医学图像跨模态转换:配准方法生成对图 + 扩散模型 + 成对配对方法
- MRI 到 CT 的高精度转换
- X 光、核磁共振 MRI、CT 区别
- 最关键的配准方法
- 读后启发:Fundus 转 OCT (只是猜想,不一定)
- 数据
- 图像预处理
- 5 个图像转换算法
- 评估图像质量
MRI 到 CT 的高精度转换
X 光、核磁共振 MRI、CT 区别
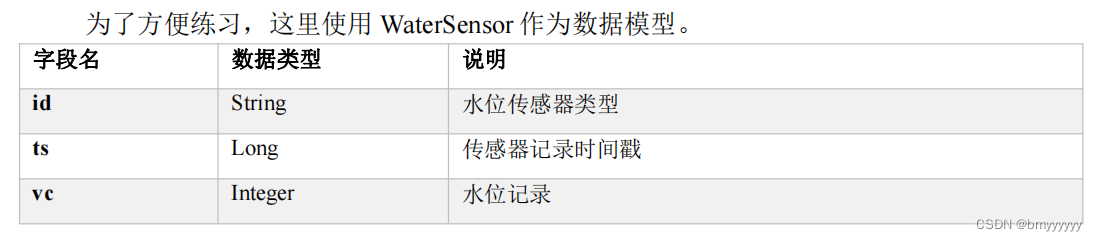
- X光:能看到大致的内部结构,特别适用于二维硬组织成像
- CT扫描:能看到切片级别的内部结构,特别适用于三维硬组织成像
- MRI:通过检测体内水分和软组织的微小变化,特别适用于三维软组织成像。
X光
- 骨科:
- 骨折
- 骨质疏松
- 胸部疾病:
- 肺炎
- 肿瘤
- 肺结核
- 牙科:
- 牙齿检查
- 颚骨问题
CT扫描
- 紧急情况:
- 脑出血
- 内脏器官损伤
- 癌症检查:
- 多种癌症(如肺癌、肝癌)
- 骨折和外伤:
- 复杂骨折
- 内部伤害
- 血管疾病:
- 动脉瘤
- 血管堵塞
- 医疗程序辅助:
- 生物镜检查
- 放射治疗规划
MRI
- 软组织和神经系统:
- 脑部
- 脊髓
- 神经系统
- 肌肉
- 脑和脊髓疾病:
- 脑肿瘤
- 脊髓损伤
- 多发性硬化症
- 关节和韧带:
- 关节损伤(如膝、肩)
- 心脏病:
- 心脏结构和功能评估
- 癌症检查:
- 前列腺癌
- 乳腺癌
最关键的配准方法
- 论文:https://arxiv.org/ftp/arxiv/papers/2308/2308.09345.pdf
- 模型:https://zenodo.org/records/8221159
- 代码:https://doi.org/10.5281/zenodo.8198697
MR图像转换成CT图像。
- MRI图像在精确地描绘脊柱后部结构,而CT图像在这方面更为精确和清晰。
作者用了:
-
点配准技术-精准对齐:将两个图像对齐,使TA们的相应特征或区域相匹配。
如果在MRI图像中发现了某种异常,也需要在CT图像中精确地定位同一异常。
-
图像到图像转换方法:2D配对方法(Pix2Pix, DDIM图像模式, DDIM噪声模式)和非配对方法(CUT, SynDiff),发现配对的图像转换方法(有直接对应关系),在将 MRI 转换为 CT 时更为有效。
发现:
-
去噪扩散模型在图像转换任务中优于传统GAN
-
精确的图像对齐是成功图像转换的关键
关键方法:刚性地标配准方法
- 选择地标:在每个待配准图像中选择显著的解剖标记作为地标。
- 地标匹配:使用算法找到不同图像中相对应的地标。
- 图像变换:通过旋转和平移操作,调整图像以使地标对齐。
- 功能:把一个模态转成另一个模态
