文章目录
- 飞天(Apsara)云计算平台简介
- 面向私有云的Apsara Stack
- 盘古横空出世
- 盘古的架构
- 盘古基本介绍
- 盘古API
- 基于C++语言的SDK
- 基于命令行的文件操作接口pu
- 盘古中的目录和文件
- 盘古目录
- 盘古中的文件
- 盘古中的文件类型
- 盘古应用场景
- 盘古的功能特性
- 盘古主要性能
- 盘古的数据安全
- 盘古的边界
- 盘古支持的文件数和目录数
- 盘古2.0
- 盘古2.0简介
- 背景介绍
- 行业趋势
- 业务挑战
- 设计目标
- 优化系统架构
- 全分布式元数据管理
- 卓越性能
- 优化成本
- 弹性部署易运维
- 架构设计
- 核心基础层
- Scale-out的元数据管理
- Non-Stop Write
- 变长Chunk
- 多种chunk冗余策略
- 高效线程模型
- 高性能网络库
- 单机存储开放接入
- 用户态文件系统
- Chunk Layout
- 端到端的数据完整性校验
- 多可用区支持
- 多介质大存储池支持
- 弹性部署
- 自动化部署与运维
- 块存储系统层
- 性能数据
- 后续规划
- 稳定性
- 性能
- 成本
- 部署运维
- 参考链接
自从有了飞天计算平台,中国云计算的面貌就焕然一新了。
飞天(Apsara)云计算平台简介
2009年,阿里云开始打造云计算的基础服务平台,并写下了飞天的第一行代码。
飞天平台内核包含的模块可以分为以下几部分:
- 分布式协调(女娲)
- 远程过程调用(夸父)
- 分布式文件系统(盘古)
- 资源管理和任务调度(伏羲)
- 集群监控(神农)
- 集群部署(大禹)

飞天的整体架构如下:
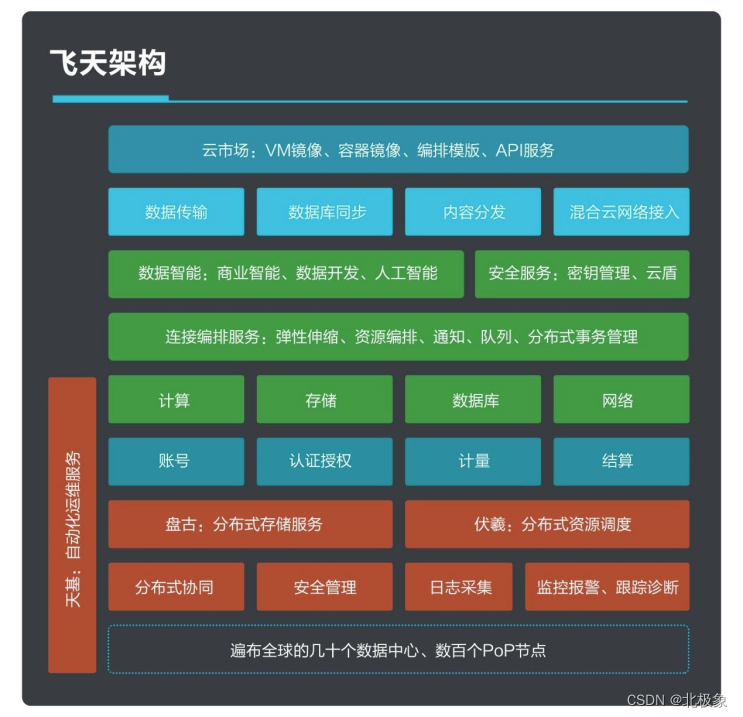
盘古是飞天中的分布式文件系统组件,盘古将并不高可靠的PC服务器中的磁盘连接成一个整体,向外提供安全稳定易用的文件存储能力。
面向私有云的Apsara Stack
Apsara Stack和飞天公共云计算的技术体系一脉相承,是将飞天内核以及内核之上的一部分云产品经过优化后,可独立部署的系统。它是飞天的一种特殊部署形式,在物理设备达标的情况下,具备和飞天公共云一样的规模、性能、稳定性和通用性。
盘古横空出世
沧海横流,伏羲女娲都已逐步升级和替代,唯有盘古稳如磐石,岿然不动。
自2009年盘古的第一行代码到今天已经过去了将近五个年头。在早期,盘古整体的设计思路参考了google的GFS和Apache HDFS。五年的演进使得今天的盘古成为一个稳定高效且具特色的分布式文件系统。
今天盘古支撑了集团和阿里云的很多业务,包括:ODPS、搜索、云主机ECS、云存储OSS、OAS、OTS、SLS、Streaming等,管理了约5万(?)台服务器的约50万块硬盘,总物理空间接近1EB。盘古已经成为阿里巴巴重要的数据持久化基础设施。
盘古提供了如下的核心价值:
-
数据安全
盘古通过数据多副本技术来保证数据安全,并不要求磁盘本身的高可用性。因此盘古可以架设在PC server和SATA盘上,并不要求磁盘本身通过RAID来保证数据安全性。同时,因为盘古将数据打散到整个集群,在发生故障时能更快的做出数据的副本,保证数据安全。盘古默认情况下数据是3副本,能够保证数据极高的安全性。具体的安全性数字和推导过程参看【数据安全】 -
服务高可用
存储服务本身是任何IT系统中最基本的服务之一,必须提供高可用性。盘古对外承诺两个层次的高可用性:数据的高可用性,单机、单rack的fail数据必须仍然能够读写;服务的高可用性,盘古文件系统能够不受大部分硬件故障的影响而继续提供服务,这里主要指盘古master的高可用性。
盘古通过多master机制来保证master的可用性。盘古的多master机制是主从机制,默认情况下3台master中有一台为primary,两台为其热备secondary master。主从之间通过Paxos算法来保证内存处于一致的状态。使用Paxos能够在2台master达成一致就返回,在保证服务高可用的同时降低服务的延时。
关于多master的具体设计设计请参考【多master】
- 单一命名空间
无论管理几百台还是几千台存储节点,盘古呈现给用户的是单一的文件系统命名空间,用户无需关注数据分布在哪几台服务器上,只需通过盘古API来以文件流的方式使用任意的存储空间。
需要注意的是盘古目前不直接支持Posix文件接口,存取盘古文件必须通过盘古API。在工具中盘古发布了Fuse模块,在安装了Fuse包的Linux上可以实现以Posix方式挂载盘古文件系统。需要注意的是Fuse模块只实现了部分功能。
盘古的架构
类似于GFS的架构,盘古文件系统中有两类server节点。
