文章目录
- 环境
- 软件版本
- 服务器系统初始化
- etcd 证书生成
- etcd集群部署
- 负载均衡器部署
- 部署k8s集群
- 部署网络组件
- FAQ
环境
控制平面节点主机的配置最少是2C2G,否则kubeadm init的时候会报错
| 主机名 | IP | 组件 | 系统 |
|---|---|---|---|
| os128 | 192.168.177.128 | etcd、kubeadm、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy、docker、cri-dockerd | CentOS7.9 |
| os129 | 192.168.177.129 | etcd、kubeadm、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy、docker、cri-dockerd | CentOS7.9 |
| os130 | 192.168.177.130 | etcd、kubeadm、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy、docker、cri-dockerd | CentOS7.9 |
| worker131 | 192.168.177.131 | kubeadm、haproxy、keepalived、kubelet、kube-proxy、docker、cri-dockerd | CentOS7.9 |
| worker132 | 192.168.177.132 | kubeadm、haproxy、keepalived、kubelet、kube-proxy、docker、cri-dockerd | CentOS7.9 |
| VIP | 192.168.177.127 |
软件版本
软件版本明细
| 软件 | 版本 | 备注 |
|---|---|---|
| CentOS | 7.9.2009 | |
| kernel | 6.7.1-1.el7.elrepo.x86_64 | |
| kube-apiserver,kube-controller-manager,kube-schedule,kubelet,kube-proxy | v1.27.2 | |
| etcd | v3.5.5 | |
| docker | 25.0.0 | |
| cri-dokcer | 0.3.6 | |
| haproxy | 1.5 | 系统默认yum源安装 |
| keepalived | 1.3.5 | 系统默认yum源安装 |
| calico | v3.25.0 |
服务器系统初始化
所有主机都需要
echo "step1 关闭防火墙"
systemctl disable firewalld
systemctl stop firewalld
echo "success 关闭防火墙"
echo "step2 安装iptables"
yum -y install iptables-services
systemctl start iptables
systemctl enable iptables
iptables -F
service iptables save
iptables -L
echo "success 安装iptables"
echo "step3 关闭selinux"
# 临时禁用selinux
setenforce 0
# 永久关闭 修改/etc/sysconfig/selinux文件设置
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
echo "success 关闭selinux"
echo "step4 禁用交换分区"
swapoff -a
# 永久禁用,打开/etc/fstab注释掉swap那一行。
sed -i 's/.*swap.*/#&/g' /etc/fstab
echo "success 禁用交换分区"
echo "step5 执行配置CentOS阿里云源"
rm -rfv /etc/yum.repos.d/*
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
echo "success 执行配置CentOS阿里云源"
echo "step6 时间同步"
yum install -y chrony
systemctl enable chronyd.service
systemctl restart chronyd.service
systemctl status chronyd.service
echo "step7 更新内核"
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install -y https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
# 设置内核
#更新yum源仓库
yum -y update
#查看可用的系统内核包
yum --disablerepo="*" --enablerepo=elrepo-kernel list available
#安装内核,注意先要查看可用内核,我安装的是5.19版本的内核
#安装kernel-lt版本,ml为最新稳定版本,lt为长期维护版本
yum --enablerepo=elrepo-kernel install kernel-ml -y
# yum --enablerepo=elrepo-kernel install kernel-ml -y
#查看目前可用内核
awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
echo "使用序号为0的内核,序号0是前面查出来的可用内核编号"
grub2-set-default 0
grub2-mkconfig -o /boot/grub2/grub.cfg
echo "success 更新内核"
echo "step8 配置服务器支持开启ipvs"
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
yum install -y ipset ipvsadm
echo "success 配置服务器支持开启ipvs"
