训练效果
DDPG算法是一种基于演员-评论家(Actor-Critic)框架的深度强化学习(Deep Reinforcement Learning)算法,它可以处理连续动作空间的问题。DDPG算法描述如下:
GPT-4 Turbo

Copilot GPT-4


DDPG算法伪代码:

深度确定性策略梯度(DDPG)算法,用于训练一个智能体解决OpenAI Gym中的LunarLanderContinuous-v2环境示例代码

import argparse # 用于解析命令行参数
from collections import deque # 提供了一个双端队列
import itertools # 用于对迭代对象执行多种操作
import random # 提供随机数相关的函数
import time # 提供时间相关的函数
import torch.optim as optim # 提供了模型优化器
import gymnasium as gym # 强化学习环境的库
import numpy as np # 数学库,用于数组和矩阵等数学运算
import torch.nn.functional as F # PyTorch的函数接口
import torch # 神经网络库
import torch.nn as nn # 用于构建神经网络
from torch.utils.tensorboard import SummaryWriter # 用于可视化的工具
# 定义一个高斯噪声类,用于给动作添加一些随机性,增加探索性
class GaussianNoise:
def __init__(self, dim, mu=None, std=None):
# 初始化高斯噪声的均值和标准差,如果没有给定,就默认为零向量和0.1的常数向量
self.mu = mu if mu else np.zeros(dim)
self.std = std if std else np.ones(dim) * .1
def sample(self):
# 从高斯分布中采样一个噪声
return np.random.normal(self.mu, self.std)
# 定义一个回放缓冲区类,用于存储和采样转移
class ReplayMemory:
__slots__ = ['buffer']
def __init__(self, capacity):
# 初始化回放缓冲区的容量,使用一个双端队列来实现
self.buffer = deque(maxlen=capacity)
def __len__(self):
# 返回回放缓冲区的长度
return len(self.buffer)
def append(self, *transition):
# 将一个转移(状态,动作,奖励,下一个状态,是否结束)添加到回放缓冲区中
# 使用tuple和map函数来将转移转换为元组的形式
self.buffer.append(tuple(map(tuple, transition)))
def sample(self, batch_size, device):
'''sample a batch of transition tensors'''
# 从回放缓冲区中随机采样一批转移,返回一个生成器,每个元素是一个张量
# 使用random.sample函数来随机采样
# 使用torch.tensor函数来将转移转换为张量,并指定数据类型为浮点数和设备为device
# 使用zip和*操作符来将转移按照元素分组
transitions = random.sample(self.buffer, batch_size)
return (torch.tensor(x, dtype=torch.float, device=device)
for x in zip(*transitions))
# 定义一个演员网络类,用于输出一个确定性的动作
# ActorNet动作空间是2的原因是因为它需要适应环境的动作空间。
# 在LunarLanderContinuous-v2环境中,智能体需要控制着陆器的两个引擎,
# 一个是主引擎,一个是方向引擎。主引擎的推力范围是0到1,方向引擎的
# 推力范围是-1到1。因此,智能体的动作空间是一个2维的向量,每个维度
# 的取值范围是-1到1。为了让ActorNet能够输出这样的动作,它的动作空间
# 也需要设置为2,即输出层的神经元个数为2,同时使用Tanh激活函数,
# 使得输出在-1到1之间。
class ActorNet(nn.Module):
def __init__(self, state_dim=8, action_dim=2, hidden_dim=(400, 300)):
# 调用父类的初始化方法
super().__init__()
# 解包隐藏层的维度
h1, h2 = hidden_dim
# 定义演员网络的头部,使用一个全连接层和一个ReLU激活函数
self.actor_head = nn.Sequential(
nn.Linear(state_dim, h1),
nn.ReLU(),
)
# 定义演员网络的主体,使用一个全连接层和一个ReLU激活函数
self.actor = nn.Sequential(
nn.Linear(h1, h2),
nn.ReLU(),
)
# 定义演员网络的输出,使用一个全连接层和一个Tanh激活函数,使得输出在-1到1之间
self.actor_output = nn.Sequential(
nn.Linear(h2, action_dim),
nn.Tanh(),
)
def forward(self, x):