类似的算法和技术包括:
- 互相关配准:
- 通过最大化图像间的互相关来对齐图像。
- 适用于具有高对比度和清晰边缘的图像,如胸部X光图像。
- 最小二乘配准:
- 通过最小化点对间距离的平方和来找到最佳配准。
- 适用于需要高精度配准的情况,尤其是当配准点可靠且易于自动检测时。
- 迭代最近点算法:
- 用于迭代地寻找最佳配准,通常用于点云数据。
- 适用于3D模型和图像的配准,如术前规划和患者特定模型的创建。
- 特征匹配和变换模型估计:
- 使用特征点检测、描述和匹配算法,如SIFT(尺度不变特征变换)、SURF(加速稳健特征)、ORB(Oriented FAST and Rotated BRIEF)等,配合RANSAC(随机抽样一致性)或其他模型估计方法来实现精确配准。
- 适用于具有丰富特征点的图像,如在手术导航和多模态成像分析中。
- 仿射配准:
- 允许图像进行旋转、平移、缩放和倾斜变换。
- 适用于需要调整图像尺度和方向的情况,尤其是在不同时间点获取的图像之间。
- 非刚性配准:
- 允许图像在局部进行弯曲或变形以更好地对齐,适用于软组织的成像对齐。
- 适用于软组织图像,如腹部或胸部CT,MRI中器官间的相对位置可能会变化。
读后启发:Fundus 转 OCT (只是猜想,不一定)
将fundus图像转换为OCT图像,应该采用非刚性配准方法。
-
非刚性配准:适用于眼底和OCT图像的配准,因为它可以适应这两种类型图像在形态上的差异。
例如,fundus图像是眼底的二维投影图像,而OCT提供的是眼部结构的三维断层扫描。
非刚性配准能够处理由于这种不同视角和成像技术导致的变形。
-
弹性配准:由于眼底图像和OCT图像的空间关系复杂,可能需要在局部进行细微的调整来精确配准。
例如,对于视网膜中的特定层面或特征,如视网膜血管和视盘的位置,在两种图像类型之间可能需要精确的局部对齐。
特殊情况的考虑:
-
视网膜层次的对应:OCT图像能够显示视网膜的多个层次,而这些在fundus图像中不是直接可见的。
因此,配准算法需要能够识别这两种图像间的对应关系。
-
疾病影响:如果患者有视网膜疾病,可能会导致图像间的形态差异增加,这时候非刚性配准方法能够提供更好的对齐效果。
可能还要结合特征匹配和变换模型估计方法,如使用特定的视网膜特征点来辅助非刚性配准,以提高配准的精度和可靠性。
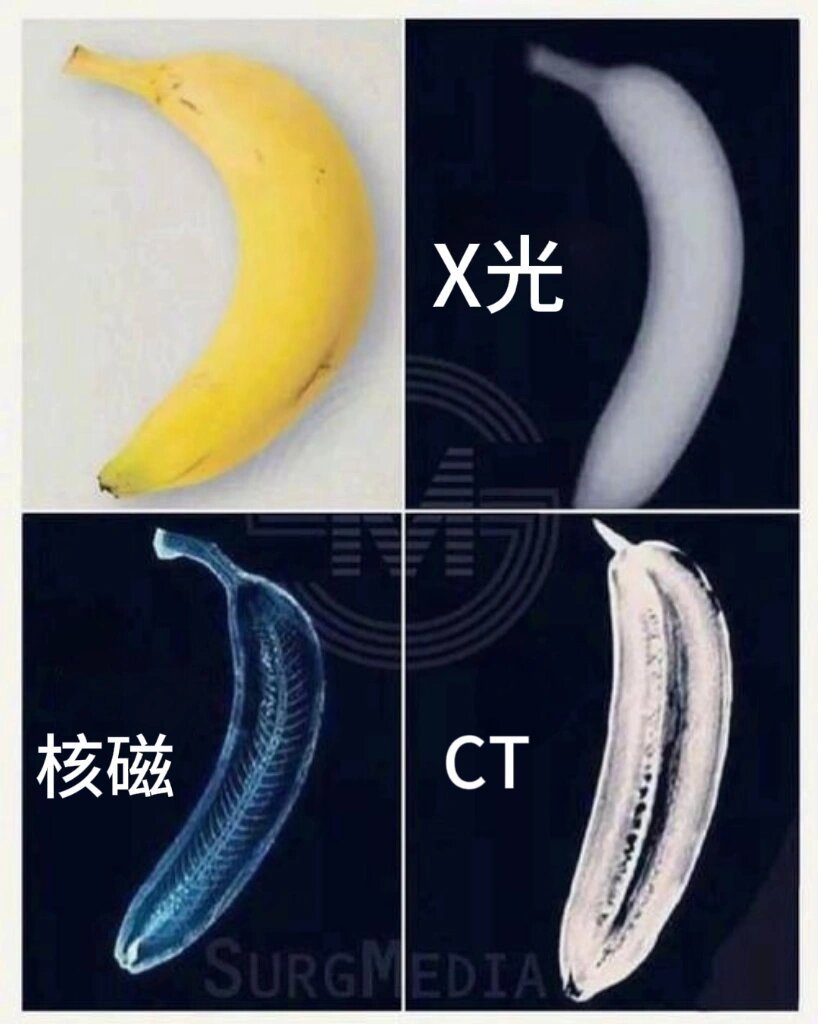
MRI 到 CT 的高精度转换流程图:
-
原始数据(Raw Data):
- 包含CT图像和T2w Dixon MRI图像。
- 图中标出了椎体(蓝色)和棘突(红色)的中心点。
-
CT刚性配准(CT rigid registration):
- 利用CT图像和MRI图像的中心点数据,进行了刚性配准,以对齐这两种类型的图像。
