作者:来自 vivo 互联网大数据团队
本文根据刘开周老师在“2023 vivo开发者大会"现场演讲内容整理而成。公众号回复【2023 VDC】获取互联网技术分会场议题相关资料。
本文介绍了vivo在万亿级数据增长驱动下,基础数据架构建设的演进过程,在实时和离线计算过程中,如何基于业务发展,数据质量,计算成本等方面的挑战,构建稳定,可靠,低成本、高性能的双活计算架构。
基础数据是公司大数据应用的关键底座,价值挖掘的基石,内容包括:大数据集成,数据计算,架构容灾等几个主要方面。建设的目标包括:确保基础数据及时准确、计算性能好、资源成本消耗低、架构容灾能力强、研发效率高,这也是基础数据工作的核心能力。
一、基础数据发展与挑战
1.1 vivo 早期的基础数据架构
为了满足业务发展,0-1构建基础数据的基础框架,数据来源主要是日志,通过实时采集,缓存到Kafka,按小时离线转存到ODS表,日处理数据量在百亿级,整个数据链路简洁高效,但是,随着业务发展,数据增长,用户的诉求多样化,该基础数据架构逐渐面临诸多挑战。
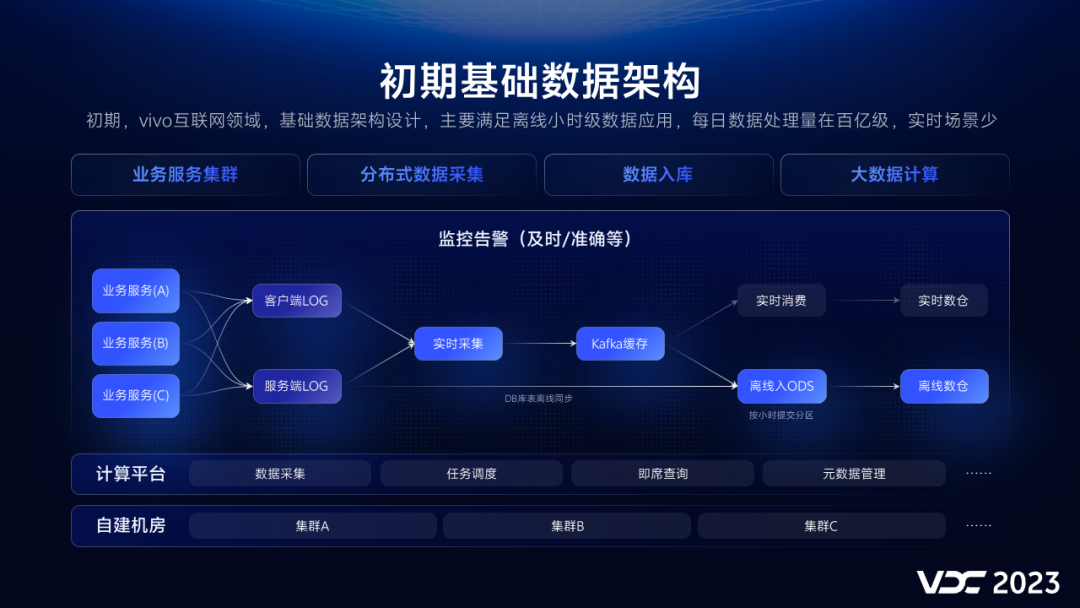
1.2 vivo 业发展带来挑战
一是:数据规模增长,日增记录数从百亿到万亿级,日增存储量从GB级到PB级,实时并发QPS量级达到数据百万。
二是:计算场景增加,从离线计算扩展到准实时,实时,甚至流批一体计算场景。
三是:性能要求提高,实时计算端到端延时,需要从小时到秒级;离线计算单小时数据量级从GB达到10TB+,业务发展速度超过了技术架构迭代速度,必然给技术带来更大的挑战。
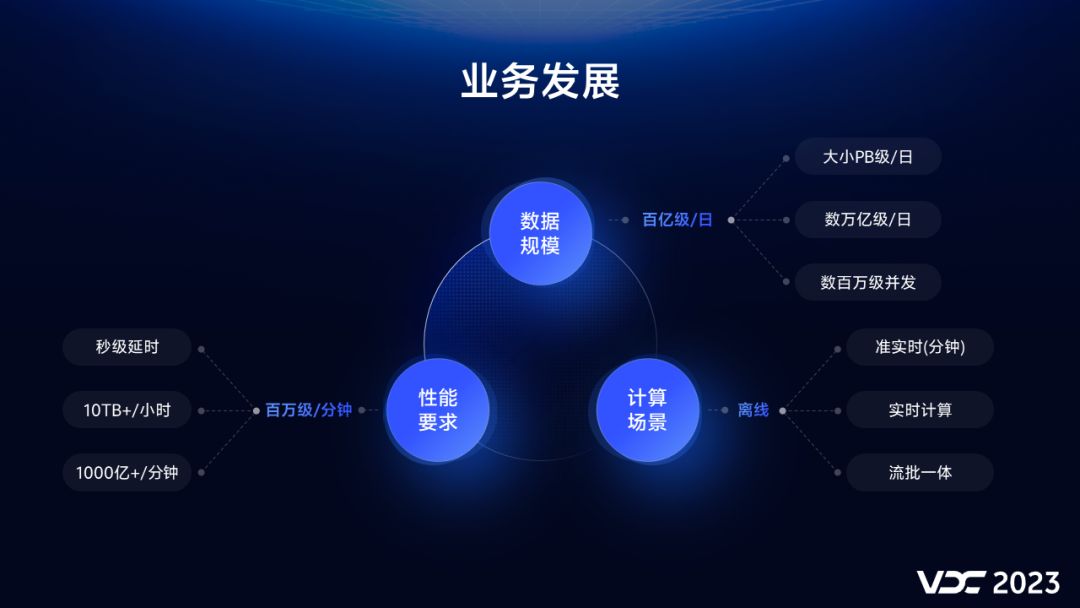
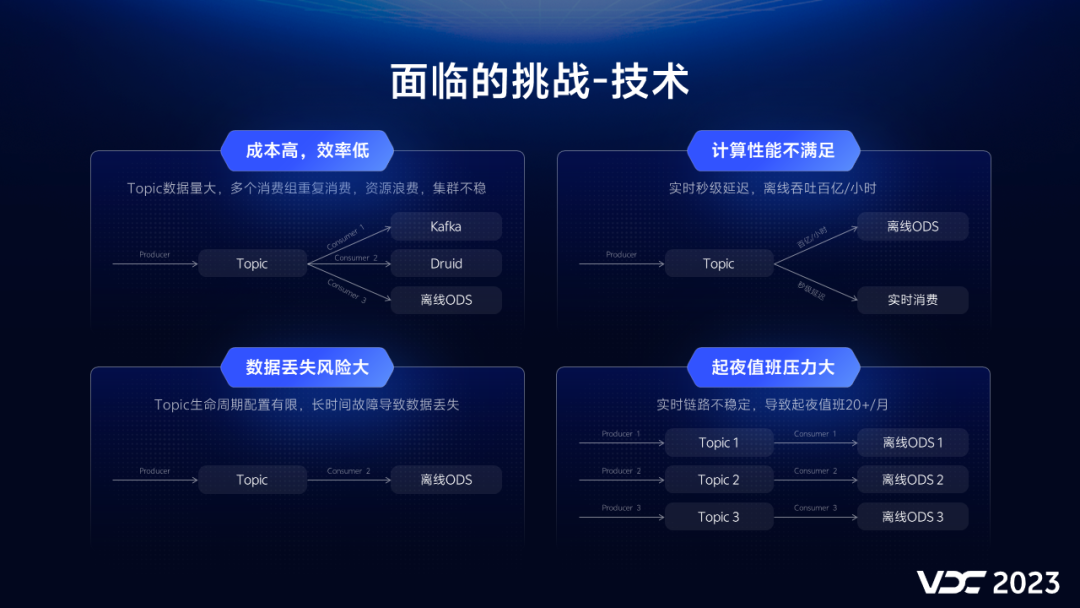
1.3 技术挑战
首先是单个Topic数据量每天数百亿,多个消费组同时消费,重复消费导致计算和存储资源浪费;Kafka集群稳定性越来越差。
