贝叶斯深度学习:增量式少样本学习跨域适应 + 贝叶斯多目标函数 + 跨模态学习 fundus + OCT,做视网膜病变
- 核心思想
- 设计网络:寻找分类模型、损失函数
- 实验结果
- 混淆矩阵与注意力图评估
- 总结
核心思想
论文:https://arxiv.org/pdf/2110.09319.pdf
代码:https://github.com/taimurhassan/continual_learning/blob/17d286a40fd5f17c9cdc8a3eac2129857a5397ac/README.md
怎样在只有少量训练样本的情况下,逐步准确识别出视网膜病变(如糖尿病性视网膜病变、黄斑变性),同时还要保证已经学过的知识不会被忘记 ?
论文提出了一种新型的增量式跨域适应方法。
这个问题可以分为以下几个子问题和对应的解决方案:
-
首先,子问题就是在只有少量训练数据的情况下怎么识别视网膜病变。
解法就是增量式跨域适应。
这个方法让深度学习模型能够利用少量的训练样本逐步学习光学相干断层扫描(OCT)和眼底图像中的异常视网膜病理。
这在医学影像领域特别重要,因为这个领域很难获得大量的标注数据。
-
接着,第二个子问题是如何在学习新知识的同时,还能保留以前学过的知识。
这个问题的解决方案是使用一种特殊的贝叶斯多目标函数。
这个方法不仅能让分类网络在增量训练过程中保持其先前的知识,还能帮助网络理解之前学过的病理和新加的疾病类别之间的结构和语义关系,这样在实际应用时就能更有效地识别它们。
这一点对医学诊断来说非常关键。
-
最后一个子问题是如何处理不同成像技术(比如OCT和眼底摄影)之间的差异。
解决这个问题的办法是跨模态学习。
这样可以让模型处理并识别不同成像技术中的疾病特征,对于提高视网膜病变筛查的准确性非常重要。
这篇论文的解决方案就是结合增量式跨域适应、贝叶斯多目标函数和跨模态学习,这样不仅能提升模型在少量数据和多模态数据下的学习和适应能力,还能保持对以前学习知识的记忆,从而大大提高了视网膜病变筛查的准确性和效率。
设计网络:寻找分类模型、损失函数
-
首先,研究团队面临的一个挑战是选出最适合用于跨域视网膜病变筛查的分类网络。
为此,他们比较了好几种模型,包括MobileNet、ResNet-50、ResNet-101和VGG-16。
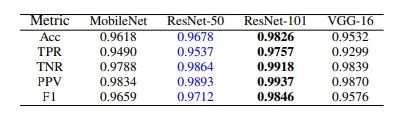
最后,他们选定了ResNet-101,因为它的残差特征融合机制能更好地保留图像的细节特征。
-
接着,为了证明他们提出的框架的有效性,研究人员将这个框架与其他现有的视网膜诊断系统进行了比较。
他们发现,尽管采用了增量式学习的方法,但他们的框架在多个数据集上都超越了其他方法,这说明了他们的方法不仅新颖,而且非常有效。
·
-
最后,他们还探索了如何在不同成像技术(比如OCT和眼底图像)之间实现有效的视网膜病变筛查。
在一系列的实验中,他们发现使用 Lcl 损失函数 的 ResNet-101 能够有效地同时学习这两种不同模态的视网膜分类任务,并且在防止灾难性遗忘方面表现得非常好。
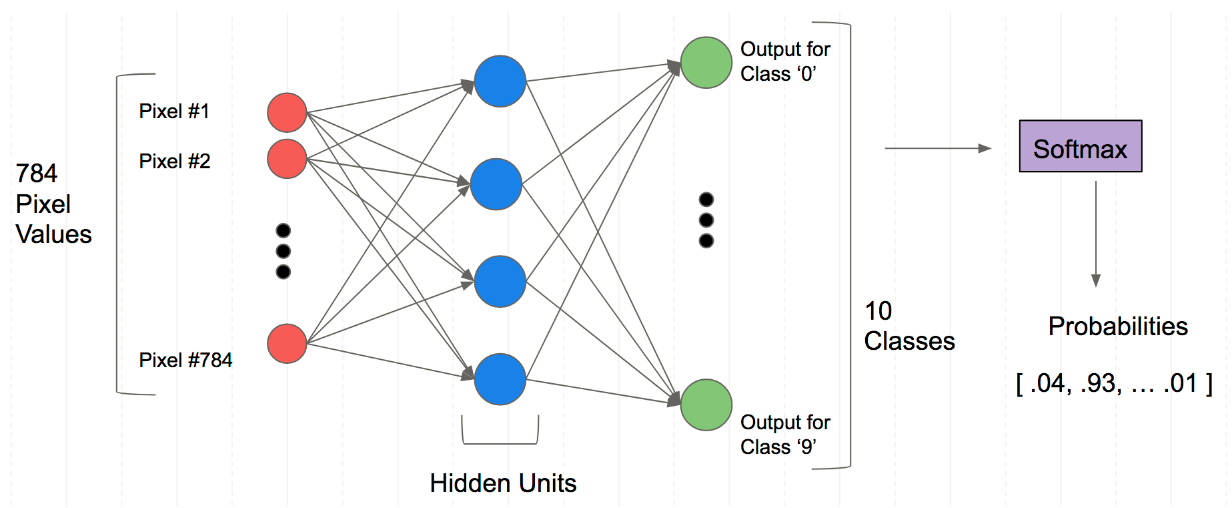
假设我们有一个用于视网膜病变筛查的深度学习模型,我们想要让它能够识别和区分多种不同的视网膜病变,比如糖尿病性视网膜病变、黄斑变性等,而且我们想要这个模型能够处理两种不同的图像数据:OCT和眼底图像。

跨域视网膜病变筛查的增量式训练框架,整个流程分为三个主要部分:
(A) 训练阶段 I:
-
这个阶段分类网络如何在第一个目标域(OCT)上逐步接受训练,以识别 k+1 种视网膜病变。
-
