引言
Transformer的自注意力机制可以进行远距离建模,在视觉的各个领域表现出强大的能力。然而在VAN中使用大核分解同样可以得到很好的效果。这也反映了卷积核的发展趋势,从一开始的大卷积核到vgg中采用堆叠的小卷积核代替大卷积核。

上图展现了MAN网络在同样的性能下具有更少的参数量。
提高模型性能,通常有三种方法:
- 更大的数据集
- 更好的训练策略
- 更好的网络结构
引言部分作者介绍了RCAN,RDN,MSRN的网络结构。作者之所以会提出这样的网络结构是因为:首先,transformer在各个领域大放光彩,但是作者认为transformer中的自注意力机制具有二次复杂度(就是太复杂了)。而出现的VAN(大核注意力机制)简单的堆叠卷积同样可以达到远距离建模的作用。所以作者产生了idea,就是应用VAN中的LKA(大核分解)来组建网络结构。作者为了最大化LKA的作用,作者采取了transformer的结构,而不是应用RCAN的架构。我们都知道transformer中包含了自注意力和MLP。但是作者认为MLP结构太过于复杂,用于低级视觉处理任务有点大材小用,所以作者引入了GSAU.
总结来说:作者首先提出了多尺度大核注意力模块(MLKA),可以得到多尺度远程建模依赖,提高了模型的表示能力。然后作者将门控机制和空间注意力结合在一起,构建了简化了前馈网络,可以减少参数和计算。
模型结构

整个模型分为三个部分。
首先是浅层的特征的提取,有一个3*3的卷积构成。

然后是级联的多尺度注意力模块(MAB),用于进一步提取特征。在级联的最后添加了一层LKAT,这时因为在传统的SR中都存在一个卷积层。但是,它在建立远程连接方面存在缺陷,因此限制了最终重建功能的代表性能力。为了从堆叠的mab中总结出更合理的信息,我们在tail模块中引入了7-9-1 LKA。实验结果表明,LKAT模块可以有效地聚合有用信息,并显着提高重建质量。

最后是重建模块,有卷积层和亚像素卷积层构成,其中应用的残差连接。
损失函数
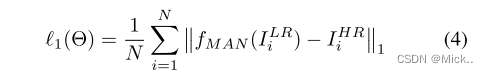
MAB
作者受transformer的启发,重新思考SISR中用于特征提取的基本卷积块。

如上图所示,MAB有多尺度大核注意力(MLKA)和门空间注意力单元(GSAU)组成。
其中整个MAB可以总结为以下公式:

分别表示可学习参数,和1*1的逐点卷积。这里的1*1卷积是为了保持维度相等。
MLKA(多尺度大内核注意力机制)
注意力机制可以迫使网络专注于关键信息,而忽略不相关的信息。以前的SR模型采用了一系列注意机制,包括通道注意 (CA) 和自注意 (SA),以获得更多的信息性特征。但是,这些方法无法同时吸收本地信息和远程依赖性,并且它们通常会考虑固定感受野的注意力图。在最新的视觉注意研究的启发下 [21],我们提出了多尺度大内核注意 (MLKA),通过结合大内核分解和多尺度学习来解决这些问题。具体来说,MLKA由三个主要功能组成: 用于建立相互依存关系的大核注意 (LKA),用于获得异质尺度相关性的多尺度机制以及用于动态重新校准的门控聚合。
LKA(大内核注意力)

LKA可以表示为以下公式:

多尺度机制
为了增强LKA,作者引入了组卷积多尺度机制,可以获得更加全面的信息。

这里意思是说将输入按照通道维度分为n份。对于每一组特征都作用一个LKA。
门控聚合(Gated aggregation. )
与许多高级计算机视觉任务不同,SR任务对膨胀卷积和分组卷积的容忍度较差。
如图4所示,虽然较大的LKA捕获较宽的像素响应,但是阻塞伪像出现在较大的LKA的生成的注意图中。

