第4章 机器学习基础
除分类和回归之外的机器学习形式
评估机器学习模型的规范流程
为深度学习准备数据
特征工程
解决过拟合
处理机器学习问题的通用工作流程
4.1 机器学习的四个分支
三种类型的机器学习问题:二分类问题、多分类问题和标量回归问题。这三者都是监督学习(supervised learning)的例子,其目标是学习训练输入与训练目标之间的关系。
4.1.1 监督学习
监督学习只是冰山一角——机器学习是非常宽泛的领域,其子领域的划分非常复杂。机器学习算法大致可分为四大类,我们将在接下来的四小节中依次介绍。
监督学习是目前最常见的机器学习类型 。给定一组样本(通常由人工标注),它可以学会将输入数据映射到已知目标[也叫 标注 (annotation)]。本书前面的四个例子都属于监督学习。一 般来说,近年来广受关注的深度学习应用几乎都属于监督学习,比如光学字符识别、语音识别、 图像分类和语言翻译。
虽然监督学习主要包括分类和回归,但还有更多的奇特变体 ,主要包括如下几种。
序列生成(sequence generation) 。给定一张图像,预测描述图像的文字。序列生成有时可以被重新表示为一系列分类问题,比如反复预测序列中的单词或标记。
语法树预测(syntax tree prediction) 。给定一个句子,预测其分解生成的语法树。
目标检测(object detection) 。给定一张图像,在图中特定目标的周围画一个边界框。这个问题也可以表示为分类问题(给定多个候选边界框,对每个框内的目标进行分类)或分类与回归联合问题(用向量回归来预测边界框的坐标)。
图像分割(image segmentation) 。给定一张图像,在特定物体上画一个像素级的掩模( mask )。
4.1.2 无监督学习
无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,其目的在于数据可视化、数据压缩、数据去噪或更好地理解数据中的相关性。无监督学习是数据分析的必备技能,在解决监督学习问题之前,为了更好地了解数据集,它通常是一个必要步骤。 降维 ( dimensionality reduction )和 聚类 ( clustering )都是众所周知的无监督学习方法。
4.1.3 自监督学习
自监督学习是监督学习的一个特例,它与众不同, 值得单独归为一类。自监督学习是没有人工标注的标签的监督学习 ,你可以将它看作没有人类参与的监督学习。标签仍然存在(因为总要有什么东西来监督学习过程),但它们是从输入数据中生成的,通常是使用启发式算法生成的。
4.1.4 强化学习
4.2 评估机器学习模型
在第 3 章介绍的三个例子中,我们将数据划分为训练集、验证集和测试集。我们没有在训练模型的相同数据上对模型进行评估,其原因很快显而易见:仅仅几轮过后,三个模型都开始过拟合。也就是说,随着训练的进行,模型在训练数据上的性能始终在提高,但在前所未见的数据上的性能则不再变化或者开始下降。
4.2.1 训练集、验证集和测试集
1. 简单的留出验证
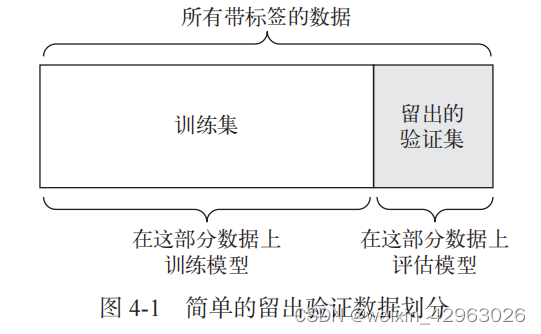
import numpy as np
num_validation_samples = 10000
np.random.shuffle(data) # 通常需要打乱数据
validation_data = data[:num_validation_samples] # 定义验证集
data = data[num_validation_samples:]
training_data = data[:] # 定义训练集
# 在训练数据上训练模型,并在验证数据上评估模型
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
# 现在你可以调节模型、重新训练、评估,然后再次调节……
# 一旦调节好超参数,通常就在所有非测试数据上从头开始训练最终模型
model = get_model()
model.train(np.concatenate([training_data,
validation_data]))
test_score = model.evaluate(test_data)
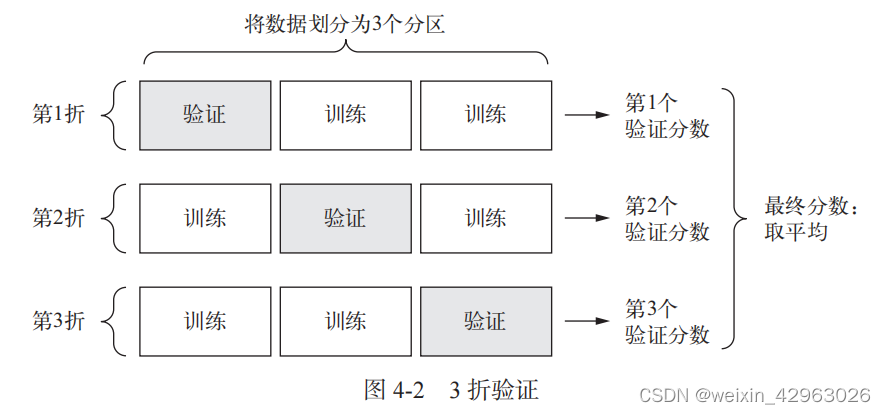
2. K 折验证
4.2.2 评估模型的注意事项
4.3 数据预处理、特征工程和特征学习
