在Ubuntu18/20上部署Kubernetes/k8s详细教程
- 一、设置Docker
- 二、安装Kubernetes
- 第 1 步:添加Kubernetes签名密钥
- 第 2 步:添加软件存储库
- 第 3 步:Kubernetes 安装工具
- 三、部署 Kubernetes
- 步骤 1:准备 Kubernetes 部署
- 步骤 2:为每个服务器节点分配唯一的主机名
- 第 3 步:在主节点上初始化 Kubernetes
- 步骤 4:将工作线程节点加入群集
- 步骤 5:将 Pod 网络部署到集群
- 四、配置dashboard
- 步骤1:安装
- 步骤2:创建Kubernetes Dashboard 的登陆Token
- 五、踩坑/问题记录和解决办法
- 问题1:使用kubeadm init初始化时,报错
- 问题2:如果忘记了节点加入命令怎么办?
- 问题3:k8s 使用 kubeadm init 初始化失败日志一直提示"Error getting node" err="node \"master\" not found"
- 问题4:找不到config.yaml
一、设置Docker
- 安装Docker Engine:
#删除老版本
sudo apt-get remove docker docker-engine docker.io containerd runc
#安装必要工具
sudo apt-get update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
#安装GPG证书&写入软件源信息
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
#安装docker
sudo apt-get -y update & sudo apt-get -y install docker-ce docker-ce-cli containerd.io
#测试
docker info
- 通过输入以下内容将 Docker 设置为在启动时启动:
sudo systemctl enable docker
- 验证 Docker 是否正在运行:
sudo systemctl status docker
- 如果 Docker 未运行,请启动它:
sudo systemctl start docker
二、安装Kubernetes
第 1 步:添加Kubernetes签名密钥
由于您是从非标准存储库下载 Kubernetes,因此必须确保软件是真实的。这是通过添加签名密钥来完成的。否则会出现如下报错:
W: GPG error: https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial InRelease: The following signatures couldn’t be verified because the public key is not available: NO_PUBKEY FEEA9169307EA071 NO_PUBKEY 8B57C5C2836F4BEB
W: The repository ‘https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial InRelease’ is not signed.
N: Data from such a repository can’t be authenticated and is therefore potentially dangerous to use.
N: See apt-secure(8) manpage for repository creation and user configuration details.
在每个节点上,使用 curl 命令下载密钥,然后将其存储在安全的位置(默认为 /usr/share/keyrings):
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg |sudo apt-key add -
第 2 步:添加软件存储库
Kubernetes 不包含在默认存储库中。要将 Kubernetes 存储库添加到列表中。否则在执行apt-get install kubeadm kubectl kubelet -y时会出现以下报错:
No apt package “kubeadm”, but there is a snap with that name.
Try “snap install kubeadm”No apt package “kubectl”, but there is a snap with that name.
Try “snap install kubectl”No apt package “kubelet”, but there is a snap with that name.
Try “snap install kubelet”
添加合适的镜像源到 sources.list 中,然后再执行安装命令。请在每个节点上输入以下内容:
vi /etc/apt/sources.list
加入:
deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
然后再更新:
apt-get update
第 3 步:Kubernetes 安装工具
Kubeadm(Kubernetes Admin)是一个帮助初始化集群的工具。它通过使用社区来源的最佳实践来快速跟踪设置。Kubelet 是工作包,它在每个节点上运行并启动容器。该工具提供对群集的命令行访问权限。
在每个服务器节点上执行以下命令。
- 使用以下命令安装 Kubernetes 工具:
sudo apt install kubeadm=1.23.6-00 kubelet=1.23.6-00 kubectl=1.23.6-00
!!!注意: 这里必须安装1.24以下的版本,否则以下的安装教程都不适用!因为kubelet版本过高,v1.24版本后kubernetes放弃docker了。否则后面初始化就会报错!如果需要更高版本的Kubernetes,请参看其他文章!