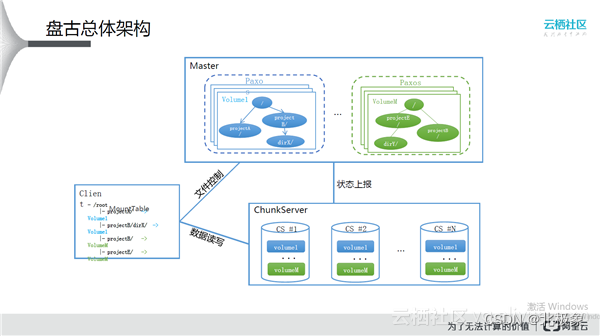
Master
Master运行在单独的Master服务器上,有特定的硬件要求。
Master上存储盘古所有的元数据,包括命名空间(目录树),文件和数据块之间的映射,quota数据,chunkserver元数据等等。Master节点对盘古非常重要,绝大多数API中都包含了同Master之间的RPC,如果Master节点不服务盘古整体就不可用。
盘古通过多master机制保证master的高可用性,同时使得盘古具备热升级的能力。
Master所有元数据都存储在内存中,因此能提供很高的服务能力。为了防止断电丢失数据,master会周期性的将内存中的状态写到磁盘上,叫做checkpoint文件。同时,每次对metadata的修改都会记录到op(eration log)中。用户的写操作只有当primary和至少1台secondary的op log落盘成功以后才能得到返回。为了保证sync 写op log不成为盘古 master的性能瓶颈,盘古要求master节点配置上带有电池的Raid卡。
master之间log的同步和主master的选举采用了Paxos算法来保证其一致性。
逻辑上master节点是盘古集群中的单点,整个集群的最大文件数取决于master节点的内存大小,metadata的访问能力取决于master节点的网络和CPU边界。在0.15中盘古会支持Federation功能来弱化单点的能力对整个集群能力的限制。
Chunkserver
Chunkserver运行在数据节点上,相当于HDFS中的Datanode,主要的职责是管理本地的硬盘和支撑对硬盘的读写删操作。
Master与Chunkserver的交互 TODO:sniff,replication…
盘古基本介绍
盘古API
盘古对外提供了几种API:
基于C++语言的SDK
主要面向开发者,包含通过FileSystem接口实现metadata相关的操作(主要同master通讯)。另外基于各种Stream的数据存取接口。
API说明及示例请参考SDK中包含的pangu.h中的注释,以及下面的文档【API文档】。
基于命令行的文件操作接口pu
面向终端用户或者系统管理员。通过pu用户可以对盘古文件系统中的目录或者文件进行拷贝、创建、删除、修改等操作。使得用户无需编写代码即可操作盘古文件。
pu命令的详细说明和示例请参考如下【链接】。
基于命令行的管理接口puadmin
盘古文件系统的管理和维护功能主要通过puadmin命令进行,未来会C++提供API。
puadmin命令的详细说明和示例请参考如下【链接】
盘古中的目录和文件
从用户的角度看,盘古中的数据是组织在文件中的。
盘古地址
文件由盘古地址来索引,盘古地址的格式如下:
pangu://localcluster/dir1/dir2/file1
盘古地址分为两个部分:
pangu://localcluster对应了盘古primary master的nuwa地址
/dir1/dir2/file1对应了该master下盘古文件的路径
注意:
当盘古地址末尾添加/时,盘古会认为该entry是一个目录,如: pangu://localcluster/dir1/dir2/
当盘古地址末尾不包含/时,盘古会认为该entry是一个文件。盘古总是根据末尾的/来首先区分是目录还是文件。这点同Linux环境下并不相同,通常的文件系统并不依赖名字来区分其属性。
当操作盘古master时需要提供盘古master的nuwa地址,如下所示:
nuwa://AT-10:10240/sys/pangu/PanguMasterRole/rs3d9000.eta
盘古目录
前文中已经提到盘古中文件元数据均存在于master内存中。盘古目录信息也是这样。 盘古目录存在于逻辑上的一颗树结构中。物理上盘古通过最多两层的hash来存放某个特定目录的子entry(子目录或者文件)信息。
目前盘古对目录深度和某个目录下的entry数上限并没有限制。但是用户需要注意:
不建议盘古目录深度超过32层,因为盘古master解析路径是按照层次进行的,时间复杂度线性于目录深度。
不建议某个特定目录下的entry数目超过10k,最好在几k级别以内。这是因为盘古内部的双层hash总的桶数目是1024,当出现冲突的时候会在桶内形成链表来解冲突。在hash平均的情况下,10k的entry数会使得平均每次查找要编译长度为10的链表,降低master的效率。
盘古中的文件
同GFS/HDFS类似,盘古提供了NormalFile来提供高吞吐量类型的数据访问能力。应用对盘古的不同需求促使盘古超过了GFS、HDFS的范畴,提供了更为丰富的文件类型。本节来描述同盘古文件相关的概念。
文件的属性
