🌈一.选择题
👿1.
1.堆是一种有用的数据结构。下列那个关键码序列是一个堆( )。
A. 94,31,53,23,16,72 B. 94,53,31,72,16,23
C. 16,53,23,94,31,72 D. 16,31,23,94,53,72D
堆排序·有两种排序方法:
大堆排序-----根结点要大于他的左右子节点,但是左右子节点不需要比较大小。
小堆排序------根结点要小于他的左右子节点,但是左右子节点不需要比较大小。

👿2.
已知序列 25, 13, 10, 12, 9 是大根堆,在序列尾部插入新元素 18 ,将其再调整为大根堆,调整过程中元素
之间进行的比较次数是( )
A.1 B.2 C.4 D.5B
25->13->12->9,这是25的全部左子树,确实是大堆排列。12,9分别是13的左右子树。
25->10->18是25的右子树,所以18要先和10比较,然后交换,18再和25比较,18<25,不进行交换。所以是比较2次。
👿3.
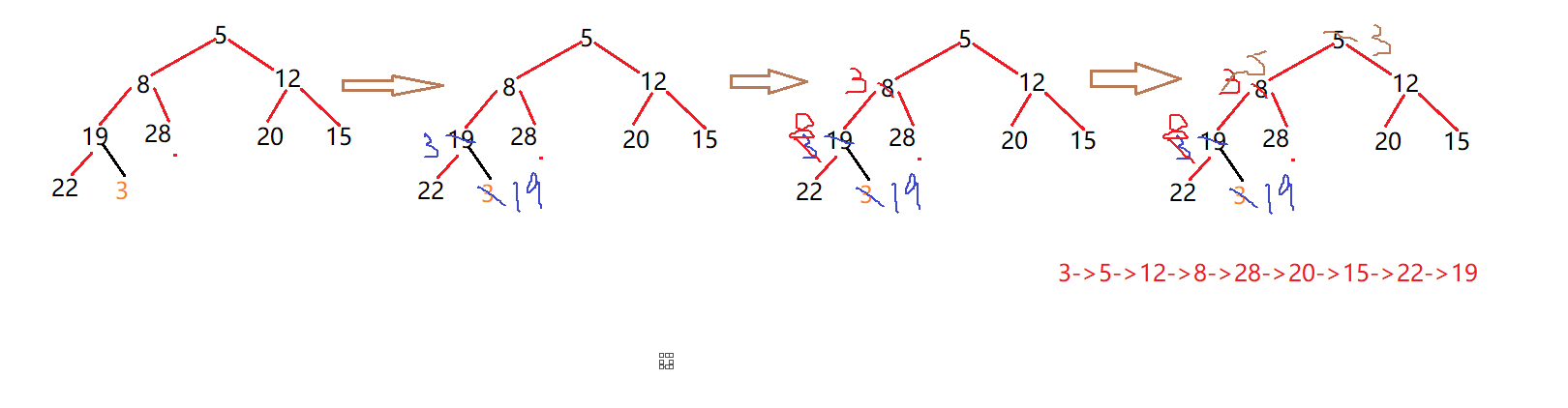
已知关键字序列 5,8,12,19,28,20,15,22 是小根堆(最小堆),插入关键字 3 ,调整后得到的小根堆是(
)
A. 3,5,12,8,28,20,15,22,19
B. 3,5,12,19,20,15,22,8,28
C. 3,8,12,5,20,15,22,28,19
D. 3,12,5,8,28,20,15,22,19A
🌈二.编程题
🍄1.有效的字母异位词

分析这个题之前先了解一下啥是字母异味词。就是给你n个字母,你随便排序,你排序的这几种就是字母异味词。这个题就是反过来让你判断这几个排序用的n=个数是不是一样。
其实这个题的大致思路也很简单,ascll码值都知道吧,直接按照码表上的顺序进行排序,如果俩个字符串排序后的内容一样,就说明就是字母异味词。
class Solution {
public:
bool isAnagram(string s, string t) {
sort(s.begin(), s.end());
sort(t.begin(), t.end());
if(s!=t)
return false;
return true;
}
};这个要是这样用就没啥意思了。我们在用哈希表炫一个。先开一个Vector类型长度为26的哈希表(就是一个数组),初始值都默认是0,然后把s字符串映射上去,初始值+1,然后映射t上去,这次不是加了,而是映射上的都-1,到最后总结,如果每一位全部是原来的0,那么是s,t他俩就是异位词,只要有-1,1就不是异位词。
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) {
return false;
}
vector<int> table(26, 0);
for (auto& ch: s) {
table[ch - 'a']++;
}
for (auto& ch: t) {
table[ch - 'a']--;
if (table[ch - 'a'] < 0) {
return false;
}
}
return true;
}
};
这里有两点需要注意:
1.为啥都是ch='a',‘a’在ascll中是97,但是我们开的空间是从0开始的,为了和我们开的0-25的空间序号对应,所以就-97(‘a’).
2.还有一个疑问是最后那个if中的判断,为啥要<0,有的人该问为啥不是!=0,s,t的长度是相同的,因为开头的if已经判断了,只要当两者全部相同才有可能为0,其他情况,s-t都是-1。结果是1的情况是两者不一样长。
当然了,也可以不先判断长度,最后那个条件就是!=0。看下面这个代码:
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = { 0 };
for (int i = 0; i < s.size(); i++) {
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[s[i] - 'a']++;
}
for (int i = 0; i < t.size(); i++) {
record[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (record[i] != 0) {
// record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
// record数组所有元素都为零0,说明字符串s和t是字母异位词
return true;
}
};🍄2.判断字符串的两半是否相似

简单题我重拳出击:
第一种、先判断字符串s中的元音字母,判断出来后再判断元音在字符串的前半段还是后半段。
class Solution {
public:
bool halvesAreAlike(string s) {
int cnt1 = 0, cnt2 = 0; //一个计前半段的元音数,一个计后半段的
for (int i = 0; i < s.size(); i++) {
if (s[i] == 'a' || s[i] == 'e' || s[i] == 'i' || s[i] == 'o' || s[i] == 'u' || s[i] == 'A' || s[i] == 'E' || s[i] == 'I' || s[i] == 'O' || s[i] == 'U')
{
if (i < s.size() / 2) cnt1++;
else cnt2++;
}
}
cout << cnt1 << " " << cnt2 << endl;
return cnt1 == cnt2;
}
};第二种、把字符串s平分成两段,各自判断自己的元音数,最后比较一下就行了。
class Solution {
public:
bool check(char c)
{
if(c=='a'||c=='e'||c=='i'||c=='o'||c=='u'||c=='A'||c=='E'||c=='I'||c=='O'||c=='U') return true;
return false;
}
bool halvesAreAlike(string s) {
int n=s.size();
string str1=s.substr(0,n/2);
string str2=s.substr(n/2,n);
int cnt1=0,cnt2=0;
for(auto & c : str1)
{
if(check(c))
cnt1++;
}
for(auto & c : str2)
{
if(check(c))
cnt2++;
}
return cnt1==cnt2;
}
};注意:
为啥最后返回的是cnt1==cnt2?注意主函数的返回值类型是bool,如果两者相等,返回true,不相等返回false。
substr函数的作用是:复制子字符串,要求从指定位置开始,并具有指定的长度。如果没有指定长度或者是指定长度超出了源字符串的长度,则子字符串将延续到源字符串的结尾。