- 这意味着MRI图像中椎体和棘突的中心点与CT图像中相对应的点对齐。
-
训练数据(Training Data):
- 经过配准的CT和MRI图像成为训练数据,用于后续的图像到图像转换模型训练。
- 图中的绿色和白色框显示了自动生成的椎体和棘突的质心。
-
预测(Prediction):
- 使用训练好的模型对MRI图像进行处理,以产生合成的CT图像。
- 然后在这些合成的CT图像上进行分割操作。
-
分割(Segmentation):
- 对合成的CT图像进行分割以识别和标注脊柱的不同部分。
- 分割的结果与原始MRI图像完美对齐。
-
图像到图像模型(Image2Image Model)和CT分割模型(CT Segmentation Model):
- 图像到图像模型用于将MRI图像转换为CT样式的图像。
- CT分割模型则用于在合成的CT图像上进行椎骨的分割。
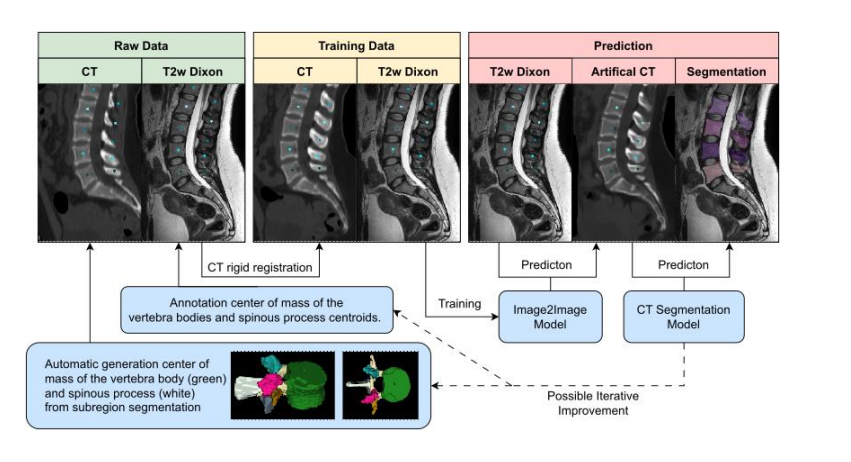
数据
-
数据来源:
- MRI数据来自12种不同的扫描仪,由3个不同的供应商提供。
- 使用MRSpineSeg Challenge (MRSSegClg) 数据集进行外部测试。
-
数据准备:
- 对于2D训练,只考虑包含脊柱的2D切片。
- 为了展示在本文中的图像,使用了德国国家队列(German National Cohort, GNC)数据集中的全身MRI。
-
数据集的分割:
- T1w 和 T2w Dixon/CT数据分为两个组,用于包括和排除在配准流程中。
- T1 加权图像对解剖细节有很好的分辨率,常用于评估脑和脊髓结构。
- T2 加权图像对于显示液体和软组织,如肿瘤、炎症和感染等病理条件特别敏感。
- 每个组中数据的描述包括了病人数量、性别分布和平均年龄。
-
配准方法:
- 使用了“Point-Rigid-Registration”(点刚性配准)方法,其中T1w组使用了从完整分割中提取的亚区域中心点,而T2w组使用了手动生成的椎体中心点和棘突中心点(可选)。
-
数据排除标准:
- 如果MR数据中后部脊椎结构不匹配,或者椎体不能由于运动而对齐,则排除该数据。
-
深度学习数据:
- 描述了不同数据集如何被用于深度学习的训练、验证和测试。
- 例如,T1w组有790对2D图像用于训练,经过增强后变为7894对,用于验证的有176对图像,测试集有151对图像。
-
外部测试:
- 通过MRSpineSeg Challenge和德国国家队列(GNC)数据集进行,以展示算法的泛化能力。
整体来看,这张图为读者提供了一个数据处理流程的概览,从数据收集到最终的模型测试阶段,包括了各个阶段的详细信息和数据处理的决策点。
图像预处理
作者对CT和MR图像集进行了预处理,以促进成对的图像转换。