除模型评估之外,在深入研究模型开发之前,我们还必须解决另一个重要问题: 将数据输入神经网络之前,如何准备输入数据和目标? 许多数据预处理方法和特征工程技术都是和特定领域相关的(比如只和文本数据或图像数据相关),我们将在后续章节的实例中介绍这些内容。
4.3.1 神经网络的数据预处理
1. 向量化
神经网络的所有输入和目标都必须是浮点数张量 (在特定情况下可以是整数张量)。无论 处理什么数据(声音、图像还是文本),都必须首先将其转换为张量,这一步叫作数据向量化 ( data vectorization)。例如,在前面两个文本分类的例子中,开始时文本都表示为整数列表(代 表单词序列),然后我们用 one-hot 编码将其转换为 float32 格式的张量。在手写数字分类和预 测房价的例子中,数据已经是向量形式,所以可以跳过这一步。
2. 值标准化
在手写数字分类的例子中,开始时图像数据被编码为 0~255 范围内的整数,表示灰度值。 将这一数据输入网络之前,你需要将其转换为 float32 格式并除以 255,这样就得到 0~1 范围内的浮点数。同样,预测房价时,开始时特征有各种不同的取值范围,有些特征是较小的浮点数,有些特征是相对较大的整数。将这一数据输入网络之前,你需要对每个特征分别做标准化,使其均值为 0、标准差为 1。
一般来说,将取值相对较大的数据(比如多位整数,比网络权重的初始值大很多)或 异质数据 ( heterogeneous data ,比如数据的一个特征在 0~1 范围内,另一个特征在 100~200 范围内) 输入到神经网络中是不安全的。这么做可能导致较大的梯度更新,进而导致网络无法收敛。为 了让网络的学习变得更容易,输入数据应该具有以下特征。
取值较小 :大部分值都应该在 0~1 范围内。
同质性(homogenous) :所有特征的取值都应该在大致相同的范围内。
此外,下面这种更严格的标准化方法也很常见,而且很有用,虽然不一定总是必需的(例如,
对于数字分类问题就不需要这么做)。
将每个特征分别标准化,使其平均值为 0。
将每个特征分别标准化,使其标准差为 1 。
这对于 Numpy 数组很容易实现。
x -= x.mean(axis=0)
x /= x.std(axis=0)
假设 x 是一个形状为 (samples, features) 的二维矩阵
3. 处理缺失值
你的数据中有时可能会有缺失值。例如在房价的例子中,第一个特征(数据中索引编号为 0 的列)是人均犯罪率。如果不是所有样本都具有这个特征的话,怎么办?那样你的训练数据 或测试数据将会有缺失值。
一般来说,对于神经网络,将缺失值设置为 0 是安全的,只要 0 不是一个有意义的值。网络能够从数据中学到 0 意味着 缺失数据 ,并且会忽略这个值。
注意,如果测试数据中可能有缺失值,而网络是在没有缺失值的数据上训练的,那么网络 不可能学会忽略缺失值。在这种情况下,你应该人为生成一些有缺失项的训练样本:多次复制 一些训练样本,然后删除测试数据中可能缺失的某些特征。
4.3.2 特征工程
特征工程(feature engineering) 是指将数据输入模型之前,利用你自己关于数据和机器学 习算法(这里指神经网络)的知识对数据进行硬编码的变换(不是模型学到的),以改善模型的 效果。多数情况下,一个机器学习模型无法从完全任意的数据中进行学习。呈现给模型的数据 应该便于模型进行学习。
我们来看一个直观的例子。假设你想开发一个模型,输入一个时钟图像,模型能够输出对应的时间(见图 4-3 )。
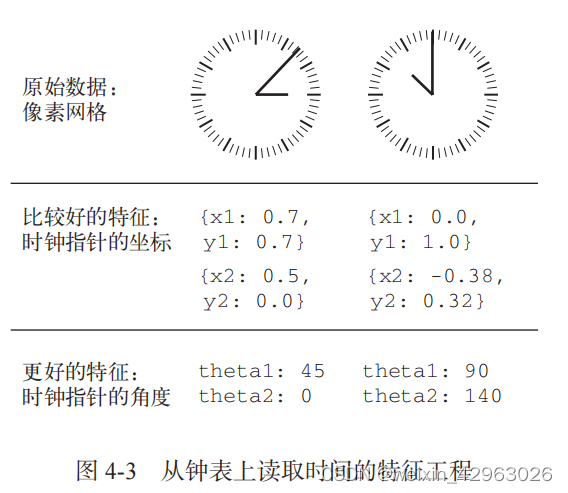
如果你选择用图像的原始像素作为输入数据,那么这个机器学习问题将非常困难。你需要 用卷积神经网络来解决这个问题,而且还需要花费大量的计算资源来训练网络。 但如果你从更高的层次理解了这个问题(你知道人们怎么看时钟上的时间),那么可以为机 器学习算法找到更好的输入特征,比如你可以编写 5 行 Python 脚本,找到时钟指针对应的黑色
像素并输出每个指针尖的 ( x , y ) 坐标,这很简单。然后,一个简单的机器学习算法就可以学会这些坐标与时间的对应关系。
你还可以进一步思考:进行坐标变换,将 ( x , y ) 坐标转换为相对于图像中心的极坐标。这样输入就变成了每个时钟指针的角度 theta。现在的特征使问题变得非常简单,根本不需要机器学习,因为简单的舍入运算和字典查找就足以给出大致的时间。
这就是 特征工程的本质:用更简单的方式表述问题,从而使问题变得更容易。它通常需要深入理解问题。
