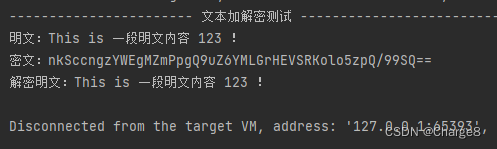
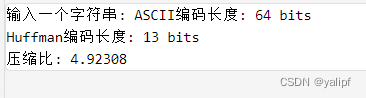
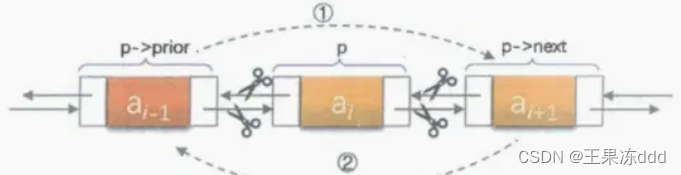
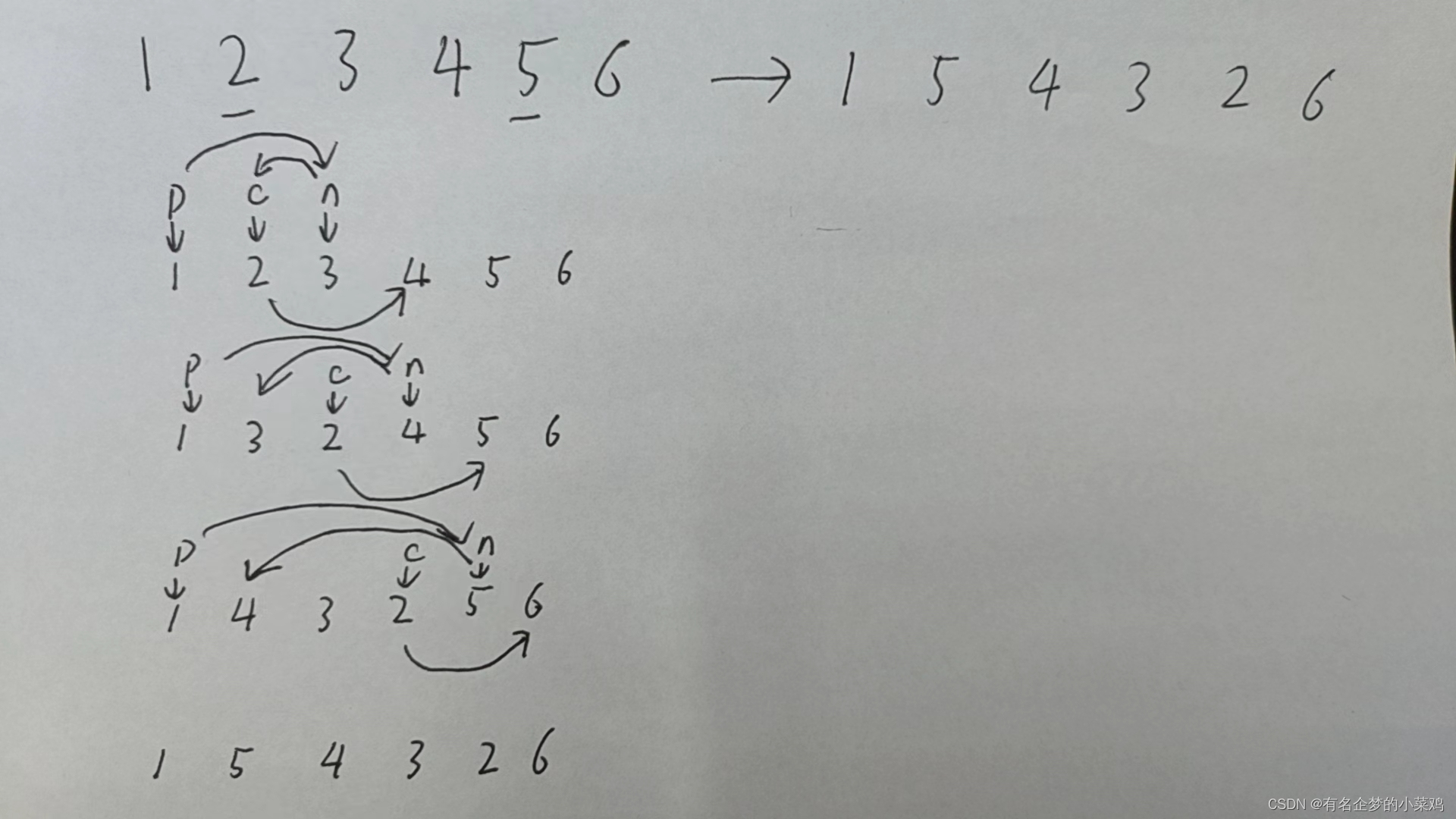
本文首发于公众号:机器感知
Virtual Assistant for Smartphone;Denoising Autoencoder;CrossMAE
The Case for Co-Designing Model Architectures with Hardware
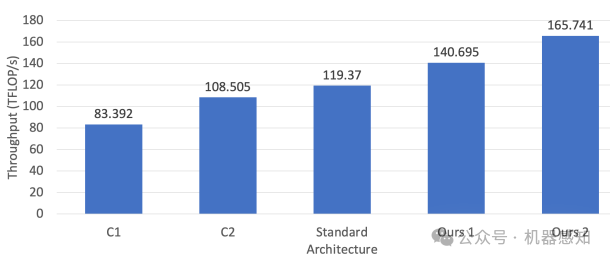
While GPUs are responsible for training the vast majority of state-of-the-art deep learning models, the implications of their architecture are often overlooked when designing new deep learning (DL) models. As a consequence, modifying a DL model to be more amenable to the target hardware can significantly improve the runtime performance of DL training and inference. In this paper, we provide a set of guidelines for users to maximize the runtime performance of their transformer models. We find the throughput of models with efficient model shapes is up to 39% higher while preserving accuracy compared to models with a similar number of parameters but with unoptimized shapes.
Taiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support

Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications.
VJT: A Video Transformer on Joint Tasks of Deblurring, Low-light Enhancement and Denoising

Video restoration task aims to recover high-quality videos from low-quality observations. This contains various important sub-tasks, such as video denoising, deblurring and low-light enhancement, since video often faces different types of degradation, such as blur, low light, and noise. Even worse, these kinds of degradation could happen simultaneously when taking videos in extreme environments. In this paper, to the best of our knowledge, we are the first to propose an efficient end-to-end video transformer approach for the joint task of video deblurring, low-light enhancement, and denoising. We also provide a new Multiscene-Lowlight-Blur-Noise (MLBN) dataset, which is generated according to the characteristics of the joint task based on the RealBlur dataset and YouTube videos to simulate realistic scenes as far as possible.