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# sysctl params required by setup, params persist across reboots
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# Apply sysctl params without reboot
sudo sysctl --system
echo "step9 重启主机, 使用新升级的内核"
reboot
etcd 证书生成
- 准备签名证书需要的工具 cfssl、cfssljson、cfssl-certinfo
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.1/cfssl_1.6.1_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.1/cfssljson_1.6.1_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.1/cfssl-certinfo_1.6.1_linux_amd64
mv cfssl_1.6.1_linux_amd64 /usr/bin/cfssl
mv cfssljson_1.6.1_linux_amd64 /usr/bin/cfssljson
mv cfssl-certinfo_1.6.1_linux_amd64 /usr/bin/cfssl-certinfo
chmod +x /usr/bin/cfssl*
- 自签etcd 的CA
mkdir -p ~/TLS/etcd
cd ~/TLS/etcd
#自签CA:
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CA": {"expiry": "87600h"},
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
#生成证书:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
会生成ca.pem和ca-key.pem文件
- 使用自签CA签发Etcd HTTPS证书
#创建证书申请文件:
cd ~/TLS/etcd
cat > server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.177.128",
"192.168.177.129",
"192.168.177.130"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
#注:上述文件hosts字段中IP为所有etcd节点的集群内部通信IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
#生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
#会生成server.pem和server-key.pem文件。
etcd集群部署
- Etcd 的概念:
Etcd 是一个分布式键值存储系统,Kubernetes使用Etcd进行数据存储,所以先准备一个Etcd数据库,为解决Etcd单点故障,应采用集群方式部署,这里使用3台组建集群,可容忍1台机器故障,当然,你也可以使用5台组建集群,可容忍2台机器故障。 - 以下在节点os128上操作,为简化操作,待会将节点os128生成的所有文件拷贝到节点os129和节点os130
# 准备etcd的安装包
wget https://github.com/etcd-io/etcd/releases/download/v3.5.5/etcd-v3.5.5-linux-amd64.tar.gz
mkdir -pv /opt/etcd/{bin,cfg,ssl}
tar zxvf etcd-v3.5.5-linux-amd64.tar.gz
mv etcd-v3.5.5-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
- 准备etcd的配置文件
#os128主机 etcd 配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.177.128:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.177.128:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.177.128:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.177.128:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.177.128:2380,etcd-2=https://192.168.177.129:2380,etcd-3=https://192.168.177.130:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
# systemd管理etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
- 安装etcd集群
#拷贝刚才生成的证书
#把刚才生成的证书拷贝到配置文件中的路径:
cp ~/TLS/etcd/ca*pem ~/TLS/etcd/server*pem /opt/etcd/ssl/
# 同步所有主机
scp -r /opt/etcd/ root@192.168.177.129:/opt/
scp -r /opt/etcd/ root@192.168.177.130:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.177.129:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service root@192.168.177.130:/usr/lib/systemd/system/
