朴素贝叶斯:用概率去预测
1、朴素贝叶斯介绍

朴素:指的是,特征之间相互独立
拉普拉斯平滑系数,每个种类都加k,避免条件概率出现0
区分情书与作业的例子,用关键词:
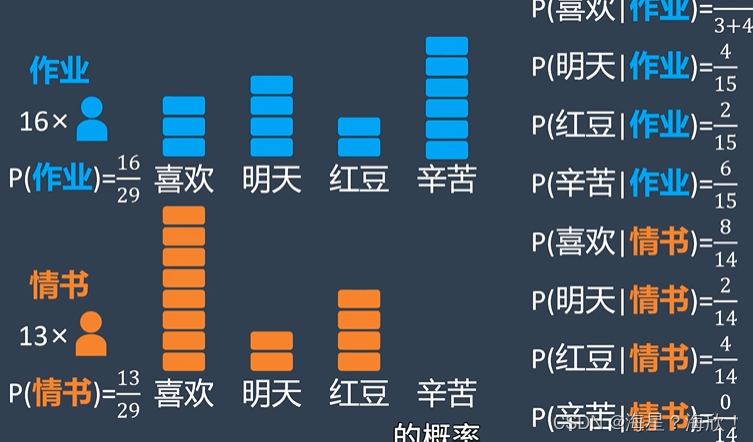

是情书的概率更高,所以估计为情书
2、案例:商品评论情感分析

import pandas as pd
import numpy as np
import jieba
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayee import MultinomialNB
#获取数据
data = pd.read_csv("./书籍评价.csv",encoding='gbk')
data
#数据基本处理
#2.1取出内容列,用于后面分析
content = data['内容']
content
#把评价列中好评差评转成数字
data.loc[:,'评价']
data.loc[data.loc[:,'评价']=='好评','评论编号']=1
data.loc[data.loc[:,'评价']=='差评','评论编号']=0
#2.3选择停用词
stopwords=[]
with open('./stopwords.txt','r',encoding='utf-8') as f:
lines = f.readlines()
#print(lines)
for tmp in lines:
line = tmp.strip()
stopwords.append(line)
stopwords = list(set(stopwords))
stopwords
#2.4 把‘内容’处理,转化成标准格式
comment_list = []
for tmp in content:
print(tmp)
seg_list = jieba.cut(tmp,cut_all=False)
seg_str = ','.join(seg_list)
comment_list.append(seg_str)
comment_list
#统计词个数
con = CountVetorizer(stop_words = stopwords)
X = con,fit_transform(comment_list)
X.toarray()
con.get_feature_names()
#2.5分割训练集和测试集
x_train = x.toarray()[:10,:]
y_train = data['评价'][:10]
x_train
y_train
x_test = x.toarray()[10:,:]
y_test = data['评价'][10:]
#3 模型训练
mb = MultinomialNB(alpha=1)
mb.fit(x_train,y_train)
y_pre = mb.predict(x_test)
print('预测值:',y_pre)
print('真实值:',y_pre)
#4.模型评估
mb.score(x_test,y_test)
3、朴素贝叶斯总结
3.1朴素贝叶斯优缺点
优:有稳定的分类效率;对缺失数据不敏感;常用于文本分类
缺:某些时候会由于假设的先验模型的原因导致预测效果不佳

朴素贝叶斯:基于贝叶斯定理和特征条件独立假设的分类方法
朴素贝叶斯朴素在哪里?
当Y确定时,X的各个特征分量取值之间相互独立
为什么引入条件独立假设?
为了避免贝叶斯定理求解时面临的组合爆炸、样本稀疏问题
在估计条件概率时出现概率为0的情况怎么办?
引入拉普拉斯平滑系数
为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍然能取得较好效果?
在使用分类器之前,进行了特征选择,这一过程排除特征之间的共线性,选择相对较为独立的特征
朴素贝叶斯与逻辑回归的区别?
朴素贝叶斯是生成模型,而LR是判别模型
朴素贝叶斯是基于很强的条件独立假设,而LR对此没有要求
朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集
生成模型VS判别模型?
判别式模型:要确定一个羊是山羊还是绵羊,从历史数据中学习到模型,通过提取这只羊的特征来预测这只羊是山羊的概率,以及是绵羊的概率。(一个模型)
生成式模型:根据山羊的特征学习出一个山羊模型,根据绵羊模型学习出一个绵羊模型。然后从这只羊中提取特征,放在山羊模型中看概率是多少,放在绵羊中看概率是多少,哪个大取哪个。(两个模型)

![数据报告:[数字健康]如何引发美国医疗深度变革](https://img-blog.csdnimg.cn/img_convert/9a92876d947433892d58bdab251a7752.jpeg)