数据量的增加,数据采集和ETL计算时延越来越长,无法满足链路秒级时延,每小时超过10TB的离线处理时间超过2~3小时。
考虑存储成本的原因,Kafka生命周期配置有限,长时间的故障会导致数据丢失。
由于计算性能和吞吐有限,需要不断增加资源,运维值班的压力日益增长,每月有超过20天都有起夜的情况。
当然,除了技术挑战,还有面临用户的挑战。
1.4 用户诉求
-
数据安全方面:数据加密,计算|需要解密|和鉴权,确保数据的安全合规
-
带宽成本方面:数据压缩,计算|需要解压缩|和拆分,降低传输的带宽成本
-
存储成本方面:数据输出,需要支持|不同压缩格式,以降低存储成本
-
使用便捷方面:需要扩充|基础数据|公共维度,避免下游重复计算
-
使用门槛方面:实时和离线数据|需要满足SQL化查询,降低用户使用门槛

二、vivo 基础数据架构应用实践
2.1 整体架构
基于业务发展,构建多机房多集群,双活容灾链路基础架构,全面支持多种周期(秒级/分钟/小时/天等)数据计算场景。
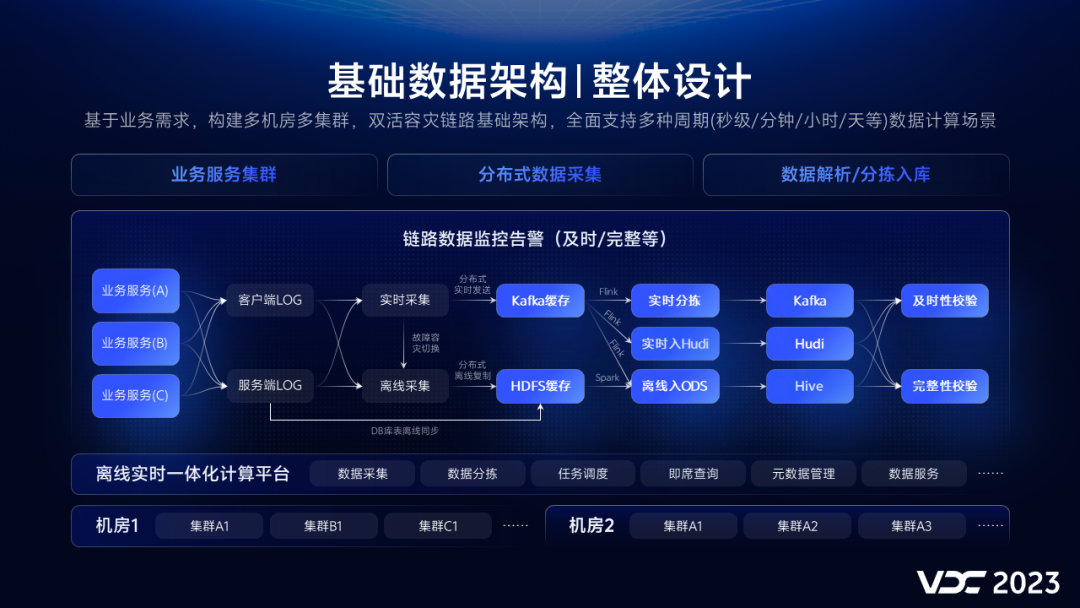
相比较历史架构,我们新增了离线采集链路,直接从源端拷贝LOG日志,缓存到HDFS目录,再解析入库写ODS表,与原实时链路互备,可实现链路故障容灾切换,同时,实时计算增加分拣层,收敛消费,支持多组件的配置化输出,为了确保数据及时和准确性,构建了完善的数据校验和监控体系。
显然,当前的架构有点类似Lambda架构,可能会有以下几个疑问:
-
实时和离线链路会出现存储和计算冗余,浪费资源多;
-
实时和离线计算会存在数据一致性问题,运维成本大;
-
现在都发展到流批/湖仓一体计算,此架构不够先进。
大数据计算架构,满足公司和业务发展,才是最好的,过于追求先进,又或者太过落后,都不利于公司和业务的发展,基础数据,重点是稳定高可用,通过持续的优化和迭代,将资源浪费问题,数据一致性问题和性能问题解决,构建一种双活容灾全新架构,才是我们初衷。
结合业务发展和使用调研,发现批计算场景远多于实时计算场景,并且有以下特点:
-
因Kafka的存储与HDFS存储比较,成本高,如果将万亿级数据全部缓存Kafka,存储成本巨大。
-
实时应用场景占比很少,约20%,海量数据消费资源持续空跑,导致大量计算资源浪费。
-
Kafka数据使用门槛高,不能直接SQL查询,理解和使用的效率太低。
-
离线重跑频繁,Kafka消费重置offset操作不方便,运维难度较大。
-
流批/湖仓一体架构成熟度有限,技术挑战难度较大,稳定性存在挑战。
-
基础数据的双链路一致性问题、资源冗余问题、性能问题,通过架构调整是可以解决的。

2.2 双链路设计
结合2种用数场景,将离线和实时计算链路,数据缓存和计算分离,减少实时存储和计算的资源,减少故障风险。

只有实时计算诉求,开启实时采集;写入到Kafka或者Pulsar集群,缓存8-24小时(可根据需要调整),用于后续实时计算。
只有离线计算诉求,开启离线采集;按小时拷贝到HDFS缓存集群,保存2-7天(可根据需要调整),用于后续离线计算。
同时,数据采集端确保实时和离线数据不冗余,这样设计的好处就是:
-
数据缓存 HDFS 比 Kafka 成本更低(降低40%成本),不容易丢,离线重跑更加便捷;
-
实时链路出问题可立即切换到离线链路(定点采集,分钟级切换入仓),容灾能力会更加强大。
随着业务发展,实时场景逐渐增加,切换到实时链路后,会与原离线数据比较,数据不一致性风险更大,为此,我们通过三个措施解决,将ETL过程组件化,标准化,配置化。
一是:开发上线通用组件,离线和实时ETL共用
二是:成立ETL|专属团队,统一处理逻辑
三是:构建ETL处理平台,配置化开发
这样,通过链路切换,处理逻辑统一,功能和逻辑一致,既提升了研发效率,也消除了数据不一致风险;而在计算方面,实时和离线计算集群相互独立,实时和离线数据缓存计算相互独立,互不影响,计算更加稳定。
解决了Kafka存储成本、双链路数据不一致、链路容灾问题,接下来就是计算性能的问题需要解决:
-
实时计算,存在每天百亿级别的大Topic,多消费组重复消费,计算资源浪费。
