概念
索引的类型
- 聚集索引:叶子节点包含行记录的全部数据
- 辅助索引:叶子节点不包含行记录的全部数据,除了键值以外,还包含指向索引行的书签。
堆表和索引组织表
堆表
无论是主键索引还是普通索引都是辅助索引。数据是按照插入的顺序存储在堆表中,而索引存放指向堆表中的数据指针。
好处:
- 由于不需要考虑顺序,所以堆表的存储速度更快点
索引组织表
主键索引是聚集索引,其他索引是辅助索引。
好处:
- 节约磁盘空间: 数据直接和主键索引放在一起,没有另外存放数据的地方
- 降低了IO:当查询都是主键时,直接就获取到对应的数据。
不好:
- 当查询大部分是使用其他索引时,就需要通过主键索引进行二次回表查询。
索引的分裂
在数据插入时的索引分裂
- 插入是随机时,Page_direction=page_no_direction(0x05), 则取页的中间记录为分裂点记录
- 同一个方向的插入记录为 5 时,page_n_direction =5, page_last_insert 之后还有三条记录,则分裂点为 page_last_insert 之后的第三条记录
- 分裂点的记录为待插入的记录
索引的管理
当索引进行添加和删除时
正常流程
- 创建一张临时表
- 原表数据导入临时表
- 删除原表
- 临时表重命名为原表
不好的点就是查询的时候,表不可用
快速索引创建(FIC)
对原表加上S 锁,不创建临时表,可以对原表进行查询,只适用于辅助索引
在线架构改变(Online Schema Change)
提高原有事物的并发性
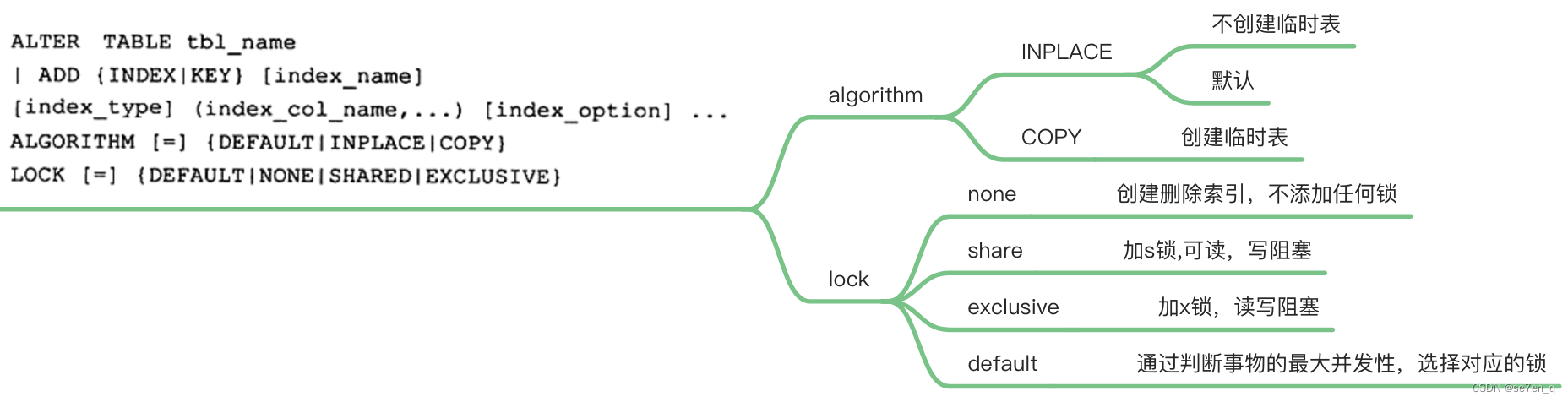
Online DDL(*)
在索引创建的过程中,将 insert ,update, delete DDL 语句记录到缓存中,当创建完成后,再应用到表中。
innodb_online_alter_log_max 控制存储大小
当查询索引时
show index from {table_name}
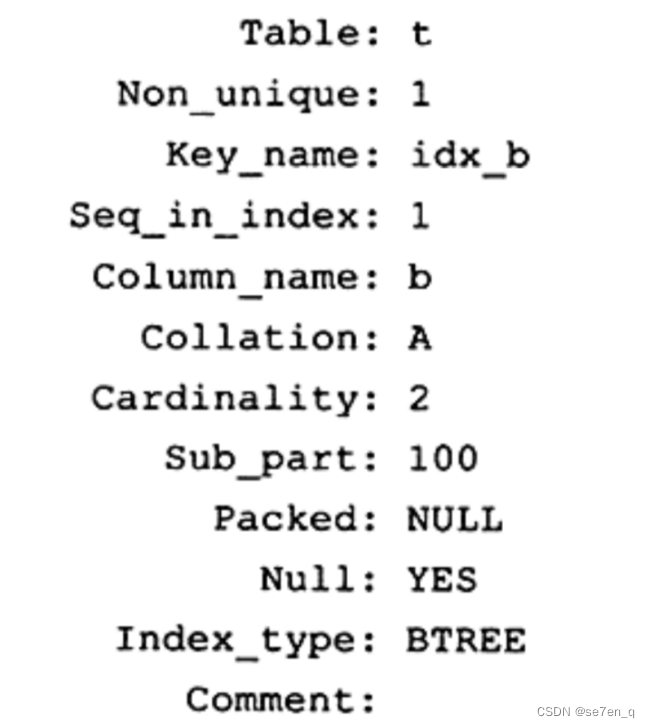
- key_name: 索引名称
- column_name: 字段名称
- seq_in_index: 字段在这个索引中是第几个位置
- collation: 列以什么方式存储在索引中,如果是 B+ 树,则这个值为 A, 若为 hash,则这个值为 null, 如果是 红黑树,则这个值为?
- cardinality: 索引中唯一值的估值
- sub_part: 列的内容前缀多长字符被索引
- packed: 关键字如何被压缩
如上图的解释为:
索引 idex_b 是表 t 的索引,b 字段在 index_b 索引中是第一列,类型为 B+ 树,可以为空,不是唯一的,取 b 字段内容的前100字符进行排序
Cardinality
- 评估这个索引的价值
- 如果 cardinality / count(1) ≈1 ,则这个索引值得加上
- 如果 cardinality / count(1) ≈ 0,则可以考虑将这个索引删除掉
- 何时更新
- 表中 1/16 的数据已发生变化
- stat_modified_count > 200 0000 0000
- 执行
analyze table强制更新
- 更新原理:
因为如果数据特别大的情况下,这个值统计有点耗时,Innodb 引擎使用采样的方式进行统计,所以这个值每次的结果可能会不一样。
- 计算 B+ 树索引叶子节点的数据量 A
- 随机选择 8 个叶子节点,统计每个页的不同记录个数: P1,P2 ……,P8
- Cardinality = (P1+P2+ …… +P8)/8 * A
| 参数 | 说明 |
| :—: | :—: |
| innodb_stats_transient_sample_pages | 每次采样页的数量。默认值为 8 |
| innodb_stats_persistent_sample_pages | analyze table 更新 cardinality 时,每次获取的采样页的数量。默认值为 20 |
索引的使用
联合索引
对多个列进行索引,对第二个键值进行排序处理
覆盖索引
从辅助索引中可以查找到记录,就不需要再从聚集索引中获取。因为辅助索引没有包含整行的数据,所以其大小远远小于聚集索引,所以可以减少磁盘 IO 操作。
select count(*) from {table_name}
综上:因为页的拆分意味着磁盘操作,尽量减少页的拆分,所以插入的数据主键最好是自带顺序的。