类似单机文件系统中的inode,盘古内部使用一个叫做FileNode的数据结构来描述文件的metadata。盘古中的meta包含如下内容:
拷贝数(min, max),或者对于raidfile的数据块和冗余块
文件长度
app/part
文件类型,可以是Normal File,Log File, Raid File, RAF等
压缩类型
创建时间
最后修改时间 可以通过命令行"pu",或者API中的FileSystem::GetFileMeta?()来取文件属性。
Locality 属性
在某些应用场景下,应用程序希望数据分布能符合一定的规律。 在盘古文件系统中,用户可以通过APP/PART的概念把一组文件聚集在同一台物理机上。
对于Normal File和Log File,用户在创建文件的时候可以指定Application ID和Partition ID两个字符串性质的属性。这两个string本身盘古不去做解释,只是当作标识符来匹配,并在分布数据的时候保证如下规律:
用户自定义的APP ID和PART ID时,文件不同的chunk的数据一定是聚集在一起的,我们称之为扎堆。也就是说,对于一个3 copy的文件,如果指定了自定义的APP ID和PART ID,只会有3台CS包含该文件的数据,每台CS上hold一份copy。
相同的APP ID和PART ID的文件一定分布在相同的物理机上
相同APP ID,不同PART ID的文件一定分布在不同的物理机上
[注意]
同一个partition 中chunk扎堆到100GB的时候,对于超过100GB的内容一根柱子会开始随机分配chunk的位置。用户可以通过如下master flag来调整该值:pangu_master_PlacementPartitionChunkLimitForOne
这是为了防止在1台cs failover后replication只能从另外两台cs来拖数据导致数据安全受损。
当同一个partion中的数据扎堆到1TB时,所有柱子都会被打散分配。理由和上面相似。
使用LOCALFILE APP/PART受到单机容量的限制,在某台CS持续写入local file,因为盘古会持续将一份replica分配到本机,有风险将某台CS空间全部吃光。后继的写入会失败。这点需要应用程序尤其注意
app/part只对normal file和log file生效,raidfile/raf/tempfile均没有相关属性。
盘古中的文件类型
盘古中文件分为多种类型,分别适用于不同的应用场景。
Normal File
应用场景
特点
使用注意事项
Raid File
应用场景
特点
使用注意事项
Log File
应用场景
特点
使用注意事项
Random Access File
应用场景
特点
使用注意事项
Temp File
盘古应用场景
盘古的功能特性
盘古的功能特性
盘古提供读写,创建,删除,查询等基本的文件系统的API。
盘古提供类似Linux中ls,cp,touch,cat,rm等工具,方便的查看和操作盘古文件,拷贝命令支持断点续传功能。
用户通过minCopy, maxCopy指定盘古文件的副本数,盘古保证数据最少有minCopy份副本,尽可能的有maxCopy份副本。
盘古提供用户自定义的数据聚簇方式,用户根据应用场景可以选择数据是打散存放,还是本地优先扎堆存放,还是所有副本都扎堆存放。
盘古提供目录的Quota,用户可以指定目录下最大的文件数和文件占用空间。
盘古提供多master机制,保证服务的高可用性,元数据的安全。
盘古支持不停机升级方案。
盘古提供优先级控制,保证后台复制的过程中,不影响前端的读写服务。
盘古提供数据rebalance操作,保证数据均衡。
盘古提供端到端的数据安全解决方案。
盘古分别提供适合高吞吐率,低延迟,随机访问等不同应用场景的解决方案。
盘古提供基于SSD的磁盘解决方案。
盘古提供慢盘规避策略保证不受到磁盘故障的影响。
盘古提供丰富的配置信息,方便的优化系统在特性场景下的表现。
盘古提供高效的内存管理策略
盘古提供数据压缩功能
盘古提供丰富的监控系统,规范的异常体系,以及完善的错误日志,方便问题调查和错误排查。
盘古提供丰富的使用手册和运维手册
see more
盘古主要性能
盘古的可用性:99.9%
盘古的数据可靠性:99.99999999%(10个9)
盘古远程读的Throughput(Normal file)
盘古远程写的Throughput(normal file)
盘古读写的latency(log file)
盘古master的QPS
盘古master切换速度
盘古重启的速度
盘古一块磁盘损坏后数据恢复的时间
盘古一台机器宕机后数据恢复的时间
see more
盘古的数据安全
