仅新增方式: 订单退款表为例, 探讨如何完成仅新增方式导入操作
从业务库将数据导入到ODS层, 分为 首次导入和增量导入两部分, 其中首次导入指的第一次建表, 导入数据, 此时一般都是全量导入, 后续每一天都是采用增量导入的方式,
当前项目, 增量模式: T+1(当天处理都是上一天的数据/ 每天的数据在下一天进行处理)
技术: DataX
当全量导入数据的时候, 整个数据集是应该放置到上一天的分区中呢? 还是说应该按照实际表数据创建时间划分到不同分区呢?
如果之前的数据不多, 且分区数量不多,一般我们采用第一种方式. 如果之前的数据体量较大, 此时务必选择第二种,防止出现单分区内超大规模数据现象.
二种方式均可以, 其实在实际应用中两种其实都是存在的, 只不过我们当前选择的第二种方式, 直接将数据不同的日期放置到不同的分区下
如何做呢? DataX不支持直接导入多个分区数据, 仅支持导入一个分区, 因为DataX本质上是将数据对接HDFS, 而非HIVE,只是HIVE正好映射到HDFS对应目录下, 正好吧数据加载到了, 所以在HIVE正好就看到了数据
既然dataX不支持那如何处理呢?
先创建一个临时表(没有分区), 通过DataX 将数据导入到临时表中, 然后在通过临时表灌入到HIVE的ODS层目标表表, 处理完成后, 删除临时表

首次导入:
目的: Datax只支持一次抽取导入到分区表中的一个分区中, 很明显历史数据中存在多个分区, 所以首次导入,必须将所有数据导入到多个分区, 此时就不能直接将数据使用datax进行分区导入,需要先将其导入到临时非分区表中, 再将其进行间接导入到目标分区表.
1- 创建订单退款表的临时表:
-- 构建订单退款表 临时表:
drop table if exists ods.ods_sale_shop_refund_i_temp;
CREATE TABLE IF NOT EXISTS ods.ods_sale_shop_refund_i_temp(
id BIGINT COMMENT '主键',
refund_no STRING COMMENT '退款单号',
refund_status BIGINT COMMENT '退款状态:1-退款中;2-退款成功;3-退款失败',
refund_code BIGINT COMMENT '退款原因code',
refund_msg STRING COMMENT '退款原因',
refund_desc STRING COMMENT '退款描述',
create_time TIMESTAMP COMMENT '创建时间/退款申请时间',
update_time TIMESTAMP COMMENT '更新时间',
cancel_time TIMESTAMP COMMENT '退款申请取消时间',
refund_amount DECIMAL(27, 2) COMMENT '退款金额',
refund_point_amount DECIMAL(27, 2) COMMENT '扣减已赠积分',
return_pay_point BIGINT COMMENT '退还支付积分',
return_point_amount DECIMAL(27, 2) COMMENT '退还积分抵扣金额',
refund_time TIMESTAMP COMMENT '退款成功时间',
less_weight DECIMAL(27, 3) COMMENT '差额重量,单位kg',
pick_weight DECIMAL(27, 3) COMMENT '拣货重量,单位kg',
is_deleted BIGINT COMMENT '失效标志:0-正常;1-失效',
refund_type BIGINT COMMENT '退款类型:1-部分退;2-全额退; 3-差额退',
order_no STRING COMMENT '订单号',
refund_apply_type BIGINT COMMENT '退款申请类型:1-仅退款;2-退货退款',
refund_delivery DECIMAL(27, 2) COMMENT '运费退款',
sync_erp_status BIGINT COMMENT '同步erp状态:-1-失败,0-未同步,1-成功',
sync_erp_msg STRING COMMENT '同步erp失败消息',
create_sys_user_id BIGINT COMMENT '操作人id',
create_sys_user_name STRING COMMENT '操作人名称',
store_no STRING COMMENT '门店编码',
store_leader_id BIGINT COMMENT '团长id'
)
COMMENT '订单退款表'
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='ZLIB');2- 通过DataX完成数据导入操作
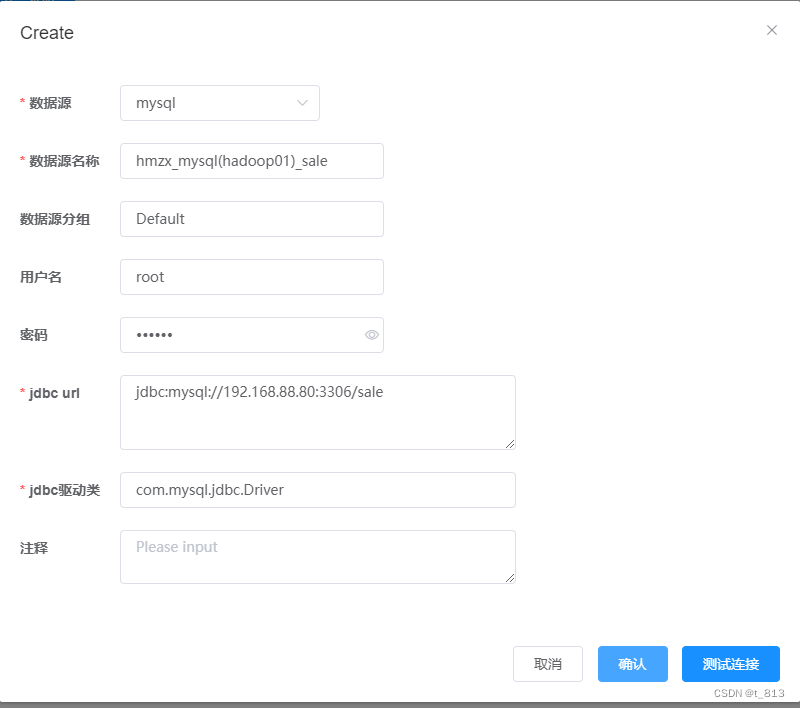
设置数据源: mysql连接 sale库 HIVE连接ODS库

