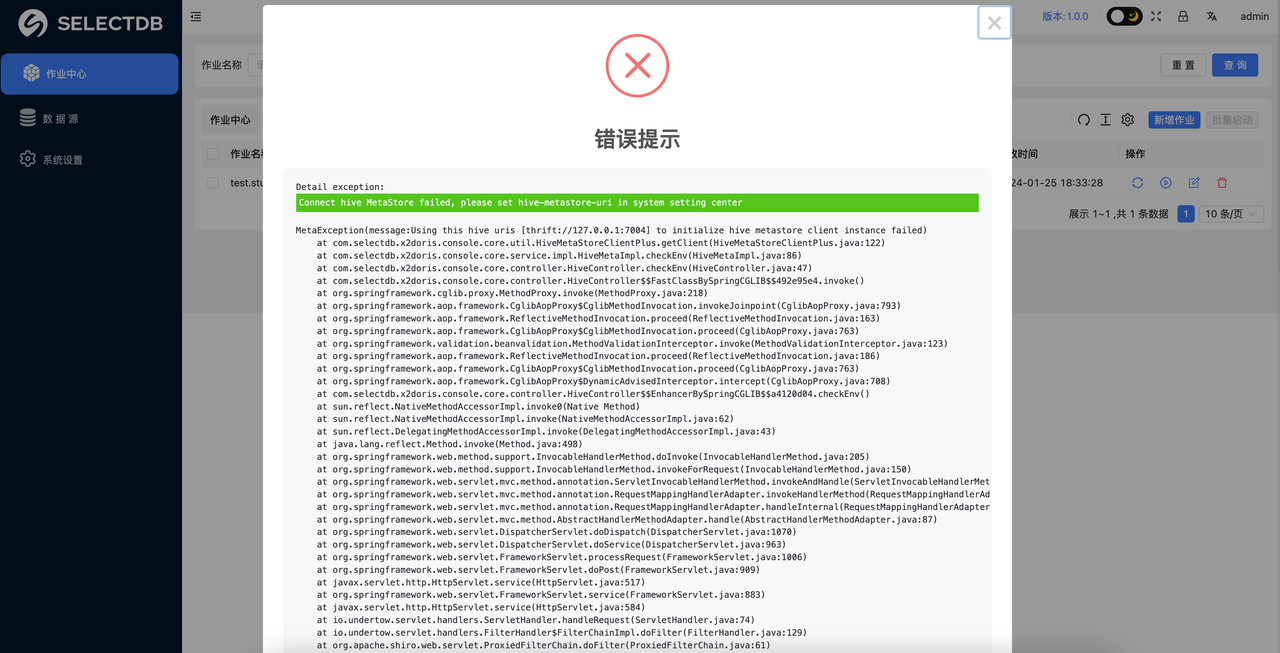
那么此时就需要检查: “系统设置” 里的 Hive metastore uris 和当前部署机的通讯是否正常,这一步必须要确保通过才可以进行后续的迁移工作,如果连接正常就可以直接进行新增作业。
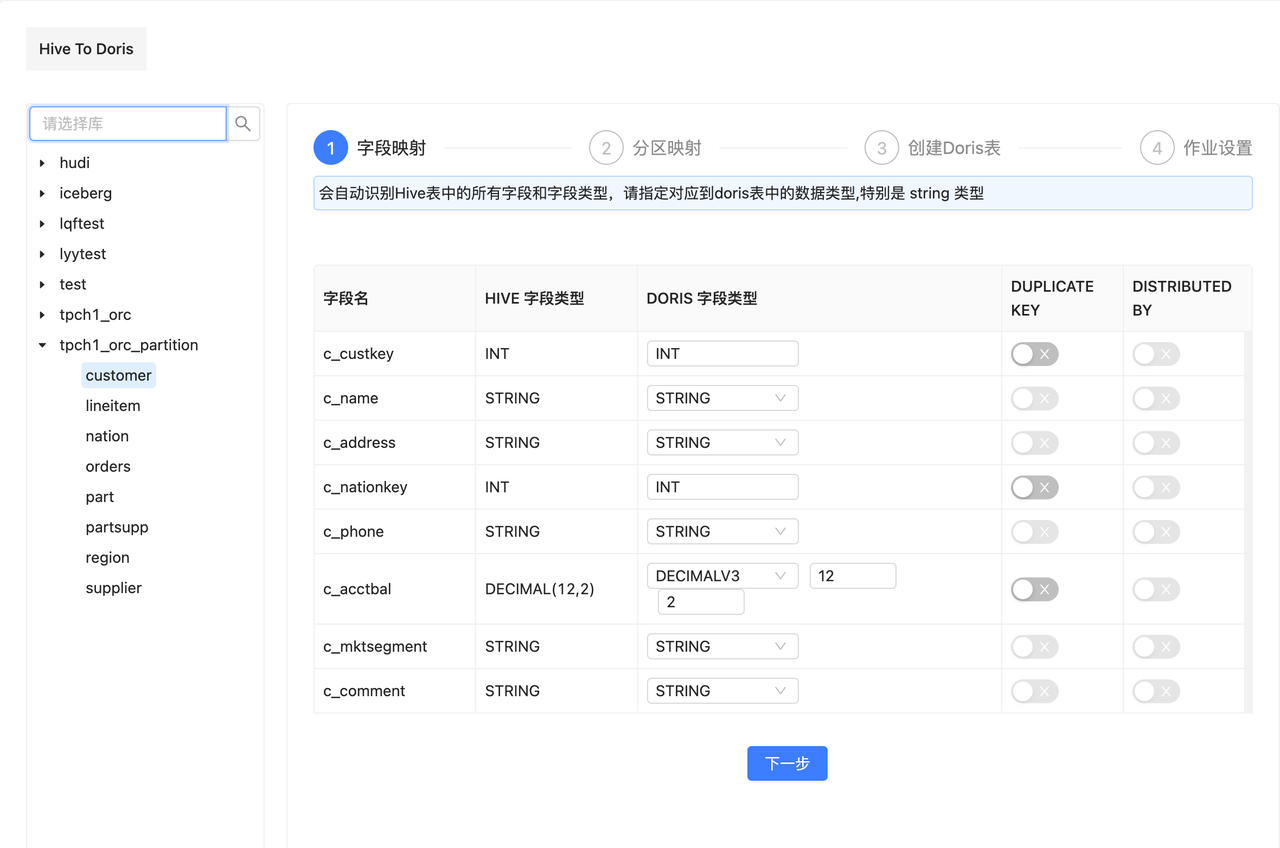
1. 字段类型映射
如果与 Hive 连接正常,就会自动把 Hive 数仓中所有的库和表都罗列出来。此时就可以点击左侧的树形目录,选择目标表进行操作,选中一个表之后,右侧会自动罗列出该表与 Doris 字段映射关系,可以很轻松地映射目标 Doris 表的字段类型,根据提示进行操作即可完成字段的映射。其中DUPLICATE KEY 和 DISTRIBUTED KEY 是 Doris Duplicate Key 模型中必须要指定的参数,按需进行指定即可。