# 定义演员网络的前向传播,输入一个状态,输出一个动作
# 先通过演员网络的头部
x = self.actor_head(x)
# 再通过演员网络的主体
x = self.actor(x)
# 最后通过演员网络的输出
x = self.actor_output(x)
# 返回输出的动作
return x
# 定义一个评论家网络类,用于评估一个状态-动作对的价值
class CriticNet(nn.Module):
def __init__(self, state_dim=8, action_dim=2, hidden_dim=(400, 300)):
# 调用父类的初始化方法
super().__init__()
# 解包隐藏层的维度
h1, h2 = hidden_dim
# 定义评论家网络的头部,使用一个全连接层和一个ReLU激活函数
# 注意输入的维度是状态维度和动作维度的和
self.critic_head = nn.Sequential(
nn.Linear(state_dim + action_dim, h1),
nn.ReLU(),
)
# 定义评论家网络的主体,使用一个全连接层,一个ReLU激活函数和一个全连接层
self.critic = nn.Sequential(
nn.Linear(h1, h2),
nn.ReLU(),
nn.Linear(h2, 1),
)
def forward(self, x, action):
# 定义评论家网络的前向传播,输入一个状态和一个动作,输出一个价值
# 先将状态和动作拼接在一起,然后通过评论家网络的头部
x = self.critic_head(torch.cat([x, action], dim=1))
# 再通过评论家网络的主体
return self.critic(x)
# 定义一个DDPG类,用于实现深度确定性策略梯度算法
class DDPG:
def __init__(self, args):
# 初始化行为网络,即演员网络和评论家网络,并将它们放到指定的设备上
self._actor_net = ActorNet().to(args.device)
self._critic_net = CriticNet().to(args.device)
# 初始化目标网络,即目标演员网络和目标评论家网络,也将它们放到指定的设备上
self._target_actor_net = ActorNet().to(args.device)
self._target_critic_net = CriticNet().to(args.device)
# 将目标网络的参数初始化为行为网络的参数
self._target_actor_net.load_state_dict(self._actor_net.state_dict())
self._target_critic_net.load_state_dict(self._critic_net.state_dict())
# 初始化优化器,使用Adam优化器,分别为演员网络和评论家网络设置不同的学习率
self._actor_opt = optim.Adam(self._actor_net.parameters(), lr=args.lra)
self._critic_opt = optim.Adam(
self._critic_net.parameters(), lr=args.lrc)
# 初始化动作噪声,使用高斯噪声,用于给动作添加一些随机性,增加探索性
self._action_noise = GaussianNoise(dim=2)
# 初始化回放缓冲区,用于存储和采样转移
self._memory = ReplayMemory(capacity=args.capacity)
# 初始化一些配置参数,如设备,批量大小,软更新系数,折扣因子等
self.device = args.device
self.batch_size = args.batch_size
self.tau = args.tau
self.gamma = args.gamma
def select_action(self, state, noise=True):
'''based on the behavior (actor) network and exploration noise'''
# 根据行为网络(演员网络)和探索噪声来选择一个动作
# 将状态转换为一个张量,并放到指定的设备上
state = torch.FloatTensor(state.reshape(1, -1)).to(self.device)
# 不计算梯度,使用演员网络输出一个动作,并将其转换为一个numpy数组
with torch.no_grad():
selected_action = self._actor_net(
state).cpu().detach().numpy().flatten()
# 如果需要添加噪声
if noise:
# 从高斯噪声中采样一个噪声
add_noise = self._action_noise.sample()
# 将动作和噪声相加,并限制在-1到1之间
selected_action = np.clip(selected_action + add_noise, -1.0, 1.0)
# 返回选择的动作
return selected_action
def append(self, state, action, reward, next_state, done):
# 将一个转移(状态,动作,奖励,下一个状态,是否结束)添加到回放缓冲区中
# 注意奖励需要除以100,是否结束需要转换为整数
self._memory.append(state, action, [reward / 100], next_state,
[int(done)])
def update(self):
# 更新网络参数
# 更新行为网络,即演员网络和评论家网络
self._update_behavior_network(self.gamma)
# 更新目标网络,即目标演员网络和目标评论家网络,使用软更新的方式
self._update_target_network(self._target_actor_net, self._actor_net,
self.tau)
self._update_target_network(self._target_critic_net, self._critic_net,
self.tau)
def _update_behavior_network(self, gamma):
# 定义一个内部方法,用于更新行为网络
# 将网络和优化器分别赋值给局部变量,方便使用
actor_net, critic_net, target_actor_net, target_critic_net = self._actor_net, self._critic_net, self._target_actor_net, self._target_critic_net
actor_opt, critic_opt = self._actor_opt, self._critic_opt
# 从回放缓冲区中随机采样一批转移
state, action, reward, next_state, done = self._memory.sample(
self.batch_size, self.device)
## update critic ##
# 更新评论家网络
# 计算评论家网络的损失函数,使用均方误差损失函数
# 使用目标网络来计算目标Q值,使用行为网络来计算当前Q值
q_value = self._critic_net(state, action)
with torch.no_grad():
a_next = target_actor_net(next_state).detach()
q_next = target_critic_net(next_state, a_next).detach()
q_target = reward + gamma * (1-done) * q_next
criterion = nn.MSELoss()
critic_loss = criterion(q_value, q_target)
# 优化评论家网络的参数,先清零梯度,再反向传播,再更新参数
actor_net.zero_grad()
critic_net.zero_grad()
critic_loss.backward()
critic_opt.step()
## update actor ##
# 更新演员网络
# 计算演员网络的损失函数,使用负的评论家网络的输出的均值作为损失函数
# 使用行为网络来输出动作,使用评论家网络来评估动作的价值
action = actor_net(state)
actor_loss = -torch.mean(critic_net(state, action))
# 优化演员网络的参数,先清零梯度,再反向传播,再更新参数
actor_net.zero_grad()
critic_net.zero_grad()
actor_loss.backward()
actor_opt.step()
@staticmethod
def _update_target_network(target_net, net, tau):
'''update target network by _soft_ copying from behavior network'''
# 定义一个静态方法,用于更新目标网络,使用软更新的方式,即目标网络的参数是行为网络的参数的加权平均
# 遍历目标网络和行为网络的参数,分别赋值给局部变量,方便使用
for target, behavior in zip(target_net.parameters(), net.parameters()):
# 使用行为网络的参数和目标网络的参数的加权平均来更新目标网络的参数
# 使用tau来控制更新的速度,tau越小,更新越慢,目标网络越稳定
target.data.copy_(tau * behavior.data + (1.0 - tau) * target.data)
# 定义一个保存模型的方法,输入一个模型路径和一个是否保存检查点的标志
def save(self, model_path, checkpoint=False):
# 如果需要保存检查点,即保存所有的网络和优化器的参数
if checkpoint:
# 使用torch.save函数来保存一个字典,包含演员网络,评论家网络,目标演员网络,目标评论家网络,演员优化器和评论家优化器的参数
# 使用state_dict方法来获取网络和优化器的参数
torch.save(
{
'actor': self._actor_net.state_dict(),
'critic': self._critic_net.state_dict(),
'target_actor': self._target_actor_net.state_dict(),
'target_critic': self._target_critic_net.state_dict(),
'actor_opt': self._actor_opt.state_dict(),
'critic_opt': self._critic_opt.state_dict(),
}, model_path)
# 如果不需要保存检查点,即只保存演员网络和评论家网络的参数
else:
# 使用torch.save函数来保存一个字典,包含演员网络和评论家网络的参数
# 使用state_dict方法来获取网络的参数
torch.save(
{
'actor': self._actor_net.state_dict(),
'critic': self._critic_net.state_dict(),
}, model_path)
# 定义一个加载模型的方法,输入一个模型路径和一个是否加载检查点的标志
def load(self, model_path, checkpoint=False):
# 使用torch.load函数来加载一个字典,包含保存的模型参数
model = torch.load(model_path)
# 使用load_state_dict方法来将演员网络和评论家网络的参数更新为加载的参数
self._actor_net.load_state_dict(model['actor'])
self._critic_net.load_state_dict(model['critic'])
# 如果需要加载检查点,即加载所有的网络和优化器的参数
if checkpoint:
# 使用load_state_dict方法来将目标演员网络,目标评论家网络,演员优化器和评论家优化器的参数更新为加载的参数
self._target_actor_net.load_state_dict(model['target_actor'])
self._target_critic_net.load_state_dict(model['target_critic'])
self._actor_opt.load_state_dict(model['actor_opt'])
self._critic_opt.load_state_dict(model['critic_opt'])
# 定义一个训练的方法,输入一些参数,一个环境,一个智能体和一个写入器
def train(args, env, agent, writer):
# 打印开始训练的信息
print('Start Training')
# 初始化总步数为0
total_steps = 0
# 初始化指数加权移动平均奖励为0
ewma_reward = 0
# 对于每个回合
for episode in range(args.episode):
# 初始化总奖励为0
total_reward = 0
# 重置环境和状态
state, _ = env.reset()
# 对于每个步骤
for t in itertools.count(start=1):
# 选择一个动作,如果总步数小于预热步数,就随机选择一个动作,否则就使用智能体选择一个动作
if total_steps < args.warmup:
action = env.action_space.sample()
else:
action = agent.select_action(state)
# 在环境中执行动作,得到下一个状态,奖励,是否截断,是否结束和其他信息
next_state, reward, truncated, terminated, info = env.step(action)
# 判断是否结束,即是否终止或截断
done = terminated or truncated
# 将转移存储到智能体的回放缓冲区中
agent.append(state, action, reward, next_state, done)
# 如果总步数大于等于预热步数,就更新智能体的网络参数
if total_steps >= args.warmup:
agent.update()
# 将状态更新为下一个状态
state = next_state
# 累加总奖励
total_reward += reward
# 累加总步数
total_steps += 1
# 如果结束,就跳出循环
if done:
# 计算指数加权移动平均奖励,使用0.05作为权重
ewma_reward = 0.05 * total_reward + (1 - 0.05) * ewma_reward
# 使用写入器记录每个回合的总奖励和指数加权移动平均奖励
writer.add_scalar('Train/Episode Reward', total_reward,
total_steps)
writer.add_scalar('Train/Ewma Reward', ewma_reward,
total_steps)
# 打印每个回合的总步数,总奖励和指数加权移动平均奖励
print(
'Step: {}\tEpisode: {}\tLength: {:3d}\tTotal reward: {:.2f}\tEwma reward: {:.2f}'
.format(total_steps, episode, t, total_reward,
ewma_reward))
break
# 关闭环境
env.close()
# 定义一个测试的方法,输入一些参数,一个环境,一个智能体和一个写入器
def test(args, env, agent, writer):
# 打印开始测试的信息
print('Start Testing')
# 定义一个种子的生成器,从参数的种子开始,每次加1,共生成10个种子
seeds = (args.seed + i for i in range(10))