对于第i组输入Xi,为了避免块效应,并了解更多本地信息,我们利用空间门通过以下方式将LKAi(·) 动态调整为MLKAi(·):
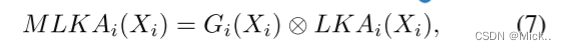
其中Gi(·) 是ai × ai深度卷积产生的第i门,LKAi(·) 是ai-bi-1分解的LKA。在图4中,我们提供门控聚合的视觉结果。可以观察到,从注意力图中删除了块效果,并且MLKAi更为合理。特别是,具有较大感受野的LKA对远距离依赖性的反应更多,而较小的LKA倾向于保留局部纹理。
门控空间注意单元(Gated Spatial Attention Unit (GSAU) )
在Transformer中,前馈网络 (FFN) 是增强特征表示的重要组成部分。但是,具有宽中间通道的MLP对于SR来说太重了,尤其是对于大型图像输入而言。受 [444 23,34,24] 的启发,我们将简单的空间注意 (SSA) 和门控线性单元 (GLU) 集成到建议的GSAU中,以实现自适应门控机制并减少参数和计算。
为了更有效地捕获空间信息,我们采用单层深度卷积对特征图进行加权。给定X和Y,GSAU的关键过程可以表示为

通过应用空间门,GSAU可以在考虑的复杂性下去除非线性层并捕获局部连续性。
Large Kernel Attention Tail (LKAT)
在以前的SR网络 [7、8、26、27、9] 中,3 × 3卷积层被广泛用作深度提取主干的尾部。但是,它在建立远程连接方面存在缺陷,因此限制了最终重建功能的代表性能力。为了从堆叠的mab中总结出更合理的信息,我们在tail模块中引入了7-9-1 LKA。具体地,如图3所示,LKA由两个1 × 1卷积包裹。实验结果表明,LKAT模块可以有效地聚合有用信息,并显着提高重建质量。
实验
数据集和指标
遵循最新的工作 [35,9,12],我们利用包含800和2650训练图像的DIV2K [36] 和Flicker2K [7] 来训练我们的模型。为了进行测试,我们在五个常用数据集上评估了我们的方法: Set5 [13],Set14 [37],BSD100 [38],Urban100 [39] 和Manga109 [40]。此外,在YCbCr图像的Y通道中应用了两个标准评估指标,即峰值信噪比 (PSNR) 和结构相似性指数 (SSIM) [41]。
实验细节
我们训练了三个不同版本的MAN: tiny,light和classical。三个版本的通道数和MAB的层数都不一样,通道数分别为48/60/180,层数分别为5/24/36.MLKA使用了三种多尺度分解模式,分别为3-5-1、5-7-1和7-9-1。GSAU中使用7 × 7深度卷积。
在训练阶段,使用双三次插值来生成lr-hr图像对。训练对通过水平翻转和90 、180 、270的随机旋转进一步增强。
消融实验
各个组件的研究
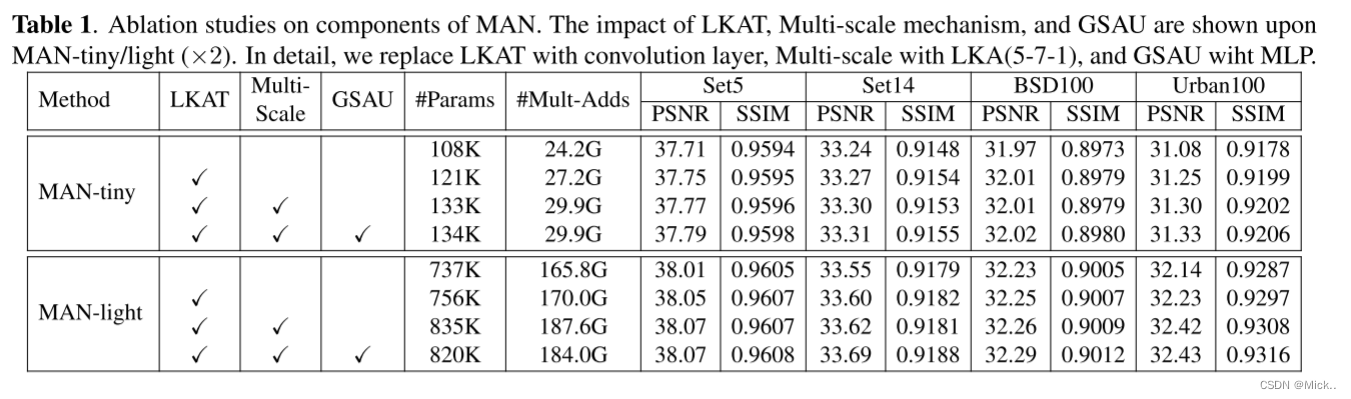
上表展现了MAN中各个组件对模型的贡献。其中LKAT用卷积层代替,多尺度用LKA(5-7-1),GSAU用MLP代替.因为作者是用的meta-transformer的架构,所以会有MLP模块。其中GSAU是一个很好的替代品对于MLP,在MAN-light中减少了15k的参数且模型性能不下降。
模型架构的选择研究

上表表明了哪种风格的架构更加有效。从表中可以看出RCAN结构的具有更多的参数且模型性能比较差。
MLKA的研究

上表展现出了作者设计了LKA和几个MLKA,表明MLKA具有更加好的性能和更快的收敛性。在表中可能存在一点疑问,就是模块数量增加,模块的参数反而没增加,这时因为作者在这里应用分组卷积。
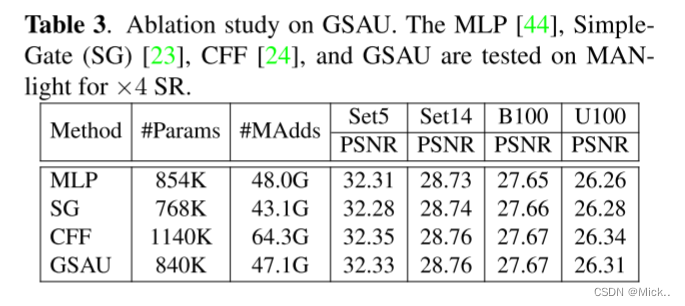
GSAU的研究
先进算法的对比
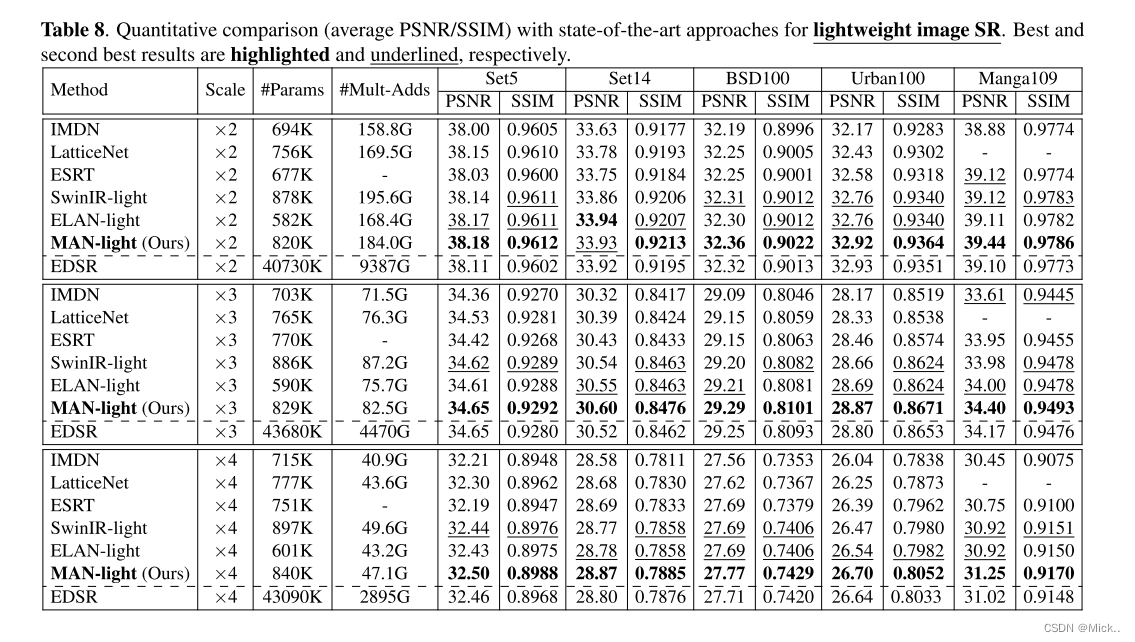
与一些最先进的小 [6,45,46] 和轻量级 [31,47,9] SR 进行对比。


经典的SR方法对比。

总结
在本文中,我们提出了一种多尺度注意力网络 (MAN),用于在多种环境下重新缩放超分辨率图像。MAN采用transformer以获得更好的建模表示能力。为了有效,灵活地在各个区域之间建立长期相关性,我们开发了结合大内核分解和多尺度机制的多尺度大内核关注 (MLKA)。此外,我们提出了一种简化的前馈网络,该网络集成了门机制和空间注意力,以激活本地信息并降低模型复杂性。广泛的实验表明,我们基于CNN的MAN可以以更有效的方式实现比以前的SOTA模型更好的性能。
模型代码:
# -*- coding: utf-8 -*-
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from basicsr.utils.registry import ARCH_REGISTRY
class LKA(nn.Module):
"""
大核注意力机制,将(K,d)的大卷积层分解为三个卷积层
"""
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 7, padding=7 // 2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 9, stride=1, padding=((9 // 2) * 4), groups=dim, dilation=4)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
# 这里的*是矩阵的点乘、torch.mul(),矩阵乘法是@、torch.mm()
return u * attn
class Attention(nn.Module):
def __init__(self, n_feats):
super().__init__()
self.norm = LayerNorm(n_feats, data_format='channels_first')
###可学习参数
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
self.proj_1 = nn.Conv2d(n_feats, n_feats, 1)
self.spatial_gating_unit = LKA(n_feats)
self.proj_2 = nn.Conv2d(n_feats, n_feats, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(self.norm(x))
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x * self.scale + shorcut
return x
# ----------------------------------------------------------------------------------------------------------------
class MLP(nn.Module):
def __init__(self, n_feats):
super().__init__()
self.norm = LayerNorm(n_feats, data_format='channels_first')
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
i_feats = 2 * n_feats
self.fc1 = nn.Conv2d(n_feats, i_feats, 1, 1, 0)
self.act = nn.GELU()
self.fc2 = nn.Conv2d(i_feats, n_feats, 1, 1, 0)
def forward(self, x):
shortcut = x.clone()
x = self.norm(x)
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return x * self.scale + shortcut
class CFF(nn.Module):
def __init__(self, n_feats, drop=0.0, k=2, squeeze_factor=15, attn='GLKA'):
super().__init__()
i_feats = n_feats * 2
self.Conv1 = nn.Conv2d(n_feats, i_feats, 1, 1, 0)
self.DWConv1 = nn.Sequential(
nn.Conv2d(i_feats, i_feats, 7, 1, 7 // 2, groups=n_feats),
nn.GELU())
self.Conv2 = nn.Conv2d(i_feats, n_feats, 1, 1, 0)
self.norm = LayerNorm(n_feats, data_format='channels_first')
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
def forward(self, x):
shortcut = x.clone()
# Ghost Expand
x = self.Conv1(self.norm(x))
x = self.DWConv1(x)
x = self.Conv2(x)
return x * self.scale + shortcut
class SimpleGate(nn.Module):
def __init__(self, n_feats):
super().__init__()
i_feats = n_feats * 2
self.Conv1 = nn.Conv2d(n_feats, i_feats, 1, 1, 0)
# self.DWConv1 = nn.Conv2d(n_feats, n_feats, 7, 1, 7//2, groups= n_feats)
self.Conv2 = nn.Conv2d(n_feats, n_feats, 1, 1, 0)
self.norm = LayerNorm(n_feats, data_format='channels_first')
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
def forward(self, x):
shortcut = x.clone()
# Ghost Expand
x = self.Conv1(self.norm(x))
a, x = torch.chunk(x, 2, dim=1)
x = x * a # self.DWConv1(a)
x = self.Conv2(x)
return x * self.scale + shortcut
# -----------------------------------------------------------------------------------------------------------------
# RCAN-style
class RCBv6(nn.Module):
def __init__(
self, n_feats, k, lk=7, res_scale=1.0, style='X', act=nn.SiLU(), deploy=False):
super().__init__()
self.LKA = nn.Sequential(
nn.Conv2d(n_feats, n_feats, 5, 1, lk // 2, groups=n_feats),
nn.Conv2d(n_feats, n_feats, 7, stride=1, padding=9, groups=n_feats, dilation=3),
nn.Conv2d(n_feats, n_feats, 1, 1, 0),
nn.Sigmoid())
# self.LFE2 = LFEv3(n_feats, attn ='CA')
self.LFE = nn.Sequential(
nn.Conv2d(n_feats, n_feats, 3, 1, 1),
nn.GELU(),
nn.Conv2d(n_feats, n_feats, 3, 1, 1))
def forward(self, x, pre_attn=None, RAA=None):
shortcut = x.clone()
x = self.LFE(x)
x = self.LKA(x) * x
return x + shortcut
# -----------------------------------------------------------------------------------------------------------------
class MLKA_Ablation(nn.Module):
def __init__(self, n_feats, k=2, squeeze_factor=15):
super().__init__()
i_feats = 2 * n_feats
self.n_feats = n_feats
self.i_feats = i_feats
self.norm = LayerNorm(n_feats, data_format='channels_first')
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
k = 2
# Multiscale Large Kernel Attention
self.LKA7 = nn.Sequential(
nn.Conv2d(n_feats // k, n_feats // k, 7, 1, 7 // 2, groups=n_feats // k),
nn.Conv2d(n_feats // k, n_feats // k, 9, stride=1, padding=(9 // 2) * 4, groups=n_feats // k, dilation=4),
nn.Conv2d(n_feats // k, n_feats // k, 1, 1, 0))
self.LKA5 = nn.Sequential(
nn.Conv2d(n_feats // k, n_feats // k, 5, 1, 5 // 2, groups=n_feats // k),
nn.Conv2d(n_feats // k, n_feats // k, 7, stride=1, padding=(7 // 2) * 3, groups=n_feats // k, dilation=3),
nn.Conv2d(n_feats // k, n_feats // k, 1, 1, 0))
'''self.LKA3 = nn.Sequential(
nn.Conv2d(n_feats//k, n_feats//k, 3, 1, 1, groups= n_feats//k),
nn.Conv2d(n_feats//k, n_feats//k, 5, stride=1, padding=(5//2)*2, groups=n_feats//k, dilation=2),
nn.Conv2d(n_feats//k, n_feats//k, 1, 1, 0))'''
# self.X3 = nn.Conv2d(n_feats//k, n_feats//k, 3, 1, 1, groups= n_feats//k)
self.X5 = nn.Conv2d(n_feats // k, n_feats // k, 5, 1, 5 // 2, groups=n_feats // k)
self.X7 = nn.Conv2d(n_feats // k, n_feats // k, 7, 1, 7 // 2, groups=n_feats // k)
self.proj_first = nn.Sequential(
nn.Conv2d(n_feats, i_feats, 1, 1, 0))
self.proj_last = nn.Sequential(
nn.Conv2d(n_feats, n_feats, 1, 1, 0))
def forward(self, x, pre_attn=None, RAA=None):
shortcut = x.clone()
x = self.norm(x)
x = self.proj_first(x)
a, x = torch.chunk(x, 2, dim=1)
# u_1, u_2, u_3= torch.chunk(u, 3, dim=1)
a_1, a_2 = torch.chunk(a, 2, dim=1)
a = torch.cat([self.LKA7(a_1) * self.X7(a_1), self.LKA5(a_2) * self.X5(a_2)], dim=1)
x = self.proj_last(x * a) * self.scale + shortcut
return x
# -----------------------------------------------------------------------------------------------------------------
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape,)
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class SGAB(nn.Module):
def __init__(self, n_feats, drop=0.0, k=2, squeeze_factor=15, attn='GLKA'):
super().__init__()
i_feats = n_feats * 2
self.Conv1 = nn.Conv2d(n_feats, i_feats, 1, 1, 0)
self.DWConv1 = nn.Conv2d(n_feats, n_feats, 7, 1, 7 // 2, groups=n_feats)
self.Conv2 = nn.Conv2d(n_feats, n_feats, 1, 1, 0)
self.norm = LayerNorm(n_feats, data_format='channels_first')
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
def forward(self, x):
shortcut = x.clone()
# Ghost Expand
x = self.Conv1(self.norm(x))
a, x = torch.chunk(x, 2, dim=1)
x = x * self.DWConv1(a)
x = self.Conv2(x)
return x * self.scale + shortcut
class GroupGLKA(nn.Module):
def __init__(self, n_feats, k=2, squeeze_factor=15):
super().__init__()
i_feats = 2 * n_feats
self.n_feats = n_feats
self.i_feats = i_feats
self.norm = LayerNorm(n_feats, data_format='channels_first')
self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
# Multiscale Large Kernel Attention
self.LKA7 = nn.Sequential(
nn.Conv2d(n_feats // 3, n_feats // 3, 7, 1, 7 // 2, groups=n_feats // 3),
nn.Conv2d(n_feats // 3, n_feats // 3, 9, stride=1, padding=(9 // 2) * 4, groups=n_feats // 3, dilation=4),
nn.Conv2d(n_feats // 3, n_feats // 3, 1, 1, 0))
self.LKA5 = nn.Sequential(
nn.Conv2d(n_feats // 3, n_feats // 3, 5, 1, 5 // 2, groups=n_feats // 3),
nn.Conv2d(n_feats // 3, n_feats // 3, 7, stride=1, padding=(7 // 2) * 3, groups=n_feats // 3, dilation=3),
nn.Conv2d(n_feats // 3, n_feats // 3, 1, 1, 0))
self.LKA3 = nn.Sequential(
nn.Conv2d(n_feats // 3, n_feats // 3, 3, 1, 1, groups=n_feats // 3),
nn.Conv2d(n_feats // 3, n_feats // 3, 5, stride=1, padding=(5 // 2) * 2, groups=n_feats // 3, dilation=2),
nn.Conv2d(n_feats // 3, n_feats // 3, 1, 1, 0))
self.X3 = nn.Conv2d(n_feats // 3, n_feats // 3, 3, 1, 1, groups=n_feats // 3)
self.X5 = nn.Conv2d(n_feats // 3, n_feats // 3, 5, 1, 5 // 2, groups=n_feats // 3)
self.X7 = nn.Conv2d(n_feats // 3, n_feats // 3, 7, 1, 7 // 2, groups=n_feats // 3)
self.proj_first = nn.Sequential(
nn.Conv2d(n_feats, i_feats, 1, 1, 0))
self.proj_last = nn.Sequential(
nn.Conv2d(n_feats, n_feats, 1, 1, 0))
def forward(self, x, pre_attn=None, RAA=None):
shortcut = x.clone()
x = self.norm(x)
x = self.proj_first(x)
a, x = torch.chunk(x, 2, dim=1)
a_1, a_2, a_3 = torch.chunk(a, 3, dim=1)
a = torch.cat([self.LKA3(a_1) * self.X3(a_1), self.LKA5(a_2) * self.X5(a_2), self.LKA7(a_3) * self.X7(a_3)],
dim=1)
x = self.proj_last(x * a) * self.scale + shortcut
return x
# MAB
class MAB(nn.Module):
def __init__(
self, n_feats):
super().__init__()
self.LKA = GroupGLKA(n_feats)
self.LFE = SGAB(n_feats)
def forward(self, x, pre_attn=None, RAA=None):
# large kernel attention
x = self.LKA(x)
# local feature extraction
x = self.LFE(x)
return x
class LKAT(nn.Module):
def __init__(self, n_feats):
super().__init__()
# self.norm = LayerNorm(n_feats, data_format='channels_first')
# self.scale = nn.Parameter(torch.zeros((1, n_feats, 1, 1)), requires_grad=True)
self.conv0 = nn.Sequential(
nn.Conv2d(n_feats, n_feats, 1, 1, 0),
nn.GELU())
self.att = nn.Sequential(
nn.Conv2d(n_feats, n_feats, 7, 1, 7 // 2, groups=n_feats),
nn.Conv2d(n_feats, n_feats, 9, stride=1, padding=(9 // 2) * 3, groups=n_feats, dilation=3),
nn.Conv2d(n_feats, n_feats, 1, 1, 0))
self.conv1 = nn.Conv2d(n_feats, n_feats, 1, 1, 0)
def forward(self, x):
x = self.conv0(x)
x = x * self.att(x)
x = self.conv1(x)
return x
class ResGroup(nn.Module):
def __init__(self, n_resblocks, n_feats, res_scale=1.0):
super(ResGroup, self).__init__()
self.body = nn.ModuleList([
MAB(n_feats) \
for _ in range(n_resblocks)])
self.body_t = LKAT(n_feats)
def forward(self, x):
res = x.clone()
for i, block in enumerate(self.body):
res = block(res)
x = self.body_t(res) + x
return x
class MeanShift(nn.Conv2d):
def __init__(
self, rgb_range,
rgb_mean=(0.4488, 0.4371, 0.4040), rgb_std=(1.0, 1.0, 1.0), sign=-1):
super(MeanShift, self).__init__(3, 3, kernel_size=1)
std = torch.Tensor(rgb_std)
self.weight.data = torch.eye(3).view(3, 3, 1, 1) / std.view(3, 1, 1, 1)
self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean) / std
for p in self.parameters():
p.requires_grad = False
@ARCH_REGISTRY.register()
class MAN(nn.Module):
def __init__(self, n_resblocks=36, n_resgroups=1, n_colors=3, n_feats=180, scale=2, res_scale=1.0):
super(MAN, self).__init__()
# res_scale = res_scale
self.n_resgroups = n_resgroups
self.sub_mean = MeanShift(1.0)
self.head = nn.Conv2d(n_colors, n_feats, 3, 1, 1)
# define body module
self.body = nn.ModuleList([
ResGroup(
n_resblocks, n_feats, res_scale=res_scale)
for i in range(n_resgroups)])
if self.n_resgroups > 1:
self.body_t = nn.Conv2d(n_feats, n_feats, 3, 1, 1)
# define tail module
self.tail = nn.Sequential(
nn.Conv2d(n_feats, n_colors * (scale ** 2), 3, 1, 1),
nn.PixelShuffle(scale)
)
self.add_mean = MeanShift(1.0, sign=1)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = x
for i in self.body:
res = i(res)
if self.n_resgroups > 1:
res = self.body_t(res) + x
x = self.tail(res)
x = self.add_mean(x)
return x
def visual_feature(self, x):
fea = []
x = self.head(x)
res = x
for i in self.body:
temp = res
res = i(res)
fea.append(res)
res = self.body_t(res) + x
x = self.tail(res)
return x, fea
def load_state_dict(self, state_dict, strict=False):
own_state = self.state_dict()
for name, param in state_dict.items():
if name in own_state:
if isinstance(param, nn.Parameter):
param = param.data
try:
own_state[name].copy_(param)
except Exception:
if name.find('tail') >= 0:
print('Replace pre-trained upsampler to new one...')
else:
raise RuntimeError('While copying the parameter named {}, '
'whose dimensions in the model are {} and '
'whose dimensions in the checkpoint are {}.'
.format(name, own_state[name].size(), param.size()))
elif strict:
if name.find('tail') == -1:
raise KeyError('unexpected key "{}" in state_dict'
.format(name))
if strict:
missing = set(own_state.keys()) - set(state_dict.keys())
if len(missing) > 0:
raise KeyError('missing keys in state_dict: "{}"'.format(missing))
参考文献:
icandle/MAN: Multi-scale Attention Network for Single Image Super-Resolution (github.com)