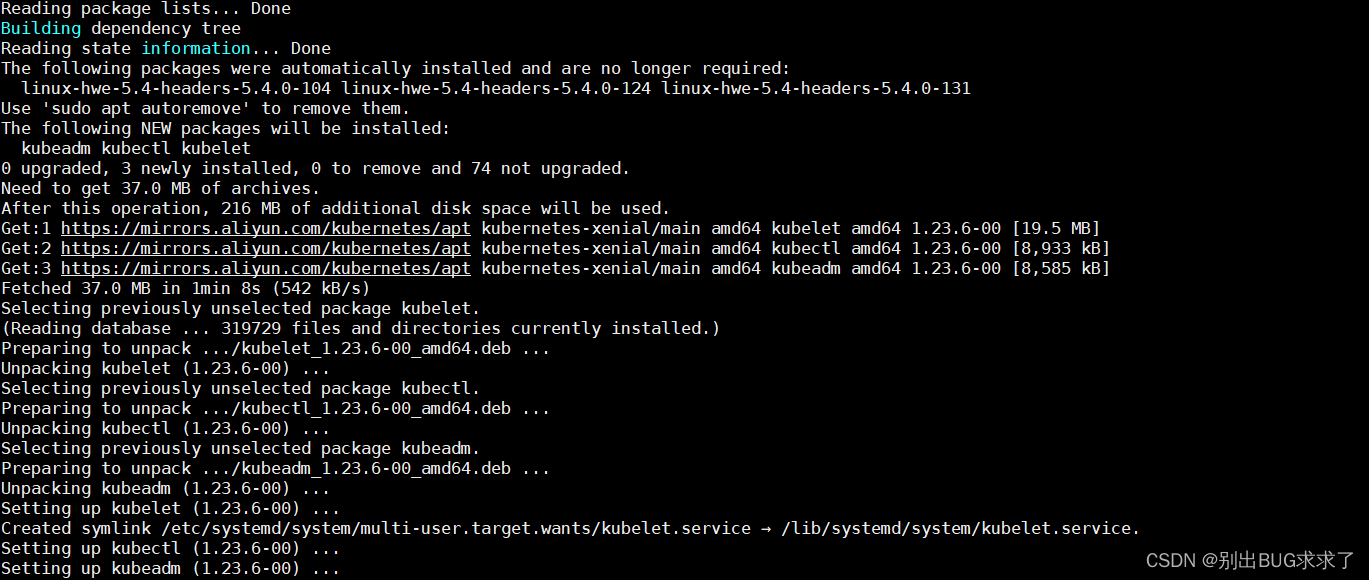
允许该过程完成。
sudo apt-mark hold kubeadm kubelet kubectl
- 使用以下方法验证安装:
kubeadm version
kubelet --version
kubectl version --client
注意: 确保在每台计算机上安装每个包的相同版本。不同的版本可能会造成不稳定。此外,此过程会阻止 apt 自动更新 Kubernetes。
三、部署 Kubernetes
步骤 1:准备 Kubernetes 部署
本部分介绍如何为 Kubernetes 部署准备服务器。在每个服务器节点上执行以下步骤。
- 禁用交换内存。要执行此操作,请执行交换:
sudo swapoff -a
然后键入下面的 sed 命令:
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
永久关闭 : 在/etc/fstab中注释掉最后一行的swap
vim /etc/fstab
- 加载所需的容器模块。首先在文本编辑器中打开 containerd 的配置文件:
sudo vi /etc/modules-load.d/containerd.conf
- 添加以下两行:
overlay
br_netfilter

- 接下来,使用 modprobe 命令添加模块:
sudo modprobe overlay
sudo modprobe br_netfilter
- 配置 Kubernetes 网络。打开 kubernetes.conf 文件:
sudo vi /etc/sysctl.d/kubernetes.conf
添加:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
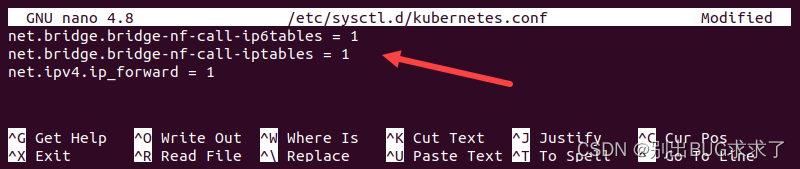
- 保存文件并退出,然后通过键入以下内容重新加载配置:
sudo sysctl --system
步骤 2:为每个服务器节点分配唯一的主机名
- 确定要设置为主节点的服务器。然后输入命令:
sudo hostnamectl set-hostname master-node
- 接下来,通过在工作服务器上输入以下内容来设置工作线程节点主机名:
sudo hostnamectl set-hostname worker01
如果您有其他工作器节点,请使用此过程在每个工作器节点上设置唯一的主机名。
- 通过添加要添加到群集的服务器的 IP 地址和主机名来编辑每个节点上的主机文件。
sudo vim /etc/hosts
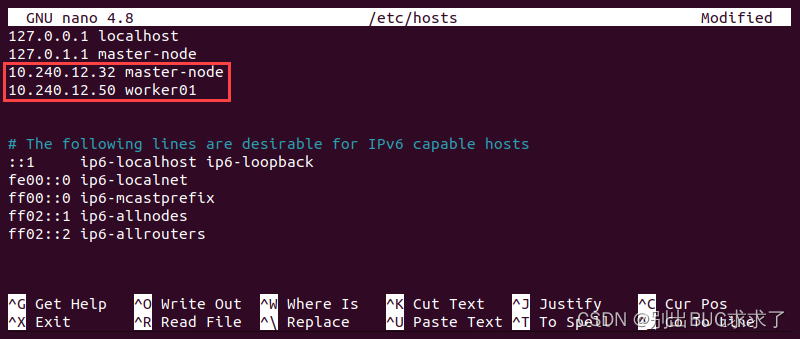