-
实时计算,数据全链路端到端(数据生产端到数据用端)秒级延迟诉求无法满足。
-
离线计算,单次处理数据量10TB+,计算时间长超过2小时,计算内存配置TB级,及时性没法保证。
-
离线计算,单小时数据量级不固定,任务配置的计算资源是固定的,当数据量增加时,常有oom现象,必然,导致值班运维压力就比较大。
2.3 实时计算性能优化
增加统一分拣层,通过Topic一次消费,满足不同业务的数据要求,避免重复消费,存储换计算,降低成本。

为了解决百亿级大Topic=重复消费问题,我们构建了实时分拣层,主要是基于用户不同诉求,将不同用户,需要的部分数据,单独分拣到子Topic,提供用户消费,该分拣层,只需要申请一个消费组,一次消费,一次处理即可,有效避免重复消费和计算,这样,通过对大Topic部分数据的适当冗余,以存储换计算,可降低资源成本30%以上,同时,有效确保下游数据的一致性。
为了实现实时链路秒级延时,也遇到了一些困难, 主要介绍下高并发场景下的Redis批量动态扩容问题:
在实时ETL环节,会存在多个维表关联,维表缓存Redis,实时并发请求量达到数百万,因并发量持续增加,在Redis动态批量扩容时,会因数据均衡导致请求延迟,严重时达30分,单次扩容量机器越多越严重,这种延时部分业务无法接受, 我们考虑到=后续组件容灾的需要,通过请求时延、并发量、扩容影响等几个方面的kv组件验证测试,最终采用了HBase2.0,得益于它毫秒级的请求延时,优秀的异步请求框架,扩容批量复制region功能,因此,我们将HBase引入到实时链路中,达到解决Redis批量扩容导致消费延时的问题。
对于动态扩容延时敏感业务,优先采用HBase缓存维表,Redis作为降级容灾组件;对于动态扩容延时不敏感业务,优先采用Redis缓存维表,HBase作为降级容灾组件。

在实际应用中,还有两个小建议:
