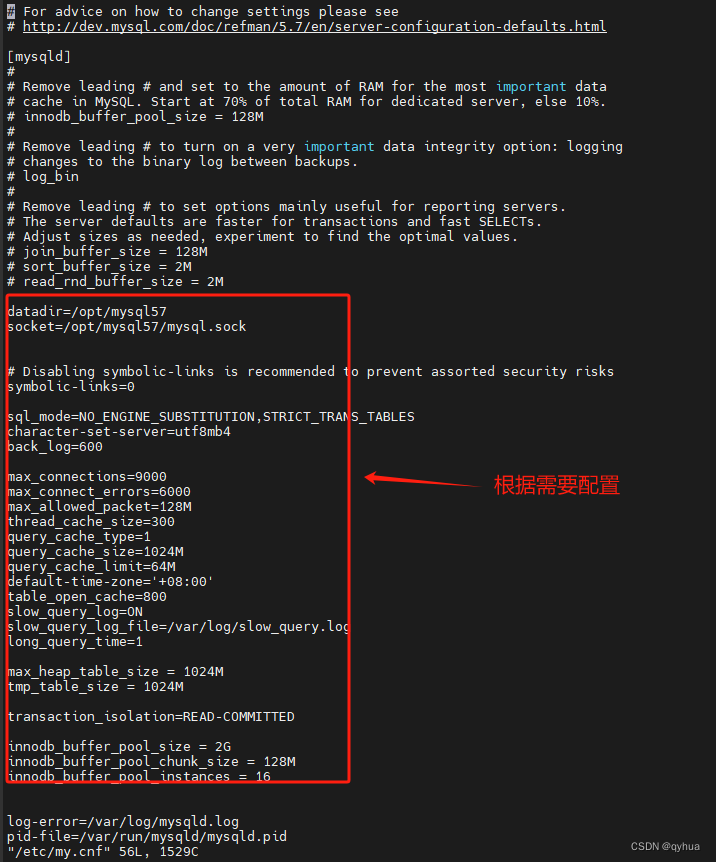
有什么不对的及时指出,共同学习进步。(●’◡’●)
有监督对比学习将自监督批量对比方法扩展到完全监督设置,能够有效地利用标签信息。属于同一类的点簇在嵌入空间中被拉到一起,同时将来自不同类的样本簇推开。这种损失显示出对自然损坏很稳健,并且对优化器和数据增强等超参数设置更稳定。
有监督对比学习论文的贡献:
- 提出了对比损失函数一种新的扩展,允许每个锚点都有多个正样本,使对比学习适应完全监督设置。
- 该损失为很多数据集的top-1的准确率带来了提升,对自然损坏有稳健性。
- 损失函数的梯度鼓励从硬正样本和硬的负样本中学习。(硬的正样本与锚点图像不相似的正样本,硬的负样本就是与锚点图像相似的负样本,都是难以学习的那种)
- 对比损失函数不如交叉熵损失函数对超参数敏感。
自监督对比学习损失

