探索元宇宙的未来:数字人对话系统 - Linly-Talker —— “数字人交互,与虚拟的自己互动”
之前空闲的时候我似乎已经写过了有关于数字人的两篇文章,今天更多的写这篇文章就是想探索一下元宇宙的未来,这种数字人对话系统能做什么,还需要做什么的,还有什么没做的,以及我做了什么
Kedreamix:“数字人交互,与虚拟的自己互动”——用PaddleAvatar打造数字分身,探索人机交互的未来
Kedreamix: 数字人对话系统 Linly-Talker (已加入Qwen和GeminiPro加强对话+上传任意图片的数字人)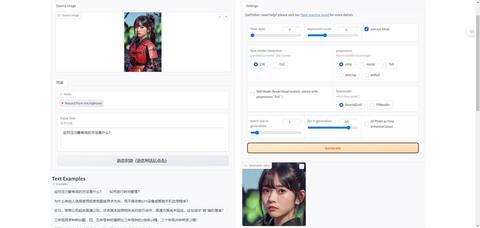
首先给大家贴一下我的数字人对话系统的github链接,我也一直保持更新和迭代,哈哈,一起加油,如果感兴趣可以给个star呀,如果有兴趣和我一起完善我也非常欢迎。
数字人对话系统 - Linly-Talker —— “数字人交互,与虚拟的自己互动”github.com/Kedreamix/Linly-Talker
最后也给出我在b站发布的视频,可以多多关注嘻嘻:
Linly-Talker 更新GPT多轮对话系统,LLM为数字人赋能 !!!_哔哩哔哩_bilibiliwww.bilibili.com/video/BV1v94y1K7GK/
TO DO LIST
先说一下我做了什么吧,这下面是我用gradio已经实现了的,大家都是可以去进行尝试的,代码应该没什么问题,现在如果跑起来,加上Qwen 1.8B的大模型,可能只需要8g显存就能跑起来,还是比较简单的,我也把百度网盘的模型下载链接传上去了,方便大家学习和下载。
- 基本完成对话系统流程,能够
语音对话 - 加入了LLM大模型,包括
Linly,Qwen和GeminiPro的使用 - 可上传
任意数字人照片进行对话 - Linly加入
FastAPI调用方式 - 利用微软
TTS加入高级选项,可设置对应人声以及音调等参数,增加声音的多样性 - 视频生成加入
字幕,能够更好的进行可视化 - GPT