一是:实时任务重启时,瞬间会产生大量Redis连接请求,Redis服务器负载急剧增加,会存在无法建立连接直接抛弃的情况,因此,建议在Redis连接代码中增加重试机制,或者,连接量比较大时,可以适当分批连接。
二是:Redis组件的单点故障,不管是不是集群部署,难免出现问题,以免到时束手无策,建议增加额外组件降级容灾,我们主要是HBase和Redis并存。
2.4 离线计算性能优化
批处理,参考流计算的原理,采用微批处理模式,解决超过10TB/小时的性能问题。

前面多次提到的离线计算,单次处理数据量超过10TB,消耗特别多的资源,数据经常出现延迟,从图中可以看出,链路处理环节比较多,尤其在Join大维表时,会产生大量shuffle读写,频繁出现7337端口异常现象(这里的7337是ESS服务端口),因集群没有类似RSS这样的服务,即使有,也不一定能抗住这个量级的shuffle读写,所以,降低shuffle数量,是我们提升离线计算性能的关键。
为了降低shuffle数量,首先想到的就是降低单次处理数据量,于是,我们借鉴了流式计算模型,设计了微批计算架构,其原理介绍下:
数据采集写HDFS频率由小时改为分钟级(如10分钟);持续监控缓存目录,当满足条件时(比如大小达到1TB),自动提交Spark批处理任务;读取该批次文件,识别文件处理状态,并写元数据,处理完,更新该批次文件状态,以此循环,将小时处理,调整为无固定周期的微批处理;当发现某小时数据处理完成时,提交hive表分区(注意:是否处理完我们调用采集接口,这里不做详细描述)。
这种微批计算架构,通过充分利用时间和资源,在提升性能和吞吐量的同时,也提升了资源利用率。至此,我们降低了单次处理的数据量,比如:业务表单次处理数据量从百亿下将到10亿,但是,join多张大维表时shuffle量依然很大,耗时较长,资源消耗较高,这不是完美的解决方案,还需要在维表和join方式上持续优化。
维表的优化,将全局全量维表,修改为多个业务增量维表,降低Join维表数据量,以适当冗余存储换Join效率。
