这里说一下ROI Pool和ROI Align的区别:
一、ROI Pool层
参考Faster RCNN中的ROI Pool层,功能是将不同size的ROI区域映射到固定大小的feature map上。
它的缺点:由于两次量化带来的误差;
- 将候选框边界量化为整数点坐标值
- 将量化后的边界区域平均分割成 k x k 个单元(bin),对每一个单元的边界进行量化
下面我们用直观的例子具体分析一下上述区域不匹配问题。
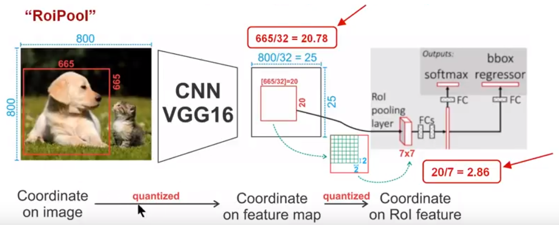
如下图所示,这是一个Faster R-CNN检测框架。输入一张 800 × 800 800\times 800 800×800的图片,图片上有一个 665 × 665 665\times 665 665×665的包围框(框着一只狗)。
图片经过主干网络提取特征后,特征图缩放步长(stride)为32。
因此,图像和包围框的边长都是输入时的1/32。
800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化 7 × 7 7\times 7 7×7的大小,因此将上述包围框平均分割成 7 × 7 7\times 7 7×7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。
经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
二、ROI Align层
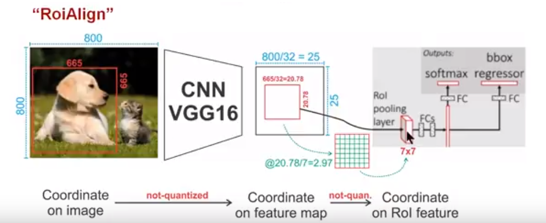
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法。
ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。