-
问题:CT和MRI图像的配准
- 解法:刚性配准(Rigid registration)
- 原因:使用标记点(landmarks)来促进成对图像的转换。
-
问题:脊柱图像的旋转错位
- 解法:两地标配准方法(Two-landmark approach)
- 原因:观察到经常发生绕头尾轴的旋转错位,因此除了椎体的质心,还加入了脊柱突出部分的质心。
-
问题:T1w和T2w图像间的自动配准和分割
- 解法:图像合成和分割提取
- 原因:通过调整T2w到CT的转换来合成T1w图像,并从中提取质心点。
-
问题:T1w图像中配准失败的情况
- 解法:模型重新翻译
- 原因:先排除失败案例,再使用其他T1w图像训练的模型进行转换,证明足以生成所有质心点。
举个例子,作者把 MRI 转 CT 的具体步骤:
-
配准问题:
- 使用了刚性配准来对齐MRI和CT图像,因为它们来自于相同的患者但是成像位置可能有所偏差。
- 解决方法: 对这些图像使用了刚性配准技术,通过选择椎体的质心(CM)作为地标点来实现。
- 原因: 椎体的质心作为一个稳定的内部地标,有助于提供一个共同的参考点,以准确对齐两种模态的图像。
-
旋转错位问题:
- 有时候单个地标不足以纠正绕头尾轴的旋转错位。
- 解决方法: 引入了第二个地标点,即脊柱突出部分的质心。
- 原因: 第二个地标有助于纠正因患者在成像过程中的不同位置而引起的旋转。
-
图像强度标准化问题:
- MRI和CT图像具有不同的强度范围和对比特性。
- 解决方法: 对CT图像的强度值除以1000 HU(Hounsfield单位),并将超出范围的值截断。对MRI数据进行线性重缩放到[-1, 1]的范围。
- 原因: 这样可以确保在图像之间具有一致的强度测量,为图像翻译提供了一个共同的基础。
-
数据增强问题:
- 需要模型能够处理现实世界中的变异,如不同的扫描条件下的图像。
- 解决方法: 为MRI图像应用随机颜色抖动(亮度、对比度的随机化)。
- 原因: 这样的增强手段可以模仿现实世界中的成像条件,增加数据的多样性,提高模型的泛化能力。
总结,作者遇到的问题和解法:
特征1:多模态图像配准需要:
- 说明:多模态图像配准是指需要将不同成像技术获取的图像对齐,如将MRI图像与CT图像对齐。由于每种成像技术显示不同的身体组织信息,正确的对齐对于后续分析至关重要。
- 问题:假设MRI显示了某个患者脊柱的软组织结构,而CT图像显示了相同脊柱区域的骨骼结构。为了在两种图像中准确识别对应的解剖位置,需要将它们对齐。
特征2:绕头尾轴的旋转错位:
- 说明:这是指在成像过程中,尤其是在脊柱成像中,患者的位置可能会稍微旋转,导致图像之间存在绕长轴的旋转差异。
