Android Clear架构最强官方指南Kotlin版
在这篇文章中,我将介绍关于Android应用程序架构的一些内容。尽管自从早期更稳健的Android架构方法在移动开发中变得流行以来已经说了很多话,但改进和演进的空间总是存在的。
基于上述文章中的清晰架构示例,代码库中有明显的演进,特别是在当今应用程序在业务层面至关重要的情况下,更加需要扩展、模块化和组织围绕移动开发的团队(主要是由于其复杂性)。
因此,我们的目标是提出一种优雅的解决方案,以便在以下方面使我们的工作更加轻松:
- 解决问题。
- 可扩展性。
- 模块化。
- 可测试性。
- 独立于框架、UI和数据库。
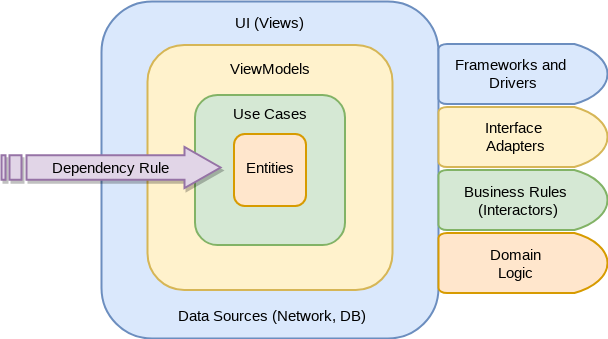
这是一个架构图,如果您在Android应用程序中使用了Clear架构,它应该看起来很熟悉。
我们的场景
一个简单的电影Android应用程序。采用Kotlin编写,我们希望利用现代语言的特性,如不可变性、简洁性、函数式编程等。
以下是App项目的截图:

我们有3个主要的用例:
- 获取电影列表。
- 显示特定点击电影的详细信息。
- 播放电影。
通用架构

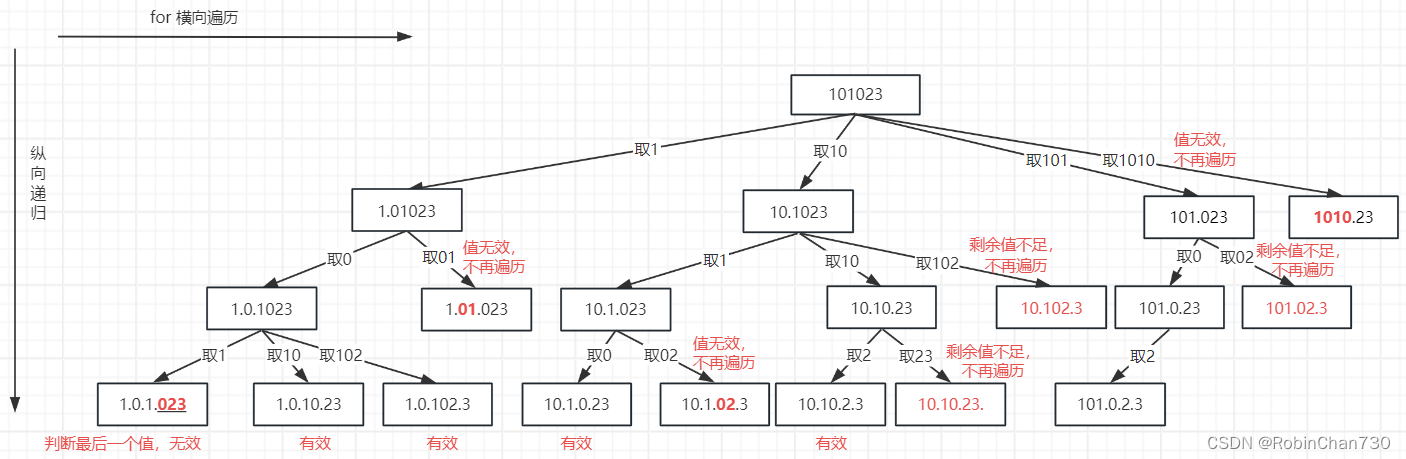
总体架构是基于基本的三层架构。好处在于,它非常容易理解,许多人都熟悉它。因此,我们将分解我们的解决方案以遵守依赖关系规则, 其中依赖关系沿着一个方向流动:请参阅下面的圆形Clear架构图。
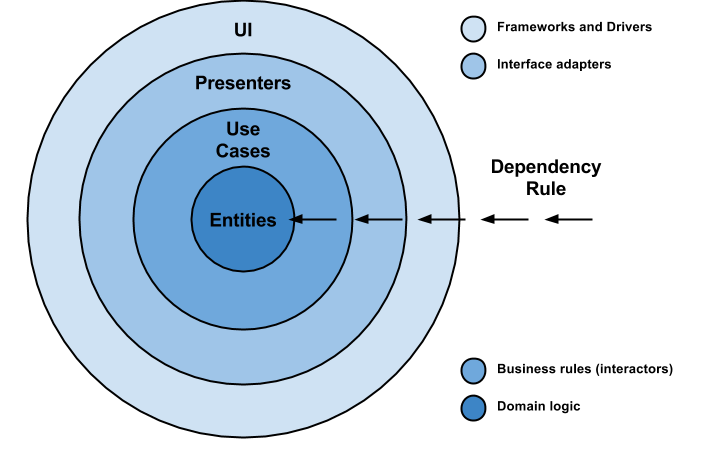
领域层(Domain Layer):功能用例
用例是我们应用程序中要做的意图,换句话说,是我们的主要参与者之一。它的主要责任是协调我们的领域逻辑以及与UI和数据层的连接。
通过使用Kotlin的强大功能和将函数作为一等公民对待的方式(即将在稍后提到的内容),在我们的框架中有一个UseCase抽象,它充当我们应用程序中所有用例的契约。
abstract class UseCase<out Type, in Params> where Type : Any {
abstract suspend fun run(params: Params): Either<Failure, Type>
fun execute(onResult: (Either<Failure, Type>) -> Unit, params: Params) {
val job = async(CommonPool) { run(params) }
launch(UI) { onResult.invoke(job.await()) }
}
}
这里发生了什么?
我们有一个抽象类,它接受两个泛型参数:
<out Type>:执行用例后的返回类型。<in Params>:一个参数类,在我们需要用例的额外数据时,将在run()函数内使用。
execute()函数是魔法发生的地方:
-
我们传递了一个
onResult函数作为参数,该函数接受Either<Failure, Type>类型的参数,并返回Unit(在错误处理部分,我将扩展对Either<L, R>的解释,请耐心等待)。好处是,UseCase的调用者通过传递这个不可变函数(onResult),实际上确定了所需的行为,从而避免了任何内部暴露或副作用(这是函数式编程的好处之一,稍后会有更多)。 -
同样,通过使用Kotlin协程,我们在不同的线程中调用传递的
onResult函数,因此从这一点开始,我们可以以同步的方式编写代码。结果将发布在Android主UI线程上。
当扩展UseCase<out Type, in Params>抽象时,我们必须覆盖abstract suspend fun run(params: Params)函数。例如,这就是我们的GetMovies用例的样子:
class GetMovies
@Inject constructor(private val moviesRepository: MoviesRepository) :
UseCase<List<Movie>, None>() {
