0. 思维导图

1. 简述Hive♥♥
我理解的,hive就是一款构建数据仓库的工具,它可以就结构化的数据映射为一张表,并且可以通过SQL语句进行查询分析。本质上是将SQL转换为MapReduce或者spark来进行计算,数据是存储在hdfs上,简单理解来说hive就是MapReduce的一个客户端工具。
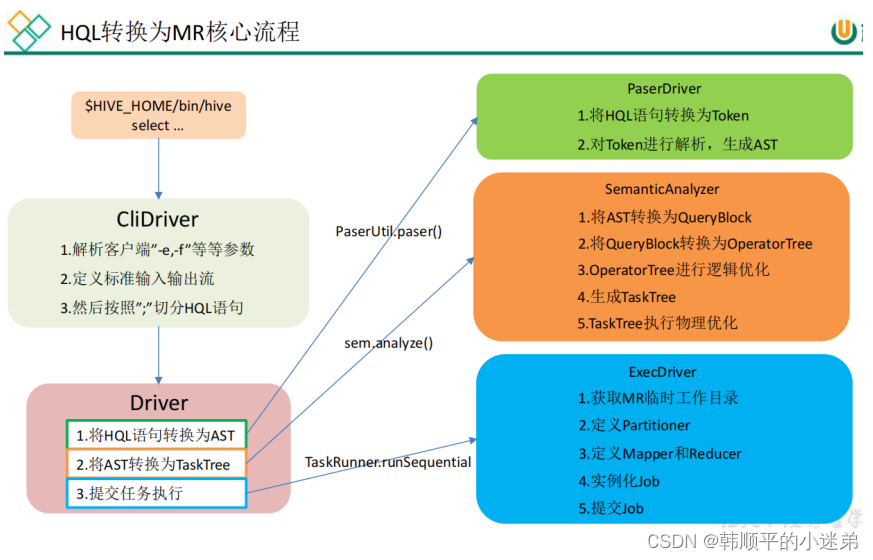
- 补充1:你可以说一下HQL转换为MR的任务流程吗?♥♥♥
- 首先客户端提交HQL以后,hive通过解析器将SQL转换成抽象语法树,然后通过编译器生成逻辑执行计划,再通过优化器进行优化,最后通过执行器转换为可以运行的物理计划,比如MapReduce/spark,然后提交到yarn上执行
- 详细来说:
- 首先客户端提交SQL以后,hive利用Antlr框架对HQL完成词法语法解析,将HQL转换成抽象语法树
- 然后遍历AST,将其转换成queryblock查询块,可以理解为最小的查询执行单元,比如where
- 然后遍历查询块,将其转换为操作树,也就是逻辑执行计划。
- 然后遍历优化器对操作树进行逻辑优化,源码中会遍历所有的优化方式,比如mapjoin,谓词下推等,来达到减少MapReduce Job,减少shuffle数据量的目的。
- 最后通过执行器将逻辑执行计划转换为物理执行计划(MR到这就结束了)(spark还需要使用物理优化器对任务树进行物理优化),提交到hadoop集群运行。
- 补充2:你可以说一下hive的元数据保存再哪里吗?
