MySQL 从大方向来说,可以分为 Server 层和存储引擎层。而 Server 层包括连接器、查询缓存、解析器、预处理器、优化器、执行器等,最后 Server 层再通过 API 接口形式调用对应的存储引擎层提供的接口来执行增删改查操作。
如下即为一个简略的 select 语句查询流程图:
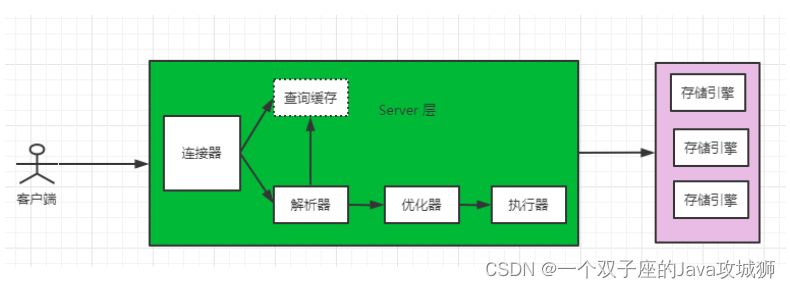 根据流程图,可以得出一条 select 查询大致经过以下六个步骤:
根据流程图,可以得出一条 select 查询大致经过以下六个步骤:
-
客户端发起一个请求时,首先会建立一个连接。
-
服务端会检查缓存,如果命中则直接返回,否则继续之后后面步骤。
-
服务器端根据收到的 sql 语句进行解析,然后对其进行词法分析,语法分析以及预处理。
-
由优化器生成执行计划。
-
调用存储引擎层 API 来执行查询。
-
返回查询到的结果。
1.建立连接
第一步建立连接,这一步很容易理解。 MySQL 服务端和客户端的通信方式采用的是半双工协议。
半双工通信
常见的通信方式主要可以分为三种:单工,半双工,全双工。
-
单工:通信的时候,数据只能单向传输。比如说遥控器,我们只能用遥控器来控制电视机,而不能用电视机来控制遥控器。
-
半双工:通信的时候,数据可以双向传输,但是同一时间只能有一台服务器在发送数据,当 A 给 B 发送数据的时候,那么 B 就不能给 A
发送数据,必须等到 A 发送结束之后,B 才能给 A 发送数据。比如说对讲机。 -
全双工:通信的时候,数据可以双向传输,并且可以同时传输。比如说我们打电话或者用通信软件进行语音和视频通话等。
半双工协议让 MySQL 通信简单快速,但是也在一定程度上限制了 MySQL 的性能,因为一旦从一端开始发送数据,另一端必须要接收完全部数据才能做出响应。所以说我们批量插入的时候尽量拆分成多次插入而不要一次插入太大数据,同样的查询语句最好也带上 limit 限制条数,避免一次返回过多数据。
MySQL 单次传输数据包的大小可以通过变量 max_allowed_packet 控制,默认大小为 64MB(5.7 版本默认只有 4MB)。
执行以下语句查看 max_allowed_packet 变量大小:
SHOW VARIABLES LIKE 'max_allowed_packet';
执行之后得到如下结果(本实验的截图并非直接使用网页版,而是使用网页环境右边的 SSH直接 功能):
 查询结果大小为 67108864,单位是字节,转换之后正好是 64MB。
查询结果大小为 67108864,单位是字节,转换之后正好是 64MB。
2.查询缓存
上面查询流程图中缓存我这边使用了虚线框的原因是缓存在 MySQL 8.0 之后的版本已经取消了,这是因为 MySQL 的缓存使用条件非常苛刻,是通过一个大小写敏感的哈希值去匹配的,这样就是说一条查询语句哪怕只是有一个空格不一致,都会导致无法使用缓存。而且一旦表里面有一行数据变动了,那么关于这种表的所有缓存都会失效,所以一般我们都是不建议使用缓存。
而且在 MySQL 8.0 版本之前缓存也是默认关闭的,但是我们可以通过变量 query_cache_type 进行控制。