多轮对话系统(提高数字人的交互性和真实感,增强数字人的智能)
那也要提一下我想做或者说未来要做的,这也感谢大家给我提出的意见什么的,其实还有很多的想法,我觉得未来是可以把这个进行完善的,慢慢的进行一个学习和开发,慢慢加强起来。
语音克隆技术(语音克隆合成自己声音,提高数字人分身的真实感和互动体验)- 加入
Langchain的框架,建立本地知识库 实时语音识别(人与数字人之间就可以通过语音进行对话交流)- 替换edgetts,转为个人可训练的TTS模型,可以任意定制音频和音色
- 提高ASR速度,替换Whisper,换为中文ASR
- NeRF数字人的方式,可以考虑替换掉SadTalker或者多几个选项
示例
从github能看到我对应给出的示例,现在能够自己自由的对话了
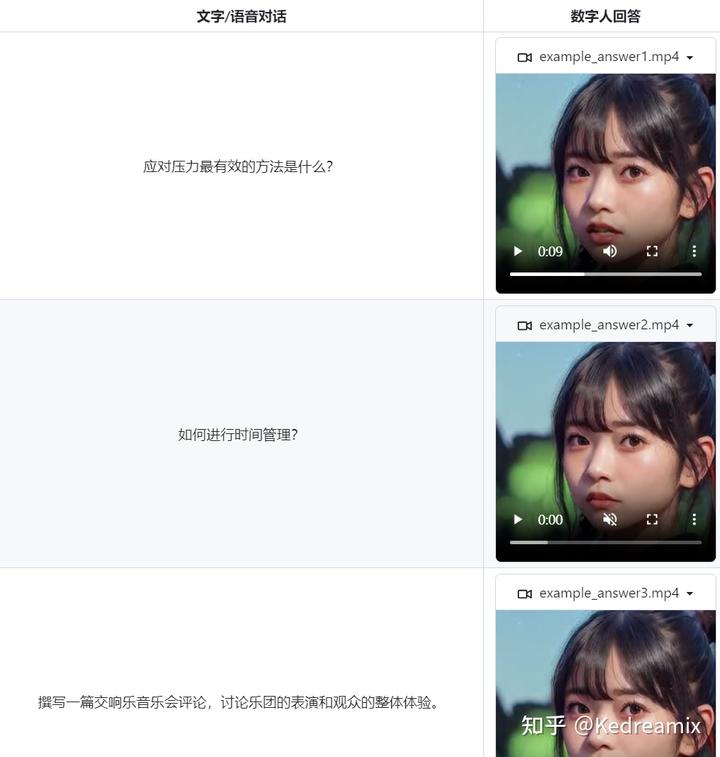
项目展示
接下来讲一下我的更新,我从2023.12到现在,大概是更新了三个版本,现在应该都是可以使用并且没有bug的,如果有问题有bug我也会及时完善
2023.12 更新
用户可以上传任意图片进行对话
2024.01 更新
- 令人兴奋的消息!我现在已经将强大的GeminiPro和Qwen大模型融入到我们的对话场景中。用户现在可以在对话中上传任何图片,为我们的互动增添了全新的层面。
- 更新了FastAPI的部署调用方法。
- 更新了微软TTS的高级设置选项,增加声音种类的多样性,以及加入视频字幕加强可视化。
- 更新了GPT多轮对话系统,使得对话有上下文联系,提高数字人的交互性和真实感
现在的启动一共有几种模式,可以选择特定的场景进行设置
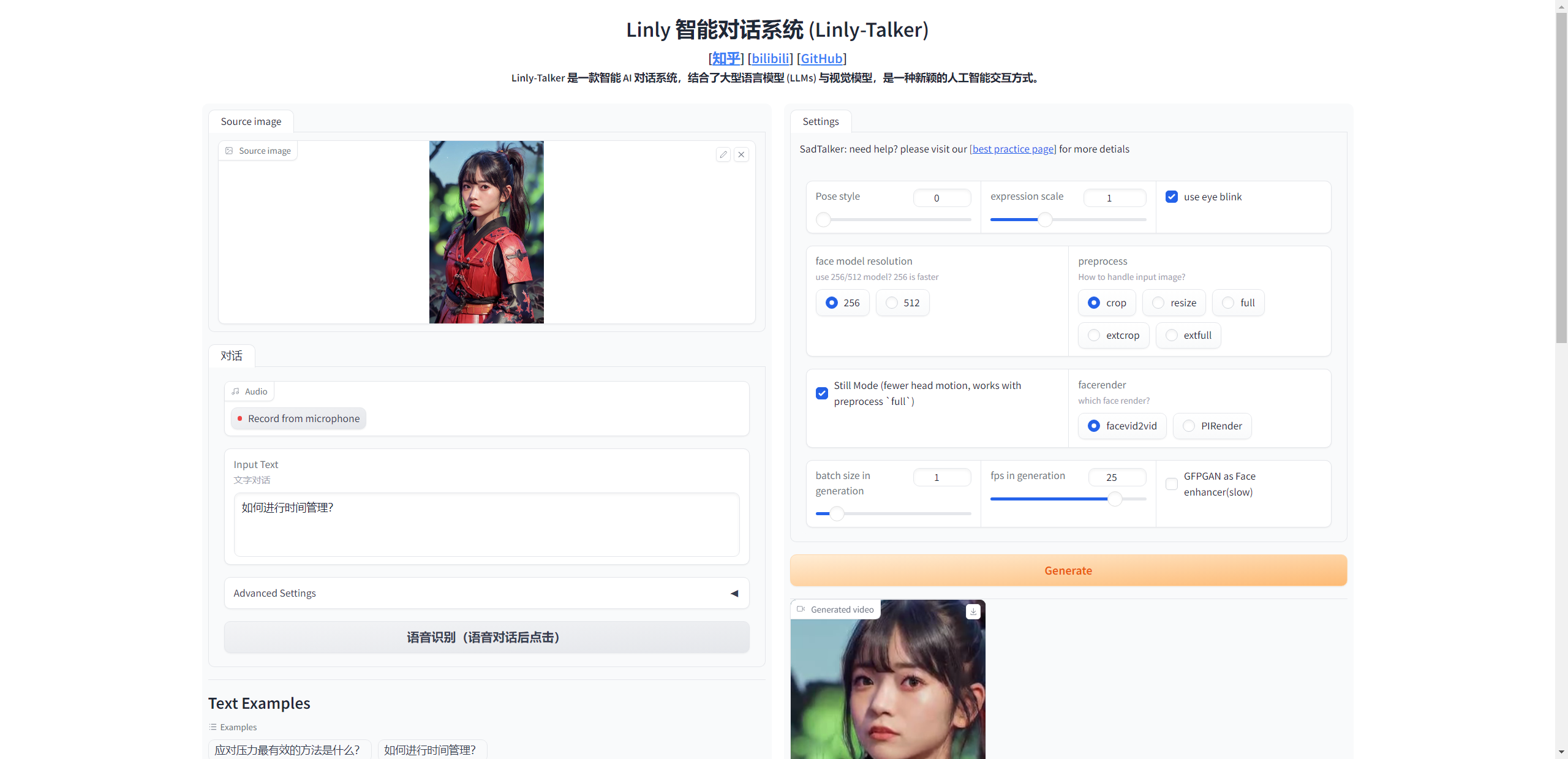
第一种只有固定了人物问答,设置好了人物,省去了预处理时间
python app.py

第二种是可以任意上传图片进行对话
python app_img.py
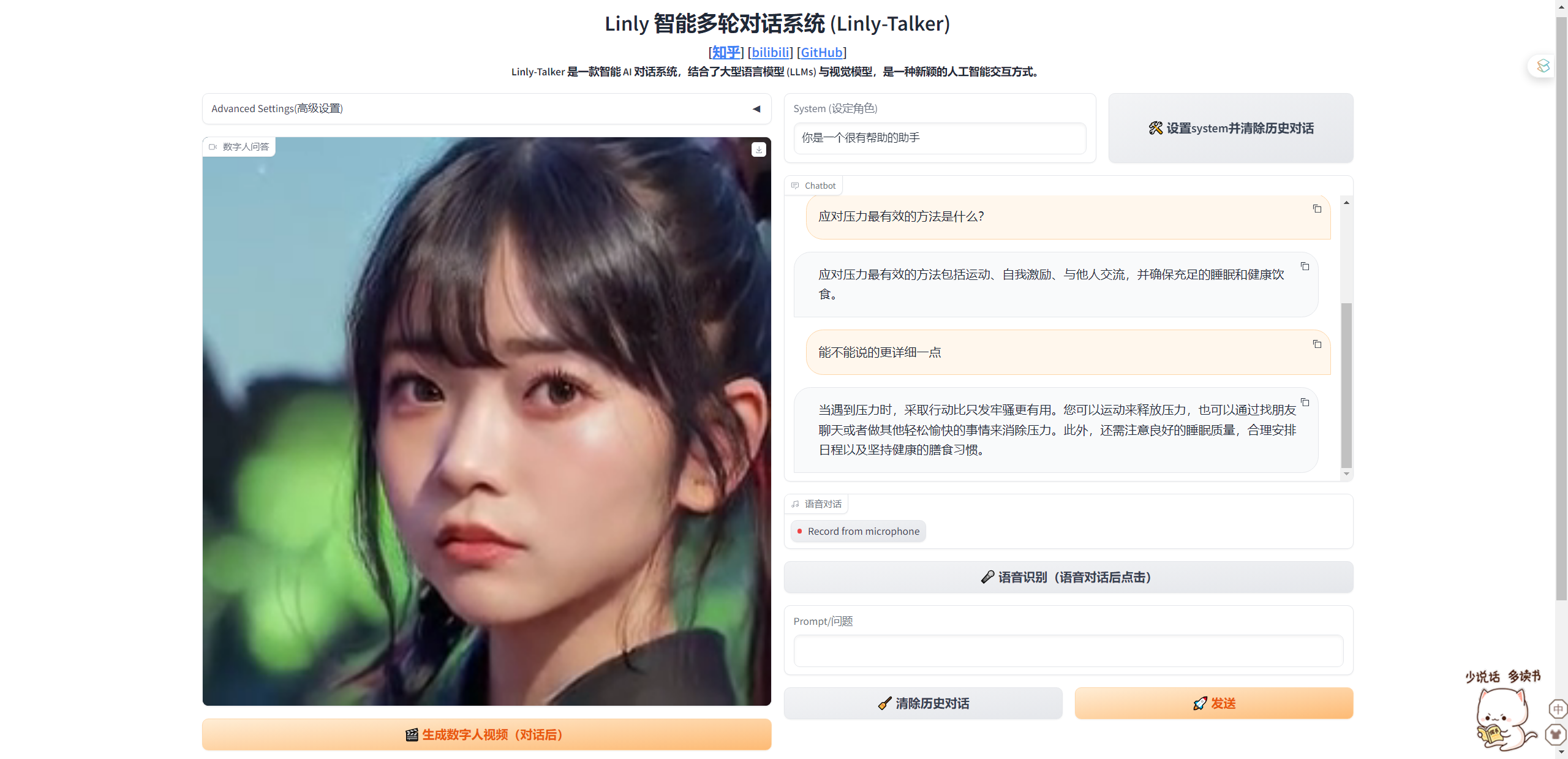