- 默认是保存java自带的derby数据库,但是这有一个缺点:derby数据库不支持并发,也就是说不能同时两个客户端去操作derby数据库,因此通常情况下,都会配置一个mysql去存放元数据。
2. 简述Hive读写文件机制
-
读取文件:
- 首先调用InputFormat(默认TextInputFormat)对文件进行逻辑切片,返回一条一条的kv键值对,然后调用SerDe(LazySimpleSerDe)的反序列化方法,将一条记录中的value根据分隔符切分为各个对应的字段。
-
写文件:
- 首先调用SerDe(默认LazySimpleSerDe)的序列化方法将对象序列化为字节序列,然后调用OutputFormat将数据写入HDFS文件中。
3. Hive和传统数据库之间的区别♥♥♥
-
我认为主要有散点的区别:
- 数据量,hive支持大规模的数据计算,mysql支持的小一些
- 数据更新快不快,hive官方是不建议对数据进行修改的,因为非常的慢,这一点我也测试过,而mysql经常会进行数据修改,速度也挺快的。
- 查询快不快,hive大多数延迟都比较高,mysql会低一些,当然这也与数据规模有关,数据规模很大的时候,hive不一定比mysql慢。
-
为什么处理小表延迟比较高:
- 因为hive计算是通过MapReduce,而MapReduce是批处理,高延迟的。hive的优势在于处理大数据,对于处理小数据是没有优势的。
4. Hive的内部表和外部表的区别♥♥♥
从建表语句来看,加上了external关键字修饰的就是就是外部表,没加的就是内部表。
-
我认为主要有两点的区别:
- 内部表的数据由hive自身管理,外部表的数据由hdfs管理。
- 删除内部表的时候,元数据和原始数据都会被删除,而删除外部表的时候仅仅会删除元数据,原始数据不会被删除。
-
使用场景:通常都会建外部表,因为一个表通常要多个人使用,以免删除了,还可以找到数据,保证了数据安全。
5. Hive静态分区和动态分区的区别
分区表,也叫分区裁剪,就是分目录,作用就是减少全表扫描。
建表的时候:partitioned by (day string) 加载数据的时候:partition(day=“20210823”)【静态分区】或者partition(day)【动态分区】。
分区字段不能是表中已经存在的字段。
-
静态分区:
- 分区字段的值是在导入数据的时候手动指定的
- 导入数据的方式可以是load data方式,也可以是insert into + select 方法
-
动态分区:
- 分区字段的值是基于查询结果自动推断出来的,也就是最后查询结果的最后一个字段值就对应分区字段的值。
- 导入数据的方式必须是insert into + select 方式
- 想使用动态分区表的时候必须要对hive进行两个配置
- 开启动态分区功能 hive.exec.dynamic.partition=true
- 设置动态分区的模式为非严格模式,也就是说允许所有分区字段都可以使用动态分区hive.exec.dynamic.partition.mode=nonstrict
-
补充题:你知道分桶表吗,谈谈这两个的区别?
-
分桶表和分区表的作用都是用来减少全表扫描的,那么有了分区表,为啥还要有分桶表呢?
-
因为并非所有的数据都可以进行合理的分区,所以有了新的技术分桶表
- 分桶表的分桶规则是,根据分桶字段的hash值,对桶的个数进行取余运算,然后得到该数据应该放到哪个桶里面去
-
说了这么多,他们有什么区别呢?
- 创建语句不同,分区表是partitioned by,分桶表是clustered by
- 分区或分桶字段要求不同,分区字段不能是表中存在的字段,分桶字段一定是表中存在的字段。
- 表现形式不同,分区表其实就是分了目录存放数据,分桶表是将一个文件拆分为很多文件存放。
-
6. 内连接、左外连接、右外连接的区别
- 内连接:返回的是两个表的交集。
- 左外连接:返回左表的所有行,如果左表的某行在右表没有匹配行,则将右表返回空值。
- 右外连接:返回右表的所有行,如果右表的某行在左表没有匹配行,则将左表返回空值。
7. Hive的join底层实现♥♥♥
-
首先hive的join分为common join 和map join,common join 就是join发生在reduce端,map join就是join发生在map端 -
common join:
- 分为三个阶段:map阶段、shuffle阶段、reduce阶段
- map阶段:对来自不同表的数据打标签,然后用连接字段作为key,其余部分和标签作为value,最后进行输出
- shuffle阶段:根据key的值进行hash,这样就可以将key相同的送入一个reduce中
- reduce阶段:对来自不同表的数据进行join操作就可以了
- 分为三个阶段:map阶段、shuffle阶段、reduce阶段
-
map join:
- 首先它是有一个适用前提的,适用于小表和大表的join操作
- 小表多小为小呢?所有就有了一个参数进行配置:hive.mapjoin.smalltable.filesize=25M
- 它的原理是将小表复制多份,让每个map task内存存在一份,比如我们可以存放到HashMap中,然后join的时候,扫描大表,对于大表中的每一条记录key/value,在HashMap中查找是否有相同的key的记录,如果有,则join连接后输出即可,因为这里不涉及reduce操作。
- 0.7版本之后,都会自动转换为map join,如果之前的版本,我们配置一个参数就可以了:hive.auto.convert.join=true。
8. Order By 和 Sort By的区别♥♥