GPTVoiceTasker: LLM-Powered Virtual Assistant for Smartphone
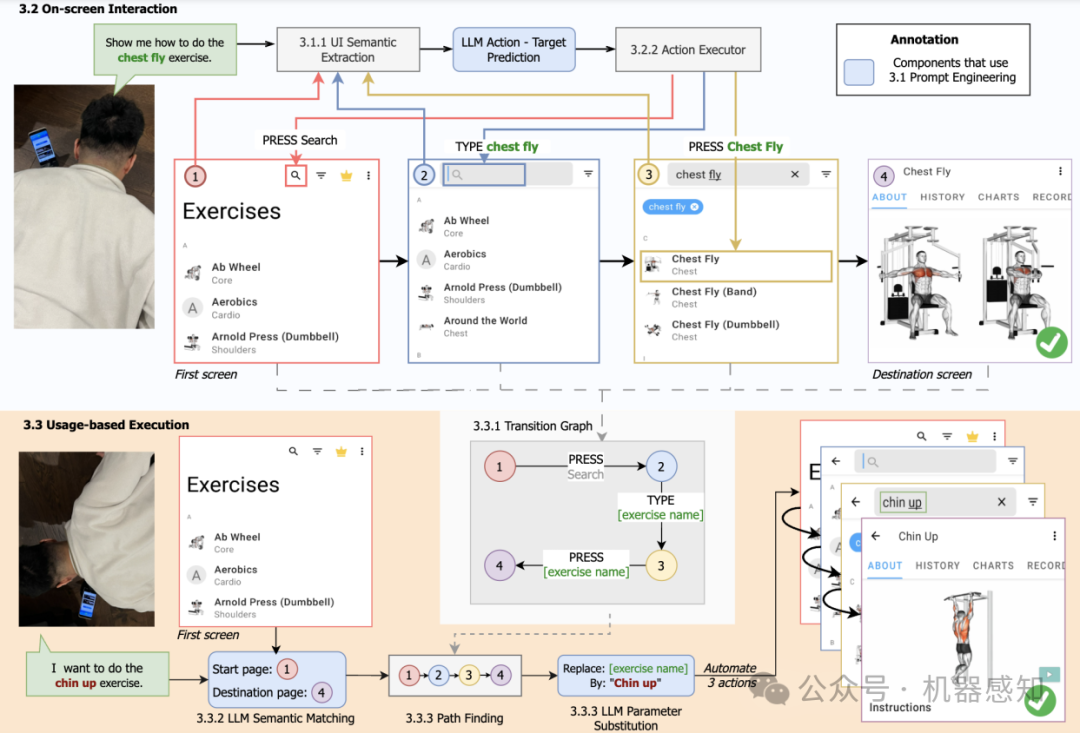
Virtual assistants have the potential to play an important role in helping users achieves different tasks. However, these systems face challenges in their real-world usability, characterized by inefficiency and struggles in grasping user intentions. Leveraging recent advances in Large Language Models (LLMs), we introduce GptVoiceTasker, a virtual assistant poised to enhance user experiences and task efficiency on mobile devices. GptVoiceTasker excels at intelligently deciphering user commands and executing relevant device interactions to streamline task completion. The system continually learns from historical user commands to automate subsequent usages, further enhancing execution efficiency. Our experiments affirm GptVoiceTasker's exceptional command interpretation abilities and the precision of its task automation module. In our user study, GptVoiceTasker boosted task efficiency in real-world scenarios by 34.85%, accompanied by positive participant feedback. We made GptVoiceTasker open-source, inviting further research into LLMs utilization for diverse tasks through prompt engineering and leveraging user usage data to improve efficiency.
Rethinking Patch Dependence for Masked Autoencoders

In this work, we re-examine inter-patch dependencies in the decoding mechanism of masked autoencoders (MAE). We decompose this decoding mechanism for masked patch reconstruction in MAE into self-attention and cross-attention. Our investigations suggest that self-attention between mask patches is not essential for learning good representations. To this end, we propose a novel pretraining framework: Cross-Attention Masked Autoencoders (CrossMAE). CrossMAE's decoder leverages only cross-attention between masked and visible tokens, with no degradation in downstream performance. CrossMAE matches MAE in performance with 2.5 to 3.7x less decoding compute. It also surpasses MAE on ImageNet classification and COCO instance segmentation under the same compute.
Deconstructing Denoising Diffusion Models for Self-Supervised Learning

In this study, we examine the representation learning abilities of Denoising Diffusion Models (DDM) that were originally purposed for image generation. Our philosophy is to deconstruct a DDM, gradually transforming it into a classical Denoising Autoencoder (DAE). This deconstructive procedure allows us to explore how various components of modern DDMs influence self-supervised representation learning. We observe that only a very few modern components are critical for learning good representations, while many others are nonessential. Our study ultimately arrives at an approach that is highly simplified and to a large extent resembles a classical DAE.