第三种是在第一种的基础上加入了大语言模型,加入了多轮的GPT对话
python app_multi.py
文件夹结构如下
Baidu (百度云盘) (Password: linl)
Linly-Talker/
├── app.py
├── app_img.py
├── utils.py
├── Linly-api.py
├── Linly-api-fast.py
├── Linly-example.ipynb
├── README.md
├── README_zh.md
├── request-Linly-api.py
├── requirements_app.txt
├── scripts
│ └── download_models.sh
├── src
│ └── .....
├── inputs
│ ├── example.png
│ └── first_frame_dir
│ ├── example_landmarks.txt
│ ├── example.mat
│ └── example.png
├── examples
│ └── source_image
│ ├── art_0.png
│ ├── ......
│ └── sad.png
├── checkpoints // SadTalker 权重路径
│ ├── mapping_00109-model.pth.tar
│ ├── mapping_00229-model.pth.tar
│ ├── SadTalker_V0.0.2_256.safetensors
│ └── SadTalker_V0.0.2_512.safetensors
├── gfpgan // GFPGAN 权重路径
│ └── weights
│ ├── alignment_WFLW_4HG.pth
│ └── detection_Resnet50_Final.pth
├── Linly-AI // Linly 权重路径
│ └── Chinese-LLaMA-2-7B-hf
│ ├── config.json