# 初始化一个奖励的列表,用于存储每个回合的总奖励
rewards = []
# 对于每个回合和对应的种子
for n_episode, seed in enumerate(seeds):
# 初始化总奖励为0
total_reward = 0
# 设置环境的种子,使得每次测试的结果是一致的
# env.seed(seed)
env.seed(seed)
# 重置环境和状态
state, _ = env.reset()
# 对于每个步骤
for t in itertools.count(start=1):
# 使用智能体选择一个动作
action = agent.select_action(state)
# 渲染环境,显示动画效果
env.render()
# 在环境中执行动作,得到下一个状态,奖励,是否截断,是否结束和其他信息
state, reward, truncated, terminated, info = env.step(action)
# 判断是否结束,即是否终止或截断
done = terminated or truncated
# 累加总奖励
total_reward += reward
# 如果结束,就跳出循环
if done:
# 使用写入器记录每个回合的总奖励
writer.add_scalar('Test/Episode Reward',
total_reward, n_episode)
# 重置环境和状态
state = env.reset()
break
# 将总奖励添加到奖励的列表中
rewards.append(total_reward)
# 将奖励的列表转换为一个numpy数组
rewards = np.array(rewards)
# 打印平均奖励,即所有回合的总奖励的均值
print('Average Reward', np.mean(rewards))
# 关闭环境
env.close()
# 定义一个主函数,用于执行整个程序
def main():
## arguments ##
# 创建一个参数解析器,用于处理命令行参数
parser = argparse.ArgumentParser(description=__doc__)
# 添加一些参数,包括设备,模型,日志目录等,指定默认值和数据类型
parser.add_argument('-d', '--device', default='cuda')
parser.add_argument('-m', '--model', default='ddpg.pth')
parser.add_argument('--logdir', default='log/ddpg')
# 添加一些训练相关的参数,包括预热步数,回合数,批量大小,回放缓冲区容量,演员网络和评论家网络的学习率,折扣因子,软更新系数等
parser.add_argument('--warmup', default=50000, type=int)
# parser.add_argument('--warmup', default=10000, type=int)
# parser.add_argument('--episode', default=2000, type=int)
# parser.add_argument('--batch_size', default=64, type=int)
parser.add_argument('--episode', default=2800, type=int)
parser.add_argument('--batch_size', default=128, type=int)
parser.add_argument('--capacity', default=500000, type=int)
parser.add_argument('--lra', default=1e-3, type=float)
parser.add_argument('--lrc', default=1e-3, type=float)
parser.add_argument('--gamma', default=.99, type=float)
parser.add_argument('--tau', default=.005, type=float)
# 添加一些测试相关的参数,包括是否只进行测试,是否渲染环境,是否设置种子等
parser.add_argument('--test_only', action='store_true')
parser.add_argument('--render', action='store_true')
parser.add_argument('--seed', default=20200519, type=int)
# 解析命令行参数,得到一个参数对象
args = parser.parse_args()
## main ##
# 创建一个环境,使用OpenAI Gym提供的LunarLanderContinuous-v2环境
env = gym.make('LunarLanderContinuous-v2')
# 创建一个智能体,使用DDPG类,并传入参数对象
agent = DDPG(args)
# 创建一个写入器,用于记录训练和测试的结果,指定日志目录
writer = SummaryWriter(args.logdir)
# 如果只进行测试,就跳过训练的部分
# if args.test_only:
# 否则,进行训练,传入参数对象,环境,智能体和写入器
train(args, env, agent, writer)