注意
- 自动生成的 Doris DDL 建表语句为 Duplicate 模型, 可以根据实际情况手动修改;
STRING类型不能设置为DUPLICATE KEY, 需要将STRING类型改成VARCHAR类型即可;
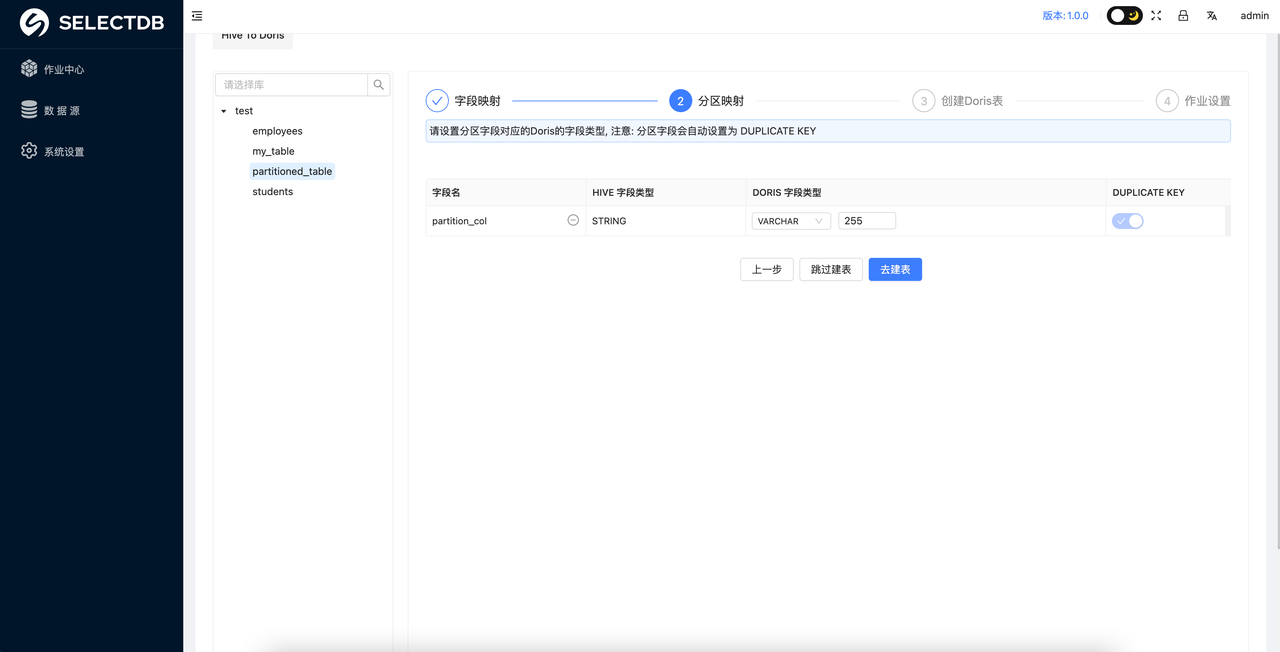
2. 分区映射
如果 Hive 原表中的分区字段类型是 STRING ,则可以根据数据实际类型判断是否需要将对应的 Doris 表的字段类型转成时间类型。如果转成时间类型的话,则需要设置分区的区间。
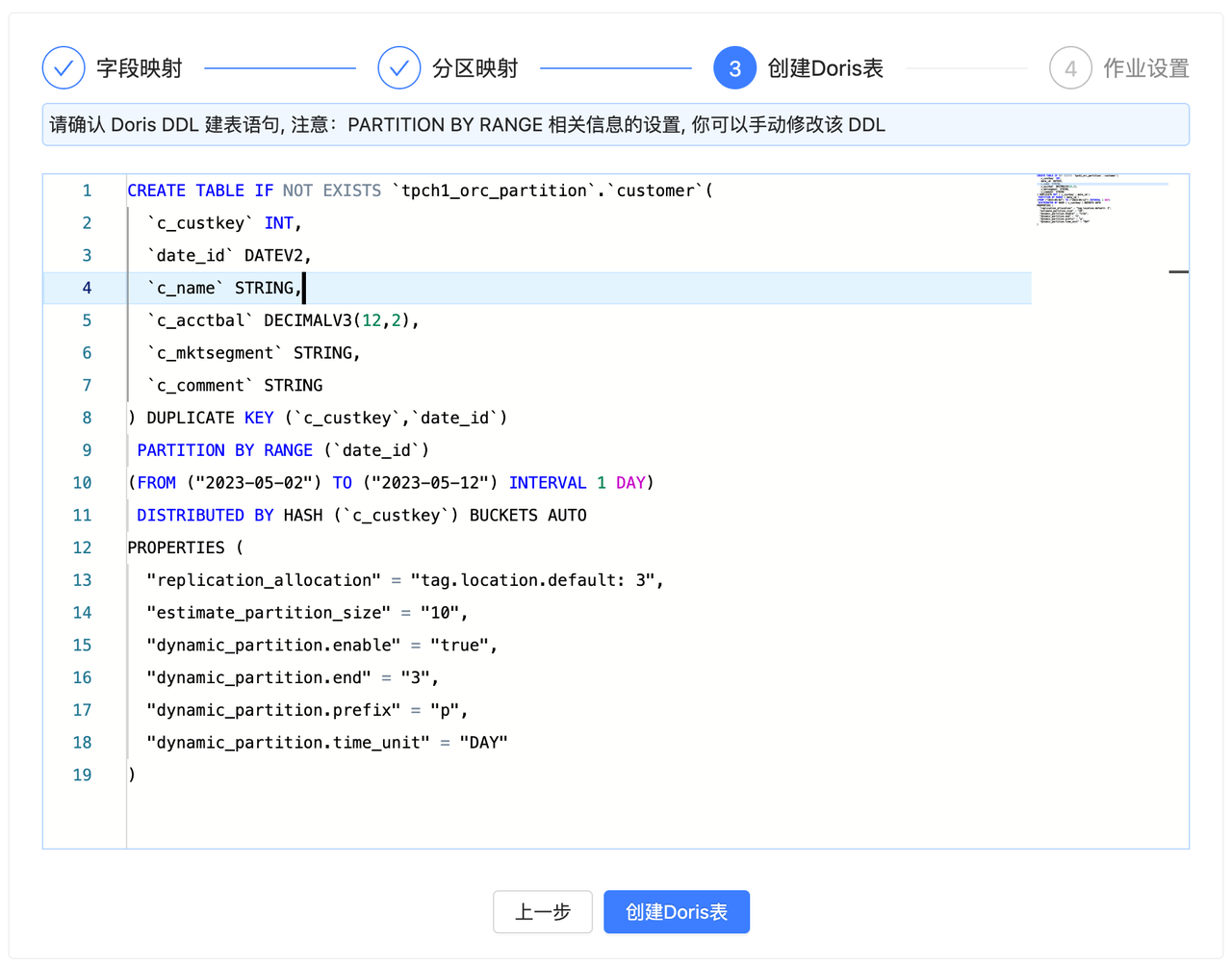
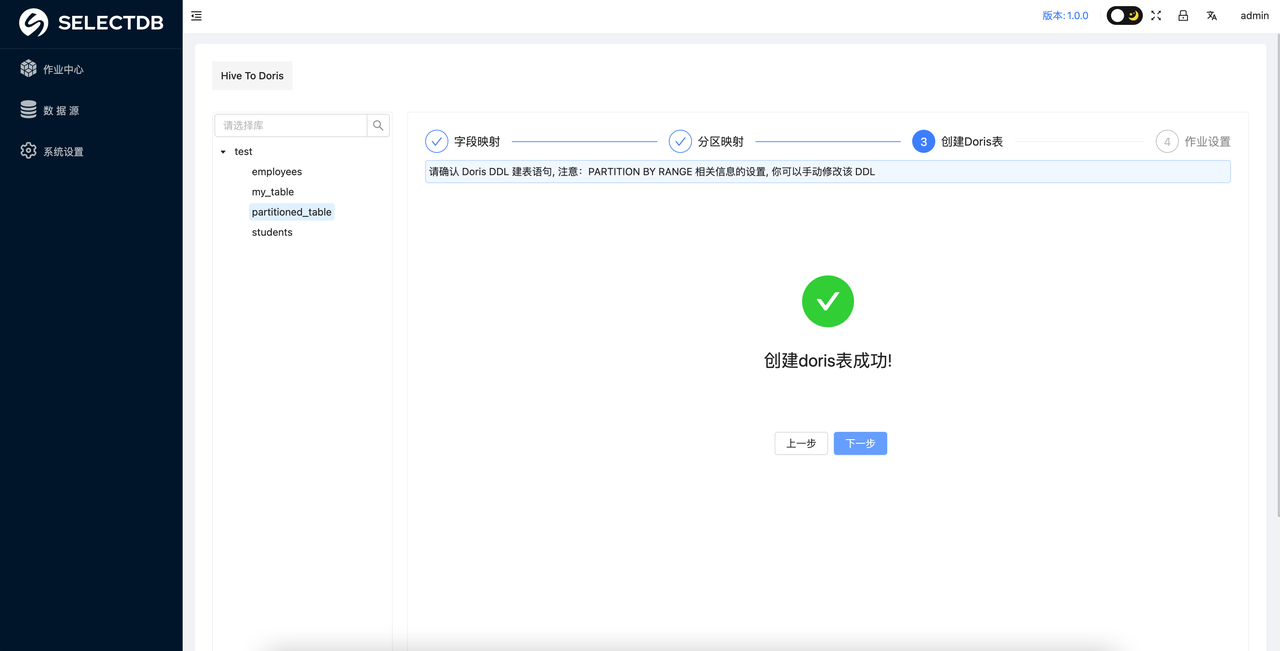
