文章目录
- GreenPlum详细入门教程
- 第一章 GreenPlum介绍
- 1.MPP架构介绍
- 2.GreenPlum介绍
- 3.GreenPlum数据库架构
- 4.GreenPlum数据库优缺点
- 第二章 GreenPlum单节点安装
- 1.Docker创建centos容器
- 1.1 拉取centos7镜像
- 1.2 创建容器
- 1.3 进入容器
- 1.4 容器和服务器免密操作
- 1.4.1 生成密钥
- 1.4.2 拷贝密钥
- 1.5 安装ssh服务和网络必须应用
- 1.6 容器设置root密码
- 1.6.1 安装passwd应用
- 1.6.2 容器本机root设置密码
- 1.7 容器本机免密
- 2.安装GreenPlum
- 2.1 准备安装包
- 2.2 创建用户及用户组
- 2.3 离线安装
- 2.3.1 检查安装包并yum安装
- 2.3.2 查看安装路径
- 2.3.3 将greenplum目录权限授予gpadmin用户
- 2.3.4 创建数据目录和配置目录
- 2.3.5 切换gpadmin用户
- 2.3.6 查看gpadmin用户环境变量
- 2.3.7 SSH互信设置
- 2.3.8 配置初始化文件
- 2.3.8.1 拷贝文件到配置目录
- 2.3.8.2 创建host文件
- 2.3.8.3 修改初始化文件
- 2.3.9 初始化数据库
- 2.3.10 连接数据库
- 2.3.11 修改密码
- 3.远程连接
- 3.1 开放端口
- 3.2 修改pg_hba.conf
- 3.3 重启greenplum
- 3.3.1 gpstop关闭失败
- 3.3.2 设置MASTER_DATA_DIRECTORY
- 3.4 关闭gp
- 3.5 启动gp
- 3.6 远程连接
- 第三章 GreenPlum系统管理
- 1.关于GreenPlum数据库发布版本号
- 2.启动和停止GreenPlum数据库
- 2.1 启动数据库
- 2.2 重启数据库
- 2.3 仅重新载入配置文件更改
- 2.4 停止GreenPlum数据库
- 2.5 停止客户端进程
- 3.GreenPlum数据库状态查询
- 4.访问GreenPlum数据库
- 4.1 数据库会话参数
- 4.2 支持客户端应用
- 4.3 psql连接
- 4.4 常见的连接问题
- 第四章 GreenPlum数据类型
- 1.基本数据类型
- 1.1 数值类型
- 1.2 字符类型
- 1.3 时间类型
- 2.复杂数据类型
- 2.1 枚举类型
- 2.2 几何类型
- 2.3 网络地址类型
- 2.4 JOSN类型
- 2.5 数组类型
- 2.6 复合类型
- 2.7 位串类型
- 第五章 DDL&DML&DQL
- 1.DDL(Data Definition Language)数据定义语言
- 1.1 创建数据库
- 1.2 查询数据库
- 1.3 删除数据库
- 1.4 创建表
- 1.5 修改表
- 1.6 清除表
- 1.7 删除表
- 2.DML(Data Manipulation Language)数据操作语言
- 2.1 数据导入
- 2.2 数据更新和删除
- 2.3 数据导出
- 3.DQL(Data Query Language)数据查询语言
- 3.1 基础语法及执行顺序
- 3.2 基本查询
- 3.3 分组查询
- 3.4 联合查询
- 3.5 排序
- 第六章 函数
- 1.函数介绍
- 2.单行函数
- 2.1 算术运算符
- 2.2 数值函数
- 2.3 字符串函数
- 2.4 时间函数
- 2.5 流程控制函数
- 3.行列转换函数
- 3.1 行转列函数
- 3.2 列转行函数
- 4.窗口函数
- 4.1 概述
- 4.2 常用窗口函数
- 5.其他函数
GreenPlum详细入门教程
第一章 GreenPlum介绍
1.MPP架构介绍
MPP是Massively Parallel Processing的缩写,也就是大规模并行处理。MPP架构是一种用于处理大规模数据的计算架构,可以通过将任务分配给多个处理单元并行执行,以提高处理速度和性能。MPP架构的由来可以追溯到对大规模数据处理需求,传统的数据库模式无法满足这些需求。MPP架构允许在大规模数据集上实现水平扩展,通过添加更多的处理单元来增加计算和存储能力。
1) 分布式存储:MPP数据库系统通常使用分布式存储架构,将数据分散存储在多个节点。每个节点都有自己的存储单元,这样可以提高数据的读取和写入速度。