override suspend fun run(params: None) = moviesRepository.movies()
}
在这个例子中,我们将电影的获取委托给一个Repository。
UI层(UI Layer):从MVP到MVVM
Model-View-ViewModel(MVVM)模式在用户界面和领域逻辑之间提供了清晰的责任分离。
它有3个主要组件:模型(model)、视图(view)和视图模型(view model)。它们之间存在关系,尽管每个组件都有不同且独立的角色:
在最高级别上,视图“知道”视图模型,而视图模型“知道”模型,但模型不知道视图模型,视图模型也不知道视图。视图模型将视图与模型类隔离开来,并允许模型独立于视图进行演进。
在我们的示例中,MVVM的实现是通过使用架构组件完成的,它的主要优势是在屏幕旋转时处理配置更改,这对于Android开发人员来说是一个常见的头痛问题(我想你明白我在说什么)。
免责声明:这并不意味着我们不再需要关心生命周期,但处理起来要容易得多。
关于前面示例中的MVP(Model View Presenter)的一点注释:我发现很难避免由于活动和片段被重新创建而导致的内存泄漏,所以我使用了一个简单的解决方案:保留片段(retain fragments)。
然而,我无论如何都会遇到这种情况。这就是为什么我决定去尝试MVVM的原因。
让我们看看MVVM与之前示例相比有何变化以及它是如何工作的:
- 片段充当视图,在这里发生与屏幕上数据显示相关的所有逻辑。
- 片段也知道视图模型,它们实际上是订阅视图模型的。
- 视图模型包含LiveData对象和对UseCases的引用。
- UseCases更新LiveData,LiveData对这些更改做出反应并通知视图模型。
- 视图模型与订阅的片段进行通信,以更新UI。
为了看到所有这些部分如何协同工作,让我们看一些代码。包含LiveData并通过调用UseCase.execute()函数进行更新的ViewModel:
class MoviesViewModel
@Inject constructor(private val getMovies: GetMovies) : BaseViewModel() {
var movies: MutableLiveData<List<MovieView>> = MutableLiveData()
fun loadMovies() =
getMovies.execute({ it.either(::handleFailure, ::handleMovieList) }, None())
private fun handleMovieList(movies: List<Movie>) {
this.movies.value = movies.map { MovieView(it.id, it.poster) }
}
}
片段在onCreate()中订阅上述的ViewModel。
我使用了一些扩展函数的技巧来减少一些冗长和样板代码。
class MoviesFragment : BaseFragment() {
@Inject lateinit var navigator: Navigator
@Inject lateinit var moviesAdapter: MoviesAdapter
private lateinit var moviesViewModel: MoviesViewModel
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
appComponent.inject(this)
//subscribtion to LiveData in MoviesViewModel
moviesViewModel = viewModel(viewModelFactory) {
observe(movies, ::renderMoviesList)
failure(failure, ::handleFailure)
}
}
...