第 3 步:在主节点上初始化 Kubernetes
切换到主节点,按照步骤在其上初始化 Kubernetes:
- 在文本编辑器中打开 kubelet 文件。
sudo vi /etc/default/kubelet
添加:
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
保存并退出文件。
- 执行以下命令以重新加载配置:
systemctl daemon-reload
systemctl restart kubelet
- 打开 Docker 守护程序配置文件:
sudo vi /etc/docker/daemon.json
附加以下配置块:
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
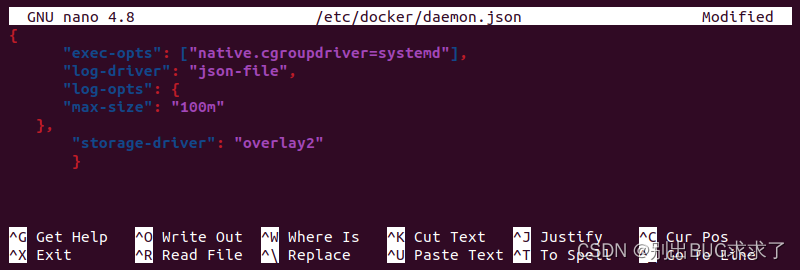
保存文件并退出。
- 重新加载配置:
systemctl daemon-reload
systemctl restart docker
- 打开 kubeadm 配置文件:
sudo vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
将以下行添加到文件中:
Environment="KUBELET_EXTRA_ARGS=--fail-swap-on=false"
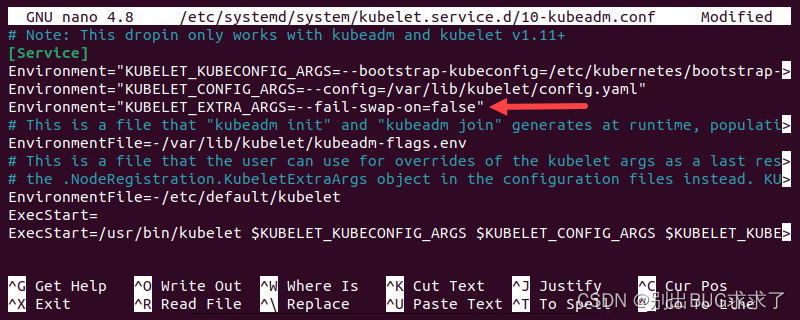
保存文件并退出。
- 重新加载Kubernetes:
systemctl daemon-reload
systemctl restart kubelet
- 通过键入以下内容初始化集群(最关键的一步):
kubeadm init --apiserver-advertise-address=$(hostname -i) \
--apiserver-cert-extra-sans=127.0.0.1 \
--pod-network-cidr=10.244.0.0/16 \
--image-repository=registry.aliyuncs.com/google_containers
注意: 这里有一个巨大的坑, 如果使用Flannel网络 【建议使用 --pod-network-cidr=10.244.0.0/16 或者后期修改Flannel ConfigMap 】,【部署Dashboard ,nfs-subdir-external-provisioner时】失败报错如下:
Error getting server version: Get
"https://10.96.0.1:443/version?timeout=32s: dial tcp 10.96.0.1:443:
i/o timeout.