http://wiki.aliyun-inc.com/projects/apsara/wiki/PanguDataSecurity
盘古的边界
盘古支持的最大集群
从盘古0.11版本开始,盘古支持的最大cs的规模是5000台(实际生产集群)
盘古正在开发Master Federation功能,目标是支持50000台规模的集群
盘古支持的文件数和目录数
盘古所能支持的最大文件数(包括目录)是由如下因素制约:
a) 盘古自身架构的限制。在目前版本中文件数的架构上限是40亿,chunk的架构上限也是40亿。这点目前看来并不是瓶颈。
b) 盘古master所在server的内存。盘古把meta信息全部存储到了内存中。这个是现实中的制约因素。考虑到做checkpoint的需求,盘古master内存使用上限是70%的物理内存。
生产环境下目前的上限是5亿左右,这时盘古master进程使用到了140G左右的内存。 测试环境下测试过的上限是6亿。原理上master内存够用的时候,盘古可以支持更多的文件。
盘古支持的最大文件名长度
盘古默认没有限制最大文件名长度。但是需要了解到长的文件名会导致盘古master进程使用更多的内存。建议文件名不要过长。不建议使用文件名长度超过255字节。
盘古支持的最大目录层次
盘古理论上不限制目录深度,但是在过深的目录会影响master效率。建议目录深度不超过32.
单目录下的最大文件数 在单个目录下盘古通过双层hash,每层都有32个桶。也就是最好情况下1024个文件时能高效查找。尽管盘古没有限制单个目录下的最大文件数,建议单目录子文件、目录数不要超过10000。 测试表明超过10000时盘古master效率会明显降低
盘古支持的最大文件尺寸 normal file/raid file/log file: temp file:
盘古支持的最大副本数
盘古和操作系统
盘古2.0
盘古2.0简介
盘古2.0是第二代自研开发的分布式存储系统,在高性能、大规模、低成本等方面深度挖掘了系统的极限能力,支持更丰富的接入形态,进一步提升了系统的部署运维自动化智能化能力,同时继承了1.0在高可靠、高可用、数据强一致性等方面的积累优势。
目前,盘古2.0已经在阿里云数据库、中间件、蚂蚁金服、HiStore等场景上线,感谢过去1年来阿里云块存储、集团数据库、集团中间件、蚂蚁金服统一存储等兄弟团队与我们一起背靠背共同战斗,打磨系统,迎来2.0的发布。更多的业务正在上线中。

背景介绍
行业趋势
近年来,存储行业及其上下游呈现出几个明显发展趋势,这些趋势影响着我们对盘古发展方向的思考。
网络和存储硬件向着高吞吐低延迟的方向不断发展。网络环境上,从主流千兆网发展为双万兆,更高性能的RDMA很快将在公司铺开,规划中的100G网络将在19年初大规模应用;存储介质上,从经典HDD到NVMe SSD、3D XPOINT。新硬件us级别的延迟,使得性能瓶颈从网络、磁盘转移到了存储软件栈;新硬件的持续导入,在考验着存储软件架构的前瞻性。
网络和存储的配套访问软件在随硬件快速进化。传统的内核态TCP、内核态文件系统被重新审视,一系列低延迟访问技术试图走向舞台中央:Userspace TCP引起高度关注,RDMA网络技术将在集团落地,SPDK等用户态存储访问技术也被广泛尝试。软硬件一体化的设计和优化,成为存储产品进化的必然方向。
新的存储形态和存储产品不断涌现。Flash Array,Hyper-Converged,Unified Storage,SDS等新存储形态逐渐被用户接受,ScaleIO,XtremIO,Nutanix,MapR,Infinidat,Hedvig等新存储产品层出不穷。如何博采众长、去芜存菁、持续创新,引发着存储人的不断思考。
业务挑战
随着业务的高速发展,以及集团存储中台战略的不断落地,应用对盘古提出了全方位的更高要求。
性能方面:集团在大力推广存储计算分离,数据库、搜索服务、高性能云盘等落地场景中,在线应用对性能极为敏感,都对盘古的延迟、延迟稳定性和吞吐能力提出了非常高的要求。
服务质量方面:集团正在推在离线混部和离在线混部,作为公共底层存储的盘古,需要提供性能隔离能力,保障混部服务质量。
功能方面:更多的企业级存储功能被提上日程,比如原生快照、备份、容灾、端到端数据校验等。
规模方面:数据业务持续发展,让大数据计算场景对盘古文件数的要求不断提高。
接入形态方面:兼容成熟的公开接口是扩大接入范围的必要能力,支持HDFS接入的需求日渐强烈,支持POSIX接入也被多个应用方提出。
成本方面:市场竞争日趋激烈,面对着友商抢占市场份额的价格战,面对不惜倒贴来拉拢创业者的云平台,必须用技术把成本压到极致,才能为商业赢得主动。
部署运维方面:公有云业务规模越来越大,专有云部署范围越来越广,边缘计算等新部署场景不断涌现,部署运维的自动化、智能化成为一个必选项。