网络通过批次1到批次k的数据,使用 Lcl损失函数 进行训练,其中Lce代表分类交叉熵损失,用于训练模型初始学习;Lcl代表持续学习损失,用于后续的增量学习。
我们从一些OCT扫描的数据集开始,这些数据已经被标记为含有或不含有特定类型的视网膜病变。
我们首先使用一批数据来训练我们的模型(例如,使用了300个ci-DME样本和200个正常样本)。
我们使用分类交叉熵损失(Lce)来进行这一阶段的训练。
随着时间的推移,我们增量地添加新批次的数据,每个新批次都可能包含之前没见过的病变类型(例如,新添加了Dry AMD样本)。
在这些新的迭代中,我们使用持续学习损失(Lcl)来保持模型在学习新知识的同时,不会忘记旧的知识。
(B) 训练阶段 II:
-
在这个阶段,分类网络在第二个目标域(眼底图像)上逐步适应,以识别 m+2 种视网膜病变。
-
这意味着网络不仅能识别OCT图像中的病变,也能识别眼底图像中的病变。
现在我们开始将模型适应第二种类型的图像数据:眼底图像。
这个过程同样是增量式的。我们先用少量的眼底图像(比如,40个CSME样本和20个正常样本)来进行初步训练。
接着,我们继续增量地添加新的眼底图像样本,每一批都包含新类型的病变,同时使用 Lcl损失函数 来继续训练模型。
© 跨域视网膜病变筛查(推理阶段):
-
最终,当k=6,m=11时,提出的框架通过增量式训练能够同时识别 OCT 和眼底图像中的 13 种视网膜病变,不受扫描器规格的影响。
-
在这个阶段,训练好的模型被用来对输入的测试扫描进行分类。
经过上述两个阶段的训练后,我们的模型现在已经准备好进行实际的病变筛查了。
当有新的OCT或眼底图像输入时,我们的模型可以识别出这是13种已知类型中的哪一种视网膜病变,无论这些图像来自哪种扫描器。
如果我们的模型接受到一个新的OCT扫描,并且它判断这个扫描显示了患有ci-DME,那么它就会将这个案例归类为ci-DME。
图中的颜色代码对应了不同的病变类别,显示了模型是如何被训练来识别这些病变的。
这张图展示的是,一个深度学习模型如何分两个阶段通过增量式训练来识别多种视网膜病变,并在最后应用于实际的病变筛查任务中。
实验结果
任务:快速准确地从成百上千的患者眼底照片中筛查出不同类型的视网膜病变,且病变类型繁多,且每种扫描设备产生的图像都有微妙的差异。
模型在实际的临床环境进行视网膜病变筛查:
-
首先,研究人员面对的问题是怎样在真实的临床环境里实时筛查视网膜病变。
为了解决这个问题,他们进行了一系列的临床实验。
这些实验特别重要,因为它们证明了这个框架不只是理论上可行,实际应用起来也很有效果。
虽然这些实验的细节因为篇幅限制放在了补充材料里,但这部分是验证框架实用性的关键。
-
接着,他们还研究了 Lcl 损失函数里一个特别的部分——互相蒸馏损失(Lmd)对分类性能的影响。
他们发现,包含了 Lmd 的 Lcl 损失函数在学习新的分类任务的同时,还能很好地保持对已知任务的高性能。
原因在于 Lmd 通过贝叶斯推理增强了网络学习新类别的能力。
比如一个患者的眼底图像显示了一些典型的DME症状,但同时又有一些不那么明显的AMD迹象,Lmd 能帮助模型在学习识别新的 AMD 病例的同时,不会忘记已经学到的关于 DME 的知识。
-
最后一个问题是如何处理类别不平衡的情况。
在实际应用中,会遇到大量的正常眼底图像和一小部分显示出病变的图像。
如果没有特别的处理,模型可能会倾向于将所有图像都分类为正常,从而忽视那些较少见的病变类别。
他们发现,尽管 Lcl 损失函数 在防止遗忘已学知识方面做得很好,但在类别不平衡的情况下表现出了一些脆弱性。
为了克服这个问题,研究人员提出了一些方法,比如引入最大边界约束、焦点损失函数和高斯亲和优化,来提高对不平衡类别的预测能力。
混淆矩阵与注意力图评估
如何评估模型在各类别上的具体表现?