# os129 主机etcd的配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-2"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.177.129:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.177.129:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.177.129:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.177.129:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.177.128:2380,etcd-2=https://192.168.177.129:2380,etcd-3=https://192.168.177.130:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
# os130主机etcd配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-3"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.177.130:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.177.130:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.177.130:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.177.130:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.177.128:2380,etcd-2=https://192.168.177.129:2380,etcd-3=https://192.168.177.130:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
- 启动etcd并设置开启自启
启动etcd:
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
- 使用etcdctl验证etcd集群
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.177.128:2379,https://192.168.177.129:2379,https://192.168.177.130:2379" endpoint health --write-out=table
负载均衡器部署
worker131、worker132主机上执行
- 安装haproxy、keepalived
yum install haproxy keepalived -y
- haproxy 配置
cat > /etc/haproxy/haproxy.cfg <<EOF
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 6000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
defaults
mode tcp
log global
option tcplog
option dontlognull
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
listen stats
bind 0.0.0.0:9100
mode http
option httplog
stats uri /status
stats refresh 30s
stats realm "Haproxy Manager"
stats auth admin:password
stats hide-version
stats admin if TRUE
#---------------------------------------------------------------------
frontend k8s-master-default-nodepool-apiserver
bind *:6443
mode tcp
default_backend k8s-master-default-nodepool
#---------------------------------------------------------------------
backend k8s-master-default-nodepool
balance roundrobin
mode tcp
server k8s-apiserver-1 192.168.177.128:6443 check weight 1 maxconn 2000 check inter 2000 rise 2 fall 3
server k8s-apiserver-2 192.168.177.129:6443 check weight 1 maxconn 2000 check inter 2000 rise 2 fall 3
server k8s-apiserver-3 192.168.177.130:6443 check weight 1 maxconn 2000 check inter 2000 rise 2 fall 3
EOF
- keepalived配置
-
worker131 主机配置