修改Flannel ConfigMap 如下:
kubectl edit cm -n kube-system kube-flannel-cfg
# edit the configuration by changing network from 10.244.0.0/16 to 10.10.0.0/16
kubectl delete pod -n kube-system -l app=flannel
kubectl delete po -n kube-system -l k8s-app=kubernetes-dashboard
部署成功如下:
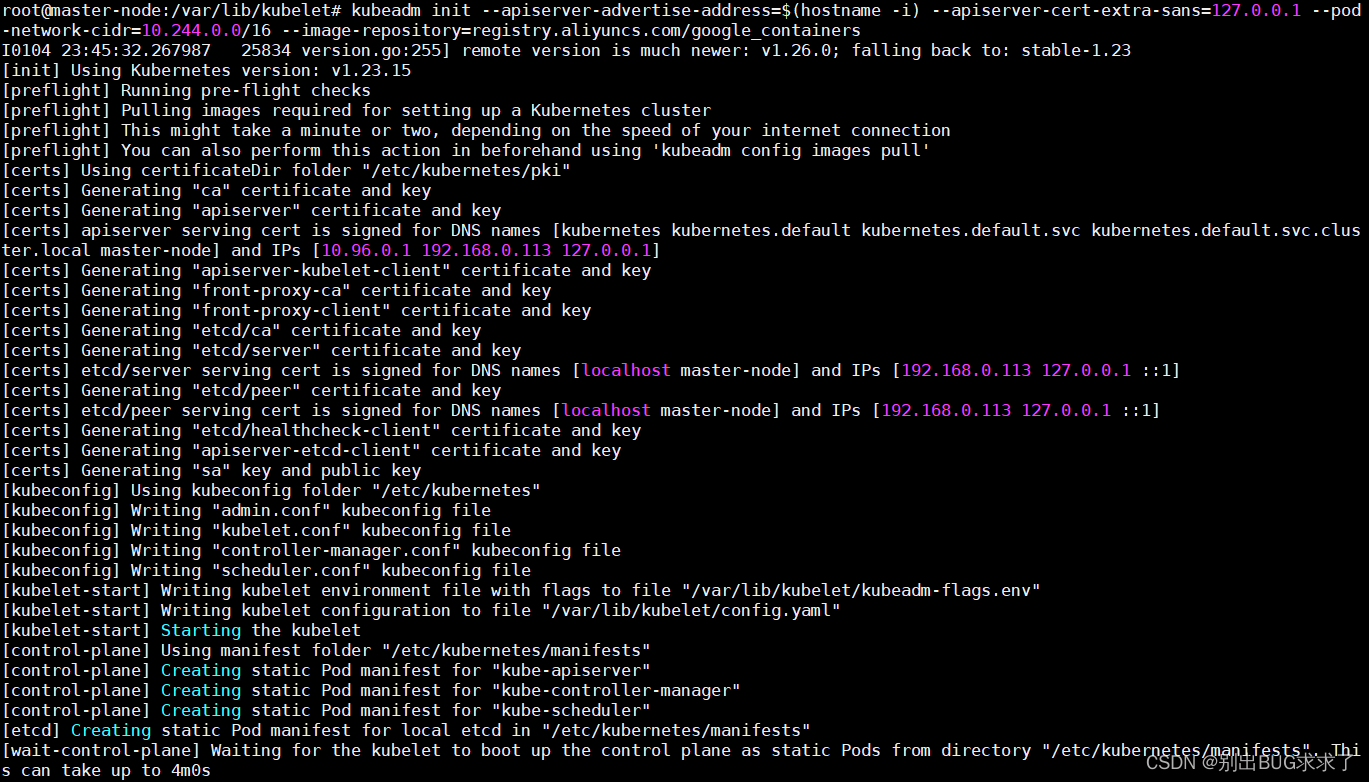
此命令完成后,它将在末尾显示一条 kubeadm 加入消息。记下整个条目。这将用于将工作器节点加入群集。
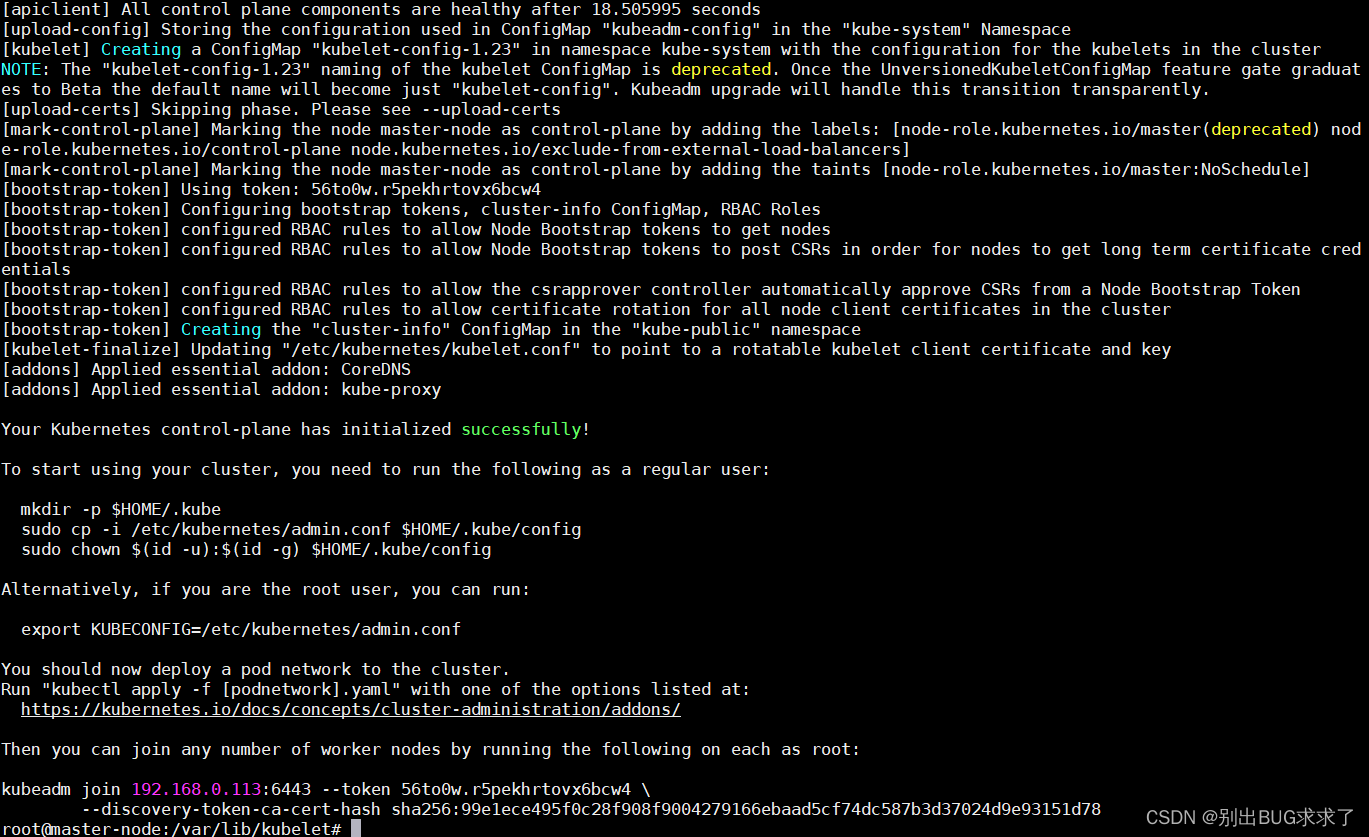
kubeadm 加入消息:
kubeadm join 192.168.0.113:6443 --token 56to0w.r5pekhrtovx6bcw4 \
--discovery-token-ca-cert-hash sha256:99e1ece495f0c28f908f9004279166ebaad5cf74dc587b3d37024d9e93151d78
- 输入以下内容以创建 Kubernetes 集群的目录:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
步骤 4:将工作线程节点加入群集
如步骤 3 所示,您可以在工作节点上输入 kubeadm join 命令以将它们连接到主节点。在要添加到群集的每个工作线程节点上重复这些步骤。
- 配置其他节点使用kubectl
scp -r /etc/kubernetes/admin.conf ${worker01}:/etc/kubernetes/admin.conf
#配置环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
#立即生效
source ~/.bash_profile
- 添加集群节点[kubeadm join]
输入您在步骤 3 中记下的命令:
sudo kubeadm join 192.168.0.113:6443 --token 56to0w.r5pekhrtovx6bcw4 --discovery-token-ca-cert-hash sha256:99e1ece495f0c28f908f9004279166ebaad5cf74dc587b3d37024d9e93151d78
此时可能会报错:
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable–etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable–etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with--ignore-preflight-errors=...
To see the stack trace of this error execute with --v=5 or higher
执行:sudo kubeadm reset 然后重新再进行一遍上面加入集群的指令即可,成功示意:
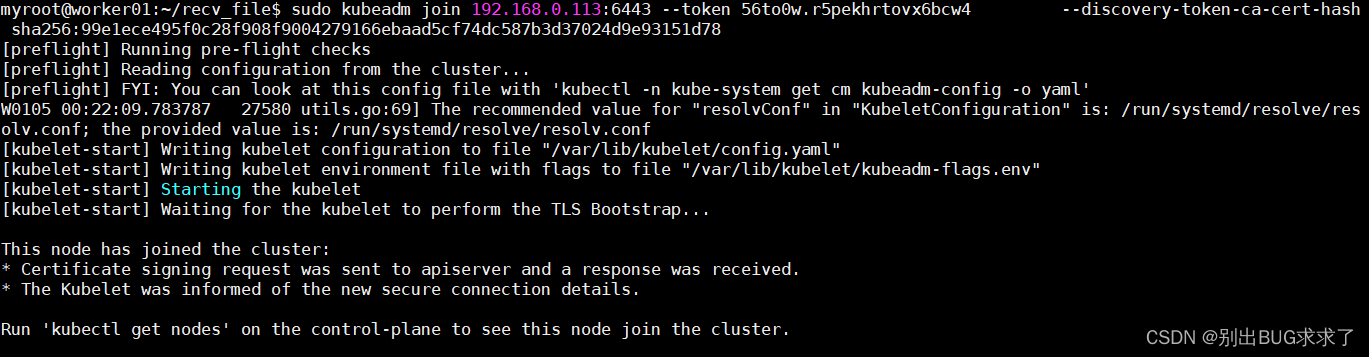
- 切换到主服务器,然后输入:
kubectl get nodes

此时,节点的status是NotReady ,这是因为没有安装网络插件
步骤 5:将 Pod 网络部署到集群
Pod 网络是一种允许集群中不同节点之间进行通信的方法。本教程使用 flannel虚拟网络。
主节点上,直接执行:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
成功配置并且Ready:

四、配置dashboard