distribute by: 将数据根据by的字段散列到不同的reduce中
cluster by:当distribute by 和sort by 字段相同的时候,等价于cluster by ,但是排序只能是升序。
- order by:全局排序,只有一个reducer,缺点:当数据规模大的时候,就会需要很长的计算时间。
- sort by:分区排序,保证每个reducer内有序,一般结合distribute by来使用
- 使用场景:在生产环境中,order by 用的比较少,容易导致OOM;一般使用distribute by + sort by
9. 行转列和列转行函数♥
JSON解析函数:
- get_json_object:每次只能返回json对象中的一列值 select get_json_object(data,‘$.movie’) as movie from json;
- json_tuple:每次可以返回多列的值 select b.b_movie, b.b_rate,b.b_timeStamp,b.b_uid from json lateral view json_tuple(json.data,‘movie’,‘rate’,‘timeStamp’,‘uid’) b as b_movie,b_rate, b_timeStamp,b_uid;
如果是json数组的话,那么就不能直接使用上述的操作,我们可以先使用regexp_replace方法进行字符串的替换,将它处理成多个json,然后再使用上述的方法就可以了。
URL解析函数:HOST QUERY - parse_url:一对一
- parse_url_tuple:一对多
-
常见的行转列包括:常见的行转列包括:一般的聚合函数,比如max,min,sum:还有汇总函数,比如collect_list,collect_set
-
常见的列转行就是:explode函数(json_tuple函数),只能传入array或者map的数据,将它拆分成多行,一般会和lateral view一起使用。
- select movie, category_name from movie_info lateral view explode(split(category, “,”)) movie_info_tmp as category_name
-
窗口函数:
-
Rand:
- rank(): 排序相同的时候,排名会重复,总数不变
- dense_rank():排序相同的时候,排名会重复,总数减少
- row_number():排序相同的时候,排名不会重复,总数不变
-
lag(col, n, default):返回往上移n行的数据,不存在则返回default
-
lead(col,n, default):返回往下移n行的数据,不存在则返回default
-
first_value(col):取分组内排序后,第一个值
-
last_value(col):取分组内排序后,最后一个值
-
-
over用法:首先通过over来指定窗口的特性,比如可以传入partition by(分组),order by(排序),rows between … and … 指定窗口的范围
- CURRENT ROW:当前行
- n PRECEDING/FOLLOWING: 往前/后n行数据
- UNBODUNDED PRECEDING/FOLLOWING:表示从前面的起点/到后面的终点
- 默认是rows between UNBOUNDED PRECEDING and current row
10. grouping_sets、cube和rollup
他们都是用于group by后面的一个函数,作用是将不同维度的group by进行简化。
- grouping_sets(字段1, 字段2)会对字段1和字段2分别分组聚合,然后UNION ALL
- cube(字段1,字段2)会对字段1和字段2的所有组合2的n次方种分别分组聚合,然后UNION ALL with cube
- rolllup 是cube的一个子集,rollup会以最左侧的维度为主with rollup
11. 自定义过UDF、UDTF函数吗♥♥♥
-
自定义函数
(1)自定义UDF:- 继承UDF
- 重写evaluate方法
(2)自定义UDTF:
- 继承GernericUDTF
- 重写3个方法:initialize,process,close
-
打成jar包,上传到服务器中
-
执行命令:add jar “路径”,目的是将jar添加到hive中
-
注册临时函数:create temporary function 函数名 as “自定义函数全类名”
12. Hive3的新特性有了解吗
- 物化视图:
- 简述:和普通视图的不同点在于普通视图不保存数据,仅仅保存查询语句,而物化视图是把查询的结果存入到了磁盘中,它的作用是通过预计算保存好一些复杂的计算结果,提高查询效率
- 语法: create materialized view … as select …
- 在向动态分区表中导入数据的时候,也可以使用load文件的方式,因为底层会自动转换为inser + select 语句
13. Hive小文件过多怎么办♥
-
首先我说一下为什么会产生小文件呢
- hive中产生小文件就是在向表中导入数据的时候,通常来说,我们在生产环境下,一般会使用insert+select的方式导入数据,这样会启动MR任务,那么reduce有多少个就会输出多少个文件,也就是说insert每执行一次啊,就至少生产一个文件,有些场景下,数据同步可能每10分钟就会执行一次,这样就会产生大量的小文件。
-
然后我再说一下问什么要解决小文件呢?不解决不行吗?
