目录
(一)数组名的理解
(1)数组名是数组首元素的地址
(2)两个例外
(二)函数内数组传参
(1)一维数组传参
(2)二维数组传参
(3)三维及高维数组传参
正文开始——数组与指针是紧密联系的
(一)数组名的理解
(1)数组名是数组首元素的地址
int arr[10] = {1,2,3,4,5,6,7,8,9,10}; int *parr = &arr[0];上述代码通过&arr[0] 的方式得到了数组第一个元素的地址,但其实数组名本身就是一个地址,并且是数组首元素的地址。
代码1:
#include<stdio.h> int main() { int arr[6] = { 1,2,3,4,5,6}; printf("%p\n",arr); printf("%p\n",&arr[0]); return 0; }结果:
数组名与数组首元素的地址打印出的结果是一样的。于是,数组名就是数组首元素(第一个元素)的地址。

(2)两个例外
代码2:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
return 0;
}结果:
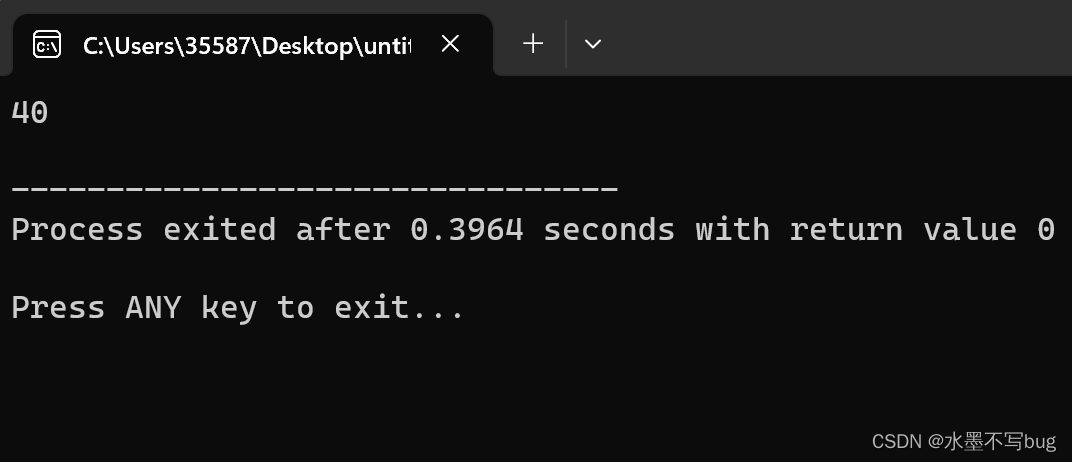
令我们出乎所料的是,这里的数组名不再是数组首元素的地址,而是表示整个数组。
对于代码中出现的数组名,不违背数组名是数组第一个元素的的地址,也就是说:
数组名是数组首元素的地址是对的,但是有两个例外:
• sizeof(数组名),sizeof中单独放数组名,这里的数组名代表整个数组,sizeof计算的是整个数组的大小,单位是字节
• &数组名,这的数组名代表整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的)
除此之外,其他地方使用数组名,都代表的是数组首元素的地址。
那么,数组名与&数组名具体有什么区别?
