文章目录
- 前言
- 1、不要相信什么验证码的库
- 2、以古诗文网为例,获取验证码
- 1)code_result.py
- 2)gsw.py
前言
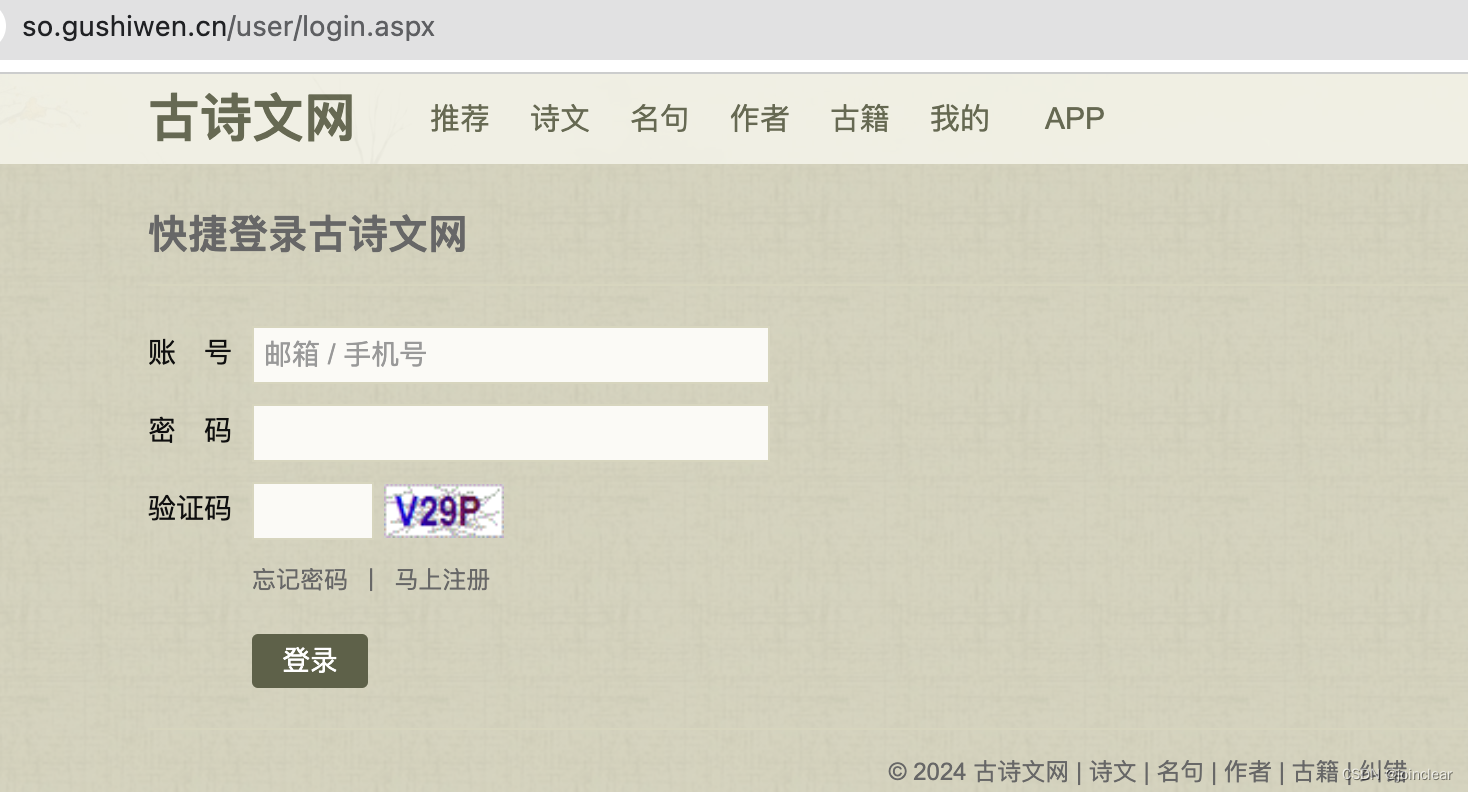
提示:以古诗文网为例,获取验证码:
登录:https://so.gushiwen.cn/user/login.aspx
1、不要相信什么验证码的库
首先:真的不要浪费时间,使用什么pytesseract库,什么ddddocr库。这些只能搞搞简单的,复杂点儿的都是搞不定。
比如,这样的,搞不定的:

直接使用打码平台吧,我这里使用的是:云码。
2、以古诗文网为例,获取验证码
1)code_result.py
code_result.py (云码的官方代码)代码如下:
import json
import requests
import base64
class YdmVerify(object):
_custom_url = "http://api.jfbym.com/api/YmServer/customApi"
_token = "" #云码的token
_headers = {
'Content-Type': 'application/json'
}
def common_verify(self, image, verify_type="10110"):
payload = {
"image": base64.b64encode(image).decode(),
"token": self._token,
"type": verify_type
}
print(payload)
resp = requests.post(self._custom_url, headers=self._headers, data=json.dumps(payload))
print(resp.text)
return resp.json()['data']['data']
2)gsw.py
获取验证码代码如下:
import requests
from lxml import etree
from code_result import YdmVerify