深度学习出现之前,特征工程曾经非常重要,因为经典的浅层算法没有足够大的假设空间来自己学习有用的表示。将数据呈现给算法的方式对解决问题至关重要。例如,卷积神经网络在 MNIST 数字分类问题上取得成功之前,其解决方法通常是基于硬编码的特征,比如数字图像中的圆圈个数、图像中每个数字的高度、像素值的直方图等。
幸运的是,对于现代深度学习,大部分特征工程都是不需要的,因为神经网络能够从原始 数据中自动提取有用的特征。这是否意味着,只要使用深度神经网络,就无须担心特征工程呢?并不是这样,原因有两点。
良好的特征仍然可以让你用更少的资源更优雅地解决问题 。例如,使用卷积神经网络来读取钟面上的时间是非常可笑的。
良好的特征可以让你用更少的数据解决问题 。深度学习模型自主学习特征的能力依赖于大量的训练数据。如果只有很少的样本,那么特征的信息价值就变得非常重要。
4.4 过拟合与欠拟合
在上一章的三个例子(预测电影评论、主题分类和房价回归)中,模型在留出验证数据上的性能总是在几轮后达到最高点,然后开始下降。也就是说,模型很快就在训练数据上开始过拟合 。过拟合存在于所有机器学习问题中。学会如何处理过拟合对掌握机器学习至关重要。
机器学习的根本问题是优化和泛化之间的对立 。
优化(optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习)。
泛化(generalization)是指训练好的模型在前所未见的数据上的性能好坏 。
机器学习的目的当然是得到良好的泛化,但你无法控制泛化,只能基于训练数据调节模型。
训练开始时,优化和泛化是相关的:训练数据上的损失越小,测试数据上的损失也越小。这时的模型是 欠拟合(underfit) 的,即仍有改进的空间,网络还没有对训练数据中所有相关模式建模。但在训练数据上迭代一定次数之后,泛化不再提高,验证指标先是不变,然后开始变差,即模型开始过拟合。这时模型开始学习仅和训练数据有关的模式,但这种模式对新数据来说是错误的或无关紧要的。
为了防止模型从训练数据中学到错误或无关紧要的模式,最优解决方法是获取更多的训练数据。模型的训练数据越多,泛化能力自然也越好。如果无法获取更多数据,次优解决方法是调节模型允许存储的信息量,或对模型允许存储的信息加以约束。如果一个网络只能记住几个模式,那么优化过程会迫使模型集中学习最重要的模式,这样更可能得到良好的泛化。
这种降低过拟合的方法叫作 正则化(regularization) 。我们先介绍几种最常见的正则化方法,然后将其应用于实践中,以改进 3.4 节的电影分类模型。
4.4.1 减小网络大小
防止过拟合的最简单的方法就是减小模型大小,即减少模型中可学习参数的个数(这由层数和每层的单元个数决定)。在深度学习中,模型中可学习参数的个数通常被称为模型的容量 ( capacity )。直观上来看,参数更多的模型拥有更大的 记忆容量 (memorization capacity),因此能够在训练样本和目标之间轻松地学会完美的字典式映射,这种映射没有任何泛化能力。例如,拥有 500 000 个二进制参数的模型,能够轻松学会 MNIST 训练集中所有数字对应的类别——我们
只需让 50 000 个数字每个都对应 10 个二进制参数。但这种模型对于新数字样本的分类毫无用处。
始终牢记:深度学习模型通常都很擅长拟合训练数据,但真正的挑战在于泛化,而不是拟合。 与此相反,如果网络的记忆资源有限,则无法轻松学会这种映射。因此,为了让损失最小化, 网络必须学会对目标具有很强预测能力的压缩表示,这也正是我们感兴趣的数据表示。同时请 记住,你使用的模型应该具有足够多的参数,以防欠拟合,即模型应避免记忆资源不足。在容 量过大 与 容量不足 之间要找到一个折中。
不幸的是,没有一个魔法公式能够确定最佳层数或每层的最佳大小。你必须评估一系列不 同的网络架构(当然是在验证集上评估,而不是在测试集上),以便为数据找到最佳的模型大小。 要找到合适的模型大小,一般的工作流程是开始时选择相对较少的层和参数,然后逐渐增加层的大小或增加新层,直到这种增加对验证损失的影响变得很小。
我们在电影评论分类的网络上试一下。原始网络如下所示。
from keras import models
from keras import layers
import matplotlib.pyplot
from keras.datasets import imdb
import numpy as np
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)
# word_index 是一个将单词映射为整数索引的字典
word_index = imdb.get_word_index()