2) 并行处理:MPP架构通过将任务分解为小块,并同时在多个处理单元上执行这些任务来实现并行处理。每个处理单元负责处理数据的一个子集,然后将结果合并以生成最终的输出。
3) 共享无状态架构:MPP系统通过采用共享无状态的架构,即每个节点之间没有共享的状态。这使得系统更容易水平扩展,因为可以简单的添加更多的节点,而不需要共享状态的复杂管理。
4) 负载均衡:MPP数据库通常具有负载平衡的机制,确保任务在各个节点上均匀分布,避免某些节点成为性能瓶颈。
5) 高可用性:为了提高系统的可用性,MPP架构通常设计成具有容错和故障恢复机制。如果一个节点出现故障,系统可以继续运行,而不会丢失数据或中断服务。
一些知名的MPP数据库系统,比如GreenPlum,Doris, Teradata、Netezza、Vertica等。这些MPP数据库广泛应用于企业数据仓库、商业智能和大数据分析等领域。总体而言,MPP架构通过将任务分布到多个节点并行执行,以及有效的利用分布式存储和处理方式,提高了一种高性能、可伸缩的数据处理解决方案,适用于处理大规模数据的场景。
2.GreenPlum介绍
GreenPlum数据库是一种大规模并行处理(MPP)数据库服务器,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。
MPP(也被成为shared nothing架构)指有两个或更多处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。GreenPlum使用这种高性能系统架构来分布数据仓库负载,并且能够使用系统的所有资源并行处理一个查询。
GreenPlum数据库是基于PostgreSQL开源技术的。它本质上是多个PostgreSQL面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。它基于PostgreSQL开发,其SQL支持、特性、配置选项和最终用户功能在大部分情况霞和PostGreSQL非常相似。与GreenPlum数据库交互的数据库用户会感觉在使用一个常规的PostgreSQL DBMS。
GreenPlum数据库可以使用追加优化(append-optimized,AO)的存储格式来批量装载和读取数据,并且能够提供HEAP表上的性能优势。追加优化的存储为数据保护、压缩和行/列方向提供了校验和。行式或者列式追加优化的表都可以被压缩。
GreenPlum数据库和PostgreSQL的主要区别在于:
1)在基于Postgres查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。
2)GreenPlum数据库可以使用追加优化的存储。
3)GreenPlum数据库可以选用列式存储,数据在逻辑上还是组织成一个表,单其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。所有压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。GreenPlum数据库在所有使用列式存储的追加优化表上都提供了压缩。
3.GreenPlum数据库架构

GreenPlum数据库是由Master Server、Segment Server和Interconnect三部分组成,Interconnect在Master和Segment之间起到了桥梁的作用。
GreenPlum是一个关系型数据库,由数个独立的数据服务组成的逻辑数据库,整个集群由多个数据节点(Segment)和控制节点(Master)组成。在典型的Shared-Nothing中,每个节点上所有的资源的CPU、内存、磁盘都是独立的,每个节点都只有全部数据的一部分,也只能使用本节点的数据资源。在GreenPlum中,需要存储的数据在进入到表时,将先进行数据分布的处理工作,将一个表中的数据平均分布到每个节点上,并未每个表指定一个分布列(Distribute Column),之后便根据Hash来分布数据,基于Shared-Nothing的原则,GreenPlum这样处理可以充分发挥每个节点处IO的处理能力。