这些全方位的更高要求,需要盘古在架构设计、工程实践等多个维度设立新的目标,实现新的突破。
设计目标
为了应对上述新趋势和新挑战,盘古2.0确立了五大核心设计目标:
优化系统架构
优化系统架构,迎接各条业务线上形态各异又迅速变化的用户需求,同时为将来向大存储池、底层存储服务化方向演进做准备。
通过建设一个公共的盘古基础核心层,包含单机存储引擎、多副本协议、元数据管理、磁盘管理、数据放置策略、数据校验、纠删码等最基本的功能,形成核心竞争力。
在上层架设相应的产品适配层,分别适配云存储产品如块存储、文件存储、对象存储,表格存储,队列,日志等场景,大计算处理如ODPS系统,数据分析如ADS等系统。
通过分层的系统架构,让更多的兄弟团队协作开发,也让盘古自身更快速的迭代。
全分布式元数据管理
通过元数据的全分布式管理及动态切分和迁移,大幅提升管理的文件数规模,去Meta节点特殊机型依赖,也进一步降低故障“爆炸半径”,提高平台稳定性。
卓越性能
面向新一代网络和存储软硬件进行架构设计和工程优化,释放软硬件技术发展的红利。
优化成本
全面采取EC,压缩、TRIM、去重等技术,降低存储成本,为日益激烈的商业竞争赢得主动权,为应对数据量爆炸式增长赢得技术优势。
弹性部署易运维
适应多种部署形态,规模可从三台扩展至上万台服务器。支持独立输出盘古,提供和客户既有的监控、运维系统API级别的对接。管理平面和数据平面完全分离,管理接口以RESTful API形式服务化。
架构设计
为了达成前述目标,盘古2.0采取了如下图所示的分层架构(由于篇幅的原因,产品层没有全部列出来)。
下文将主要介绍其中广义的“核心基础层”(pangu core),包括图中盘古核心基础层、单机存储引擎层以及软硬件一体化层,概述其中的关键技术和功能,本文末尾的文章列表中会详细展开每个关键点。关于“块存储系统层”,将在专门系列文章中另做深入介绍。
核心基础层
pangu core专注于单机存储引擎、多副本协议、元数据管理、磁盘管理、数据放置策略、数据校验、纠删码、分层存储、混合多介质等基本功能,解决一致性、高可靠、高可用、低延迟、高吞吐、QoS等基本问题。
pangu core的整体架构和data path如下图所示。ChunkServer负责管理本机存储空间,以及分配到该节点的chunk的读写。RootServer、MetaServer和NameSpaceServer是meta管理结点,一起管理系统的meta信息。RootServer维护NameSpaceServer和MetaServer的元信息,NameSpaceServer维护目录树,以及file与stream的关系,MetaServer维护stream与chunk的关系,以及chunk的分配信息。Client通过与各个元数据管理结点交互获取操作的meta,把数据操作分解到chunk级,然后和ChunkServer交互完成chunk的数据操作等。
pangu core层的建立,使得整体系统的架构更松耦合,方便同时开展pangu core层的软硬件一体化、单机存储引擎、ChunkServer控制层,pangu core meta层,pangu core client,以及基于pangu core打造极致性能的块存储等多个分解的目标上的打磨。
pangu core中包含了一系列的关键技术:
通过scale-out的元数据管理设计,去除了盘古1.0中对Master高配机型的依赖,提供了(近乎)无限的文件数目的支持,并减小了系统出故障时的爆炸半径;
FlatLogFile的接口,提供高性能的顺序写随机读能力;
通过2-3异步写,FileGroup,快速切Chunk等技术优化写延迟;
通过Backup read,可变副本数等方式实现了读优化;
通过InlineFile帮助上层应用实现假死节点的快速切换;
通过IO路径的E2E checksum和后台的checksum扫描,保证数据的安全性;
通过多可用区(AZ,Availability Zone)实现跨地域容灾;
通过run-to-completion并发模型,EasyRPC plus RDMA,SPDK plus用户态文件系统,Zero Copy等技术实现性能优化;
通过部署、热升级的自动化,以及自动化的机器磁盘上下线、故障自愈、自动巡检、告警体系、基线异常检测、环境标准化等手段提升可运维性;
通过混合机型、分层存储、EC、压缩等实现成本的优化;
。。。
下面着重介绍一些pangu core中的关键功能和技术。
Scale-out的元数据管理
盘古2.0采用分布式的架构来管理元数据,主要有三类元数据:
1)Chunk:一段字节流,由全局唯一id标识
2)Stream:多个chunk组成的一段字节流,由全局唯一id标识