# 键值颠倒,将整数索引映射为单词
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
# enumerate
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # 将 results[i] 的指定索引设为 1
# print(i, sequence)
# print(results)
return results
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
original_model = models.Sequential()
original_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
original_model.add(layers.Dense(16, activation='relu'))
original_model.add(layers.Dense(1, activation='sigmoid'))
original_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
smaller_model = models.Sequential()
smaller_model.add(layers.Dense(4, activation='relu', input_shape=(10000,)))
smaller_model.add(layers.Dense(4, activation='relu'))
smaller_model.add(layers.Dense(1, activation='sigmoid'))
smaller_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
original_hist = original_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
smaller_model_hist = smaller_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
epochs = range(1, 21)
original_val_loss = original_hist.history['val_loss']
smaller_model_val_loss = smaller_model_hist.history['val_loss']
# 'bo' 表示蓝色圆点
matplotlib.pyplot.plot(epochs, original_val_loss, 'bo', label='Original loss')
# 'b' 表示蓝色实线
matplotlib.pyplot.plot(epochs, smaller_model_val_loss, 'b', label='Smaller loss')
matplotlib.pyplot.title('Training and validation loss')
matplotlib.pyplot.xlabel('Epochs')
matplotlib.pyplot.ylabel('Loss')
matplotlib.pyplot.legend()
matplotlib.pyplot.show()
如你所见,更小的网络开始过拟合的时间要晚于参考网络(前者 6 轮后开始过拟合,而后
者 4 轮后开始),而且开始过拟合之后,它的性能变差的速度也更慢。
为了好玩,我们再向这个基准中添加一个容量更大的网络(容量远大于问题所需)
bigger_model = models.Sequential()
bigger_model.add(layers.Dense(512, activation='relu', input_shape=(10000,)))
bigger_model.add(layers.Dense(512, activation='relu'))
bigger_model.add(layers.Dense(1, activation='sigmoid'))
bigger_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
bigger_model_hist = bigger_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