- 问题:如果在进行MRI和CT扫描时,患者的脊柱在两次扫描中的位置不完全一致,就可能出现一个图像相对于另一个图像旋转了一定角度。
特征3:不同成像技术的强度标准化:
- 说明:MRI和CT图像的像素强度值表示的是不同的物理量。标准化这些强度值使得它们在数值上具有可比性,是后续处理的重要步骤。
- 问题:在CT图像中,骨骼可能显示为高像素值(亮),而在MRI中,根据不同的加权,同样的骨骼可能显示为不同的亮度。通过强度标准化,这些不同的亮度可以被转换成统一的范围,以便于比较和分析。
特征4:数据增强和空间分辨率的统一:
- 说明:数据增强通过引入随机变化来增加图像数据的多样性,提高模型的泛化能力。空间分辨率的统一则确保所有图像都有相同的尺寸和比例。
- 问题:通过对图像应用随机亮度和对比度调整,可以模仿不同的扫描条件。将所有图像调整到相同的像素尺寸和切片厚度,可以使得它们在空间上具有一致性,便于算法处理。
将这些特征组合起来,目的是为了创建一个标准化和一致的数据集,用于训练能够准确识别和分割脊柱结构的深度学习模型。
-
关键步骤:强度标准化和空间分辨率调整
- 定义:将CT图像的值范围变换到[-1, 1],并对MRI数据应用线性重缩放,同样转换到[-1, 1]范围内。这是为了处理不同成像技术产生的不同强度值,保证训练过程中数据的一致性。
-
关键步骤:数据增强
- 定义:为MRI图像应用随机颜色抖动,以模拟真实世界成像中的亮度和对比度变化,增强模型的鲁棒性。
-
关键步骤:仿真弱脊柱侧弯和未对齐采集
- 定义:通过引入3D图像变形来增强训练数据,模拟弱脊柱侧弯和未对齐采集的情况,提高模型对于实际临床情况的适应能力。
5 个图像转换算法
作者测了 5 个 图像转换算法:
- 两种非配对方法(CUT和SynDiff)
- 三种配对方法(Pix2Pix,DDIM噪声,和DDIM图像)
使用了单地标和双地标方法,处理的配准和未配准数据来训练模型。
关键方法:
- 方法:SA-UNet的使用
- 定义:采用带有自注意力机制和时间步嵌入的UNet架构,以适应DDIM方法的需要。
非配对方法和配对方法的选择取决于数据是否已经配准,而SA-UNet架构和超参数搜索则是为了提高翻译后图像的质量和模型的性能。
评估图像质量
评估图像质量的方法是,通过比较实际的CT图像和合成的CT图像。
-
问题:如何评估合成CT图像的质量
- 解法:使用峰值信噪比(PSNR)
- 原因:需要一个量化指标来评估图像的质量,特别是合成图像与实际图像之间的相似度。
-
问题:如何在视觉上判断图像质量
- 解法:PSNR值大于30分贝(dB)
- 原因:大于30 dB的PSNR值通常表明图像间的差异对人眼来说是不可察觉的。
-
关键步骤:评估过程中的像素掩码
- 定义:为了专注于脊柱结构而忽略软组织的差异,在评估图像质量时,将距离分割的脊柱结构超过10个像素的像素掩码为零。