3)File:目录树中的一个stream,由目录树中的路径唯一标识
Chunk是数据的基本存储单元,Stream是对多个有序chunk的封装,File则在stream的基础上添加了树型目录结构。此外,还有少量的Root Meta存储一些基本的信息,例如Namespace Server和Meta Server的partition信息。
上述的meta由三种结点来管理,分别是RootServer、Namespace Server和Meta Server,它们都使用RAFT协议来实现高可用和三副本强一致。File meta按照namespace进行切分后被多组Namespace Server管理,stream meta按照stream id切分后被多组Meta Server管理,meta server同时也管理着stream对应的chunk meta。RootServer直接将root meta存放在各自的本地磁盘,而其他角色则将meta分布式地写到特殊的meta chunk组成的stream中,这些特殊的meta chunk stream被RootServer直接管理。
meta.png
这种scale-out的meta server设计,使得单集群不再有stream/file数上限。同时由于meta server故障只会影响一部分meta partition,减小了故障的爆炸半径。
对于负责目录树功能的NamespaceServer而言,由于相比1.0的PanguMaster职责更单一,也获得了更好的scale-out能力,能服务的文件数更多。
特别指出的是,所有meta管理结点都不依赖特殊的机型。
FlatLogFile
pangu core层主要提供一种称为FlatLogFile的文件接口,对用户呈现顺序写和随机读的语义,类似于本地文件系统的流,但FlatLogFile不支持随机写。FlatLogFile是最简单的数据模型,把原来多种文件类型统一到这种单一的文件,可以提高底层存储的效率,scale能力和容错能力,同时支持多种写模式使上层应用更灵活。
flatlogfile.png
如上图所示,FlatLogFile的语义由pangu core中各个角色协同来实现。Namespace Server管理目录树,负责维护File到Stream的映射;MetaServer维护Stream到Chunk的映射,以及Replica的信息;数据传输则直接在FlatLogFile SDK和Chunkserver之间进行。
多种写模式
FlatLogFile支持从数据流拓扑、buffer/direct、写透的份数三个维度上进行配置,帮助用户进行多种权衡。
FlatLogFile支持“星型写”和“Y型写”两种数据流拓扑:
星型写:直接从client写到多个Chunkserver。适合客户端与存储节点混布的场合,数据路径需要1跳网络,有更短的延迟;但是,当存储计算分离时,星型写需要更多的存储集群和计算集群间网络带宽。
Y型写:client先写到一个Chunkserver结点,由其再转发给另外两个Chunkserver结点。克服了带宽问题,但需要2跳网络,会增加延迟。此外,Y型写还用于解决文件多客户端写的问题。
FlatLogFile也支持buffered写和direct写。前者强调更高的throughput,适合离线计算和后台compaction写等操作;后者强调更低的延迟,适用于前台写操作,如块存储的写操作,journaling的写操作等。
FlatLogFile还支持设置需要写透的份数,例如3-3写(写透3份才返回),2-3写(3份中写透2份即可返回)。3-3写提供了更高的数据可靠性,但可能因为网络、介质的波动,或者系统的热点引入毛刺。2-3写能帮助克服毛刺,提供更好的延迟稳定性。写透2份数据返回用户成功和第3份数据被后台补足期间,有秒级到分钟级的时间空隙。经过推算,2-3写保证了10个9的可靠性。EC写同样支持这样的配置。
Non-Stop Write
FlatLogFile的写入流程遇到结点failure时,只要还有一个可用副本,就能够快速切换到新的chunk,写入新的位置,并在后台异步完成failure chunk的数据复制。而在基于RAFT/Paxos实现的写入路径中,当遇到非大多数副本的failure时,剩余正常副本要同时参与前台写和后台数据复制;而一旦遇到大多数副本的failure时,数据写入和副本替换都无法进行,系统将不可用。
变长Chunk
FlatLogFile支持Chunk最大长度的可配置,同一个File内部的chunk大小也允许不同。
更大的chunk可以带来更少的meta量和更少的meta操作压力,更小的chunk则可以让chunk数据复用更精细。同一个File内部允许chunk可变长,既使得Non-Stop Write成为可能,又使得用户利用Chunk API在不同chunk大小的stream间复用Chunk时更为灵活。
