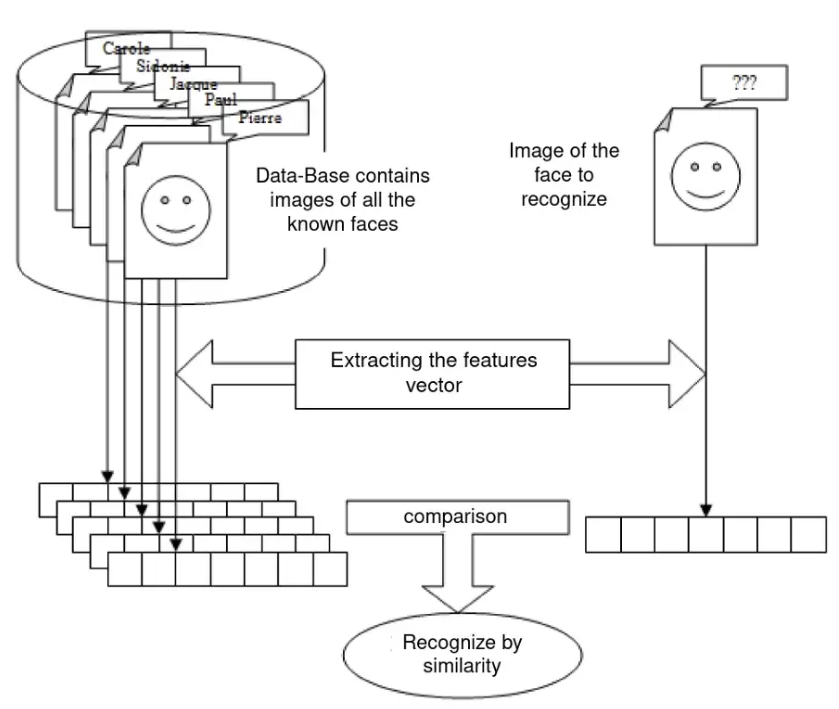
任何自动人脸识别过程都必须考虑导致其复杂性的几个因素,因为人脸是一个动态实体,在多个因素的影响下不断变化,例如光照、姿势、年龄……这三个参数中的任何一个的变化都会导致同一个人的两幅图像之间的误差值大于不同个体的两幅图像之间的误差值。
通常人脸识别过程包括以下几个步骤:
编程:图像采集和数字化处理,在这个过程中,噪声被添加到系统采集的数据中,这将影响图像的质量。添加到图像中的噪声量取决于设备和环境。
预处理:必须使用图像处理和恢复技术去除噪声,此过程包括补偿已知或恢复良好的图像质量。除此之外,如果获取的图像包含多张人脸或背景不是中性的,则需要人脸检测算法来定位图像中的人脸。