因为维表都是公司级的全量表,数据在4~10亿左右,且需要关联2到3个不同维表,关联方式是Sort Merge Join,会产生shuffle和Sort的开销,效率很低。

因此,我们做了降低维表量级,调整Join模式两个优化,降维表如下:
首先:基于业务表和维表,构建业务增量维表,维表数据量从亿级下降到千万级;
其次:所有维表都存储在HBase,增量维表半年重新初始化一次(减少无效数据);
最后:Join时优先使用增量维表,少部分使用全量维表,并且每次计算都会更新增量维表。
接下来,调整业务表和维表的Join方式,首先,来看下原来大表关联使用的Sort Merge Join的原理。
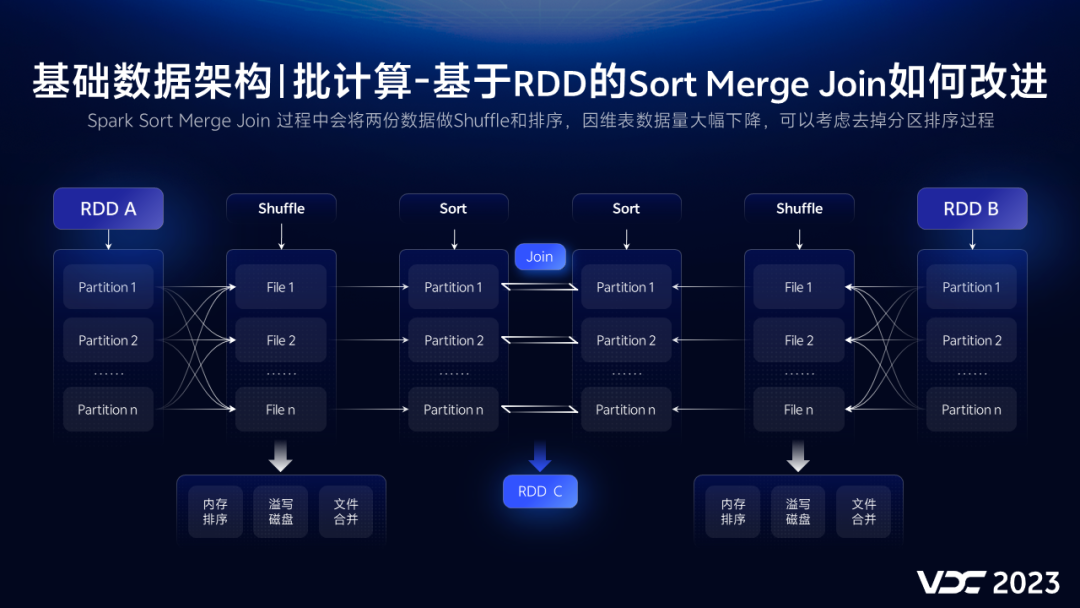
先读取数据,基于SortShuffleManager机制,做内存排序,磁盘溢写,磁盘文件合并等操作,然后,对每个分区的数据做排序,最后匹配关联,可以有效解决大数据量关联,不能全部内存Join的痛点。
而我们降低了业务表和维表的数据量,分区减少了,shuffle量自然也会减少,如果再把消耗比较大的分区排序去掉,就可以大大提升关联性能。
而对于千万级维表如果采用广播方式,可能造成Driver端OOM,毕竟维表还是GB级别的,所以,采用Shuffle Hash Join方式是最佳方案。
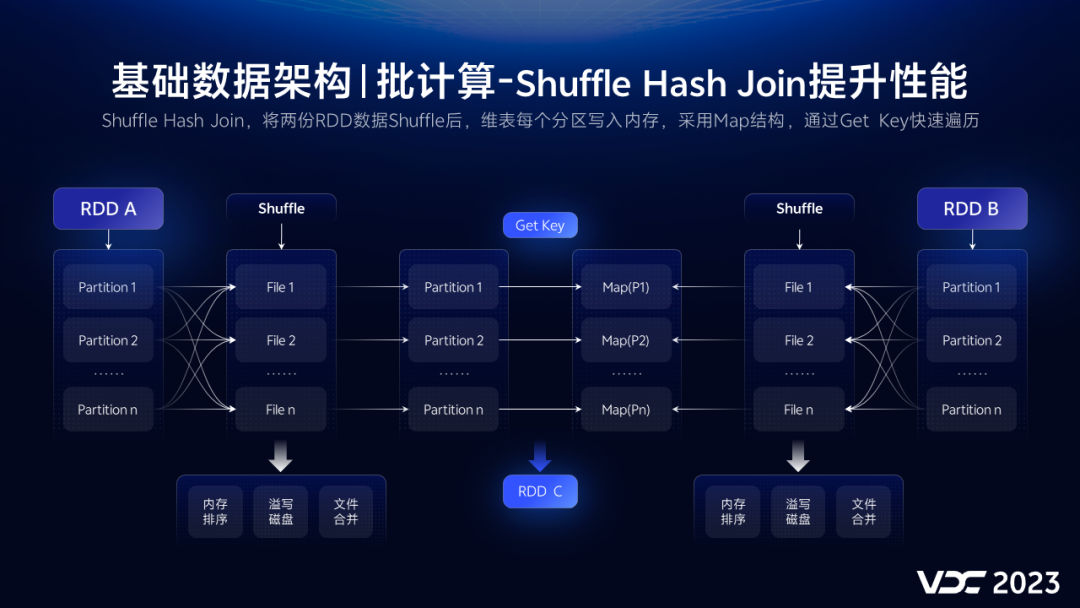
最大的优点就是,就是将维表分区的数据加载到内存中,并且使用Map结构保存,Join时,通过get的方式遍历,避免排序,简单高效。
这样,通过降低业务表和维表数据量,改变Join方式,相比较原来计算性能提升60%+,至此,离线计算性能问题得到解决,数据产出及时性也就迎刃而解。
2.5 数据完整性
在数据采集,实时ETL和离线ETL,写ODS过程中,如何确保数据不丢,不错,保持数据完整性 ?其挑战主要有三个。
-
数据完整如何判定,比如A表数据量,下降20%?或者30%,表示不完整?很难统一定义,也是行业痛点。
-
出现问题,并且是异常,如何快速定位?