值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程:
- 遍历每一个候选区域,保持浮点数边界不做量化
- 将候选区域分割成k x k个单元,每个单元的边界也不做量化
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。
比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。
显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。
在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了mis-alignment的问题。
值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受mis-alignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
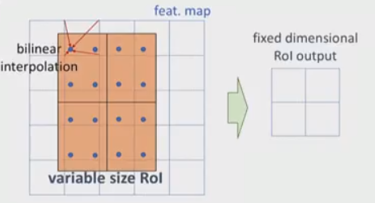
ROI Align层要将feature map固定为 2 × 2 2\times 2 2×2大小,那些蓝色的点即为采样点,然后每个bin中有4个采样点,则这四个采样点经过MAX得到ROI output;
它的优点:通过双线性插值避免了量化操作,保存了原始ROI的空间分布,有效避免了误差的产生。
三、ROI Align的原理
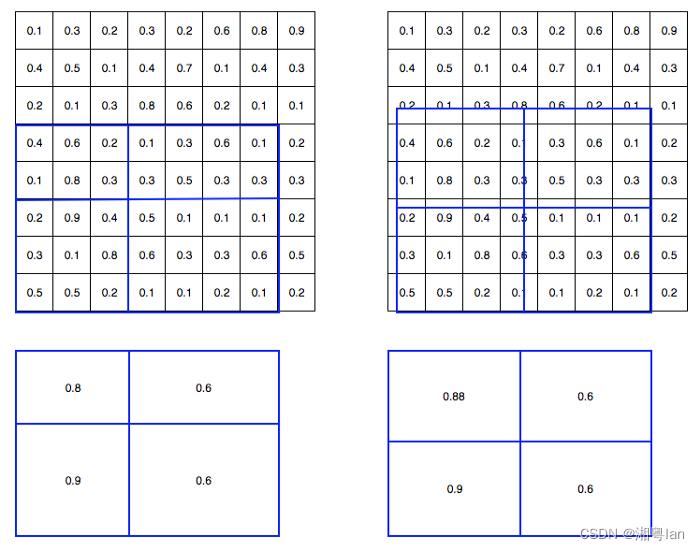
Mask R-CNN 的另一个主要贡献是对 ROI pooling的改进。