url = "https://so.gushiwen.cn/user/login.aspx"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers).text
tree = etree.HTML(response)
img_code = "https://so.gushiwen.cn"+tree.xpath('//*[@id="imgCode"]/@src')[0]
# 图片
image_byte = requests.get(url=img_code,headers=headers).content
with open('/Users/test/Downloads/python/code.png','wb') as fp:
fp.write(image_byte)
# 云码打码
Y = YdmVerify()
with open("/Users/test/Downloads/python/code.png", 'rb') as f:
img_content = f.read()
resp = Y.common_verify(img_content)
print(resp)
结果如下:
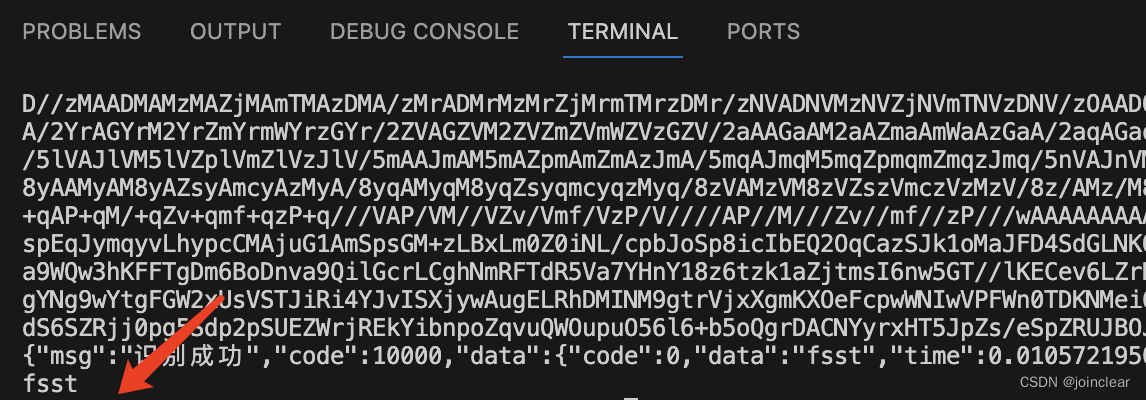
对应云码平台记录:
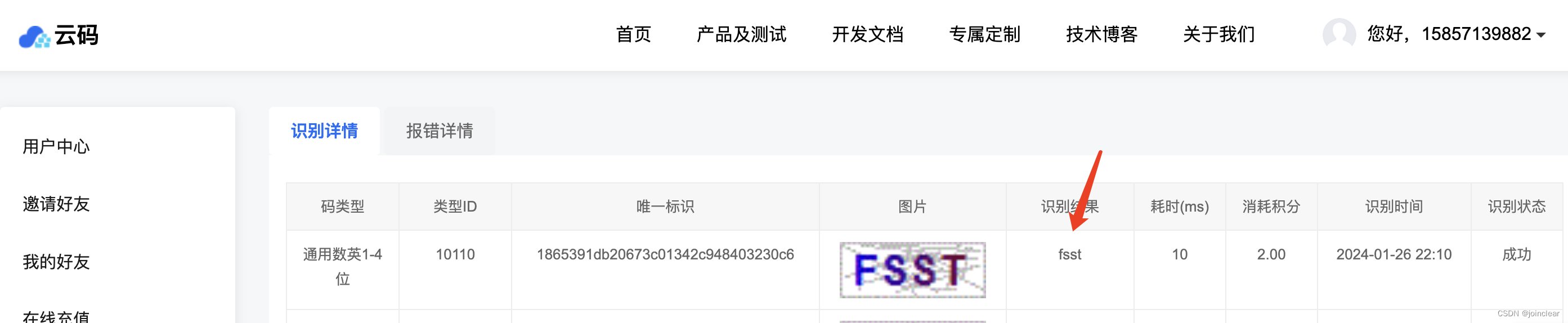
这是通用数字1-4位,其它类型和代码参考云码官方资料吧:
代码:https://zhuce.jfbym.com/test/100.html
# 数英汉字类型
# 通用数英1-4位 10110
# 通用数英5-8位 10111
# 通用数英9~11位 10112
# 通用数英12位及以上 10113
# 通用数英1~6位plus 10103
# 定制-数英5位~qcs 9001
# 定制-纯数字4位 193
# 中文类型
# 通用中文字符1~2位 10114
# 通用中文字符 3~5位 10115
# 通用中文字符6~8位 10116
# 通用中文字符9位及以上 10117
# 定制-XX西游苦行中文字符 10107
# 计算类型
# 通用数字计算题 50100
# 通用中文计算题 50101
# 定制-计算题 cni 452