pochs = range(1, 21)
original_val_loss = original_hist.history['val_loss']
bigger_model_val_loss = bigger_model_hist.history['val_loss']
# 'bo' 表示蓝色圆点
plt.plot(epochs, original_val_loss, 'bo', label='Original_ loss')
# 'b' 表示蓝色实线
plt.plot(epochs, bigger_model_val_loss, 'b', label='Bigger loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
上图同时给出了这两个网络的训练损失。如你所见,更大网络的训练损失很快就接近于零。 网络的容量越大,它拟合训练数据(即得到很小的训练损失)的速度就越快,但也更容易过拟合 (导致训练损失和验证损失有很大差异)。
4.4.2 添加权重正则化 | weight regularization
你可能知道 奥卡姆剃刀 (Occam’s razor)原理:如果一件事情有两种解释,那么最可能正 确的解释就是最简单的那个,即假设更少的那个。这个原理也适用于神经网络学到的模型:给定一些训练数据和一种网络架构,很多组权重值(即很多 模型)都可以解释这些数据。 简单模型比复杂模型更不容易过拟合。
这里的 简单模型(simple model)是指参数值分布的熵更小的模型(或参数更少的模型 ,比 如上一节的例子)。因此,一种常见的降低过拟合的方法就是强制让模型权重只能取较小的值, 从而限制模型的复杂度,这使得权 重值的分布更加规则(regular) 。这种方法叫作权重正则化 ( weight regularization ),其实现方法是向网络损失函数中添加与较大权重值相关的 成本 ( cost )。
这个成本有两种形式。
L1 正则化(L1 regularization) :添加的成本与 权重系数的绝对值 [权重的 L1 范数 ( norm)] 成正比。
L2 正则化(L2 regularization) :添加的成本与 权重系数的平方 (权重的 L2 范数)成正比。 神经网络的 L2 正则化也叫 权重衰减 ( weight decay)。不要被不同的名称搞混,权重衰减 与 L2 正则化在数学上是完全相同的。
在 Keras 中,添加权重正则化的方法是向层传递 权重正则化项实例 (weight regularizer instance )作为关键字参数。下列代码将向电影评论分类网络中添加 L2 权重正则化。
其中L1的限制,使得大部分都在角的部分相交,就使得某些参数为0,而L2没有突出的角,所以不能使得参数为0。总结就是L1会使得某些参数为0,具有稀疏性,而L2没有这个功能,使得参数的值比较小去降低过拟合。
L1,L2都是规则化的方式,最小化目标函数,类似于一个下坡的过程,所以它们下降的坡不同,L1是按照绝对值函数下坡,L2是按照二次函数下坡,在0附近,L1的速度更快。
from keras import models
from keras import layers
import matplotlib.pyplot as plt
from keras.datasets import imdb
import numpy as np
from keras import regularizers
#
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)
#
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
# enumerate
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # 将 results[i] 的指定索引设为 1
# print(i, sequence)
# print(results)
return results
x_train = vectorize_sequences(train_data)
# 将测试数据向量化
x_test = vectorize_sequences(test_data)
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
original_model = models.Sequential()
