文章目录
- 前言
- 数组的形状变换
- reshape的基本介绍
- 使用reshape
- reshape([10, 1])运行结果
- reshape自动判断形状
- reshape([-1, 1])运行结果
- 合并数组
- 使用vstack和hstack
- vstack和hstack的运行结果
- 使用concatenate
- concatenate运行结果
- 分割数组
- array_split运行结果
- 数组的条件筛选
- 条件筛选运行结果
前言
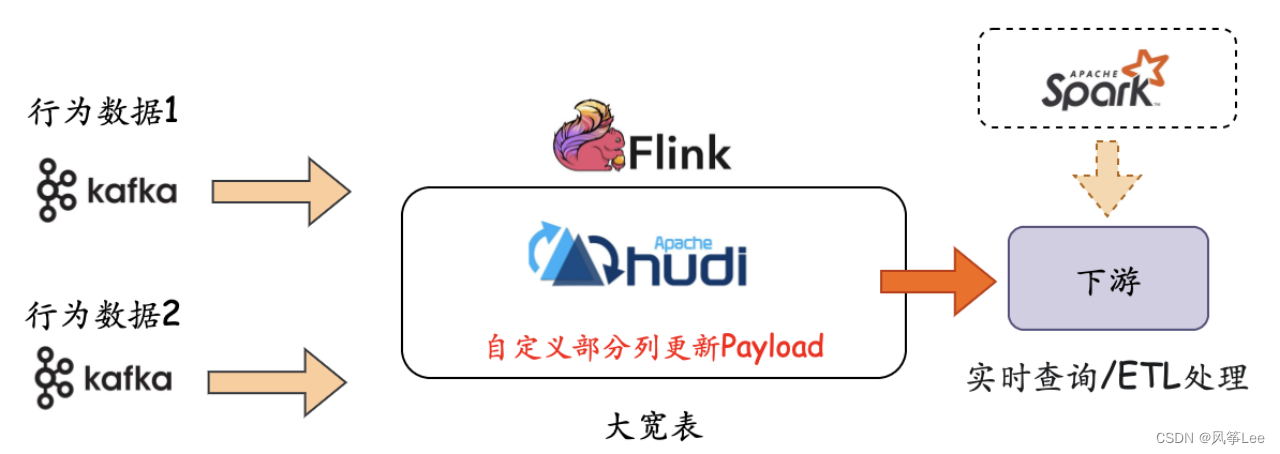
本文包含数组的形状变换,数组的合并和分割,数组的条件筛选,为了专注于应用,我只会讲解其中相对常用的几个部分。
建议先读完第一天(点击传送)的文章再读本文。
本文代码:
链接
提取码:1024`
数组的形状变换
在Numpy中,数组的形状变换是非常常见的操作,它让你能够重新排列数组的维度。本人认为最常用的形状变换方法是reshape,因此本部分我们只会讲解reshape。
reshape的基本介绍
通常,我们会给reshape传入一个列表,或者元祖,这里为了区分圆括号,我们将会传入列表,列表中的元素指定了形状。在下面的代码中,我们将会写reshape([10, 1])和reshape([-1, 1])。
使用reshape
假设你有一个1维数组(只有一个维度的数组),你想要将它转换为一个多个行1个列的数组(拥有两个维度的数组)(通常,这是一个适合sklearn的机器学习模型的输入格式的2维数组),现在我们知道这个1维数组有10个元素,如果它们要变成只有1列的形式,意味着它们有10行,我们可以写reshape([10, 1]),代表将数组转为10行1列的二维数组,请看下面代码:
import numpy as np
# 创建一个1维数组
arr = np.arange(10) # 这将生成一个包含0到9的数组
# 使用reshape将其变为2维数组
arr_reshaped = arr.reshape([10, 1])
print('原来的数组:')
print(arr)
print()
print('reshape([10, 1])之后的数组:')
print(arr_reshaped)
reshape([10, 1])运行结果
可以看到,我们的数组的形状已经成功改变了。

reshape自动判断形状
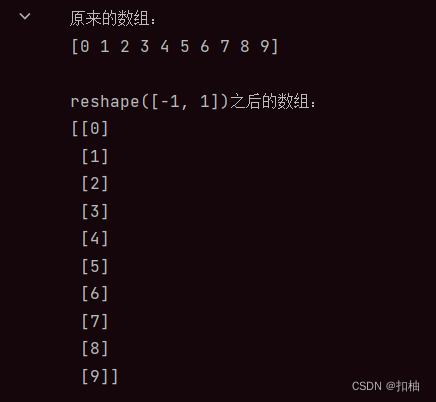
上文中,我们希望将一个一维数组,arr,转为一个拥有多个行一个列的二维数组,由于我们很清楚arr 中有10个元素,所以我们写了reshape(10, 1),但如果我们不知道有多少个元素,但是仍然希望将这个一维数组变成多个行一个列的二维数组呢?此时,我们可以写reshape(-1, 1),-1代表的是:让Numpy自动推导形状
。
具体使用请看下面代码:
import numpy as np
# 创建一个1维数组
arr = np.arange(10) # 这将生成一个包含0到9的数组
# 使用reshape将其变为2维数组
arr_reshaped = arr.reshape([-1, 1])
print('原来的数组:')
print(arr)
print()