}
数据层(Data Layer):拯救的存储库模式
与之前的示例相比,这里有什么新东西吗?因为我在使用存储库模式时取得了非常好的结果。
需要记住的是:在其核心,存储库模式是一个简单的接口。它存在于我们的领域和数据之间的一层,这样我们的逻辑就不需要关注不同数据源的实现:网络、数据库或内存。

在下面的代码块中,我们可以看到我们的MoviesRepository契约:
interface MoviesRepository {
fun movies(): Either<Failure, List<Movie>>
fun movieDetails(movieId: Int): Either<Failure, MovieDetails>
}
在我们的示例中,我们通常将Repository作为UseCase实现的协作者进行注入。
功能性错误处理
整体上,错误/异常处理应该在设计层面而不是实现层面上加以处理,而在我看来,作为开发者我们所犯的最大错误之一就是这个(吸取了教训)。这就是为什么有一个专门的框架来处理这个目的非常重要。
传统的错误处理会发生什么?
观察异常(try/catch块)并基于此做出改变控制流的决策是一种不好的实践:它会导致不可预测性,影响我们的弹性,并且调试变得困难,尤其是在并发环境中。再加上回到C风格的错误处理,使用需要按约定检查的错误代码可能会成为一个噩梦。
说到这里,我们已经看到我们在UseCase抽象中使用Either<L, R>作为返回类型:
abstract suspend fun run(params: Params): Either<Failure, Type>
因此,让我介绍一下Either
Either<L, R>被称为不相交函数,这意味着这个结构被设计为只容纳Left<T>或Right<T>值,而不是两者兼有。它是一种函数式编程的单子类型,尚未存在于Kotlin标准库中。
这里有一个简单的实现,非常符合我的需求,并且易于理解和使用:
/**
* Represents a value of one of two possible types (a disjoint union).
* Instances of [Either] are either an instance of [Left] or [Right].
* FP Convention dictates that:
* [Left] is used for "failure".
* [Right] is used for "success".
*
* @see Left
* @see Right
*/
sealed class Either<out L, out R> {
/**
* Represents the left side of [Either] class
* which by convention is a "Failure".
*/
data class Left<out L>(val a: L) : Either<L, Nothing>()
/**
* Represents the right side of [Either] class
* which by convention is a "Success".
*/
data class Right<out R>(val b: R) : Either<Nothing, R>()
val isRight get() = this is Right<R>
val isLeft get() = this is Left<L>
fun either(fnL: (L) -> Any, fnR: (R) -> Any): Any =
when (this) {
is Either.Left -> fnL(a)
is Either.Right -> fnR(b)
}
fun <T> flatMap(fn: (R) -> Either<L, T>): Either<L, T> {...}
fun <T> map(fn: (R) -> (T)): Either<L, T> {...}
}
让我也引用一下Daniel Westheide(Scala专家)在他的一篇精彩博客文章中的话:
Either<L, R>类型的语义中没有规定其中一个子类型分别表示错误或成功。事实上,Either是一种通用类型,用于处理结果可能为两种可能类型之一的情况。
然而,错误处理是它的一种常见用例,并且根据惯例,当以这种方式使用时,Left<T>表示错误情况,而Right<T>包含成功值。
请不要忘记阅读他的整个Scala系列文章,以拓宽你的视野(从其他语言中获取灵感总是+1):
- 使用Try进行错误处理。
http://danielwestheide.com/blog/2012/12/26/the-neophytes-guide-to-scala-part-6-error-handling-with-try.html
- Either类型。
http://danielwestheide.com/blog/2013/01/02/the-neophytes-guide-to-scala-part-7-the-either-type.html
那么我们的代码示例呢?