- 解决方案:使用混淆矩阵和注意力图进行细致的性能分析。
- 原因:混淆矩阵能够详细展示模型在每个类别上的准确性和误分类情况,注意力图可以显示模型在做出判断时关注的区域,这有助于理解模型的决策过程。
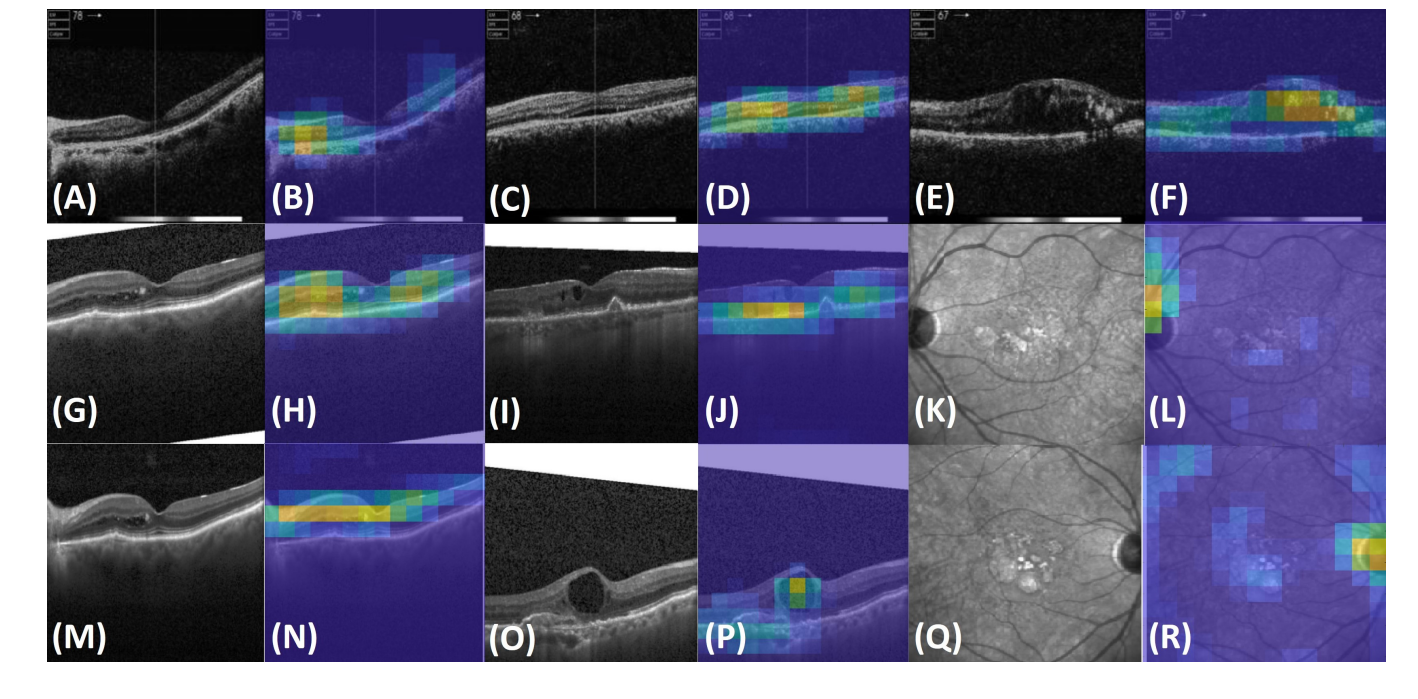
注意力图通过颜色的强度来表示模型关注的程度,颜色越亮表示模型越关注那一部分区域。
这些影像可能包括 OCT图像和眼底图像,其中 OCT 图像通常用于检测视网膜厚度和结构的变化,眼底图像用于观察视网膜表面的特征。
注意力集中在某些区域,是由于这些区域在视网膜病变的上下文中具有重要的诊断特征。
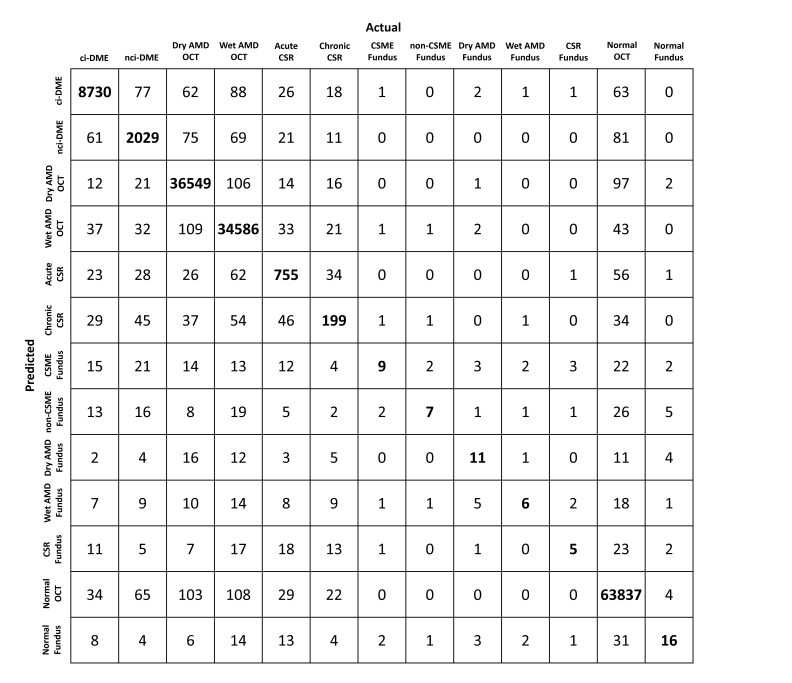
这个混淆矩阵提供了使用 Lcl损失函数 训练的 增量式ResNet-101模型,在跨域视网膜病变筛查任务中的分类效果的详细视图。
从矩阵可以看出:
- 模型在某些类别上具有很高的准确性,例如,ci-DME 类别中有8730个样本被正确分类。
- 然而,模型在区分某些相似的类别时存在混淆,如将 ci-DME 误分类为 nci-DME 或 Dry AMD OCT。
- 大部分的预测都集中在混淆矩阵的对角线上,表明多数类别都被正确分类。
总结
问题与解法组成:
-
子问题1:如何让模型能够在识别新的视网膜病变类型时不忘记已学知识?
- 解决方案:采用增量学习策略,使用Lcl损失函数进行训练。
- 原因:增量学习能够通过连续训练来逐步扩展模型的识别能力,而 Lcl损失函数 专门设计来平衡新旧知识,防止过去学习的知识被新信息覆盖,即解决了“灾难性遗忘”问题。