步骤1:安装
参考地址:GitHub - kubernetes/dashboard: General-purpose web UI for Kubernetes clusters
- 获取yml配置文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml
vim ./recommended.yaml
- dashboard安装后service 默认是 ClusterIP 运行 修改成 NodePort

3. 安装dashboard命令:
kubectl apply -f recommended.yaml
- 成功:
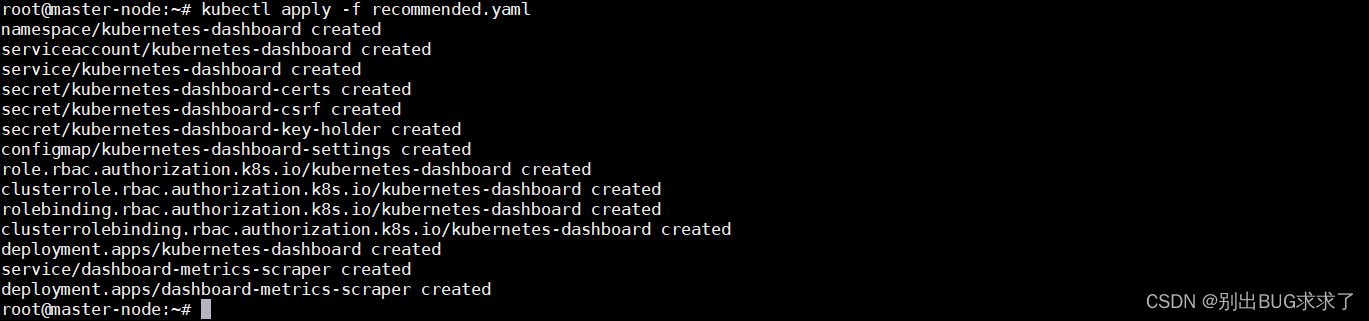
- 通过 https://hostname:31443 就可以访问 Kubernetes Dashboard 了, 如下图
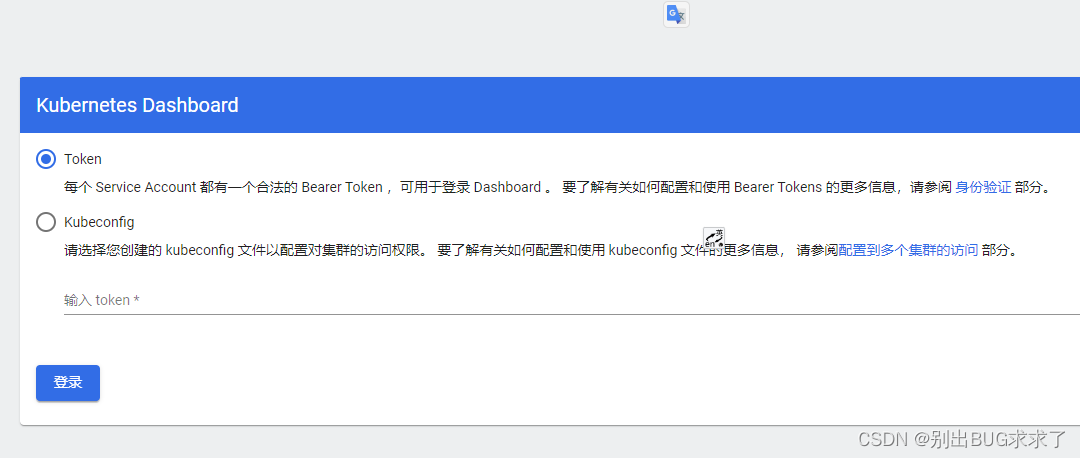
步骤2:创建Kubernetes Dashboard 的登陆Token
- 创建一个ServiceAccount :dashboard-admin
kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
- 将dashboard-admin 绑定到集群管理角色
kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
- 查看dashboard-admin的登陆Token
kubectl get secret -n kubernetes-dashboard
kubectl describe secret dashboard-admin-token-5pglz -n kubernetes-dashboard
如下:
root@master:~/app/k8s# kubectl get secret -n kubernetes-dashboard
NAME TYPE DATA AGE
dashboard-admin-token-5pglz kubernetes.io/service-account-token 3 6m26s
default-token-95htf kubernetes.io/service-account-token 3 12m
kubernetes-dashboard-certs Opaque 0 12m
kubernetes-dashboard-csrf Opaque 1 12m
kubernetes-dashboard-key-holder Opaque 2 12m
kubernetes-dashboard-token-7xxbl kubernetes.io/service-account-token 3 12m
root@master:~/app/k8s# kubectl describe secret dashboard-admin-token-5pglz -n kubernetes-dashboard
Name: dashboard-admin-token-5pglz
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 4b4029cb-6eb2-49f3-a15c-42c9b7ac8d60
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1099 