3.解析器
这一步主要的工作首先就是检查 sql 语句的语法对不对,在这里,会把我们整个 sql 语句打碎,比如:select name from lanqiao2 where id=1,就会被打散成 select,name,from,lanqiao2,where,id,=,1 这 8 个字符,并且能识别出关键字和非关键字,然后根据 sql 语句生成一个数据结构,也叫做解析树(select_lex)。
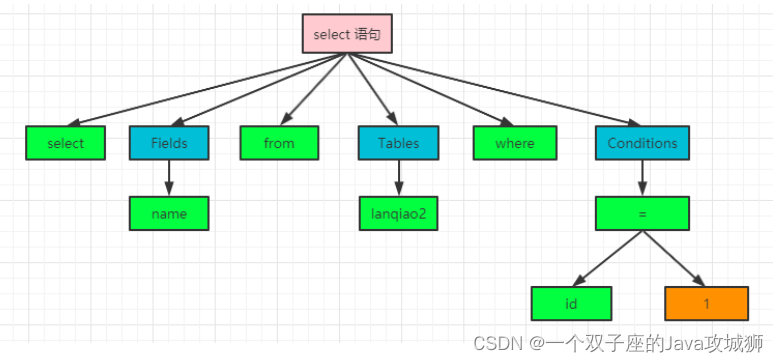 当然,这只是一棵非常简单的解析树,当我们查询语句越复杂,这棵树也会越复杂。
当然,这只是一棵非常简单的解析树,当我们查询语句越复杂,这棵树也会越复杂。
经过了前面的词法和语法解析,那么至少我们这条查询的 sql 语句的语法格式是满足要求了,接下来我们还需要做什么呢?接下来自然是检查表名,列名以及其他一些信息等是不是真实存在的,这就是预处理的一个过程,预处理就是做一个表名和字段名等相关信息合法性的检测。
4.优化器
经过上面的步骤,到这里就得到了一句有效的 sql 语句了。而对一个查询语句,尤其是复杂的多表查询语句,我们可以有很多种执行方式,每种执行方式的效率也不一样,所以这时候就需要查询优化器去选择一种它认为最高效的执行方式。
查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选择一种最优的执行计划,MySQL 里面使用的是基于开销(cost)的优化器,哪种执行计划开销最小,就选择哪种。
我们可以通过变量 Last_query_cost 来查询开销:
select name from lanqiao2 where id=1;
show status like 'Last_query_cost';-- 查看最近一条语句的执行开销
执行之后,得到的结果如下:
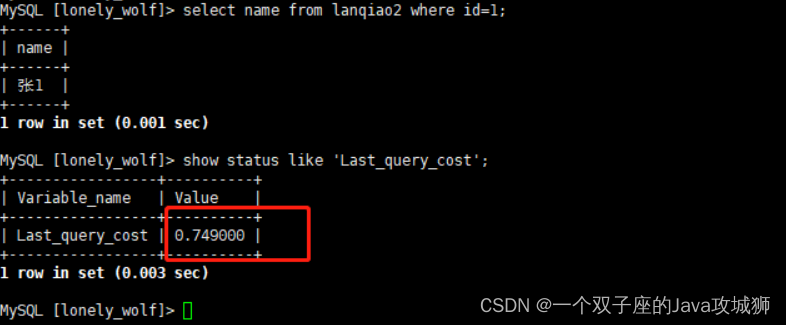 上图中的结果表示当前查询平均会经过几个数据页的检索,上图中为 0.74,说明还不到一个数据页,查询效率很高。
上图中的结果表示当前查询平均会经过几个数据页的检索,上图中为 0.74,说明还不到一个数据页,查询效率很高。
这个结果是通过一系列复杂的运算得到的,包括每个表或者索引的页面个数,索引的基数,索引和数据行的长度,索引分布的情况。而且优化器在评估成本的时候,不会考虑任何缓存的作用,而是假设读取任何数据都需要经过一次 IO 操作。
5.存储引擎查询
当 Server 层得到了一条 sql 语句的执行计划后,这时候就会去调用存储引擎层对应的 API 来执行查询了。因为 MySQL 的存储引擎是插件式的,所以每种存储引擎都会对 Server 提供了一些对应的 API 进行调用。
6.返回结果
最后,将查询出得到的结果返回 Server 层,如果有且开启了缓存,Server 层返回数据的同时还会写入缓存。
MySQL 将查询结果返回是一个增量的逐步返回过程。例如:当我们处理完所有查询逻辑并开始执行查询并且生成第一条结果数据的时候,MySQL 就可以开始逐步的向客户端传输数据了。这么做的好处是服务端无需存储太多结果,从而减少内存消耗。