在GetMovies UseCase中,在实现层面上,我们总是返回一个Either<Failure, List<Movie>>,从数据层开始一直到我们的MoviesViewModel,它会更新either失败LiveData<Failure>(如果失败,则为Left<T>)或电影LiveData<List<MovieView>>(成功,Right<T>):
class MoviesViewModel
@Inject constructor(private val getMovies: GetMovies) {
var movies: MutableLiveData<List<MovieView>> = MutableLiveData()
var failure: MutableLiveData<Failure> = MutableLiveData()
fun loadMovies() =
getMovies.execute({ it.either(::handleFailure, ::handleMovieList) }, None())
private fun handleMovieList(movies: List<Movie>) {
this.movies.value = movies.map { MovieView(it.id, it.poster) }
}
private fun handleFailure(failure: Failure) {
this.failure.value = failure
}
}
在视图层级的MoviesFragment中,我们订阅来自视图模型的更新:
moviesViewModel = viewModel(viewModelFactory) {
observe(movies, ::renderMoviesList)
failure(failure, ::handleFailure)
}
这是用于处理Failure的handleFailure()函数的样子:
private fun handleFailure(failure: Failure?) {
when (failure) {
is NetworkConnection -> renderFailure(R.string.failure_network_connection)
is ServerError -> renderFailure(R.string.failure_server_error)
is ListNotAvailable -> renderFailure(R.string.failure_movies_list_unavailable)
}
}
顺便说一下,Failure是一个密封类,它提供了全局默认的Failures:
/**
* 用于处理错误/失败/异常的基类。
* 每个特定功能的失败应该扩展[FeatureFailure]类。
*/
sealed class Failure {
class NetworkConnection: Failure()
class ServerError: Failure()
/** * 扩展此类以获取特定功能的失败。*/
abstract class FeatureFailure: Failure()
}
我希望现在对Either<L, R>的用法更清晰了,你理解了这种应用技术的原因和好处。
模块化第一步
首先,我想解释一下,这篇文章并不是专门讨论一个具体问题的,但我想分享一些经验,以便初学者更容易入门。从我的角度来看,模块化开发的方式早晚都会被广泛采用,并且通过良好的架构设计可以更好地实现这个目标。
什么是模块化?
模块化是一种将代码的逻辑组件分离并创建清晰边界的方法。
如果你已经做了功课,并且看过我之前关于Android架构的帖子,你可能已经注意到我使用Android模块来表示每个层级的架构。
在讨论中,一个常见的问题是:为什么要这样做?答案很简单… 这是为了避免错误的技术决策。通过建立更严格的依赖规则和边界,我们可以减少模块之间的相互影响。
然而,权力伴随着巨大的责任。虽然一开始看起来效果很好,但模块化也会带来一些问题:
- 当我们修改或添加新功能时,我们必须同时修改每个单独的模块/层(因为它们之间存在强依赖/耦合)。
- 开发人员在共同使用代码库时可能会发生冲突(特别是在团队规模较大、与代码审查和git相关的情况下)。
拥抱App模块化
我倾向于模块化的第一个提示是按功能组织Package,这样我们可以实现:
更高的模块性。
更高的内聚性。
更容易的代码导航。
最小化作用域。
隔离和封装。
代码/包的组织是良好架构的关键因素之一:包结构是程序员在浏览源代码时遇到的第一件事。一切都从这里开始。一切都依赖于它。
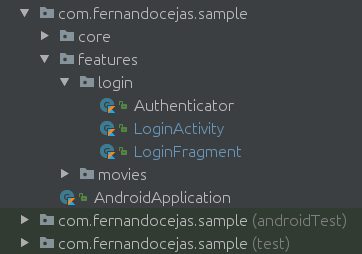
我的第二个提示是创建一个核心模块,它将拥有以下主要职责:
处理全局依赖注入。
包含扩展函数。
包含主要框架抽象。
在主应用程序中启动常见的第三方库,如Analytics、Crash Reporting等。
我的第三个提示不涉及到代码库级别,但如果我们正在与功能团队合作,添加代码所有权可能会有所帮助,这对于在许多开发人员共同使用代码库的不断发展的组织中获得胜利来说是一件好事。
这些是模块化的主要优点:
更快的构建时间。
包内凝聚力。
共享常见功能的可重用性。
减少冲突(特别是在使用git流时)。
特性封装。
更加控制的依赖项。
团队合作:团队之间的协作。
我知道这些听起来在纸面上很好,虽然将Android代码库模块化是棘手和具有挑战性的(因为涉及到许多部分),但优点是巨大的。
结论
本文使用Kotlin实现了Clear Arch, 涉及到比较抽象的理论知识,给出了相关理论实现,希望对你今后Android开发有大的帮助。
项目地址
Android-CleanArchitecture-Kotlin(https://github.com/android10/Android-CleanArchitecture-Kotlin)
旧版Android-CleanArchitecture-Java(https://github.com/android10/Android-CleanArchitecture)