-
不完整的数据,给到下游用户,成千上万的任务都在使用错误的数据计算,影响面很大,故障恢复成本很高。
而这一切的基础,都需要依赖元数据,因此,元数据收集成了很关键的工作,必须优先设计和建设,这里不展开讲实时元数据的收集内容。
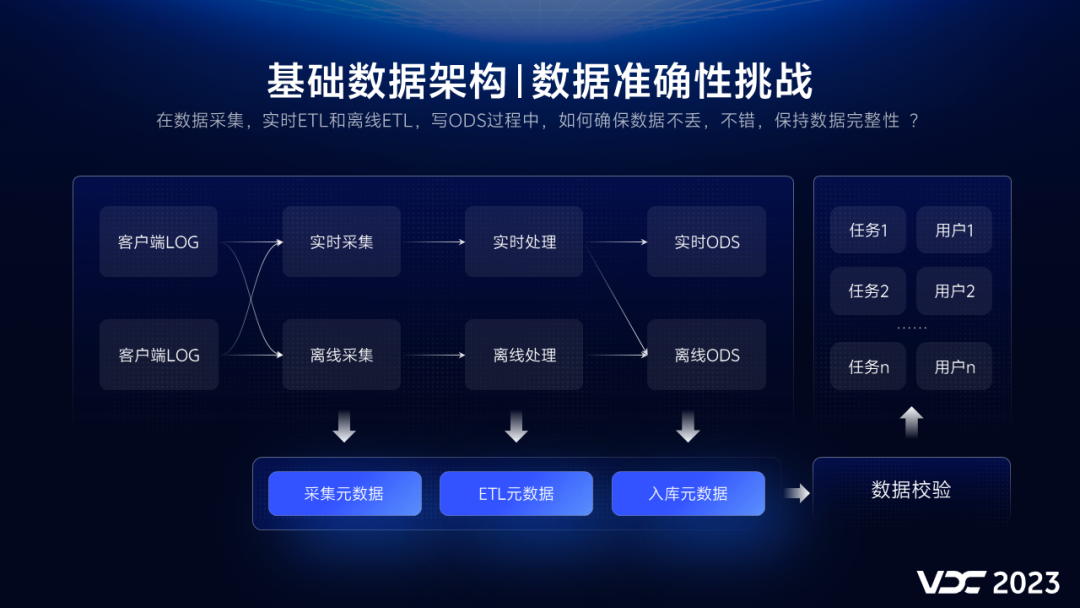
当有了丰富的元数据后,利用实时元数据,我们在链路中,增加了三层实时数据完整性对账校验,它们分别是:
-
数据采集,完整性对账
-
ETL处理,完整性对账
-
组件输出,完整性对账
这样,通过可视化输出对账结果,能够快速定位和发现问题,定位时长从天级别下降到分钟级别。

为了准确识别数据异常波动,我们结合业务特征,建设出了多种完整性校验方法,并构建多功能交叉验证体系,应用于数据校验,主要有以下几种校验方案:
-
短周期内的同比和环比
-
基于历史趋势的算法校验
-
基于数据时延的偶发漂移
-
基于节假日的数据起伏等
-
基于时间段的操作特征等
将这些验证方案,交叉叠加应用到,不同的表和Topic,可以明显提升异常发现的准确率,实际从85%提升到99%,如果出现异常告警,也会自动阻断下游任务,这样会大大降低对下游用户的影响。
三、vivo 基础数据架构总结展望
3.1 架构实践总结
基础数据架构应用诸多实践,没有全部详细描述,有关业务痛点,用户诉求,研发幸福感经过长期的建设,也取得了一些进步。