cat > /etc/keepalived/keepalived.conf << EOF ! Configuration File for keepalived global_defs { router_id LVS_DEVEL script_user root enable_script_security } vrrp_script check_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 5 weight -5 fall 2 rise 1 } vrrp_instance VI_1 { state BACKUP interface ens33 # 非抢占vip模式 nopreempt # 单播 unicast_src_ip 192.168.177.131 unicast_peer { 192.168.177.132 } virtual_router_id 51 #优先级100大于从服务的99 priority 100 advert_int 2 authentication { auth_type PASS auth_pass K8SHA_KA_AUTH } virtual_ipaddress { #配置规划的虚拟ip 192.168.177.127 } #配置对worker131主机haproxy进行监控的脚本 track_script { #指定执行脚本的名称(vrrp_script check_haproxy此处做了配置) check_haproxy } } EOF -
worker132 主机配置
cat > /etc/keepalived/keepalived.conf << EOF ! Configuration File for keepalived global_defs { router_id LVS_DEVEL script_user root enable_script_security } vrrp_script check_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 5 weight -5 fall 2 rise 1 } vrrp_instance VI_1 { state BACKUP interface ens33 nopreempt unicast_src_ip 192.168.177.132 unicast_peer { 192.168.177.131 } virtual_router_id 51 priority 99 advert_int 2 authentication { auth_type PASS auth_pass K8SHA_KA_AUTH } virtual_ipaddress { 192.168.177.127 } #配置对worker132主机haproxy进行监控的脚本 track_script { #指定执行脚本的名称(vrrp_script check_haproxy此处做了配置) check_haproxy } } EOF
-
- 健康检查脚本
cat > /etc/keepalived/check_haproxy.sh <<EOF
#!/bin/bash
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_haproxy.sh
- 设置开启自启并验证高可用VIP
systemctl daemon-reload
systemctl enable --now haproxy
systemctl enable --now keepalived
#查看启动状态
systemctl status keepalived haproxy
#查看虚拟ip是否配置成功了
ip address show
部署k8s集群
- 安装kubernets相关软件
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 安装kubeadm、kubectl、kubelet
version=1.27.2-0
yum install -y kubectl-$version kubeadm-$version kubelet-$version --disableexcludes=kubernetes
# kubelet服务
systemctl enable kubelet
- 安装docker
# 使用docker engine作为CRI, 使用docker进行容器管理
# 安装docker所需的工具
yum install -y yum-utils device-mapper-persistent-data lvm2 bash-completion net-tools gcc
# 配置阿里云的docker源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce
mkdir -p /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"data-root": "/var/lib/docker"
}
EOF
echo "启动docker"
systemctl daemon-reload
systemctl enable docker && systemctl start docker && systemctl status docker
- 安装cri-docker
# yum 从远程地址安装
yum install -y https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.6/cri-dockerd-0.3.6.20231018204925.877dc6a4-0.el7.x86_64.rpm
# 更换container-image的镜像地址
cat > /usr/lib/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
#ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now cri-docker
# 验证cri运行时使用有木有问题
crictl config runtime-endpoint unix:///var/run/cri-dockerd.sock
crictl ps
- 生成集群init配置文件
#查看默认的KubeletConfiguration配置
kubeadm config print init-defaults --component-configs KubeletConfiguration
# 查看默认的KubeProxyConfiguration的配置
kubeadm config print init-defaults --component-configs KubeProxyConfiguration
# 查看默认配置
kubeadm config print init-defaults
