模型介绍
GoogLeNet是谷歌工程师设计的深度神经网络结构,于2014年在ImageNet比赛中取得了冠军。它的设计特点在于既有深度,又在横向上拥有“宽度”,并采用了一种名为Inception的核心子网络结构。这个网络名字中的“GoogLeNet”是对LeNet的致敬,LeNet是早期由Yann LeCun设计的卷积神经网络。
论文地址:https://arxiv.org/pdf/1409.4842.pdf
模型结构
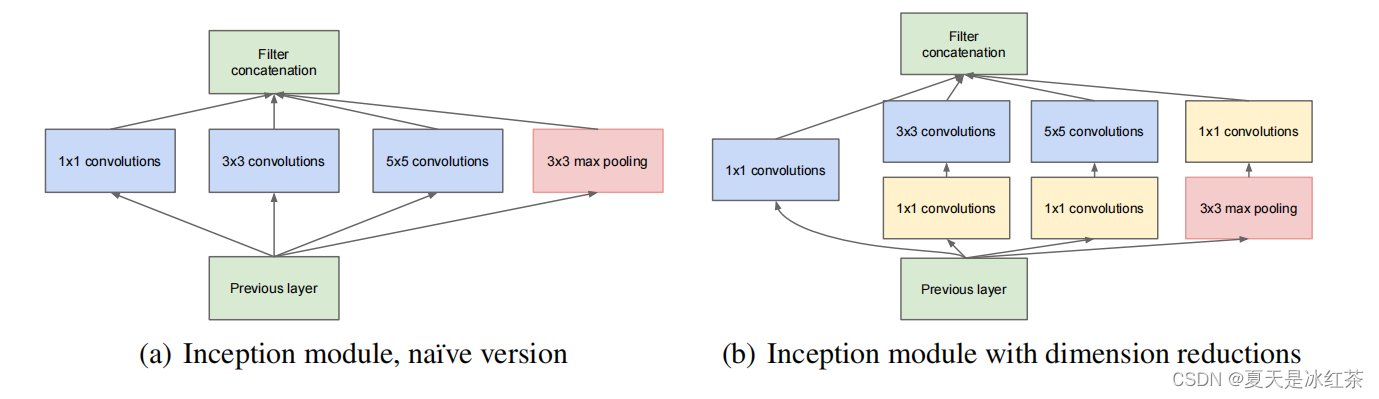
左图(a)就是Inception模块的设计思想,它的设计是通过并行使用多个卷积和池化操作来提取特征,然后将这四个操作的输出进行通道维度的拼接,这样获得的图像是经过不同核大小的卷积提取的特征,有利于捕捉不同尺度的特征。
- 1x1卷积核用于学习通道间的线性关系和降维。
- 3x3卷积核用于捕捉局部特征和空间相关性。
- 5x5卷积核用于学习更大范围的特征。
- 最大池化用于捕捉局部的空间不变性。
不过,Inception的计算复杂度相对较高,尤其是包含大尺寸卷积核的部分。并行使用了多个卷积和池化操作,模块内的参数数量较大,这可能导致过拟合,尤其是在数据量有限的情况下。
为了减小参数量,又使用像右图(b)所示的那样,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数,在最大池化层后面增加1x1卷积层减小输出通道数。
代码实现
该网络的实现比较简单,没有加辅助分类器。
import torch
import torch.nn as nn
__all__ = ["GoogLeNet"]
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = self.BasicConv(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
self.BasicConv(in_channels, ch3x3red, kernel_size=1),
self.BasicConv(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
self.BasicConv(in_channels, ch5x5red, kernel_size=1),
self.BasicConv(ch5x5red, ch5x5, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
self.BasicConv(in_channels, pool_proj, kernel_size=1)
)
def BasicConv(self, in_channels, out_channels, **kwargs):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, bias=False, **kwargs),
nn.BatchNorm2d(out_channels, eps=0.001),
nn.ReLU(inplace=True),)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, dim=1)
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(GoogLeNet, self).__init__()
# 可参考 https://arxiv.org/pdf/1409.4842.pdf 第七页结构图和第六页Table 1
self.conv1 = self.BasicConv(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = self.BasicConv(64, 64, kernel_size=1, stride=1)
self.conv3 = self.BasicConv(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def BasicConv(self, in_channels, out_channels, **kwargs):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, bias=False, **kwargs),
nn.BatchNorm2d(out_channels, eps=0.001),
nn.ReLU(inplace=True),)
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x
if __name__=="__main__":
import torchsummary
input = torch.ones(2, 3, 224, 224).cpu()
net = GoogLeNet(num_classes=4)
net = net.cpu()
out = net(input)
print(out)
print(out.shape)
torchsummary.summary(net, input_size=(3, 224, 224))
# Total params: 5,604,004通过使用不同大小的卷积核,模型实现了对不同尺度感受野的提取,这样能够捕获到局部与全局的信息,而且1,3,5这样的选择也方便进行对齐, 在网络的后期,为了减少计算量,使用了 1x1 的卷积核来进行降维。这一设计在保留特征信息的同时,有效地降低了计算复杂度。
GoogLeNet在分类性能上的实验
该实验为四类分类实验,每类有800张左右的图片,分为了训练集,测试集,验证集,轮次为50轮,其他超参数不变。
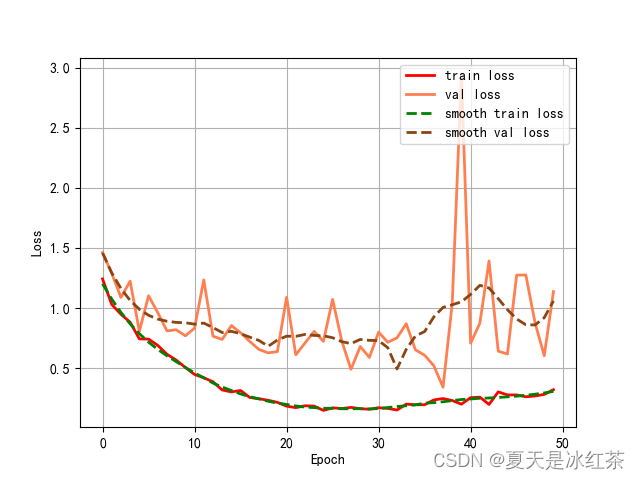
训练集和验证集的损失记录
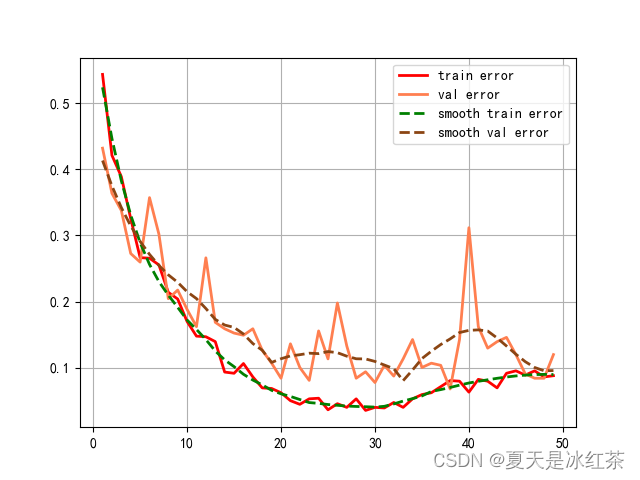
错误率记录
可以看到,在验证集上损失在后期的波动较大,错误率整体还是在向下的趋势。
参考文章
GoogLeNet详解-CSDN博客
GoogLeNet — PaddleEdu documentation
GoogLeNet网络详解与模型搭建_googlenet模型-CSDN博客