3. 创建 Doris 表
完成前两步即可进入到 Doris 表 DDL 的确认阶段,在该阶段已经自动生成了对应的 Doris 建表 DDL 语句,你可以进行 Review 确认并手动修改 DDL。
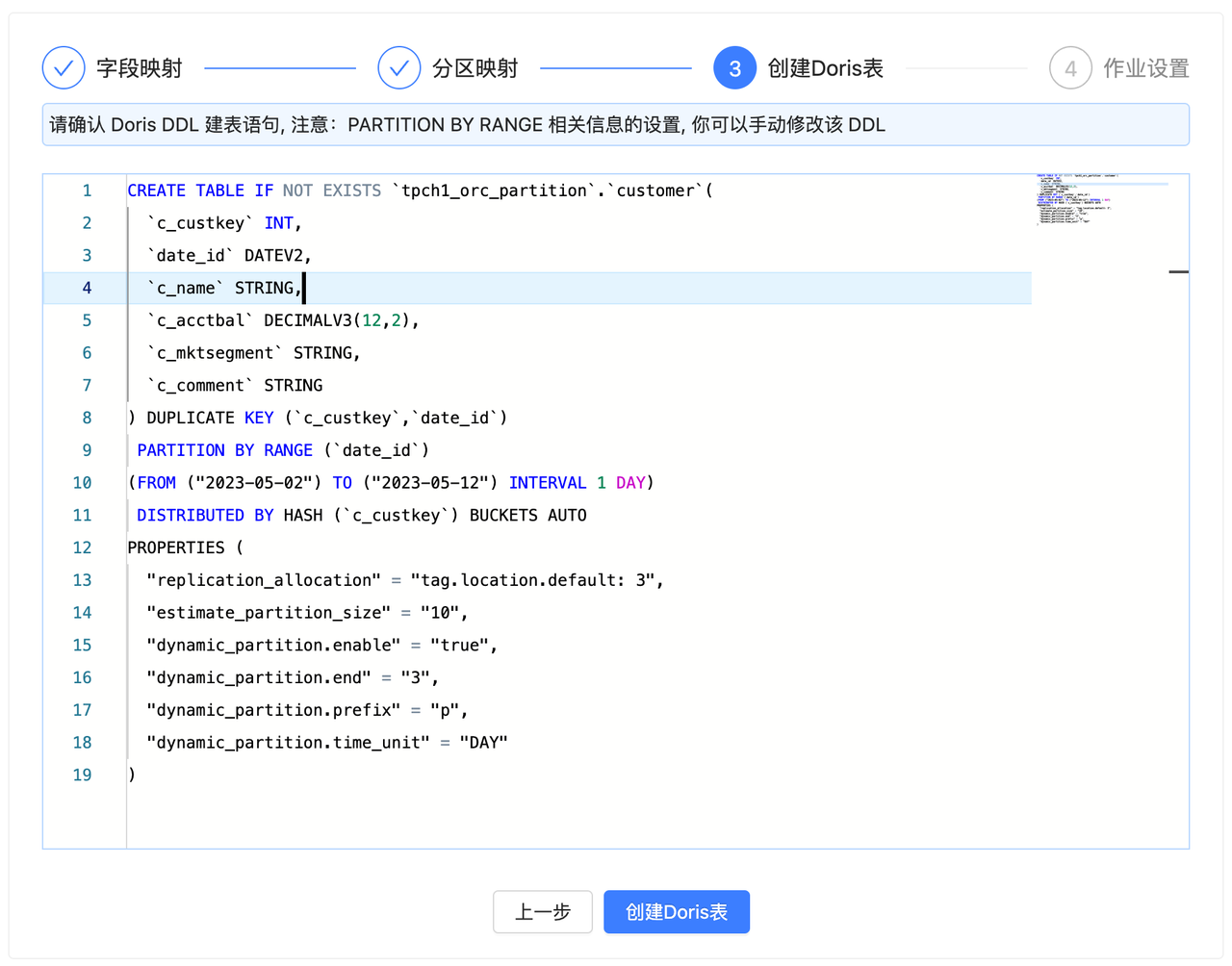
确认无误后,可以点击创建 Doris 表。
注意: 要确保对应 Doris 的库存在,库需要用户手动创建
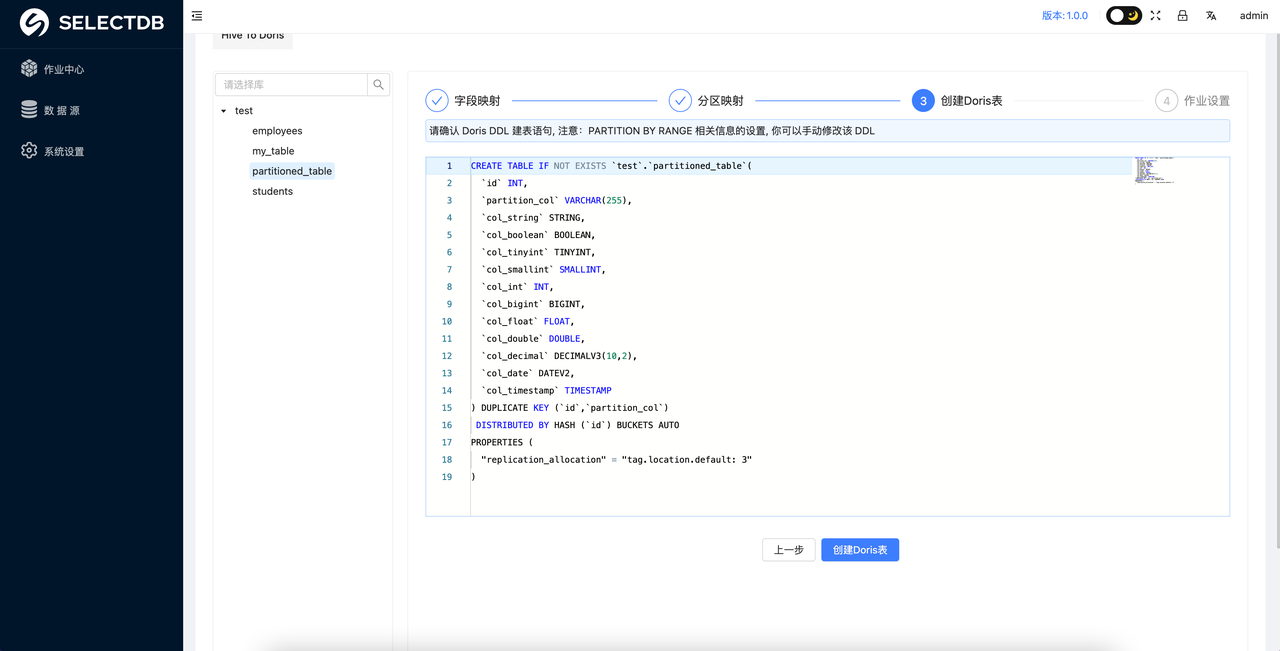
4. 作业设置
在点击创建作业之后会弹出一个任务配置的界面,用户需要在这个界面配置任务迁移所需要的参数,具体示例如下:
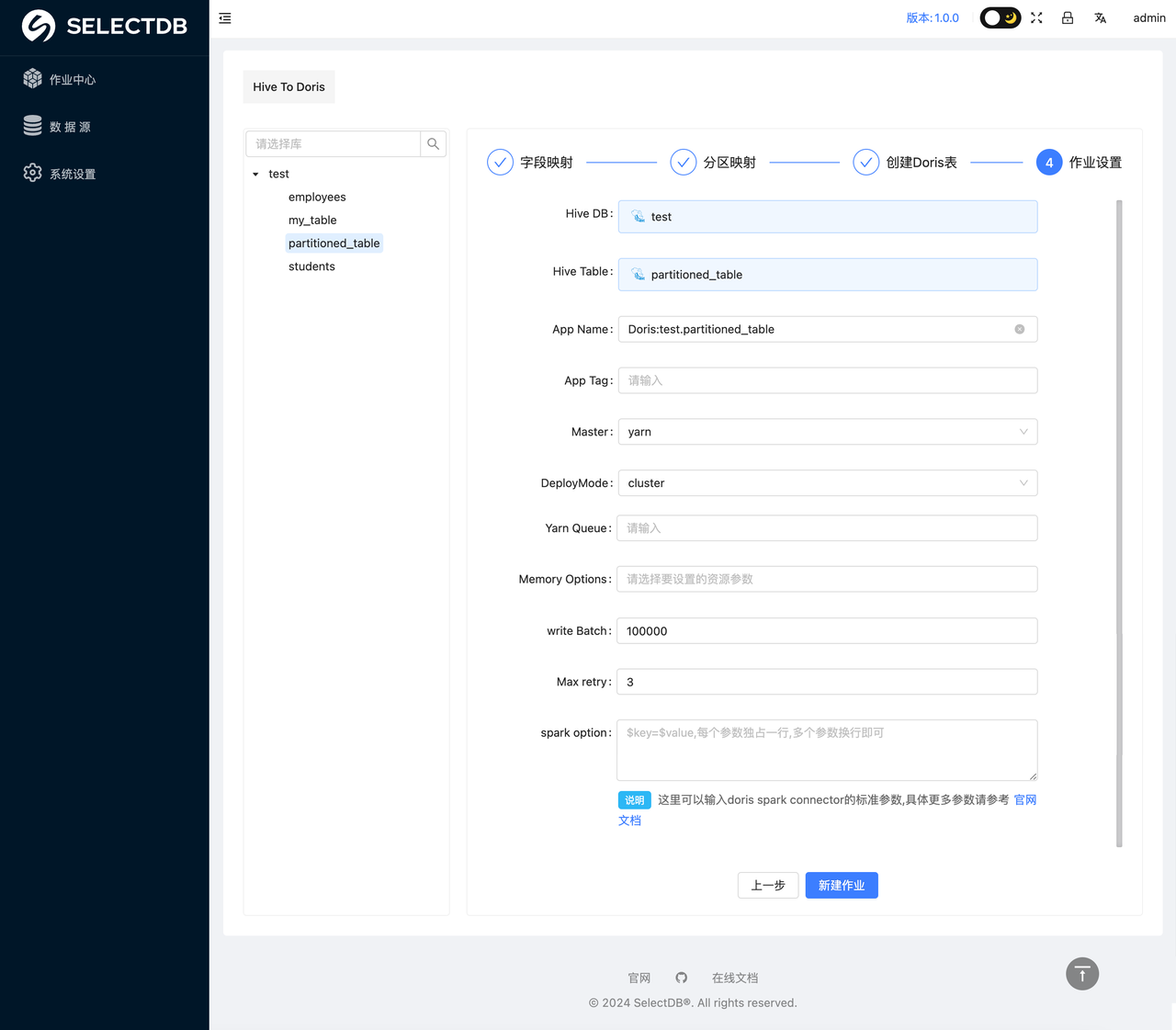
具体参数解释如下(重要参数已经加粗):
- Hive DB:自动生成,数据源的数据库名称