original_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
original_model.add(layers.Dense(16, activation='relu'))
original_model.add(layers.Dense(1, activation='sigmoid'))
original_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
original_hist = original_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
# l2(0.001) 的意思是该层权重矩阵的每个系数都会使网络总损失增加 0.001 * weight_
# coefficient_value。注意,由于这个惩罚项只在训练时添加,
# 所以这个网络的训练损失会比测试损失大很多。
l2_model = models.Sequential()
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu'))
l2_model.add(layers.Dense(1, activation='sigmoid'))
l2_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
l2_model_hist = l2_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
epochs = range(1, 21)
original_val_loss = original_hist.history['val_loss']
l2_model_val_loss = l2_model_hist.history['val_loss']
# 'bo' 表示蓝色圆点
plt.plot(epochs, original_val_loss, 'bo', label='Original loss')
# 'b' 表示蓝色实线
plt.plot(epochs, l2_model_val_loss, 'b', label='l2 loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
上图显示了 L2 正则化惩罚的影响。如你所见,即使两个模型的参数个数相同,具有 L2 正则化的模型(圆点)比参考模型(实线)更不容易过拟合。
你还可以用 Keras 中以下这些权重正则化项来代替 L2 正则化。也可以同时做 L1 和 L2 正则化
from keras import regularizers
regularizers.l1(0.001)
regularizers.l1_l2(l1=0.001, l2=0.001)
4.4.3 添加 dropout 正则化
dropout 是神经网络最有效也最常用的正则化方法之一,它是由多伦多大学的 Geoffrey Hinton 和他的学生开发的。 对某一层使用 dropout,就是在训练过程中随机将该层的一些输出特征舍弃(设置为 0) 。假设在训练过程中,某一层对给定输入样本的返回值应该是向量 [0.2, 0.5, 1.3, 0.8, 1.1] 。使用 dropout 后,这个向量会有几个随机的元素变成 0 ,比如 [0, 0.5, 1.3, 0, 1.1] 。 dropout 比率(dropout rate)是被设为 0 的特征所占的比例,通常在 0.2~0.5 范围内 。测试时没有单元被舍弃,而该层的输出值需要按 dropout 比率缩小,因为这时比训练时 有更多的单元被激活,需要加以平衡。
假设有一个包含某层输出的 Numpy 矩 阵 layer_output ,其形状为 (batch_size, features) 。训练时,我们随机将矩阵中一部分值设为 0 。
4.5 机器学习的通用工作流程
4.5.1 定义问题,收集数据集
首先,你必须定义所面对的问题。
你的输入数据是什么?你要预测什么? 只有拥有可用的训练数据,你才能学习预测某件 事情。比如,只有同时拥有电影评论和情感标注,你才能学习对电影评论进行情感分类。 因此,数据可用性通常是这一阶段的限制因素(除非你有办法付钱让人帮你收集数据)。
你面对的是什么类型的问题 ?是二分类问题、多分类问题、标量回归问题、向量回归问题, 还是多分类、多标签问题?或者是其他问题,比如聚类、生成或强化学习?确定问题类 型有助于你选择模型架构、损失函数等。 只有明确了输入、输出以及所使用的数据,你才能进入下一阶段。注意你在这一阶段所做 的假设。