- 首先对于hdfs来说,不适合存储大量的小文件,文件多了,namenode需要记录元数据就非常大,就会占用大量的内存,影响hdfs存储性能
- 对于hive来说,每个文件会启动一个maptask来处理,这样也会浪费计算资源。
-
最后说一下怎么解决:
- 使用hive自带的concatenate命令合并小文件,但是它只支持recfile和orc存储格式
- MR过程中合并小文件
- map前:
- 设置inputformat为combinehiveinputformat:在map的时候会把多个文件作为一个切片输入
- map后,reduce前:
- map输出的时候合并小文件 hive.merge.mapfiles
- reduce 后
- reduce输出的时候合并小文件hive.merge.mapredfiles
- 直接设置少一点的reduce数量mapreduce.job.reduces
- 使用hadoop的archive归档方式
14. Hive优化♥♥♥
-
建表优化:
-
分区表:减少全表扫描,通常查询的时候先基于分区过滤,再查询
-
分桶表:按照join字段进行分桶,join的时候就不会全局join,而是桶与桶之间进行join
-
合适的文件格式:公司中默认采用的是ORC的存储格式,这样可以降低存储空间,内部有两个索引(行组索引和布隆过滤器索引)的东西,可以加快查询速度
- 我直到的hive的文件格式有textFile,sequenceFile,ORC,Parque;其中textFile为hive的默认存储格式,它和sequenceFile一样都是基于行存储的,ORC,Parquet是基于列存储的。sequenceFile,ORC,Parque文件都是以二进制的方式存储的。
-
合适的压缩格式:减少了IO读写和网络传输的数据量,比如常用的LZO(可切片)和snappy
-
-
语法优化:
-
单表查询优化:
- 列裁剪和分区裁剪:如果select * 或者不指定分区,全列扫描和全表扫描效率都很低(公司规定了必须指定分区,select * 没有明确规定)
- group by优化:
- 开启map端聚合
- 开启负载均衡:这样生成的查询计划会有两个MR job,一个是局部聚合(加随机数),另一个是全局聚合(删随机数)
- SQL写成多重模式:有多条SQL重复扫描一张表,那么我们可以写成from 表 select … select
-
多表优化查询:
- CBO优化:选择代价最小的执行计划:自动优化HQL中多个Join的顺序,并选择合适的Join算法
- set hive.cbo.enable=true(默认开启)
- 谓词下推:将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
- hive.optimize.ppd=true(默认开启)
- MapJoin:将join双方比较小的表直接分发到各个Map进程的内存中,在Map进程中进行join操作,这样就不用进行Reduce,从而提高了速度
- set hive.auto.convert.join=true(默认开启)
- set hive.mapjoin.smalltable.filesize=25000000(默认25M以下是小表)
- SMB Join:分桶join,大表转换为很多小表,然后分别进行join,最后union到一起
- CBO优化:选择代价最小的执行计划:自动优化HQL中多个Join的顺序,并选择合适的Join算法
-
-
job优化:
- map优化
- 复杂文件增加map数
- 小文件合并
- map端聚合
- 推测执行
- reduce优化
- 合理设置reduce:
- 为什么不是reduce的数量越多越好?
- 过多的启动和初始化reduce也会消耗时间和资源
- 另外,有多少个reduce,就会有多少个输出文件,如果生成的很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
- 为什么不是reduce的数量越多越好?
- 推测执行
- 合理设置reduce:
- 任务整体优化:
- fetch抓取:Hive中对某些情况的查询可以不必使用MapReduce计算【全局查找、字段查找、limit查找】hive.fetch.task.conversion=more
- 小数据集启用本地模式hive.exec.mode.local.auto=true
- 多个阶段并行执行 set hive.exec.parallel=true
- JVM重用:针对小文件过多的时候使用
- map优化
15. 常用函数的补充
- NVL(value, default):如果value为null,就返回default,否则返回value
- IF(expr, value1, value2):如果expr为true,返回value1,否则返回value2
- concat_WS(seperator, str1, str2, …):参数可以是字符串,也可以是数组
- substring(value, start, len):字符串索引是从1开始,我们要截取value中第start字符开始len长度的字符串
- 日期函数:

- 行列转换: