vp9协议笔记📒
本文主要是对vp9协议的梳理,协议的细节参考官方文档:VP9协议链接(需要加速器)
vp9协议笔记
- vp9协议笔记📒
- 1. 视频编码概述
- 2. 超级帧superframe(sz):
- 2. frame(sz)
- 3. vp9中的一些索引解释:
- 4. decode-tiles()
- 5. decode_partition
- 6. Residual()
- 7. 参考文献
1. 视频编码概述
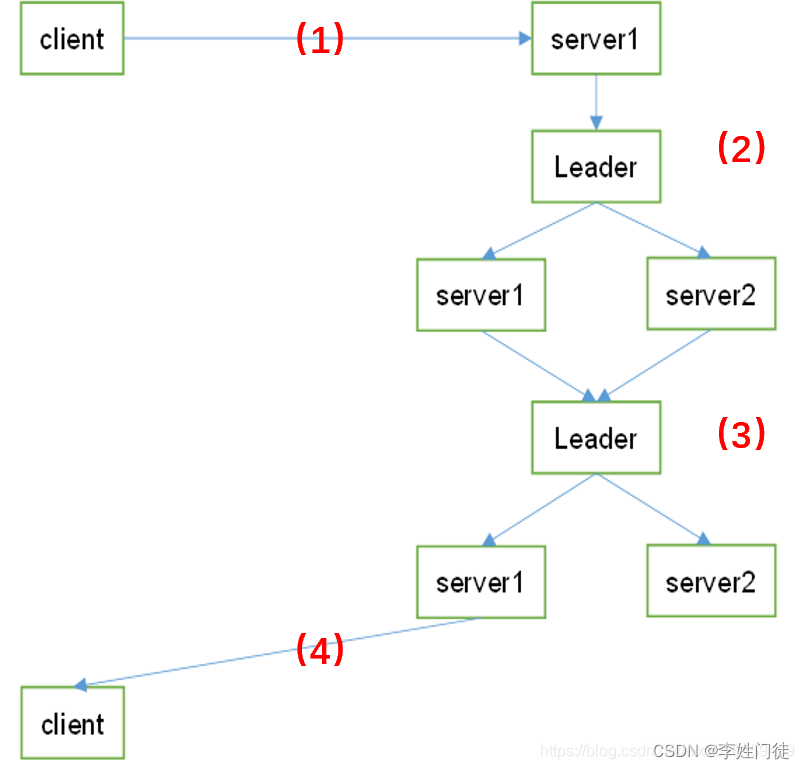
🐶视频编码的流程大概是预测 + 残差 + loop filter(LPF)的模式;
🐭编码端 : 编码端首先对图像进行合理的划分,之后对划分的块(CU)采用帧内预测或帧间预测的方式,对图像进行预测,筛选出误差最小的预测模式,但这样预测出来的图像和原图像会有很大误差,这个误差被称为残差(residual, TU);
🐹编码端可能会对残差进行进一步的split划分(因此TU的大小是小于CU的, H265有对TU进一步的划分, 而vp9中没有),之后再对划分后的块进行DCT变换和量化,以减小残差所占的字节大小(这一步一般图像会有少许的损失);
🐰为了弥补变换量化产生的损失,编码端会编码一种选择一种合适的loop_filter(lpf)过滤器的模式,对图像进行补偿;
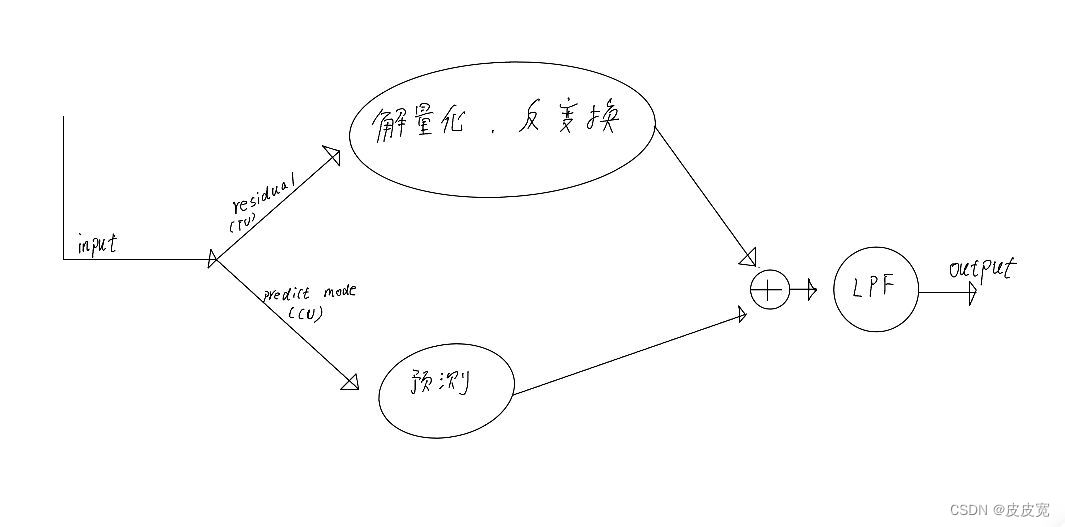
🐺如图所示, 解码端拿到预测模式,根据预测模式对图像进行预测;同时对拿到的残差进行解量化和反变换; 将预测图像和接量化,反变换后的残差相加,再根据lpf的模式进行滤波,就可以完成图像的解码了。
2. 超级帧superframe(sz):
superframe( sz ) {
for( i = 0; i < NumFrames; i++ )
frame( frame_sizes[ i ] )
superframe_index( )
}
- 🐸各个帧的解析函数frame(frame_ize)需要用的fram_size在superframe_index()里,为什么super_frame_index在后面才解码?
-
- Q1 : 该解析函数顺序并不是真实解码顺序,只是码流的排列顺序。解析超级帧时,整个超级帧的大小sz是已知的,直接先读取大小为sz的字符串的最后1个字节(superframe_header),解析后就知道frame的数量和frame_size的大小;解析完superframe-index然后才开始从头开始解析各个frame;
-
- Q2. 由于我们编码完所有的帧信息才能知道各个帧的大小,所以superframe index放在超级帧的后面;而解析的时候是先解析superframe index,再从头解析各个frame
- 🐯为什么superframe header要解析两遍
-
- Q : 因为vp9支持superframe,也支持不用superframe的结构,解析两遍(对比一下是否存在这个信息)和superframe-mark标志的,一起判断该段是否为超级帧;
2. frame(sz)
frame( sz ) {
startBitPos = get_position( )
uncompressed_header( )
trailing_bits( )
if ( header_size_in_bytes == 0 ) {
while ( get_position( ) < startBitPos + 8 * sz)
padding_bit
return
}
load_probs( frame_context_idx )
load_probs2( frame_context_idx )
clear_counts( )
init_bool( header_size_in_bytes )
compressed_header( )
exit_bool( )
endBitPos = get_position( )
headerBytes = (endBitPos - startBitPos) / 8
decode_tiles( sz - headerBytes )
refresh_probs( )
}
- 🐻uncompress-header()为一些图像基本信息,bit位宽,YUV格式,色彩空间,帧间预测所需要用到的参考帧的更新等等;
- 🐷header_size_in_byte为0时表示该帧直接copy其他帧信息,不需要进一步解码了,这个变量的解析在ubcompress-header中;
- 🐽vp9采用的基于概率的压缩,具体可以参考协议第9节,很多压缩的语法元素有一张概率表,解码过程是会用到这张概率表的,而这张概率表也是会在运算过程中更新的。load-probs(idx)是加载frame_context_idx表示的这张概率表,frame_context_idx的值在uncompress-header中解析;
- 🐮编解码过程中会将很多语法元素编码的次数记录下来,以便后面在refresh_probs()中更新概率模型;因此开始解析压缩后的信息前,clear_count()清空计数器;
- 🐵Compress_header()里解析的是概率表,因为vp9并不是完全按上面load-probs加载的概率表来计算的,部分位置需要更新后再使用,哪些概率信息需要更新,更新值是多少,就在compress-header里解析;概率表用于从二进制码流里解析各个语法元素(详见协议第9节)
- 🐒decode-tiles()开始正式解析还原这个图像;
3. vp9中的一些索引解释:
- 🐴segment id : sement id对应的位置存储了之前解码过的图像的skip,QP,参考帧等信息,根据一些segment的相关标志位决定这些参数是直接采用segment id位置 所对应这些信息,还是单独解码这些信息;
- 🐎 frame_to_show_map_idx : 表示该帧直接显示frame_to_show_map_idx所对应的图像(之前解码存储的图像),该帧解码结束;
- 🐫frame_context_idx : vp9的字符串解析过程中会用到很多概率表(第9节),load_probs( frame_context_idx )表示加载frame_context_idx所对应的概率表;
4. decode-tiles()
- 🐑tileCols,这一帧图像有多少列tile
- 🐘tileRows,这一帧图像有多少行tile
- 🐼tileROw:当前tile位于该帧的第几行tile
- 🐍tileCOl: 当前tile位于该帧的第几行tile
- 🐦MiROWs:这一帧图像有多少行8*8块
- 🐤MiCols:这一帧图像有多少行8*8块
- 🐥MiROWSTART : 该tile的起始行的位置(8*8为单位,比如若为20,表示该tile位于一帧图像的y坐标的160像素点);
- 🐣简单来说,一个Mi的为8*8个r像素点;
5. decode_partition
- 🐔bsize是根据partition划分后的大小,也就是说,如果对88进行划分,之后一定进decode-block()。 如果bsize是88,partition 若为 NONE则一定进入decode_ block;其他partition对应的bsize为44,84,48,也是直接进decode block(一个88,无论怎么划分,都只解码一次decode_block);需要注意的是,decode_block函数里虽然Misze是44,84或48,但实际上都是在处理一个88的块;
- 🐧如果不需要编解码残差(skip),那还需要编码tx size吗?需要,intra mode预测要用到tx_size;
6. Residual()
Token : extra_bits[ 11 ][ 3 ] = {
{ 0, 0, 0},
{ 0, 0, 1},
{ 0, 0, 2},
{ 0, 0, 3},
{ 0, 0, 4},
{ 1, 1, 5},
{ 2, 2, 7},
{ 3, 3, 11},
{ 4, 4, 19},
{ 5, 5, 35},
{ 6, 14, 67}
}
- 【0】 位置是概率解码时要用到的;
- 【1】 表示offset的位宽
- 【2】 表示base
残差的绝对值 = base + offset;
例如:
- 🐟若token为 0(ZERO_TOKEN),则base为0,offset位宽为0,则残差的绝对值为0;
- 🐳若token为7(DCT_VAL_CAT3)则base = 7, offset位宽为2bit([0 , 3]),因此残差绝对值的取值范围为[7 , 10];
- 🐋若token为8(DCT_VAL_CAT4)则base = 11, offset位宽为3bit[0 , 7],因此表示残差绝对值的取值范围为[11 , 18];
7. 参考文献
【1】VP9协议链接(需要加速器)