- Hive Table:自动生成,数据源的要迁移的表的名称
- App Name:自动生成,数据迁移任务的名称
- App Tag:自动生成,数据迁移任务的 Tag
- Master: 需要选择是 Local 模式还是 Yarn 模式,这里是指的 X2Doris 任务运行的方式,这个根据实际情况调整。
- DeployMode: 这里需要选择 Client 还是 Cluster,根据实际情况调整。
- Yarn Queue: Spark 任务运行所使用的队列资源
- Memory Options: 这里需要选择 Spark 任务的一些内存参数,如 Executor 和 Driver 的 Core 的数量和内存大小,这个根据实际情况进行调整。
- Write Batch: 数据刷写时的批次大小,这个可以根据实际数据量调整大小,如果迁移的数据量比较大,建议该值夜调整为 500000 以上
- Max retry:任务失败的重试次数,如果网络情况不理想,可以适当增大此参数
- Spark option: Spark 的自定义参数,如果需要增加 Spark 任务的其他参数,可以在这里添加,以
key=value的形式增加即可。 - Properties: 数据迁移时,如果有针对数据源读取或者 Doris 数据写入的一些优化参数,可以在这里编写,具体的参数描述可以看对应的 Spark Connector 的官方文档
在上一步创建完数据迁移任务后,用户就可以在任务详情界面看到刚创建的数据迁移任务,如下图所示:
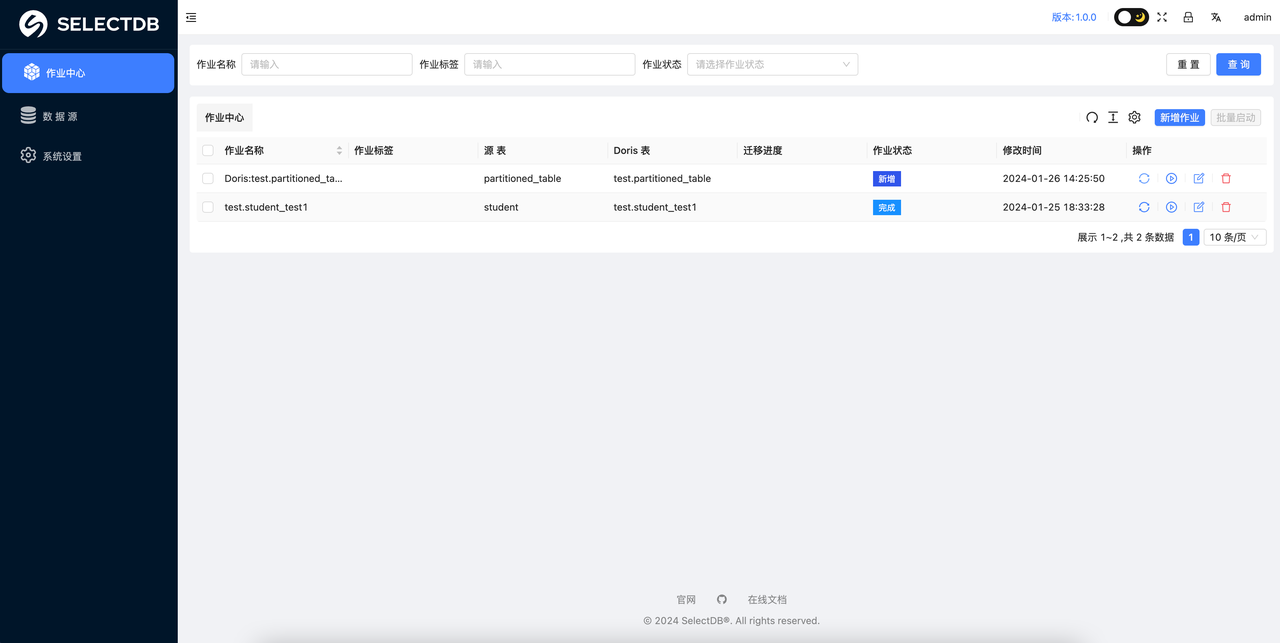
至此从 Hive 到 Doris 的数据迁移任务已经配置完成,可以根据作业状态判断完成与否。