print('reshape([-1, 1])之后的数组:')
print(arr_reshaped)
reshape([-1, 1])运行结果
可以看到,即使我们没有指定行数为10,Numpy也自动推导出了新形状应有的行的个数。
合并数组
合并是将多个数组拼接为一个更大的数组。在Numpy中,你可以用concatenate、vstack和hstack等方法来实现。
使用vstack和hstack
比较简单易理解的是下面两种方法:
vstack(垂直堆叠)hstack(水平堆叠)
我们一般会把要进行堆叠的Numpy数组放入一个列表中,再传给vstack和hstack,比如vstack([arr1, arr2]),我们把arr1和arr2装入一个列表中,传给vstack进行垂直堆叠,hstack的使用方法同理。
具体请看下面的代码:
import numpy as np
# 创建两个数组
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6], [7, 8]])
# 垂直堆叠
arr_vstack = np.vstack([arr1, arr2])
# 水平堆叠
arr_hstack = np.hstack([arr1, arr2])
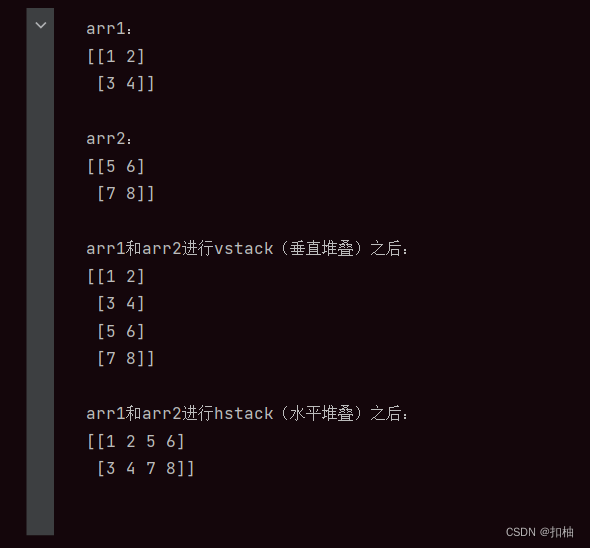
print('arr1: ')
print(arr1)
print()
print('arr2:')
print(arr2)
print()
print('arr1和arr2进行vstack(垂直堆叠)之后:')
print(arr_vstack)
print()
print('arr1和arr2进行hstack(水平堆叠)之后:')
print(arr_hstack)
vstack和hstack的运行结果
使用concatenate
concatenate相对更加灵活,但是对于初学者来说也相对复杂。
concatenate相对vstack和hstack,多了一个参数叫axis,你可以通过指定axis的值指定堆叠的轴
axis=0时,在行的轴上进行堆叠,与vstack的效果相同axis=1时,在列的轴上进行堆叠,与hstack的效果相同
当axis更大的时候,就是在高维数组上的操作了,对于初学者来说可能会太过抽象,可以暂时忽略,先理解简单情况,学习会更高效。
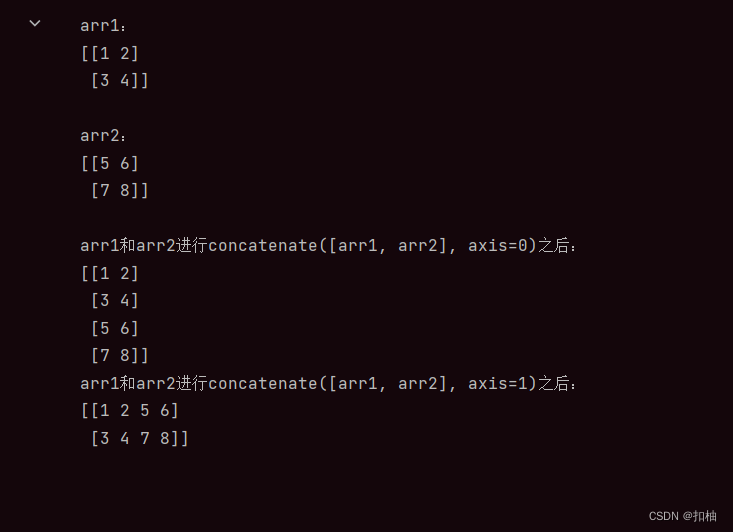
print('arr1: ')
print(arr1)
print()
print('arr2:')
print(arr2)
print()
# 使用concatenate进行垂直堆叠
arr_vstack = np.concatenate([arr1, arr2], axis=0)
print('arr1和arr2进行concatenate([arr1, arr2], axis=0)之后:')
print(arr_vstack)
# 使用concatenate进行水平堆叠
arr_hstack = np.concatenate([arr1, arr2], axis=1)
print('arr1和arr2进行concatenate([arr1, arr2], axis=1)之后:')