配置DataX任务模板(后续调度时间依然凌晨20分, 可以省略配置)
构建任务

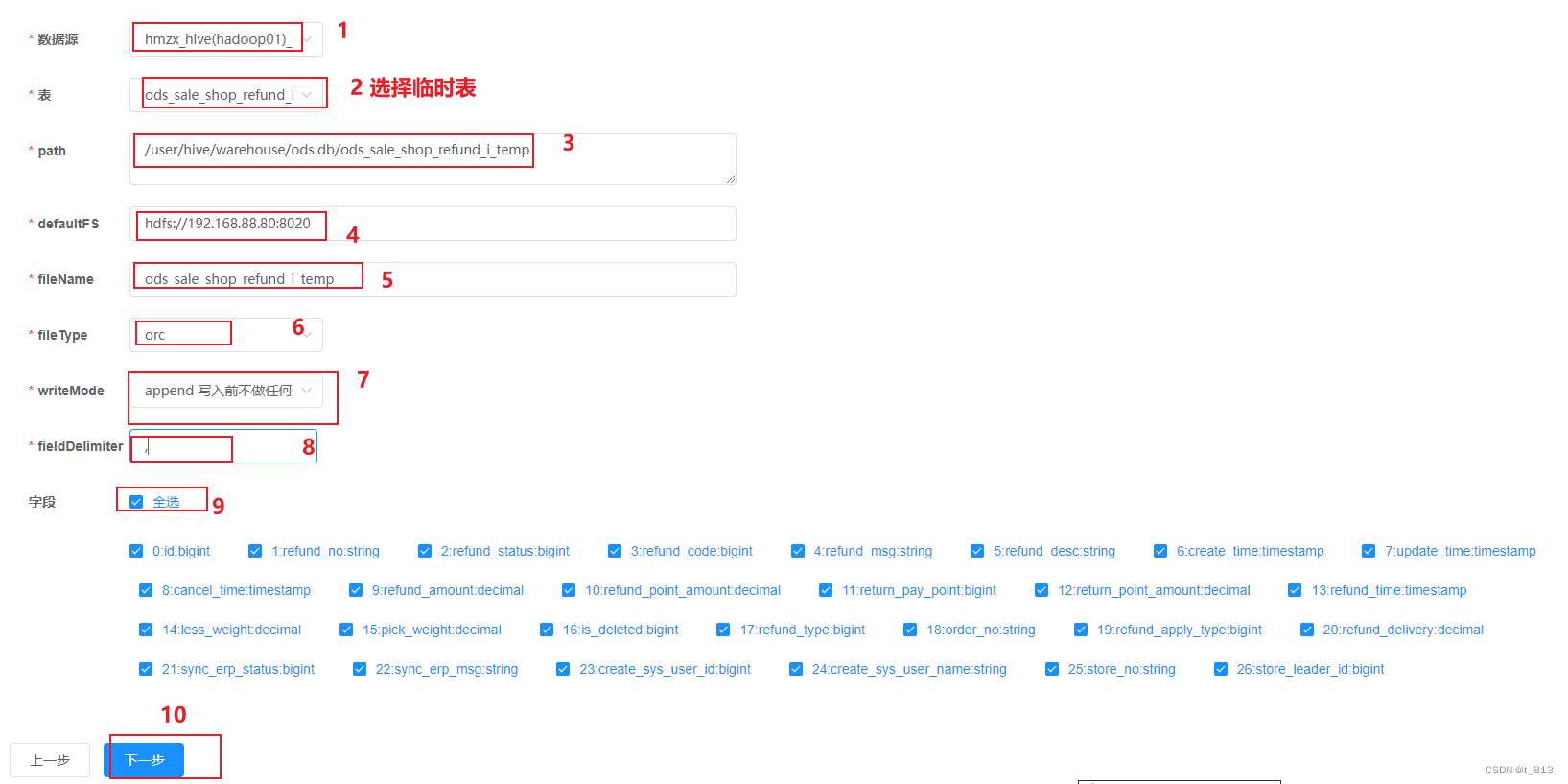

点击构建, 生成Json采集信息内容, 将其中append 更改为truncate
点击选择模板 –> 下一步
执行任务:

校验是否ok: 
将临时表的数据导入到目标表
insert overwrite table ods.ods_sale_shop_refund_i partition (dt)
select
*,
date_format(create_time,'yyyy-MM-dd') as dt
from ods.ods_sale_shop_refund_i_temp;
删除临时表
drop table ods.ods_sale_shop_refund_i_temp;增量导入: T+1模式
为了测试方便, 将MySQL中数据, 更为其中一条为上一天的数据
insert into sale.shop_refund (id, refund_no, refund_status, refund_code, refund_msg, refund_desc, create_time, update_time,
cancel_time, refund_amount, refund_point_amount, return_pay_point, return_point_amount,
refund_time, less_weight, pick_weight, is_deleted, refund_type, order_no, refund_apply_type,
refund_delivery, sync_erp_status, sync_erp_msg, create_sys_user_id, create_sys_user_name,
store_no, store_leader_id)
values (13,'220731Y28899211127',2,999,'其他原因','','2023-09-21 17:50:24','2023-06-14 17:50:24',null,5.26,5.00,null,null,'2023-06-14 17:50:23',null,null,0,1,'BL22073199620677',1,0.00,1,null,1001107,1001107,'Y288',null);目标表是一个分区表, 需要将数据导入到上一天的分区中, 每天导入上一天的即可, 每次新增数据, 都是简历一个新的分区, 将上一天的数据放置到这个分区中