分析:又名索引、建模或特征提取,对于从图像(面部的 ROI)中提取将保存在内存中并稍后在决策阶段(在线)使用的信息是必要的。选择要使用的特征非常重要,因为它会对系统的性能产生影响,所选择的特征必须是有区别的并且是非冗余的。这些特征的一个例子是面部特征,包括眼睛之间的距离、眼窝的深度、前额到下巴的距离、颧骨的形状以及嘴唇、耳朵和下巴的轮廓……
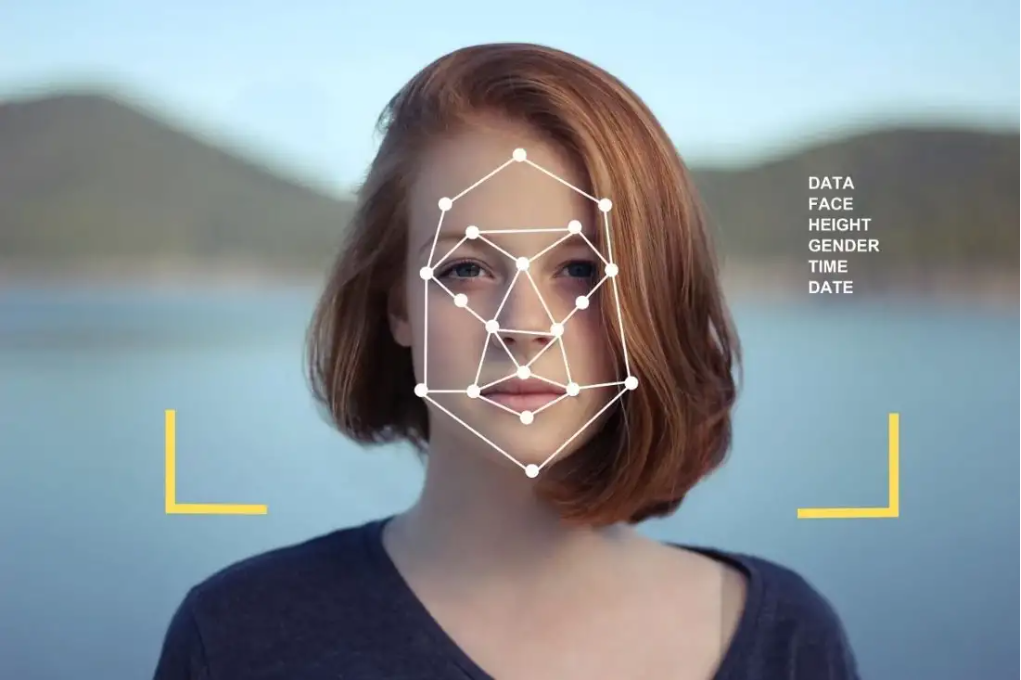
学习:这一阶段将上一步提取的特征存储到数据库中,一般将分析和学习两个步骤合并为一个阶段。
决策:为了估计两幅图像之间的差异,使用相似性度量,例如欧氏距离。
人脸识别技术的类别
基于图像的人脸识别技术分为三类:
本地方法
a.k.a 几何方法,或基于特征的方法。在这种方法中,面部分析是通过对其各部分及其关系的单独描述来进行的。该模型对应于人类使用面部特征点感知面部的方式。
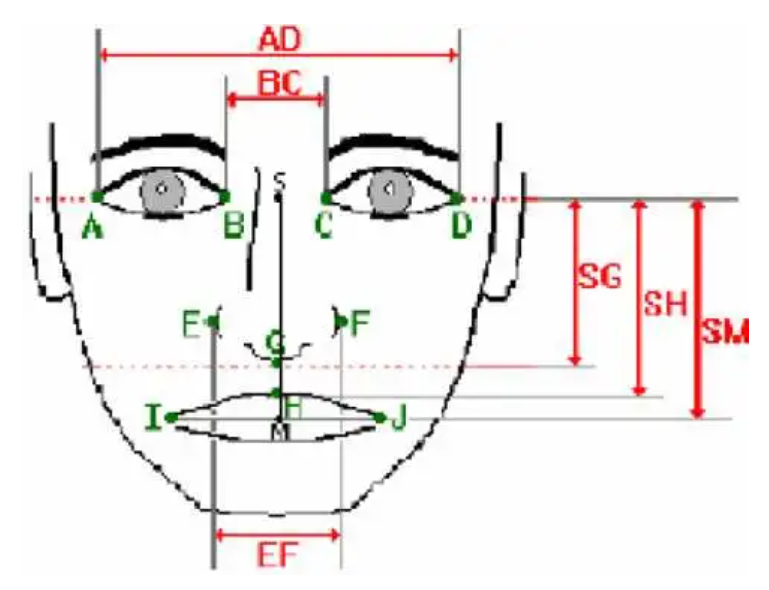
面部特征提取阶段是该过程中的关键步骤,因为整个系统的性能取决于提取相关信息的准确性。另一方面,它们的主要缺点是难以处理面部的不同视图,以及“提取”阶段缺乏精确性。

全局方法
这些方法使用面部的整个区域作为识别算法的输入。它们是非常成功且经过充分研究的技术。这些方法提供了最好的性能,但存储在“学习”阶段提取的信息的问题仍然是一个主要缺点。
混合方法
这些方法结合了前两种类型,因此有可能提供两全其美的方法。它们基于与人类感知系统相同的原理,人类感知系统使用局部特征和整个面部区域来识别个人。
人脸识别技术的应用
人脸识别技术被用于许多行业,从娱乐到国家安全问题。
健康
安全
零售、营销和广告
银行
结论
从我的角度来看,这是关于人脸识别、可用技术的类别及其应用。
这项技术的未来会怎样?根据一些专家的说法,我们的生物特征(例如面部、指纹、声音……)最终将取代身份证、护照和信用卡密码。考虑到这项技术的简单性和成本效益,并且越来越多地被普通民众使用和接受,这一预测并不牵强。想一想您口袋里或手上拿着的设备,现在几乎每部手机都具有面部或指纹识别功能

当然还有语音识别系统:iPhone 的 Siri、Android 的 Iris、Windows 的 Cortana
如果这一预测成真,那么现在采用该技术的任何公司都将在未来拥有竞争优势。
· END ·
HAPPY LIFE