1 介绍
PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理(NLP)工具库。
它提供了一系列用于文本处理、文本分类、情感分析、文本生成等任务的预训练模型、模型组件和工具函数。
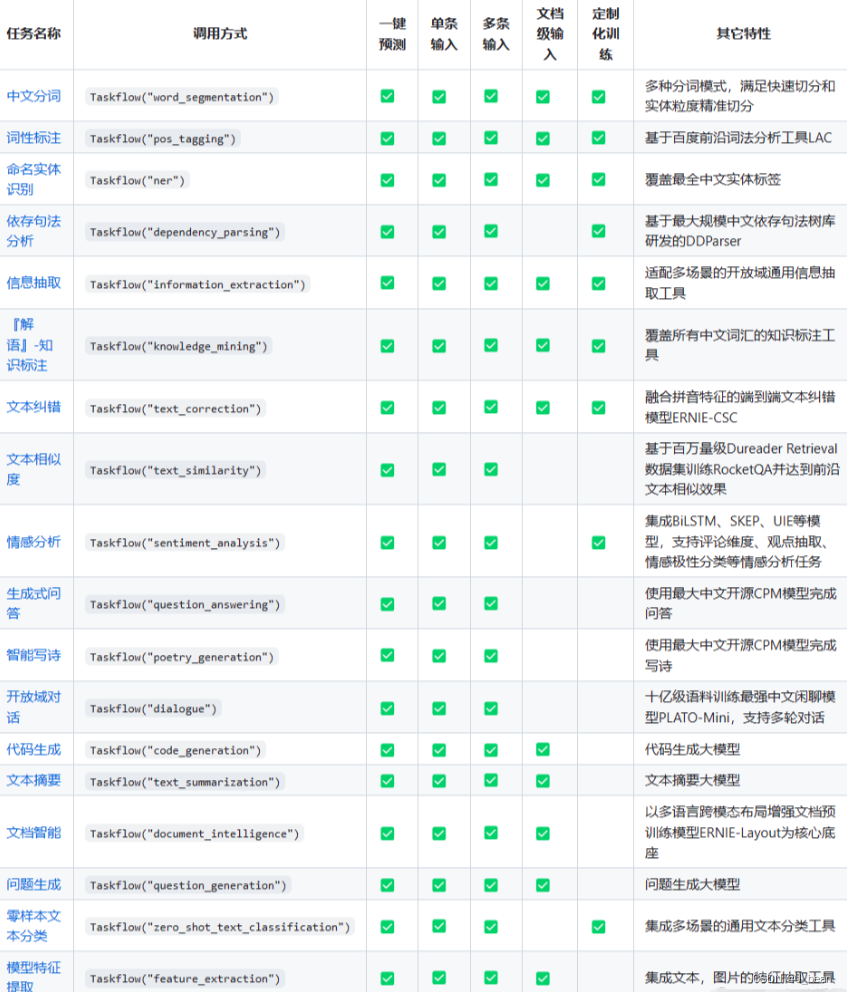
PaddleNLP有统一的应用范式:通过 paddlenlp.Taskflow 调用,简捷易用。
2 安装
2.1 安装依赖包
pip install python==3.8.10 -i https://mirror.baidu.com/pypi/simple
pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple
pip install paddlenlp==2.5.2 -i https://mirror.baidu.com/pypi/simple
pip install opencv-python -i https://mirror.baidu.com/pypi/simple
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
pip install --upgrade opencv-python
pip install --upgrade paddlenlp
pip install --upgrade paddleocr
2.2 验证是否安装成功
执行python命令,未报错则代表安装成功
import paddle
paddle.utils.run_check()2.3 问题排查
(1)执行时如果报错 ModuleNotFoundError: No module named ‘paddle.nn.layer.layers‘,则再次执行以下安装命令
pip install paddlenlp==2.5.2 -i https://mirror.baidu.com/pypi/simple3 使用
3.1 中文分词
from paddlenlp import Taskflow
# 默认模式-实体粒度分词,在精度和速度上的权衡,基于百度LAC
seg = Taskflow("word_segmentation")
print(seg("PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理工具库"))
# 指定模式-粗粒度分词,速度更快,基于jieba
seg = Taskflow("word_segmentation", mode="fast")
print(seg("PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理工具库"))
# 精确模式-最准:实体粒度切分准确度最高,基于百度解语
seg_accurate = Taskflow("word_segmentation", mode="accurate")
print(seg_accurate("PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理工具库"))
# 批量处理——平均速度更快
print(seg(["PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理工具库",
"它提供了一系列用于文本处理、文本分类等任务的预训练模型、模型组件和工具函数"]))
4 参考文献
(1) 数据处理轻松搞定:如何利用PaddleNLP高效处理大规模文本数据
(2)ModuleNotFoundError