在 ROI 中,卷积图被数字化(上图左上图):目标特征图的单元边界被迫与输入特征图的边界重新对齐。因此,每个目标单元格的大小可能不同(左下图),而这使得物体的预测边框与真实边框存在一个差距,这个差距在大物体检测时,误差可以接受,但在小物体检测时,误差就显得尤为难以接受。
Mask R-CNN 使用ROI Align,它不会取整单元格的边界(右上)并使每个目标单元具有相同的大小(右下)。它还应用插值来更好地计算单元格内的特征图值。例如,通过应用插值,现在左上角的最大特征值从 0.8 变为 0.88。
四、Roi Pooling vs Roi Align
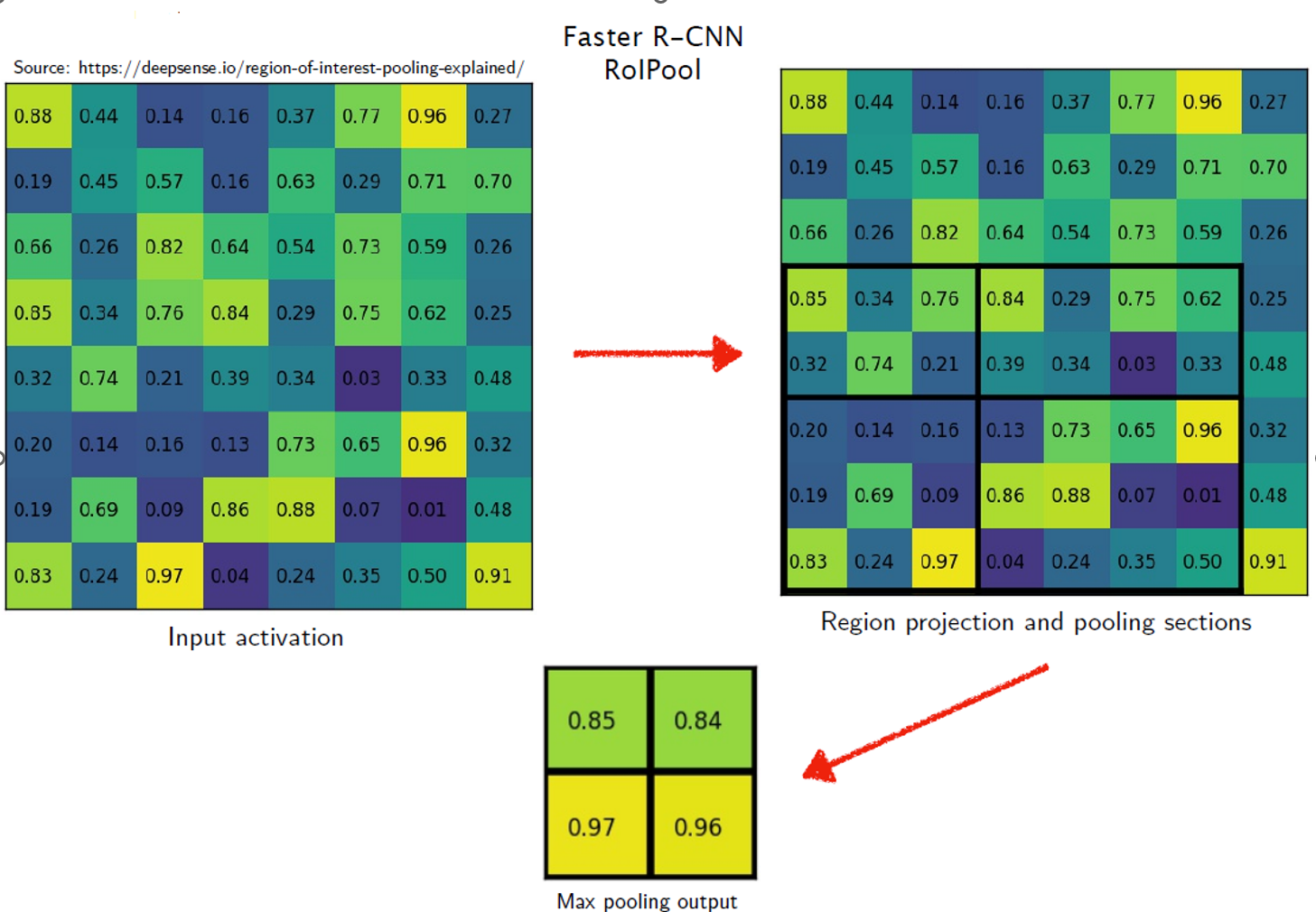
- 首先,我们经过一些卷积层得到了如图左侧的输入特征图。
- 然后根据region proposal(区域提议),我们使用一个 7×5 的区域作为 RoI Pooling 的输入,以输出 2×2 的特征图
- 每个黑色矩形都经过四舍五入以具有整数长度以供以后进行池化
- 对于输出特征图的每个值,它们只选取每个黑色矩形的最大值,称为最大池化(Max Pooling)
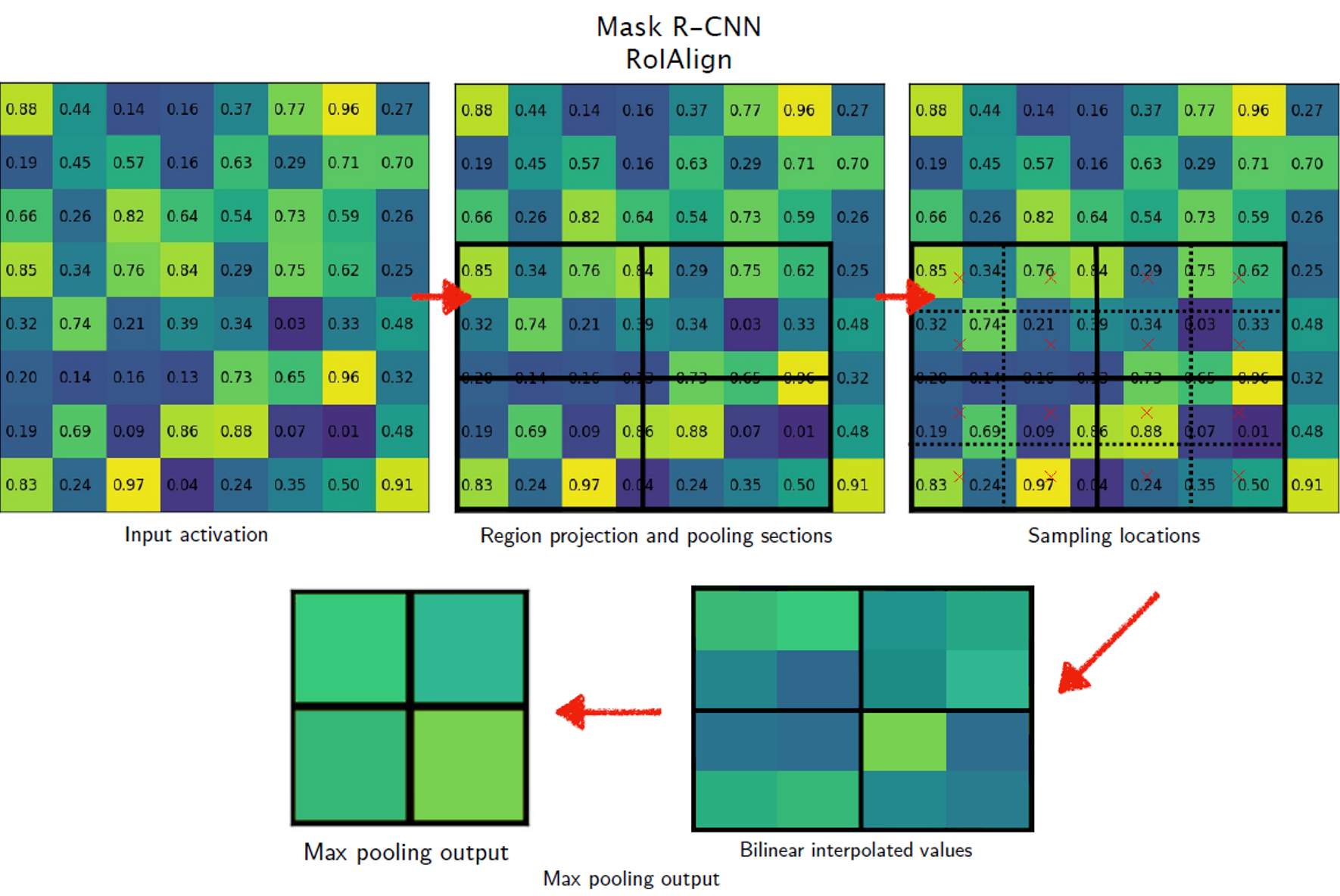
- 不是将黑色矩形四舍五入以获得整数长度,而是使用相同大小的黑色矩形。
- 基于特征图值重叠的区域,取各单元格中心位置,使用双线性插值得到中间池化特征图
- 然后在这个中间池化特征图上执行最大池化(Max pooling)





![[MySQL]-双主+keepalived实现高可用](https://img-blog.csdnimg.cn/3dc2c82c1d6445a9a05c05e75d98d5b0.png#pic_center)




![数据报告:[数字健康]如何引发美国医疗深度变革](https://img-blog.csdnimg.cn/img_convert/9a92876d947433892d58bdab251a7752.jpeg)