create_time between concat(date_sub(current_date,INTERVAL 1 DAY),' 00:00:00') and concat(date_sub(current_date,INTERVAL 1 DAY),' 23:59:59')
或者:
date_format(create_time,'%Y-%m-%d') = DATE_FORMAT(date_sub(NOW(),INTERVAL 1 DAY),'%Y-%m-%d')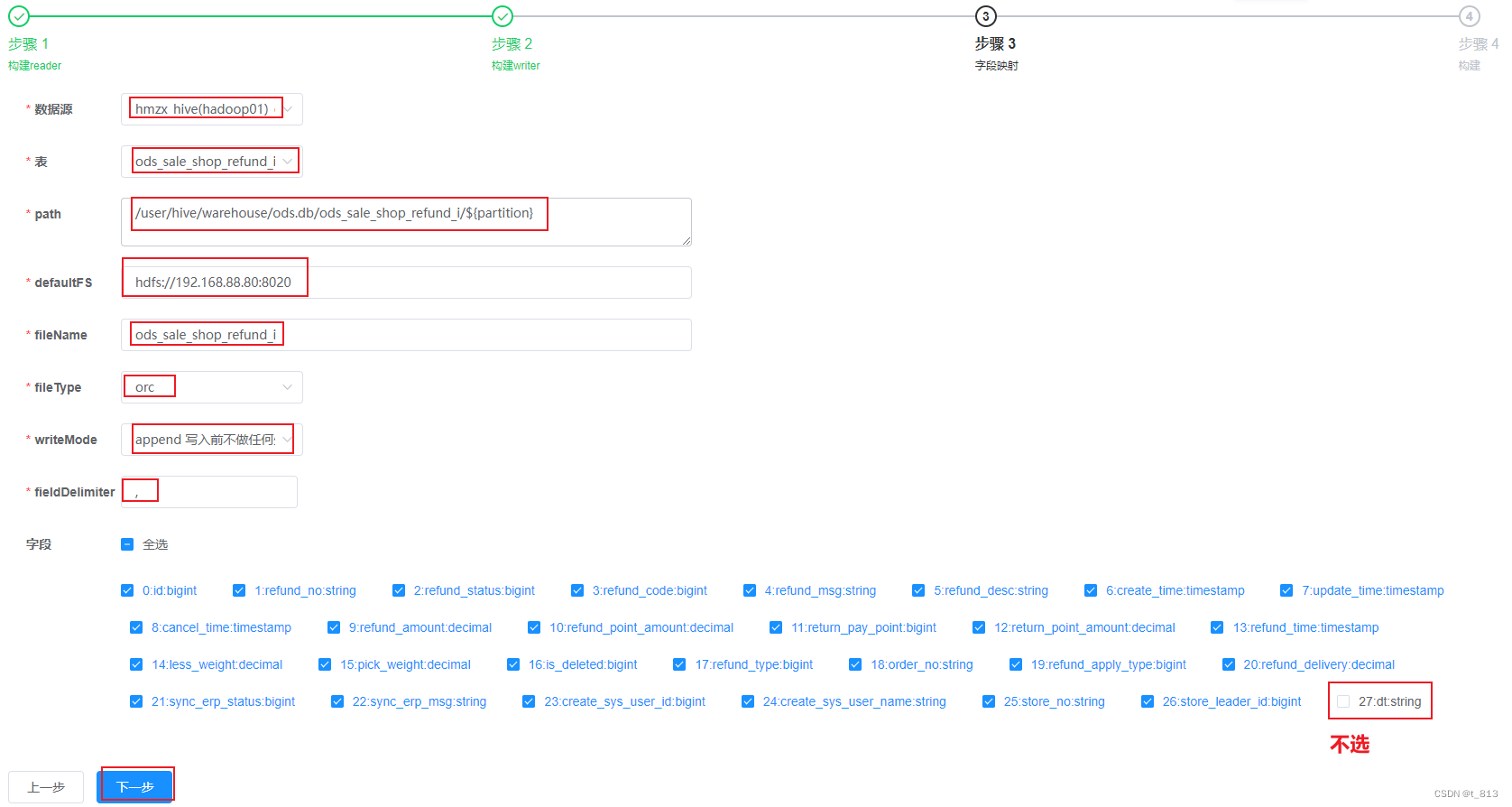