多种chunk冗余策略
pangu core同时支持多副本和EC(Erasure Coding)两种chunk冗余策略,为不同业务场景提供了多种选择。
用户可以根据场景需要选择单副本、2副本、3副本,或者更多的副本数,用户可以在创建文件时通过参数指定副本数,也可以通过专门的调用来调整。
pangu core层的EC能力可以广泛应用于多种业务,默认8+3的EC配置将存储的成本降到约1.375份。不同于盘古1.0的是,在2.0中支持Direct EC,也即前台的数据直接写成EC形式。这对OSS等应用优化网络及IO流量有重要意义。
高效线程模型
Data path采用了run-to-completion并发模型,IO请求的整个处理都在同一个线程中完成,节省了线程间同步、CPU的cache miss、context switch等开销。为了利用此并发模型获得极致性能,盘古从底层的RDMA/TCP网络库、SPDK IO库,到业务层的各个模块都精心设计,全链路打通。
这种线程模型为我们带来了极大的性能优势。在LBA对齐写NVMe SSD的情况下,实测chunkserver内部软件栈耗时在1us以下。
高性能网络库
我们将RDMA网络访问封装到EasyRPC内部,对上层透明,保证了部署的弹性。经过优化的RDMA访问延迟,在典型的写条件下(4k写请求+64bytes响应),延迟为6+us。
同时我们也在密切关注集团使用Userspace TCP的情况,EasyRPC团队也正在接入mTCP。
单机存储开放接入
我们将ChunkServer对单机存储的需求提炼成为BlobStorage接口规范,为Chunk Server软件栈屏蔽底层存储接口的多样性和快速演变。基于BlobStorage我们希望联合各个团队为Chunk Server构建一个开放、良性竞争的单机存储生态,保持单机存储软硬件在成本、性能、技术先进性上的优势。
用户态文件系统
我们基于Intel SPDK为Chunkserver定制了一个用户态文件系统,提供了极致的IO访问性能。用户态文件系统直接管理NVME SSD盘的LBA空间,实现了全内存的meta访问和基于FAT(File Allocation Table)的空间管理,将连续的LBA空间抽象为Blob,提供无锁、全异步的Blob的CRUD接口。
Chunk Layout
Chunk Layout是chunk在磁盘上的格式,能够保证数据写入的原子性,解决数据“写放大”问题,且便于meta损坏时的数据恢复。
块存储的应用对写延迟特别敏感,对于其中LBA对齐的前台写场景,要尽量保证IO路径上每个LBA的写只对应磁盘上的1个LBA的1次写,避免产生“写放大”。
端到端的数据完整性校验
Chunk Layout为每个sector保留了footer,其职责之一是维护sector的CRC信息。用户通过SDK可选的提供CRC,相应的Chunkserver接收到请求后,验证请求本身的完整性。Chunkserver根据数据落盘位置按sector分拆请求,更新sector的CRC;同时解决了非对齐写情形下的原子性问题(物理盘上的sector可能是512bytes,盘古以4kbytes为单位使用)。另外,后台低优先级任务周期的扫描chunk的数据,校验数据的完整性。
多可用区支持
盘古2.0沿用了1.0的多AZ(Availability Zone)能力,用户能够通过“两城三机房”等部署模式提供更高的数据可靠性和可用性,也能利用多AZ控制数据分布实现大规模分批OS升级等功能。用户可以在file级别指定数据的可用区要求(例如,只写client本zone,必须写三个zone)。
多介质大存储池支持
盘古2.0支持异构介质的大存储池,在Chunkserver内部能够混合使用SSD、HDD等多种介质,支持将不同文件或文件的不同replica放置到指定的不同介质上。用于业务元数据/数据,前台/后台数据等对容量、性能、成本等维度的不同要求,同时用于业务为用户实现不同的SLO,另外,大存储池用于多个业务的混布。在更大的存储池里实现资源分配利于提高资源利用率。
弹性部署
弹性部署是pangu core的重要特征。
盘古支持的上层产品,跨度巨大,包括块存储、数据库、OSS、OTS、NAS、ADS、ODPS等:
部署规模从3台到10000+台;
包括全HDD、SSD+HDD混合存储、全SSD等存储介质;
单机容量从几个T,到貔貅机型最大单机容量500+TB;
支持离线、在线、在离线混跑等多种形式;
多种访问方式,顺序,随机,数据流,记录流;
……
所有这些不同的部署形态,底层基于同样的存储核心,共享同样的data path!