通过指针运算就可以体现出他们的区别:
代码3:
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);结果:
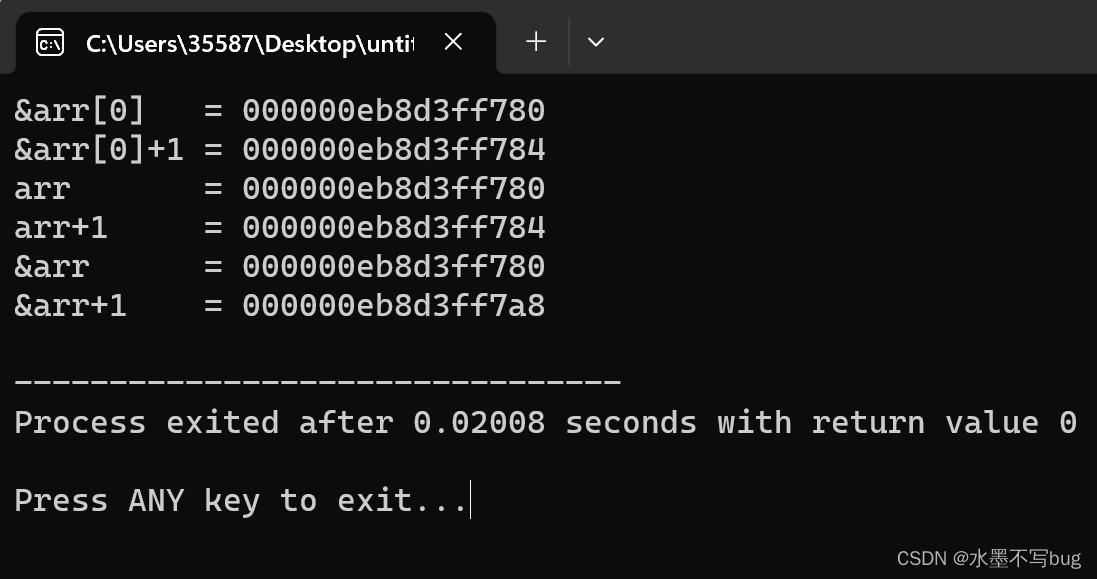
&arr[0] 和 &arr[0] + 1 相差4个字节,arr 和 arr + 1 相差 4个字节,原因是&arr[0] 和arr 都是数组arr 首元素的地址,通过指针运算 +1 就是跳过一个int型的元素(也就是跳过4个字节)。
&arr 和 &arr + 1 相差40个字节,原因是&arr是数组的地址,指针运算 + 1 就是跳过整个数组 int [10] 型元素(也就是10个整形,40个字节)。
(二)函数内数组传参
(1)一维数组传参
相信你一定使用过冒泡排序吧;
将数组(传址)和数组内元素个数传给函数,
int main()
{
int arr[10] = {5,4,8,7,9,6,3,2,1,0};
int sz1 = sizeof(arr)/sizeof(arr[0]);
Bobble_sort(arr,sz1);
Print();
return 0;
}
就会得到排序好的数组。
观察上述操作,我们都是在函数外部计算数组的元素个数,那我们可以把数组传给⼀个函
数后,函数内部求数组的元素个数吗?
#include <stdio.h>
void test(int arr[])
{
int sz2 = sizeof(arr)/sizeof(arr[0]);
printf("sz2 = %d\n", sz2);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz1 = sizeof(arr)/sizeof(arr[0]);
printf("sz1 = %d\n", sz1);
test(arr);
return 0;
}结果:(在x86下)
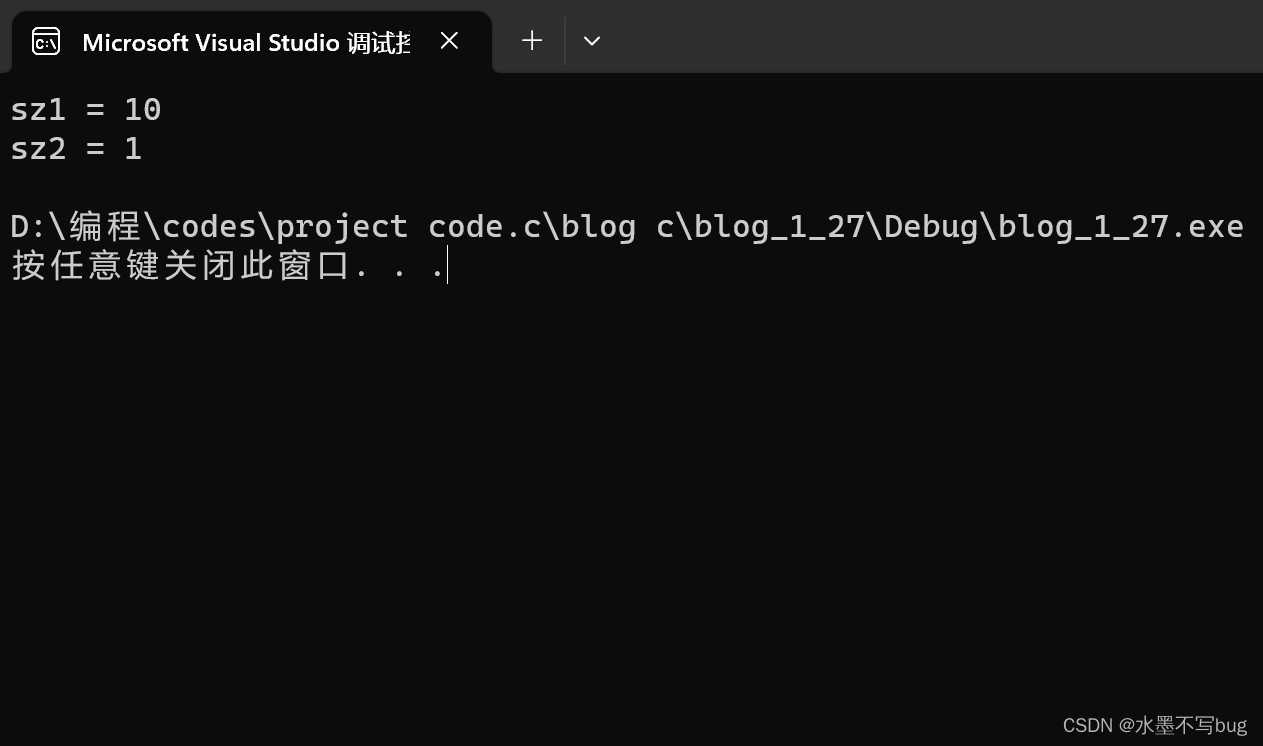
为什么传给函数的是数组,结果sizeof计算整个数组的的大小 = 4 字节呢?