-
子问题2:如何处理从 OCT 图像到眼底图像的跨域适应?
- 解决方案:使用同一模型进行跨域训练,逐步引入新域的数据。
- 原因:跨域适应需要模型在不同类型的数据上都具有良好的性能,逐步引入新域的数据允许模型调整其参数以适应新环境的特征。
-
子问题3:如何提高模型对不平衡数据的分类性能?
- 解决方案:引入额外的技术,如最大边界约束、焦点损失函数和高斯亲和优化。
- 原因:类别不平衡会导致模型偏向于多数类,这些技术可以帮助模型更关注少数类,改善对不平衡数据的处理。
-
子问题4:知识保留,使其能够在每一步学习中同时保留以前学到的知识,并且有效地学习新的数据和类别。神经网络在学习新任务时往往会遗忘之前学习的任务的情况,当网络参数为了适应新的数据而调整时,之前针对旧数据设置的权重可能会被覆盖,导致网络在旧任务上的性能下降。
- 解决方案:贝叶斯多目标函数
- 原因:通过量化不确定性并通过后验概率整合新信息,使模型能够在添加新类别数据时,维持对旧类别的识别能力。
- 原因:贝叶斯方法还帮助模型理解新旧类别之间的结构和语义关系,这对于跨模态学习尤为重要。在眼底图像和OCT图像之间可能存在一些共通的病变特征,贝叶斯目标函数使模型能够理解这些共通性,即使这些特征在不同的模态中以不同的形式呈现。
- 原因:贝叶斯方法适合少样本学习情境,因为它可以利用先验知识来指导模型的学习过程,这样即使在只有有限数据的情况下,模型也能做出合理的推断。
贝叶斯增量式跨域适应 = 增量学习与Lcl损失函数 + 跨域适应性训练 + 处理类别不平衡 + 贝叶斯实现知识保留和推断