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IlExNUJWbDZXWWpsTFhuWGxqNmRzNkFvMXBOTkc0aERlNzR1UGpIblFnc2MifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tNXBnbHoiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNGI0MDI5Y2ItNmViMi00OWYzLWExNWMtNDJjOWI3YWM4ZDYwIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.jcpagiw7jhORVxhsbMH4HpB9Fi_bS2crTYcXTXTtJY1JBcyazoahE3UOm6ZPL9NRX9U-Ut7nds7WrIYugi0LzjJIHQIj9sEhZhTdVTxTdrlUXzMGuEBW_RaWZzbxw6-S2NPFCVnAS3P0jY8GVFjD8rhtNU_ZtMFDJOLe6J3Cz_OQL9-Zz2lxWnklxoEmh8qmz3neczBR95bVOAznJ9mwyivsTpvgRYauAi7yrdanCCiJgORr21S0O4TYPhbZHdIq_4
- 拿到token就可以登陆dashboard 了,如图
五、踩坑/问题记录和解决办法
问题1:使用kubeadm init初始化时,报错
我执行了kubeadm init这条命令之后就会在下面这里卡很久
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory “/etc/kubernetes/manifests”. This can take up to 4m0s
然后就报下面这个错
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the conditionThis error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)If you are on a systemd-powered system, you can try to troubleshoot
the error with the following commands:
- ‘systemctl status kubelet’
- ‘journalctl -xeu kubelet’Additionally, a control plane component may have crashed or exited
when started by the container runtime. To troubleshoot, list all
containers using your preferred container runtimes CLI. Here is one
example how you may list all running Kubernetes containers by using
crictl:
- ‘crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v
pause’
Once you have found the failing container, you can inspect its logs with:
- ‘crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID’ error
execution phase wait-control-plane: couldn’t initialize a Kubernetes
cluster To see the stack trace of this error execute with --v=5 or
higher
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz’ failed with error: Get “http://localhost:10248/healthz”: dial tcp 127.0.0.1:10248: connect: connection refused.
1. 排查1
进入/etc/systemd/system/kubelet.service.d,查看是否存在10-kubeadm.conf,在文件末尾添加
Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false"
执行如下命令重新加载配置
systemctl daemon-reload
systemctl restart kubelet.service
再次初始化时如果报错
[ERROR FileAvailable–etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable–etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
是因为第一次初始化失败后有垃圾数据没有清理,执行 kubeadm reset重置
如果再次初始化又报如下错误
failed to run Kubelet: misconfiguration: kubelet cgroup driver: “systemd” is different from docker cgroup driver: “cgroupfs”
systemd
cgroupfs
原因是kubelet的cgroup配置与docker的cgroup不一致,分别修改docker与控制平台的kubelet的cgroup,官方推荐systemd
首先修改或创建/etc/docker/daemon.json,添加如下配置
{ "exec-opts": ["native.cgroupdriver=systemd"] }
重启docker,检查是否变更成功
docker info|grep "Cgroup Driver"
Cgroup Driver: systemd
变更kubelet的cgroup
vi /var/lib/kubelet/config.yaml
cgroupDriver: systemd
2. 排查2
自行进行错误的排查:
运行:
systemctl status kubelet
发现服务并未启动,而正常启动是这样的:

运行:
journalctl -u kubelet --no-pager
通过查看err所在的行,也能找到相应的错误
8041 run.go:74] “command failed” err=“failed to run Kubelet: validate
service connection: CRI v1 runtime API is not implemented for endpoint
“unix:///var/run/containerd/containerd.sock”: rpc error: code =
Unimplemented desc = unknown service runtime.v1.RuntimeService”
产生这个问题就是Kubernetes的版本的原因,降低Kubernetes版本就好.解决方案见问题3
问题2:如果忘记了节点加入命令怎么办?
使用如下命令重新生成
kubeadm token create --print-join-command
问题3:k8s 使用 kubeadm init 初始化失败日志一直提示"Error getting node" err=“node “master” not found”
如下错误:
16358 kubelet.go:2448] “Error getting node” err=“node “master-node”
not found”
此时部署状态:

部署后集群状态,所有node的kubelet无法启动,master的kubelet活动正常
[kubelet-check] Initial timeout of 40s passed之后报各种错误
解决一个又有新的,一直都无法启动
期间尝试过重装k8s组件,甚至重装系统,结果都一样
journalctl -xefu kubelet(查看日志有过这些报错)
[ERROR CRI]: container runtime is not running: output: E0725 08:28:43.725092 27421 remote_runtime.