- 基础数据架构,从单链路升级到流批存算分离双活架构,多机房/集群/组件容灾,基础数据链路高可用。
-
实时计算,避免重复消费,数据按需分拣,构建低延时的计算架构,满足数百万并发处理请求。
-
离线计算,任务化整为零,数据分拆减量,计算降低过程开销,存储换性能,整体性能提升60%。
-
数据及时性,整体架构升级改造,数据处理量级从百亿级到数万亿级,SLA及时率稳定保持在99.9%。
-
数据完整性,三层级实时对账,多功能数据校验,准确的监控告警,SLA完整性稳定99.9995%。
-
值班运维,得益于高可用架构和链路,高性能计算,起夜值班天数从月均20+下降到月均5天以内。
而数据压缩,数据安全,数据易用性,便捷性,在过程中都有涉及,只是没有详细讲述。
3.2 架构迭代规划
打造更敏捷高效,低成本的湖仓一体大数据计算架构。
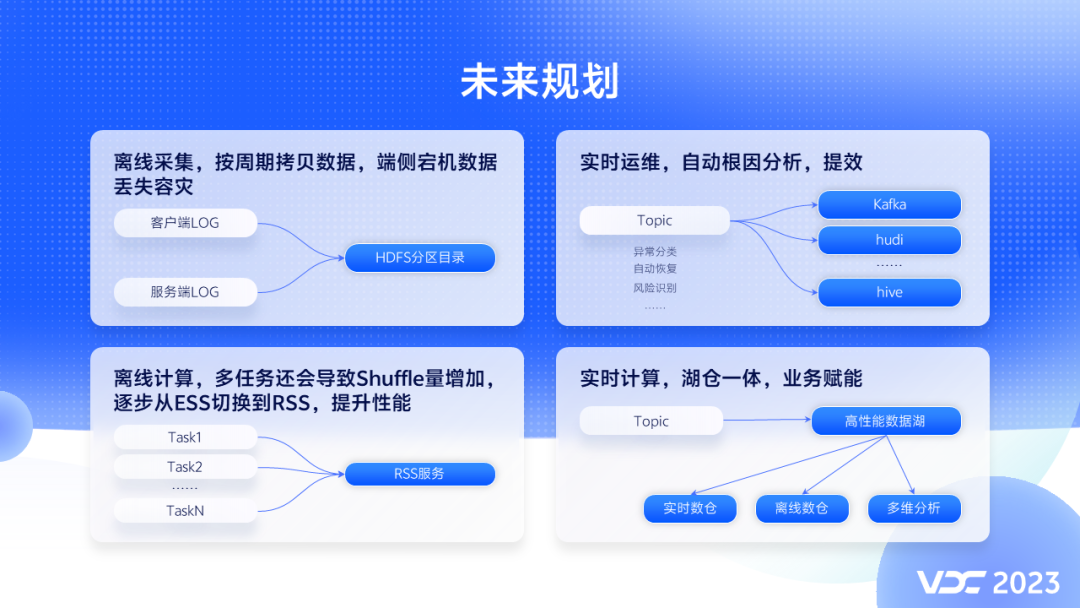
- 离线采集,重点解决源端宕机数据丢失问题,因为当前部分数据离线采集,端侧服务器宕机,可能会有数据丢失风险。
-
离线计算,重点解决Shuffle问题,从ESS切到RSS,实现Shuffle数据的存储和计算分离,解决ESS服务的性能问题。
-
实时运维,提升异常发现和处理的智能化水平,重点是实时元数据的捕获与归因分析,解决实时运维中定位难,处理时间要求短的问题。
-
实时计算,将联合相关团队,构建更敏捷高效,低成本的,湖仓一体化大数据计算架构。