这就要学习数组传参的本质了,上个小节我们学习了:数组名是数组首元素的地址;那么在数组传参的时候,传递的是数组名,也就是说数组传参本质上传递的是数组首元素的地址。
所以函数形参的部分理论上应该使用指针变量来接收首元素的地址。void Bobble_sort(int* p,int sz) { ....... } int main() { int arr[5] = {1,2,3,4,5}; int sz = sizeof(arr)/sizeof(arr[0]); Bobble_sort(arr,sz); return 0; }那么在函数内部我们写sizeof(arr) 计算的是⼀个地址的大小(单位字节)而不是数组的大小(单位字节)。正是因为函数的参数部分是本质是指针,所以在函数内部是没办法求的数组元素个数的。
(2)二维数组传参
二维数组传参,以上的结论仍成立:
数组传参本质上传递的是数组首元素的地址。
二维数组的首元素,不再是一个基本的数据类型,而是一个数组类型。
什么是数组类型?
如果一个数组是整形数组,元素是5个整形,那么他的类型就是( int [5] )类型。
二维数组首元素的地址其数据类型就是(int (*)[5])类型。
那么在主函数内(未传参)sizeof(二维数组的数组名)计算的就是整个二维数组大小;
传参后,sizeof(二维数组名)的结果就是指针(int (*)[5])的大小了。(所有类型,函数,其地址的大小是一定的)
(3)三维及高维数组传参
仍然满足 数组传参本质上传递的是数组首元素的地址。
这里我们来看一段代码:
#include<stdio.h>
void PR(int (*p)[3][3])
{
}
int main()
{
int arr[3][3][3];
PR(arr);
return 0;
}解释:
数组arr的首元素类型是int [3][3],在传参的时候,可以用指针类型int(*)[3][3]来接收,类型是照应的。这也说明 arr传递的是首元素的地址
完~
未经作者同意禁止转载







![XCTF:Normal_RSA[WriteUP]](https://img-blog.csdnimg.cn/direct/6a9909ce81f3451cbd3f7be4e9518f61.png)