点击构建 –> 修改为truncate –> 点击选择模板 –> 下一步 生成任务
修改全局参数: dt的分区

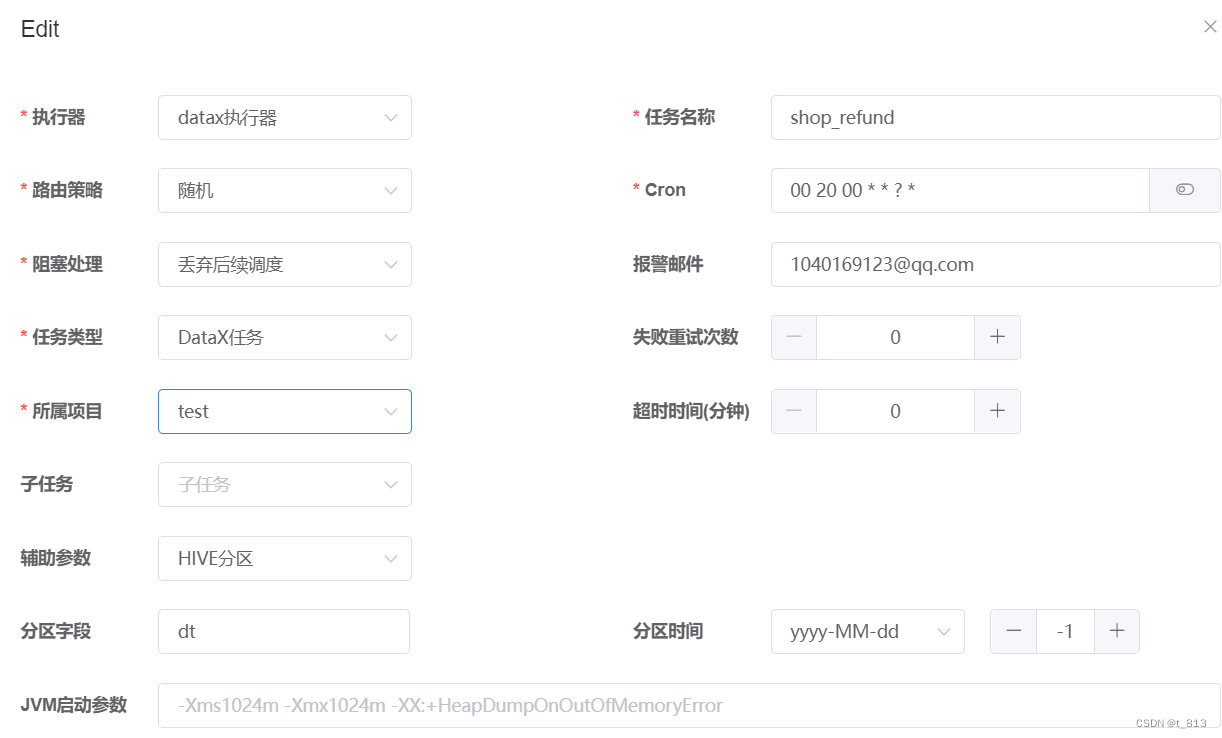
执行任务
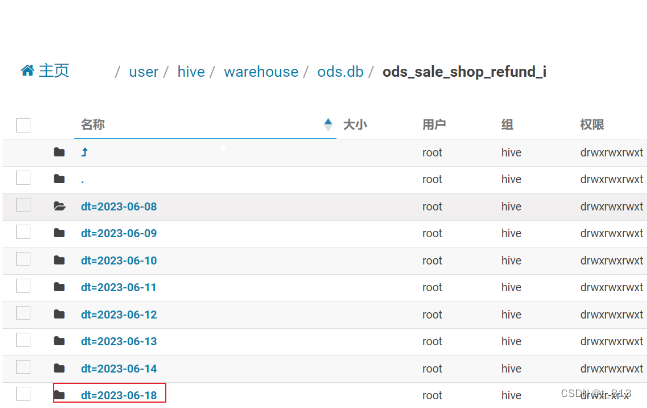
通过hive查询:

会发现压根没有数据, 但是数据确实在HDFS中存在了
查看当前有多少个分区内容?

如何解决呢?
方式一: 手动添加一个分区即可
alter table ods.ods_sale_shop_refund_i add partition (dt='2023-06-18')
方式二: HIVE自动修复分区 (比较适合于有多个分区的情况)
MSCK REPAIR TABLE ods.ods_sale_shop_refund_i sync partitions;
