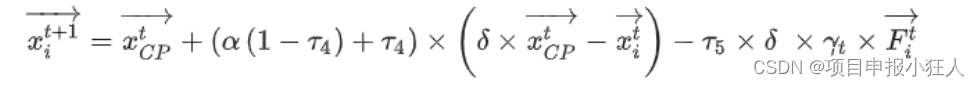近日,国外研究者发布了一篇论文《Seven Failure Points When Engineering a Retrieval Augmented Generation System》,探讨了在实际工程落地RAG应用过程中容易出的七类问题。
论文地址:https://arxiv.org/pdf/2401.05856.pdf
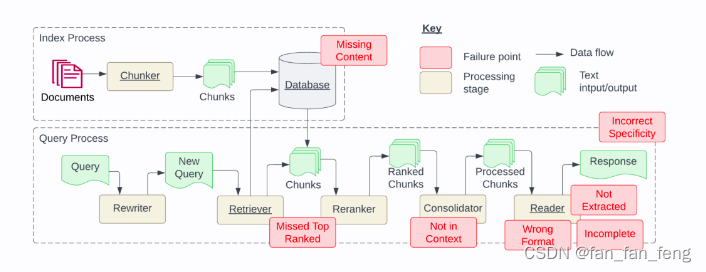
一、丢失内容( Missing Content )
- 提问的问题,无法在被检索文档库中找到,最准确的答案是缺失的。
- 比较好的情况是回答"我不知道"。但事实上,它却会编造一个看似正确的错误答案。
二、错过了最相关的文档( Missed the Top Ranked Documents )
- 问题的答案在文档库中,但排名得分不够高,无法返回给用户。
- 理论上,检索过程中所有文档都会被排名得分。然而,在实际操作中,会返回排名前K个文档,为了提高召回率,K不可能设置的无限大,必须基于LLM大模型的能力,折中选择的一个值。
三、不在上下文中(Not in Context - Consolidation strategy Limitations)
- 有时候,可能会检索到大量的的文档,受限于模型的context大小限制,需要进行整合修剪才能传给大模型,但这有可能导致真正包含的答案未能放进上下文中。这种情况一样会导致模型产生幻觉,除非Prompt明确指示模型不返回不在上下文中的结果。
四、无法提取(Not Extracted )
- 在这种情况下,答案在上下文中存在,但大语言模型未能正确提取出答案。通常,这是因为上下文中存在太多干扰性信息或相互矛盾的信息。
- 当数据库返回许多文档时,会进行整合过程以获取答案,此时会发生这种情况。
五、错误的格式(Wrong Format )
- 问题涉及提取特定格式(例如表格或列表)的信息,但大语言模型忽略了指令。
- 需要通过系统Prompt并编写代码来以特定格式生成信息。如果这是一个重要功能,就需要进行软件开发和测试。
六、特定性不准确(Incorrect Specificity)
- 回答不够具体或过于笼统,不能满足用户的需求。这种情况通常是因为RAG系统的设计者对于特定问题有特定的期望结果。
- 比如教师对学生,在这种情况下,应该提供特定的教育内容,而不仅仅是答案。
- 特定性不准确还会在用户不确定如何提问或问题过于笼统时出现。
七、不完整(Incomplete)
- 不完整的答案并不是错误的,但是会漏掉一些信息,尽管这些信息在上下文中并且可以提取出来。
- 例如,一个问题是:“文档 A、B 和 C 中包括哪些关键点?”更好的方法是分别提出这些问题。
八、改善方向
| FP | 研究方向 | 具体描述 |
| FP4 | 更多的上下文信息 | 大模型的窗口从4K增加到8K或者更大,LLM可以使用更多的上下文信息 |
| FP1 | 语义缓存降低了成本和延迟 | 由于速率限制和LLM的成本,RAG系统在应对并发用户方面存在困难。使用常见问题的预检索能力,可以缓解内容缺失现象。 |
| FP5~FP7 | RAG“越狱” | LLM大模型fine-tuning,增加模型的基础能力 |
| FP2,FP4 | 增加元信息 | 将文件名和块编号添加到检索到的上下文中有助于读者提取所需信息。这对聊天对话很有用。 |
| FP2 FP4~7 | 开源嵌入模型在处理小型文本方面表现更优。 | 在处理小型文本方面,开源句子嵌入模型的表现与闭源替代品相当。 |
| FP2~7 | RAG系统需要持续校准。 | RAG系统在运行时接收未知输入,需要不断监控。 |
| FP1 FP2 | 实现一个RAG配置流水线 | 一个RAG系统需要校准块大小、嵌入策略、分块策略、检索策略、整合策略、上下文大小和提示。 |
| FP2,FP4 | 通过组装定制解决方案创建的RAG管道是次优的。 | 端到端训练模型,增强RAG的领域实用性 |
| FP2~FP4 | 只有在运行时才能测试性能特征。 | 离线评估技术,如G-Evals看起来很有前景,但前提是能够获得标记过的问题和答案对。 |
参考:
RAG系统的“七宗罪”--一周出demo,半年用不好







![[GN] 设计模式—— 创建型模式](https://img-blog.csdnimg.cn/direct/a7efabd4689241e28faea3df62e1be3b.png)