自动化部署与运维
盘古2.0支持部署、热升级的自动化,通过自动化的机器磁盘上下线、故障自愈、自动巡检、告警体系、基线异常检测、环境标准化等手段提升可运维性。
特别指出的是,盘古2.0与具体部署运维系统松耦合,能够支持小型化部署。
除了上述介绍外,pangu core层沿用了盘古1.0的大量功能,如chunk placement,replication等,这些功能点不在本文一一赘述。
块存储系统层
块存储系统层基于pangu core提供块存储功能。
经过反复比较和PoC之后,盘古2.0选用了Log-Structured Merge Tree(LSM tree)方式实现块存储,称为LSBD(Log Structured Block Device)。具体而言,块设备上的各个LBA被映射到若干append-only的data流中,LBA与数据位置的映射关系记在另外的index流中。特别地,data流中的format设计为自包含,即使index文件缺失也能从data文件中重新构造出来。这使得只有data写操作在IO关键路径上,而index只需要异步更新。Index的内容也采用LSM tree思路,以checkpoint加journal的形式组织。
LSM tree的设计带来了诸多的优势。由于LSM tree只依赖了append-only的流,压缩与EC的复杂度都变得更可控,成本控制相关的feature更易于实现。同时log structure也能让快照、备份、连续数据保护等高级功能的实现更加便利。
当然,LSM tree的设计由于需要处理data和index的garbage collection(GC),会带来一些空间、网络流量和CPU资源的消耗。但是,这些消耗通过精细的优化被控制在了可接受范围之内。
块存储层的整体架构如下图所示,block逻辑建立在pangu core层的FlatLogFile之上。
如下图所示,云盘的逻辑空间被划分为若干个32G所有size的segment,segment被BlockMaster调度到BlockServer,由BlockServer负责处理块相关IO逻辑。
性能数据
盘古用V41机型(Mellanox双25G网卡、NVME SSD硬盘)测试了2.0的极限性能,测试方法是使用fio读写盘古块设备,存储计算分离架构,两跳网络使用RDMA协议通讯,磁盘使用SPDK+DPDK读写。单路4k读写e2e延迟极低,4k写延迟软件栈耗时约为3us。单客户端极限测试,4K随机读/写的IOPS峰值分别为130/110万,比较接近打满测试机双25Gb网卡。
关于块存储,有专门的文章做更系统的介绍,本文不再展开。
后续规划
盘古2.0当前还在不断的演进当中,我们将继续在多个方面发力,比如:
兼容成熟存储接口:由于业务的需要,后续我们会支持HDFS和POSIX接口,让Hadoop生态和其他基于POSIX接口的开源系统能够方便的接入盘古平台。
与广泛存在的LSM tree存储进行协同优化:大量基于文件系统的存储系统都使用了LSM tree结构(e.g. OSS/OTS、盘古块存储层、XEngine、HBase等等),大家面临的一个共同难题是compaction的资源消耗。不同业务线都发现,在compaction过程中有大量数据块是未修改的,复用而非重写这些数据块能够大幅降低网络带宽和IO消耗。我们正在开发chunk API与业务一起E2E优化。
软件和硬件层面的QoS:存储介质和网络上高低优先级的混合流量成为常态。一方面,需要为用户提供软件层面的精细QoS控制,比如OSS, OTS, HBase, XEngine等大量场景中需要QoS来保证前台访问性能,又比如搜索服务的前台流量和索引发布流量也有明显的优先级要求;另一方面,由于压测发现原生的硬件接口缺乏良好的隔离性,我们也在考虑软硬件一体化的方案,比如Open Channel SSD和Object SSD等技术,实现更精准的IO隔离。
软硬件一体化优化成本:结合pangu core的数据模型的特点,我们也在考虑引入消费级SSD,通过和NVDIMM, 3D XPOINT等技术的结合,更进一步优化成本。
与此同时,我们真诚欢迎各个兄弟团队一起交流需求与经验,共同推进阿里巴巴在存储领域的创新!
稳定性
减少爆炸半径 基于全分布式元数据管理的爆炸半径的控制
non-stop IO 数据关键路径快速容错软硬件异常及热点规避
快速数据恢复 基于网络可用带宽,动态调节复制流量,加快数据复制
多AZ 跨地域数据容灾有的不只是数据安全,低成本高性能一个都不能少
数据一致性协议 对CAP与BASE的思考和数据强一致性的实现
性能
chunkserver线程模型设计 如何保证chunkserver无锁零拷贝的高性能
2-3异步写 大多数副本同步写技术解决写长尾问题
NVDIMM的现状与应用 采用NVDIMM非易失性存储介质优化存储系统IO Pattern
SPDK多进程机制 全用户态访问的NVMe设备,管理平面不可少,iostat/tsar应有尽有
成本
Erasure Coding 新版EC File实现,支持应用数据直接写EC
TRIM 分布式系统及时感知,动态回收用户层面的无效数据
消费级SSD 基于低成本SSD也能实现高可靠高性能的存储系统
Optane 盘古对3D XPoint技术的分析和思考
部署运维
热升级 在线升级20万台存储机器
机器与磁盘的自动上下线 一键机器、硬盘上下线
故障自愈 完备修复存储系统故障
自动巡检 快速检查20万台机器运行指标
告警体系 如何设计完备的分布式存储系统报警体系
环境标准化 盘古如何管理复杂多变的运行环境,消除安全隐患
参考链接
- 阿里飞天云平台架构简介