用户使用反馈
自 X2Doris 公开测试以来,已在近百家企业生产环境中应用,并收获广泛的好评。以下是来自部分企业的真实使用反馈:
X2Doris 在 BIGO 中主要用于离线同步 Hive 数据到 Doris 集群,并结合 Doris 打造高效的数据分析平台,日均同步量达 10TB。对比其他数据同步工具,在稳定性、易用性以及性能上 X2Doris 都有明显优势,希望 X2Doris 未来能支持更多数据同步场景,帮助业务数据快速落地。
—— BIGO 高级开发工程师 关老师
X2Doris 在杭银消金落地,打通了我司 Hive 到 Doris 的链路,为更多上游数据同步到 Doris 提供了快捷便利的工具。希望 X2Doris 的功能越来越丰富,可以一站式的解决其他数据源到 Doris 的同步,真正提供一站式数据平台的使用体验!
—— 杭银消金大数据架构师 周老师
X2Doris 在某金融企业实施,为我司从 StarRocks 迁移到 Doris 以及从 Hive 同步 Doris 提供了极大的便利。通过配置化的方式实现了 Hive 中近百张大表 TB 级别离线数据、StarRocks 中单表百 GB 数据的迁移同步工作,在提升了、数据迁移工作效率的同时降低了工作复杂度,是数据同步 Doris 的不二选择。最后希望 X2Ddoris 能接入更多上游数据源,真正完整实现百川归海。
—— 某金融企业大数据架构师 王老师
在迁移开源 Apache Doris 到 SelectDB Cloud 的过程中,10T+的存量历史数据和几百张数据表的迁移,成为我们必须面对的难题。幸运的是,SelectDB 团队推荐的内测版 X2Doris 给我们带来了惊喜。这款工具部署简单,上手较快,无运维烦恼,且页面简洁,开箱即用。同时支持多数据源和可视化用户界面,极大提升数据迁移的效率。在迁移过程中,SelectDB 技术团队均能对所反馈的问题积极响应和解答。我们相信,X2Doris 正式版本将是一款真正解决用户痛点的数据迁移的好产品。
——正浩大数据架构师 陈鹏
总结语
作为一个强大而易用的数据迁移工具,X2Doris 的发布将为广大用户提供更便捷、高效的数据迁移解决方案。无论是小规模的数据迁移还是大规模的数据同步,X2Doris 都能提供极速和稳定的迁移体验。我们将继续改进和优化 X2Doris,扩展支持更多的数据源,以满足不断扩大的用户需求。如果在使用过程中遇到任何问题或需要支持和帮助,请随时联系我们的团队。
交流学习:https://www.selectdb.com/blog/160