print(arr_hstack)
concatenate运行结果
可以看到,我们只需要使用一个concatenate就可以完成vstack和hstack两者的任务。
分割数组
数组的分割操作相对较少用,我们了解一下即可。
我们可以使用array_split,将一个数组分为指定数量的部分。
具体请看下面代码:
import numpy as np
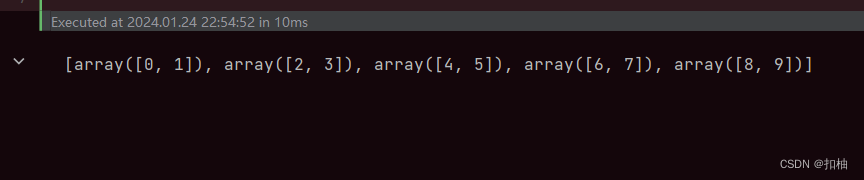
arr = np.arange(10) # 创建一个包含0到9的数组
newarr = np.array_split(arr, 5) # 分割成5部分
print(newarr)
array_split运行结果
可以看到我们的数组被分割成了5个相同大小的部分。
数组的条件筛选
在Numpy中,你可以使用条件筛选来获取数组中符合特定条件的元素,这里的筛选操作和pandas相差不大,弄懂了numpy的条件筛选,你可以很自然地用到pandas上。
对于单个条件:
- 筛选出数组中大于5的元素,可以写
arr[arr > 5] - 筛选出数组中等于5的元素,可以写
arr[arr == 5] - 筛选出数组中小于5的元素,可以写
arr[arr < 5]
对于多个条件:
- 筛选出数组中小于5,同时大于2的元素,可以写
arr[(arr < 5) & (arr > 2)]
注意: 不同条件必须使用圆括号括起来。如果对这个注意点有疑问,请看解释,如果看解释看得一头雾水,请跳过。
解释:
&代表and,也就是二进制运算中的按位与运算,因为按位与的特性,也有人会将&当成Python的关键字and使用来结合多个条件,这里刚刚提到的(arr < 5) & (arr > 2)就是这个用法。
如果写arr & 5,代表对arr中的所有元素跟5进行一次按位与运算,运算结果是数值,比如,arr中的数字3的二进制表达是011,因为arr & 5,所以arr中的数字3会与数字5的二进制表达(101)进行按位与运算,运算结果是001,也就是十进制中的1。
因此&的结果不仅仅是结合多个条件中得到的true或者false,在一些需要用到位运算的情况下,我们可能希望比较按位与之后的数值结果,而不是简单地使用&来结合多个条件。既然有按位与和结合条件这两种用法,如果不同条件不加括号,难免造成歧义,为了消除歧义,Numpy的开发者要求我们不同条件必须使用圆括号括起来。
以此类推,你可以自己尝试编写其它类似的代码。 具体请看下面的代码。
import numpy as np
# 创建一个数组
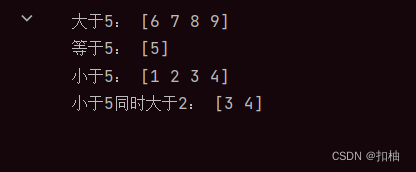
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
# 条件筛选
greater = arr[arr > 5]
equals = arr[arr == 5]
less = arr[arr < 5]
between = arr[(arr < 5) & (arr > 2)]
print('大于5:', greater)
print('等于5:', equals)
print('小于5:', less)
print('小于5同时大于2:', between)
条件筛选运行结果