│ ├── generation_config.json
│ ├── pytorch_model-00001-of-00002.bin
│ ├── pytorch_model-00002-of-00002.bin
│ ├── pytorch_model.bin.index.json
│ ├── README.md
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.model
├── Qwen // Qwen 权重路径
│ └── Qwen-1_8B-Chat
│ ├── cache_autogptq_cuda_256.cpp
│ ├── cache_autogptq_cuda_kernel_256.cu
│ ├── config.json
│ ├── configuration_qwen.py
│ ├── cpp_kernels.py
│ ├── examples
│ │ └── react_prompt.md
│ ├── generation_config.json
│ ├── LICENSE
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── modeling_qwen.py
│ ├── model.safetensors.index.json
│ ├── NOTICE
│ ├── qwen_generation_utils.py
│ ├── qwen.tiktoken
│ ├── README.md
│ ├── tokenization_qwen.py
│ └── tokenizer_config.json
总结
最后说一下我想做什么吧,其实我一直把这个数字对话系统趋于实时化,最近也看到相关的项目有做音频和视频流式的东西,我也在不断的学习中,希望也不断的学习,不断的超越自己。最后也提一下,我做了一个个人博客,后续也会放出来我博客的笔记,和知乎同步更新应该哈哈,大家也可以多关注一下,一起学习交流。