目录
1:SQL优化
1.1:limit优化
1.2:count优化
1.2.1:概述
1.2.2:count用法
1.3:update优化
1:SQL优化
1.1:limit优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。 我们一起来看看执行limit分页查询耗时对比:
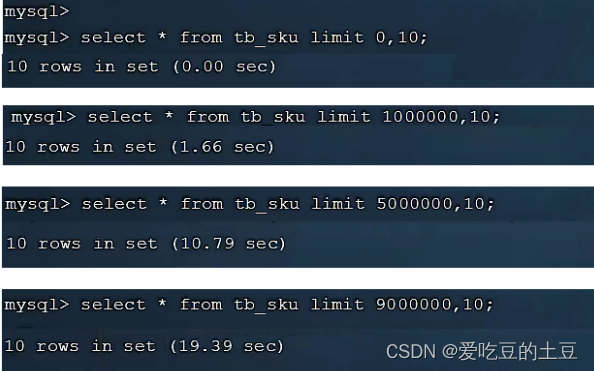
通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。
因为,当在进行分页查询时,如果执行 limit 2000000,10 ,此时需要MySQL排序前2000010 记 录,仅仅返回 2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查 询形式进行优化。
explain select * from tb_sku t , (select id from tb_sku order by id
limit 2000000,10) a where t.id = a.id;1.2:count优化
1.2.1:概述
select count(*) from tb_user ;在之前的测试中,我们发现,如果数据量很大,在执行count操作时,是非常耗时的。
1:MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很高; 但是如果是带条件的count,MyISAM也慢。
2:InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出 来,然后累积计数。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:自己计数(可以借助于redis这样的数 据库进行,但是如果是带条件的count又比较麻烦了)。
1.2.2:count用法
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
count(主 键):InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。 服务层拿到主键后,直接按行进行累加(主键不可能为null)
count(字 段):
没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出 来,返回给服务层,服务层判断是否为null,不为null,计数累加。
有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返 回给服务层,直接按行进行累加。
count(数 字):InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1” 进去,直接按行进行累加。
count(*):InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接 按行进行累加。
按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽 量使用 count(*)。
1.3:update优化
我们主要需要注意一下update语句执行时的注意事项。
update course set name = 'javaEE' where id = 1 ;当我们在执行删除的SQL语句时,会锁定id为1这一行的数据,然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
update course set name = 'SpringBoot' where name = 'PHP' ;
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁 升级为表锁 。









![[Java]异常处理](https://img-blog.csdnimg.cn/4cdfd58c2e6340a9a375d8560769d4eb.png)