-
方法:评估指标的应用
- 定义:除了PSNR外,还计算了绝对差异(L1)、均方误差(MSE)、结构相似性指数(SSIM)和视觉信息保真度(VIFp)等其他指标,为了全面评估图像质量。
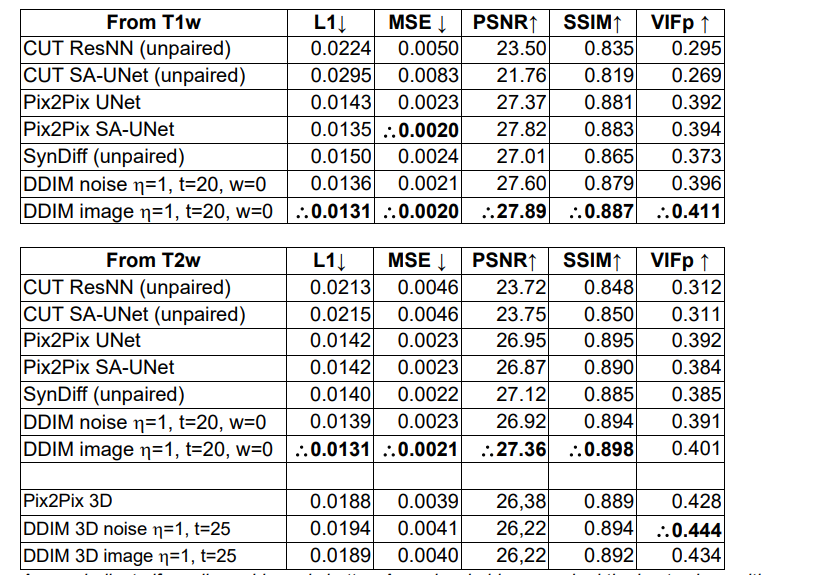
表格的上半部分是针对从 T1 加权MRI(T1w)到CT图像的转换。
下半部分是从 T2 加权 MRI(T2w)到CT图像的转换。
最后两行提供了 3D 图像到图像转换的数据。
性能指标包括:
- L1 Loss:绝对差异的平均值,越低表示预测图像与目标图像的差异越小。
- MSE (均方误差):预测值与实际值差异的平方的平均值,也是越低越好。
- PSNR (峰值信噪比):用分贝(dB)表示,反映图像质量,较高的值通常表示较高的图像质量。
- SSIM (结构相似性指数):衡量图像的视觉效果相似度,1为完全相同,越高越好。
- VIFp (Visual Information Fidelity):视觉信息保真度,衡量图像保留的信息量,越高表示保留的信息越多,图像质量越好。
表格中使用箭头来指示每个指标更好的方向(向上的箭头表示数值越大越好,向下的箭头表示数值越小越好)。
- 最佳的值在表格中用黑点标记。
通过这些指标,可以看出 DDIM image 模型在从T1w到CT的转换中,在PSNR和SSIM两个指标上表现最佳,而在从T2w到CT的转换中,DDIM image模型在所有指标上都有着较好的表现。
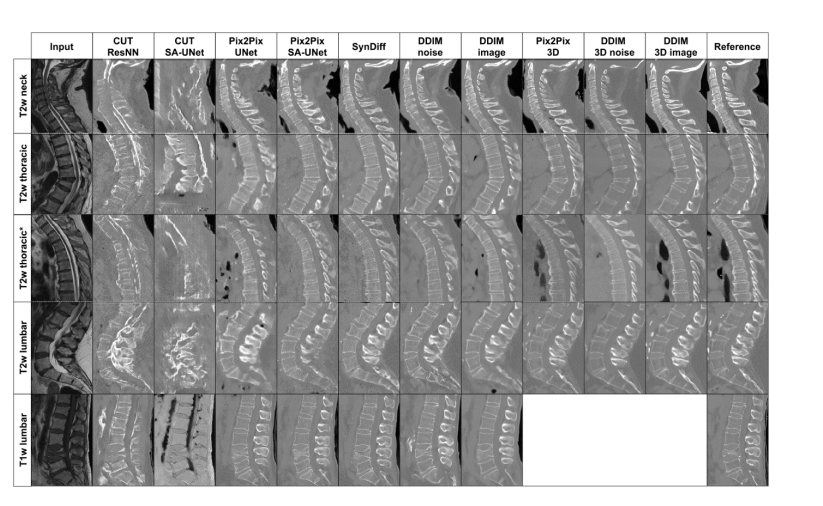
这些技术包括:
- CUT ResNN(对比学习的非配对翻译技术使用残差神经网络)
- CUT SA-UNet(使用自注意力U-网络的对比学习的非配对翻译技术)
- Pix2Pix UNet(使用U-网络的配对翻译技术)
- Pix2Pix SA-UNet(使用自注意力U-网络的配对翻译技术)
- SynDiff(未指明使用的网络架构的非配对翻译技术)
- DDIM noise(去噪扩散隐式模型预测噪声)
- DDIM image(去噪扩散隐式模型预测图像)
- Pix2Pix 3D(3D图像到图像翻译技术)
- DDIM 3D noise(3D去噪扩散隐式模型预测噪声)
- DDIM 3D image(3D去噪扩散隐式模型预测图像)
最右边的列为“Reference”,即真实的CT图像,作为评估转换效果的标准。

![[足式机器人]Part2 Dr. CAN学习笔记- 最优控制Optimal Control Ch07-4 轨迹追踪](https://img-blog.csdnimg.cn/direct/40f20d6d28c74c3a981944c5315bfd56.png#pic_center)