假设输出是可以根据输入进行预测的。
假设可用数据包含足够多的信息,足以学习输入和输出之间的关系。
4.5.2 选择衡量成功的指标
要控制一件事物,就需要能够观察它。要取得成功,就必须给出成功的定义:精度?准确
率( precision )和召回率( recall )?客户保留率?衡量成功的指标将指引你选择损失函数,即
模型要优化什么。它应该直接与你的目标(如业务成功)保持一致。
4.5.3 确定评估方法
一旦明确了目标,你必须确定如何衡量当前的进展。前面介绍了三种常见的评估方法。
留出验证集 。数据量很大时可以采用这种方法。
K 折交叉验证 。如果留出验证的样本量太少,无法保证可靠性,那么应该选择这种方法。
重复的 K 折验证。如果可用的数据很少,同时模型评估又需要非常准确,那么应该使用 这种方法。
只需选择三者之一。大多数情况下,第一种方法足以满足要求。
4.5.4 准备数据
4.5.5 开发比基准更好的模型
这一阶段的目标是获得 统计功效(statistical power ),即开发一个小型模型,它能够打败纯随机的基准( dumb baseline )。在 MNIST 数字分类的例子中,任何精度大于 0.1 的模型都可以说 具有统计功效;在 IMDB 的例子中,任何精度大于 0.5 的模型都可以说具有统计功效。 注意,不一定总是能获得统计功效。如果你尝试了多种合理架构之后仍然无法打败随机基准, 那么原因可能是问题的答案并不在输入数据中。要记住你所做的两个假设。
假设输出是可以根据输入进行预测的。
假设可用的数据包含足够多的信息,足以学习输入和输出之间的关系。
这些假设很可能是错误的,这样的话你需要从头重新开始。
如果一切顺利,你还需要选择三个关键参数来构建第一个工作模型。
最后一层的激活。 它对网络输出进行有效的限制。例如, IMDB 分类的例子在最后一层 使用了 sigmoid ,回归的例子在最后一层没有使用激活,等等。
损失函数。 它应该匹配你要解决的问题的类型。例如, IMDB 的例子使用 binary_ crossentropy 、回归的例子使用 mse ,等等。
优化配置。 你要使用哪种优化器?学习率是多少?大多数情况下,使用 rmsprop 及其 默认的学习率是稳妥的。
关于损失函数的选择,需要注意, 直接优化衡量问题成功的指标不一定总是可行的 。有时 难以将指标转化为损失函数,要知道,损失函数需要在只有小批量数据时即可计算(理想情况 下,只有一个数据点时,损失函数应该也是可计算的),而且还必须是可微的(否则无法用反向 传播来训练网络)。例如,广泛使用的分类指标 ROC AUC 就不能被直接优化。因此在分类任务 中,常见的做法是优化 ROC AUC 的替代指标,比如交叉熵。 一般来说,你可以认为交叉熵越小, ROC AUC 越大。
4.5.6 扩大模型规模:开发过拟合的模型
要搞清楚你需要多大的模型,就必须开发一个过拟合的模型,这很简单。
(1) 添加更多的层。
(2) 让每一层变得更大。
(3) 训练更多的轮次。
要始终监控训练损失和验证损失,以及你所关心的指标的训练值和验证值。如果你发现模型在验证数据上的性能开始下降,那么就出现了过拟合。
下一阶段将开始正则化和调节模型,以便尽可能地接近理想模型,既不过拟合也不欠拟合。
4.5.7 模型正则化与调节超参数| hyperparameter
这一步是最费时间的:你将不断地调节模型、训练、在验证数据上评估(这里不是测试数据)、
再次调节模型,然后重复这一过程,直到模型达到最佳性能。你应该尝试以下几项。
添加 dropout 。
尝试不同的架构:增加或减少层数。
添加 L1 和 / 或 L2 正则化。
尝试不同的超参数(比如每层的单元个数或优化器的学习率),以找到最佳配置。
(可选)反复做特征工程:添加新特征或删除没有信息量的特征。
本章小结
定义问题与要训练的数据。收集这些数据,有需要的话用标签来标注数据。
选择衡量问题成功的指标。你要在验证数据上监控哪些指标?
确定评估方法:留出验证? K 折验证?你应该将哪一部分数据用于验证?
开发第一个比基准更好的模型,即一个具有统计功效的模型。
开发过拟合的模型。
基于模型在验证数据上的性能来进行模型正则化与调节超参数。许多机器学习研究往往
只关注这一步,但你一定要牢记整个工作流程。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_42963026/article/details/134316116