cat >config.yml <<EOF
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.177.128
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock #由于是用的docker这里必须修改,否则初始化会报错
imagePullPolicy: IfNotPresent
name: os128 #节点名字 一般和主机名对应
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
controlPlaneEndpoint: "192.168.177.127:6443"
etcd:
external: #这里默认是local,由于我们用的外部etcd,所以需要修改
endpoints:
- https://192.168.177.128:2379
- https://192.168.177.129:2379
- https://192.168.177.130:2379
#搭建etcd集群时生成的ca证书
caFile: /opt/etcd/ssl/ca.pem
#搭建etcd集群时生成的客户端证书
certFile: /opt/etcd/ssl/server.pem
#搭建etcd集群时生成的客户端密钥
keyFile: /opt/etcd/ssl/server-key.pem
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.27.2 #和版本需要一一对应
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 #pod的CIDR地址,不要和别的有交叉
serviceSubnet: 10.96.0.0/12 #service的CIDR地址,不要和别的有交叉
scheduler: {}
EOF
-
初始化第一个控制平面节点
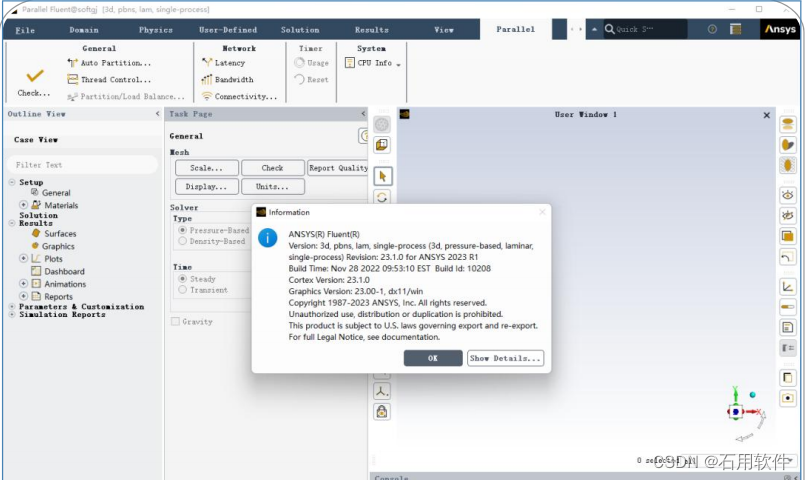
kubeadm init --config config.yml --upload-certs --v=9
初始化成功截图:
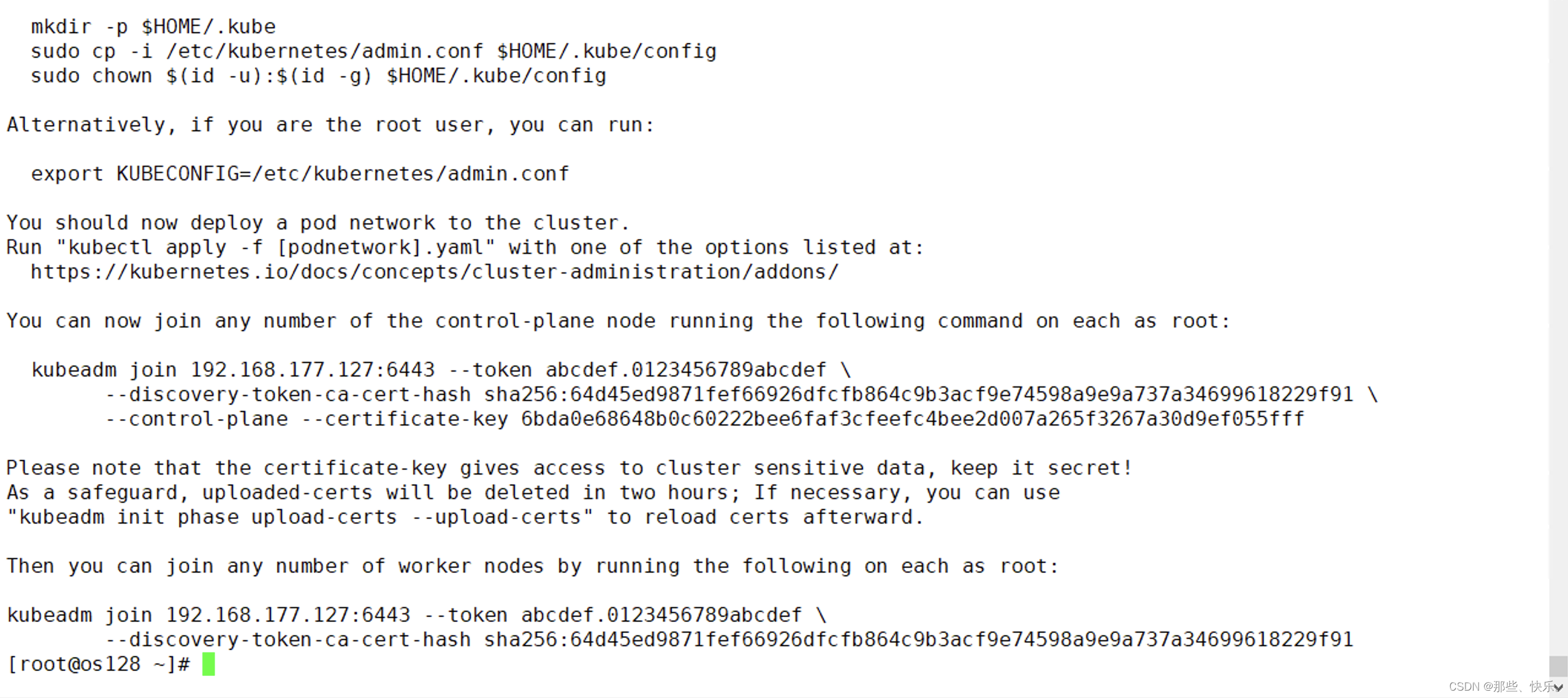
若是启动失败则执行: kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock 可以调整相应的配置再次执行init 操作。 -
其他的控制节点加入
kubeadm join 192.168.177.127:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:64d45ed9871fef66926dfcfb864c9b3acf9e74598a9e9a737a34699618229f91 --control-plane --certificate-key 6bda0e68648b0c60222bee6faf3cfeefc4bee2d007a265f3267a30d9ef055fff --cri-socket unix:///var/run/cri-dockerd.sock
- 其他数据平面节点加入
kubeadm join 192.168.177.127:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:64d45ed9871fef66926dfcfb864c9b3acf9e74598a9e9a737a34699618229f91 --cri-socket unix:///var/run/cri-dockerd.sock
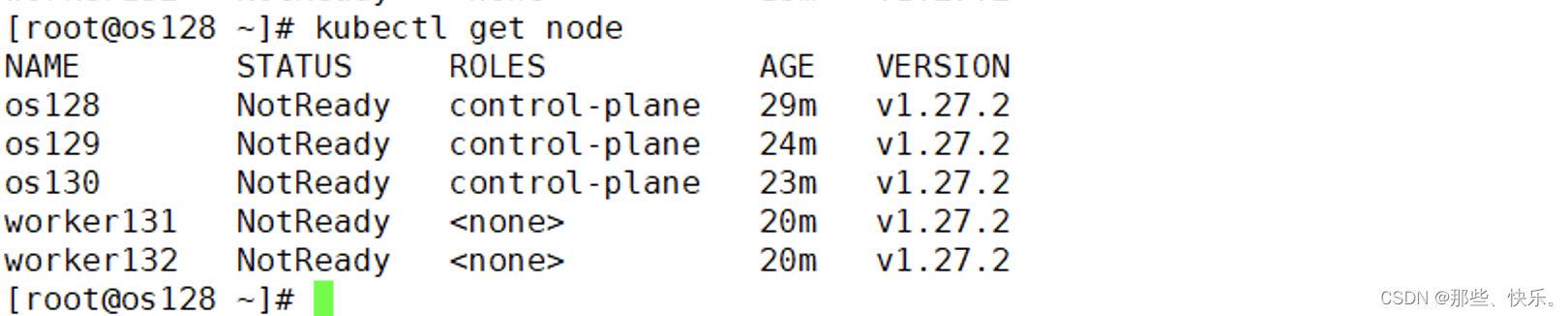
节点加入集群后,默认都是NotReady状态,需要安装网络插件后才会Ready
部署网络组件
- 下载calico
wget https://docs.tigera.io/archive/v3.25/manifests/calico.yaml
- 修改默认网段
# 把calico.yaml里pod所在网段改成 --cluster-cidr=10.244.0.0/16 时选项所指定的网段,
#直接用vim编辑打开此文件查找192,按如下标记进行修改:
# no effect. This should fall within `--cluster-cidr`.
# - name: CALICO_IPV4POOL_CIDR
# value: "192.168.1.0/16"
# Disable file logging so `kubectl logs` works.
- name: CALICO_DISABLE_FILE_LOGGING
value: "true"
把两个#及#后面的空格去掉,并把192.168.1.0/16改成10.244.0.0/16
# no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16" #与kubeadm init所用的配置文件定义的 pod网段保持一致。
# Disable file logging so `kubectl logs` works.
- name: CALICO_DISABLE_FILE_LOGGING
value: "true"
- 部署calico
kubectl apply -f calico.yaml - 验证node节点是否Ready
kubectl get node

FAQ
- worker131 一块网卡上有两个IP,kubelet 使用了一个keepalived 的vip,需要修改成131的IP
 解决方案: 在worker131 主机上/var/lib/kubelet/kubeadm-flags.env 中使用-node-ip 指定要使用的IP,然后重启kubelet即可
解决方案: 在worker131 主机上/var/lib/kubelet/kubeadm-flags.env 中使用-node-ip 指定要使用的IP,然后重启kubelet即可
KUBELET_KUBEADM_ARGS="--node-ip=192.168.177.131 --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9"