有监督对比学习损失

文中对交叉熵损失训练,自监督对比损失训练和有监督对比损失训练进行比较

推理模型中的参数个数始终保持不变,应该是推理的时候就是编码器+分类头都一样。
上图是训练的时候,交叉熵损失不必说。
自监督损失一般采用的是个体判别代理任务,正样本是自身经过数据增强后的图像(一般一个正样本),其他的都是负样本,训练编码器的时候让正样本和锚点图像经过编码器得到的特征尽可能接近,与负样本之间的特征尽可能拉远。
有监督对比学习,有标签信息,正样本除了自身数据增强后的之外还有这个类别中的其他样本(一般这个batch_size中)。
stage1就是训练编码器。
stage2是训练分类头,作者指出不需要训练线性分类器,并且先前的工作已经使用k -最近邻分类或原型分类来评估分类任务上的表示。线性分类器也可以与编码器联合训练,只要不将梯度传播回编码器即可,就是分类头和编码器之间训练要分开。
有监督对比学习损失代码
对比学习对比的是特征,所以损失函数的输入是特征,有监督对比学习损失还要输入标签信息。
损失函数就是模型的输出和标签(这里是mask)之间的差距,输出和标签差距越大,那么loss就越大。
输出这里是编码器的输出就是特征,标签就是类别标签。标签是如何起作用的呢?就是让损失函数区分这个batchsize中的正负样本,属于同一类就是正样本,其他都是负样本。
其中标签mask怎么获得,一个是通过label,另一个直接输入。label是每个数据的类别信息,label.view(1,-1)变成列向量然后再与它的转置进行torch.eq(),得到一个矩阵mask,mask(i,j)如果第i个数据和第j个数据类别相同那么这个位置是True,否则为False,float就变成0,1。后面乘了一个对角线元素为0,其他位置元素为1的矩阵,就是不让每个feature与自身对比。
我们看它self.contrast_mode="one"的时候只是比较feature中第0个特征(也就是平常的第一个特征),那么锚点特征就是所有数据的第0个特征;"all"就是所有的特征都要对比;锚点特征就是所有数据的所有特征。 torch.cat(torch.unbind(features, dim=1), dim=0)把feature按照第1维拆开,然后在第0维上cat,然后比较的feature的形式就是每一个数据的第1个特征|每个数据的第2个特征|…|每个数据的第n个特征,排列,这些特征是排在一起的在一个维度上。锚点特征要么是输入特征组的每个数据的第0个特征要么就是这些比较的特征。(不太理解为什么one的时候比较特征还是所有的)
锚点特征与比较特征的转置相乘,得到的就是batch_size*channel个相似矩阵,每两个数据在这个特征下的相似度。然后这个相似度矩阵要和我们得到的mask进行比较,就是上面的第二个式子。
下面是详细解释。
"""
Author: Yonglong Tian (yonglong@mit.edu)
Date: May 07, 2020
"""
from __future__ import print_function
import torch
import torch.nn as nn
class SupConLoss(nn.Module):
"""Supervised Contrastive Learning: https://arxiv.org/pdf/2004.11362.pdf.
It also supports the unsupervised contrastive loss in SimCLR"""
def __init__(self, temperature=0.07, contrast_mode='all',
base_temperature=0.07):
super(SupConLoss, self).__init__()
self.temperature = temperature
self.contrast_mode = contrast_mode#设置对比的模式有one和all两种,代表对比一个channel还是所有,个人理解
self.base_temperature = base_temperature #设置的温度
def forward(self, features, labels=None, mask=None):
"""Compute loss for model. If both `labels` and `mask` are None,
it degenerates to SimCLR unsupervised loss:
https://arxiv.org/pdf/2002.05709.pdf
Args:
features: hidden vector of shape [bsz, n_views, ...].
labels: ground truth of shape [bsz].
mask: contrastive mask of shape [bsz, bsz], mask_{i,j}=1 if sample j
has the same class as sample i. Can be asymmetric.
Returns:
A loss scalar.
"""
device = (torch.device('cuda')#设置设备
if features.is_cuda
else torch.device('cpu'))
if len(features.shape) < 3:
raise ValueError('`features` needs to be [bsz, n_views, ...],'
'at least 3 dimensions are required')
if len(features.shape) > 3:# batch_size, channel,H,W,平铺变成batch_size, channel, (H,W)
features = features.view(features.shape[0], features.shape[1], -1)
batch_size = features.shape[0]
if labels is not None and mask is not None:#只能存在一个
raise ValueError('Cannot define both `labels` and `mask`')
elif labels is None and mask is None:#如果两个都没有就是无监督对比损失,mask就是一个单位阵
mask = torch.eye(batch_size, dtype=torch.float32).to(device)
elif labels is not None:#有标签,就把他变成mask
labels = labels.contiguous().view(-1, 1)#contiguous深拷贝,与原来的labels没有关系,展开成一列,这样的话能够计算mask,否则labels一维的话labels.T是他本身捕获发生转置
if labels.shape[0] != batch_size:
raise ValueError('Num of labels does not match num of features')
mask = torch.eq(labels, labels.T).float().to(device)#label和label的转置比较,感觉应该是广播机制,让label和label.T都扩充了然后进行比较,相同的是1,不同是0.
#这里就是由label形成mask,mask(i,j)代表第i个数据和第j个数据的关系,如果两个类别相同就是1, 不同就是0
else:
mask = mask.float().to(device)#有mask就直接用mask,mask也是代表两个数据之间的关系
contrast_count = features.shape[1]#对比数是channel的个数
contrast_feature = torch.cat(torch.unbind(features, dim=1), dim=0)#把feature按照第1维拆开,然后在第0维上cat,(batch_size*channel,h*w..)#后面就是展开的feature的维度
#这个操作就和后面mask.repeat对上了,这个操作是第一个数据的第一维特征+第二个数据的第一维特征+第三个数据的第一维特征这样排列的与mask对应
if self.contrast_mode == 'one':#如果mode=one,比较feature中第1维中的0号元素(batch, h*w)
anchor_feature = features[:, 0]
anchor_count = 1
elif self.contrast_mode == 'all':#all就(batch*channel, h*w)
anchor_feature = contrast_feature
anchor_count = contrast_count
else:
raise ValueError('Unknown mode: {}'.format(self.contrast_mode))
# compute logits
anchor_dot_contrast = torch.div(
torch.matmul(anchor_feature, contrast_feature.T),#两个相乘获得相似度矩阵,乘积值越大代表越相关
self.temperature)
# for numerical stability
logits_max, _ = torch.max(anchor_dot_contrast, dim=1, keepdim=True)#计算其中最大值
logits = anchor_dot_contrast - logits_max.detach()#减去最大值,都是负的了,指数就小于等于1
# tile mask
mask = mask.repeat(anchor_count, contrast_count)#repeat它就是把mask复制很多份
# mask-out self-contrast cases
logits_mask = torch.scatter(#生成一个mask形状的矩阵除了对角线上的元素是0,其他位置都是1, 不会对自身进行比较
torch.ones_like(mask),
1,
torch.arange(batch_size * anchor_count).view(-1, 1).to(device),
0
)
mask = mask * logits_mask
# compute log_prob
exp_logits = torch.exp(logits) * logits_mask#定义其中的相似度
log_prob = logits - torch.log(exp_logits.sum(1, keepdim=True))#softmax
# compute mean of log-likelihood over positive
# modified to handle edge cases when there is no positive pair
# for an anchor point.
# Edge case e.g.:-
# features of shape: [4,1,...]
# labels: [0,1,1,2]
# loss before mean: [nan, ..., ..., nan]
mask_pos_pairs = mask.sum(1)#mask的和
mask_pos_pairs = torch.where(mask_pos_pairs < 1e-6, 1, mask_pos_pairs)#满足返回1,不满足返回mask_pos_pairs.保证数值稳定
mean_log_prob_pos = (mask * log_prob).sum(1) / mask_pos_pairs
# loss
loss = - (self.temperature / self.base_temperature) * mean_log_prob_pos#类似蒸馏temperature温度越高,分布曲线越平滑不易陷入局部最优解,温度低,分布陡峭
loss = loss.view(anchor_count, batch_size).mean()#计算平均
return loss
使用的化就是下面这段:
loss = criterion(features, labels)