解决方法(执行后也是无法启动的):
rm -rf /etc/containerd/config.toml
systemctl restart containerd
failed to run Kubelet: unable to determine runtime API version: rpc error: code = Unavailable desc = connection error: desc = “transport: Error while dialing dial unix: missing address”
“Error getting node” err="node “master” not found"后面日志一直提示这个,也是更具这个问题在一个帖子的一句提示中找到了答案
问题原因:kubelet版本过高,v1.24版本后kubernetes放弃docker了
我真的掏了,解决办法:卸掉1.24版本的组件,使用低版本,上面教程中下载的是v1.23.6
K8s官方公布从1.24版本开始移除dockershim:https://cloud.it168.com/a2022/0426/6661/000006661320.shtml
此时需要指定版本安装,可以通过以下指令来寻找版本:
apt-cache madison xxx(比如kubeadm)
问题4:找不到config.yaml
E0104 23:36:57.074830 24271 server.go:205] “Failed to load kubelet
config file” err=“failed to load Kubelet config file
/var/lib/kubelet/config.yaml, error failed to read kubelet config file
“/var/lib/kubelet/config.yaml”, error: open
/var/lib/kubelet/config.yaml: no such file or directory”
path=“/var/lib/kubelet/config.yaml”
err="failed to load Kubelet config file /var/lib/kubelet/config.yaml,
error failed to read kubelet c: failed to load Kubelet config file /var/lib/kubelet/config.yaml,
error failed to read kub
启动kubelet失败 原因是没有还需要执行:kubeadm init
之后会生成:
[root@localhost rpm]# cd /var/lib/kubelet/
[root@localhost kubelet]# ls -l
total 12
-rw-r--r--. 1 root root 1609 Jun 24 23:40 config.yaml
-rw-r--r--. 1 root root 40 Jun 24 23:40 cpu_manager_state
drwxr-xr-x. 2 root root 61 Jun 24 23:41 device-plugins
-rw-r--r--. 1 root root 124 Jun 24 23:40 kubeadm-flags.env
drwxr-xr-x. 2 root root 170 Jun 24 23:41 pki
drwx------. 2 root root 6 Jun 24 23:40 plugin-containers
drwxr-x---. 2 root root 6 Jun 24 23:40 plugins
drwxr-x---. 7 root root 210 Jun 24 23:41 pods
[root@localhost kubelet]#
再启动 就会正常
root@localhost kubelet]# systemctl status kubelet.service
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Thu 2021-06-24 23:40:36 PDT; 4min 31s ago
Docs: http://kubernetes.io/docs/
Main PID: 26379 (kubelet)
Memory: 40.1M
CGroup: /system.slice/kubelet.service
└─26379 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubele...
Jun 24 23:44:46 localhost.localdomain kubelet[26379]: W0624 23:44:46.705701 26379 cni.go:172] Unable to update cni config: No networks found in /etc/cni/net.d
Jun 24 23:44:46 localhost.localdomain kubelet[26379]: E0624 23:44:46.705816 26379 kubelet.go:2110] Container runtime network not ready: NetworkReady=fals...itialized
Jun 24 23:44:51 localhost.localdomain kubelet[26379]: W0624 23:44:51.706635 26379 cni.go:172] Unable to update cni config: No networks found in /etc/cni/net.d
Jun 24 23:44:51 localhost.localdomain kubelet[26379]: E0624 23:44:51.706743 26379 kubelet.go:2110] Container runtime network not ready: NetworkReady=fals...itialized
Jun 24 23:44:56 localhost.localdomain kubelet[26379]: W0624 23:44:56.708389 26379 cni.go:172] Unable to update cni config: No networks found in /etc/cni/net.d
Jun 24 23:44:56 localhost.localdomain kubelet[26379]: E0624 23:44:56.708506 26379 kubelet.go:2110] Container runtime network not ready: NetworkReady=fals...itialized
Jun 24 23:45:01 localhost.localdomain kubelet[26379]: W0624 23:45:01.710355 26379 cni.go:172] Unable to update cni config: No networks found in /etc/cni/net.d
Jun 24 23:45:01 localhost.localdomain kubelet[26379]: E0624 23:45:01.710556 26379 kubelet.go:2110] Container runtime network not ready: NetworkReady=fals...itialized
Jun 24 23:45:06 localhost.localdomain kubelet[26379]: W0624 23:45:06.712081 26379 cni.go:172] Unable to update cni config: No networks found in /etc/cni/net.d
Jun 24 23:45:06 localhost.localdomain kubelet[26379]: E0624 23:45:06.712241 26379 kubelet.go:2110] Container runtime network not ready: NetworkReady=fals...itialized
Hint: Some lines were ellipsized, use -l to show in full.
[root@localhost kubelet]#