# 保存模型,传入模型路径
agent.save(args.model)
# 加载模型,传入模型路径
agent.load(args.model)
# 进行测试,传入参数对象,环境,智能体和写入器
test(args, env, agent, writer)
# 如果当前模块是主模块,就执行主函数
if __name__ == '__main__':
main()train终端输出:
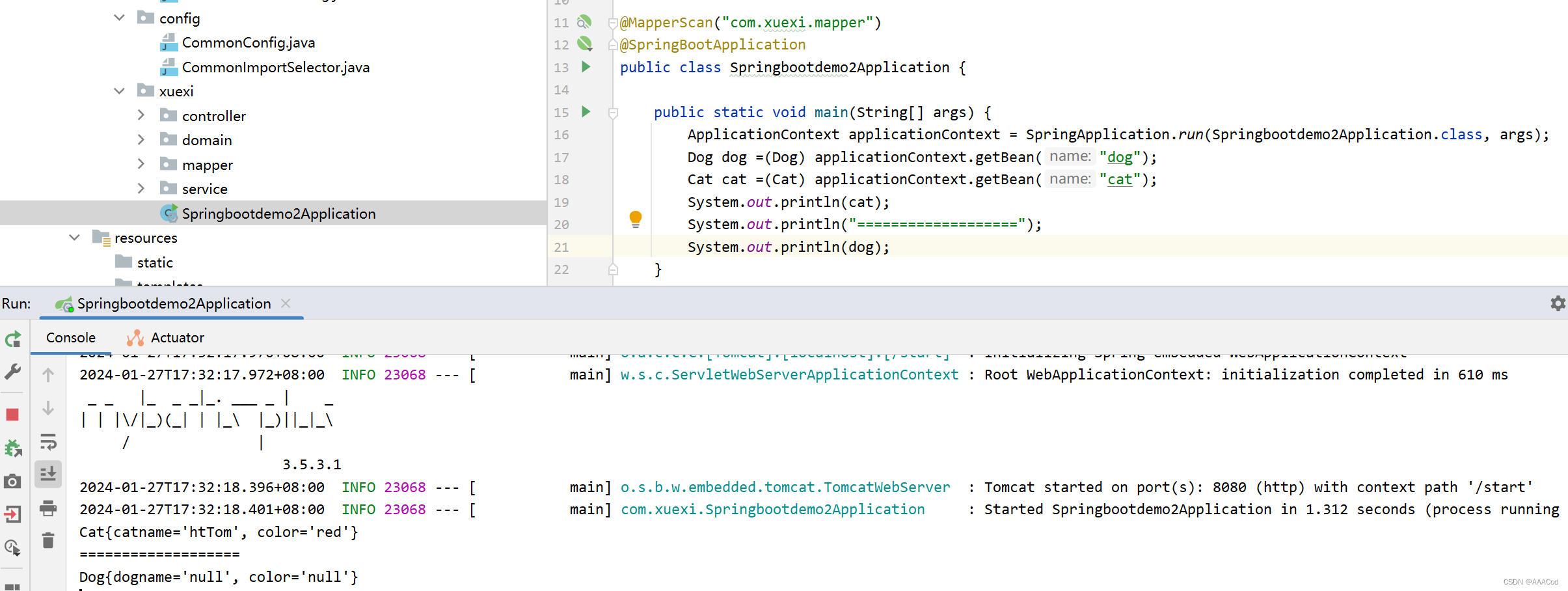
……
Step: 636378 Episode: 1623 Length: 201 Total reward: 265.38 Ewma reward: 93.79
Step: 636595 Episode: 1624 Length: 217 Total reward: 209.17 Ewma reward: 99.56
Step: 636818 Episode: 1625 Length: 223 Total reward: 245.03 Ewma reward: 106.84
Step: 637096 Episode: 1626 Length: 278 Total reward: 236.37 Ewma reward: 113.31
Step: 637424 Episode: 1627 Length: 328 Total reward: 220.33 Ewma reward: 118.66
……
Step: 644345 Episode: 1643 Length: 171 Total reward: 251.87 Ewma reward: 160.08
Step: 644658 Episode: 1644 Length: 313 Total reward: 226.51 Ewma reward: 163.41
Step: 644825 Episode: 1645 Length: 167 Total reward: 256.26 Ewma reward: 168.05
Step: 644940 Episode: 1646 Length: 115 Total reward: 40.98 Ewma reward: 161.70
……
Step: 742280 Episode: 1934 Length: 190 Total reward: 260.15 Ewma reward: 244.47
Step: 742474 Episode: 1935 Length: 194 Total reward: 251.45 Ewma reward: 244.82
Step: 742660 Episode: 1936 Length: 186 Total reward: 219.01 Ewma reward: 243.53
Step: 742772 Episode: 1937 Length: 112 Total reward: 6.66 Ewma reward: 231.69
……Step: 表示当前的总步数,即从训练开始到现在,智能体在环境中执行了多少个动作。
Episode: 表示当前的回合数,即从训练开始到现在,智能体完成了多少个完整的任务。
Length: 表示当前回合的长度,即智能体在当前回合中执行了多少个动作。
Total reward: 表示当前回合的总奖励,即智能体在当前回合中获得的所有奖励的和。
Ewma reward: 表示当前回合的指数加权移动平均奖励,即智能体在所有回合中获得的奖励的指数加权移动平均值,用于衡量智能体的长期表现。
test终端输出:
Average Reward 275.752779884482训练效果:



总 结
DDPG算法是一种基于演员-评论家(Actor-Critic)框架的深度强化学习(Deep Reinforcement Learning)算法,它可以处理连续动作空间的问题。DDPG算法的主要思想是:
演员(Actor)网络:负责根据当前状态(state)输出一个确定性的动作(action),并尝试最大化评论家(Critic)网络给出的期望回报(expected return)。
评论家(Critic)网络:负责根据当前状态(state)和演员(Actor)网络输出的动作(action)评估一个Q值(Q-value),即动作的期望回报(expected return)。
经验回放(Experience Replay)机制:将每一步的转移(transition)(状态(state),动作(action),奖励(reward),下一个状态(next state))存储在一个回放缓冲区(replay buffer)中,然后从中随机采样一批转移(transition)来更新网络参数,这样可以打破数据之间的相关性,提高数据利用效率,稳定学习过程。
目标网络(Target Network)机制:为了减少目标Q值(target Q-value)的震荡和偏差,DDPG算法使用了两组网络参数,一组是在线网络(online network),即实际用于输出动作和评估Q值的网络,另一组是目标网络(target network),即用于计算目标Q值(target Q-value)的网络。目标网络(target network)的参数不是直接更新,而是定期或软更新(soft update)地跟随在线网络(online network)的参数,这样可以使目标Q值(target Q-value)更加平滑和稳定。

目标演员网络和目标评论家网络与演员网络和评论家网络之间有什么区别?


有哪些其他的深度强化学习算法可以处理连续动作空间问题?

如何选择适合自己的深度强化学习算法?


The End