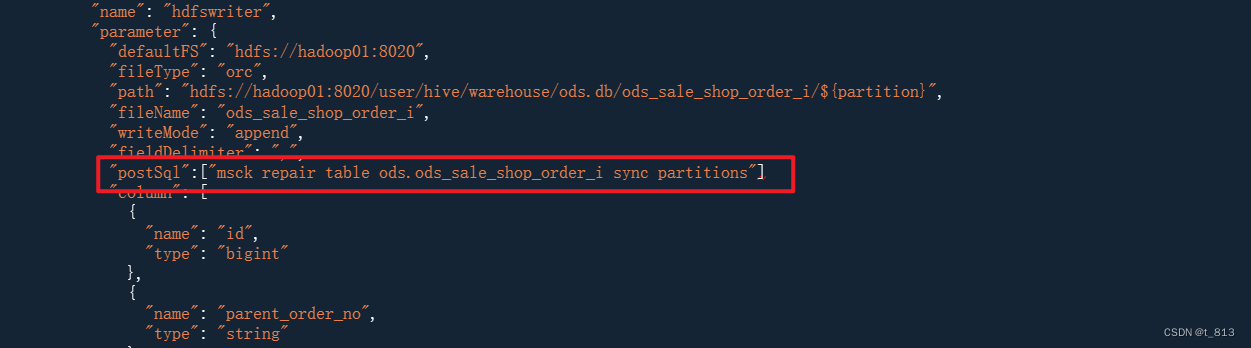
在DataX中如何解决呢? 在写出到HIVE中, 添加一个后置SQL:
MSCK REPAIR TABLE ods.ods_sale_shop_refund_i
演示增量数据导入, 演示完, 需要将增量数据删除,恢复原样, 以免影响后续的计算的结果
hive:
alter table ods.ods_sale_shop_refund_i drop partition(dt='2023-06-18');
mysql:
delete from sale.shop_refund where id = 13;HIVE的函数库: LanguageManual UDF - Apache Hive - Apache Software Foundation