1)Master节点:Master是整个系统的控制中心和堆外的服务接入点,它负责接收用户SQL请求,将SQL生成查询计划并进行处理优化,然后将查询计划分配到所有Segment节点并进行处理,协调组织各Segment节点按照查询计划一步一步的进行并行处理,最后获取到Segment的计算结果,再返回给客户端。从用户的角度看GreenPlum集群,看到的只是Master节点,无需关心集群内部的机制,所有的并行处理都是在Master控制下自动完成的。Master节点一般配备一个Standby节点。
2)Segment节点:Segment是GreenPlum执行并行任务的并行计算节点,它接收Master指令进行MPP并行计算,因此所有Segment节点的计算性能总和就是整个集群的性能,通过增加Segment节点,可以线性化的增加集群处理性能和存储容量,Segment节点可以是1-10000个节点。
3)InterConnect:InterConnect是Master节点和Segment节点、Segment节点之间进行数据传输的组件,基于千兆交换机或者万兆交换机实现数据在节点之间的高速传输。
外部数据在加载到Segment时,采用并行数据流进行加载,直接加载到Segment节点,这项独特的技术是GreenPlum的专有技术,保证数据在最短时间内加载到数据库中。
4.GreenPlum数据库优缺点
1)优点
1.1)数据存储:数据激增,采用MPP架构的数据库系统可以对海量数据进行管理。
1.2)高并发:拥有强大并行处理能力提供并发支持。
1.3)线性扩展:线性扩展为数据分析系统的扩展提供技术上的保证,用户可根据实际实施需要进行容量和性能的扩展。
1.4)高性价比:基于业界开放式硬件平台,在普通的x86 server上就能达到很高的性能,因此性价比很高。
1.5)处理速度:GreenPlum通过准实时、实时的数据加载方式,实现数据仓库的实时更新,进而实现动态数据仓库。
1.6)高可用性:对于主节点,GreenPlum提供Master/Standby机制进行主节点容错,当主节点发生错误时,可以切换到Standby节点继续服务。
1.7)系统易用:GreenPlum产品是基于流行的PostgreSQL之上开发,几乎所有的PostgreSQL客户端工具及PostgreSQL应用都能运行在GreenPlum平台上,在Internet上有丰富的资源支持。
2)缺点
2.1):主从双层架构,并非真正的扁平架构,存在性能瓶颈和SPOF单点故障。
2.2):无法支持数据压缩态下的DML操作,不易于数据的维护和更新。
2.3):单个节点上的数据库没有并行和大内存实用能力,必须通过部署多个实例(segmenr server)来充分利用系统资源,造成使用和部署很复杂。
第二章 GreenPlum单节点安装
如果有充分的资源,可以做分布式安装GreenPlum。如果资源不足,可以做单节点安装,同样可以用来熟悉GreenPlum语法。本章计划使用Docker创建一个Centos7的镜像,并在Centos7中安装GreenPlum。如果不打算使用Docker的话,可以直接从第二步安装GreenPlum开始。
《Docker系列》Docker安装、运维教程
1.Docker创建centos容器
1.1 拉取centos7镜像
docker pull centos:7
[root@zxy ~]# docker pull centos:7
[root@zxy ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
centos 7 eeb6ee3f44bd 18 months ago 204MB
1.2 创建容器
外部端口6002映射容器内部ssh端口22
外部端口5432映射内部端口5432
外部端口6000映射内部端口6000
外部端口6001映射内部端口6001
[root@zxy ~]# docker run -itd --name gp-docker01 \
> -p 6002:22 \
> -p 5432:5432 \
> -p 6000:6000 \
> -p 6001:6001 \
> --privileged eeb6ee3f44bd \
> /usr/sbin/init
b0c0fe56c04889c3d22aed9f422e16647030517b97f787095b70a8bf84f757a4
1.3 进入容器
[root@zxy ~]# docker exec -it b0c0fe56c048 /bin/bash
[root@b0c0fe56c048 /]#
1.4 容器和服务器免密操作
1.4.1 生成密钥
如果在执行ssh-keygen的时候,找不到该命令,那么使用yum安装openssh即可
bash: ssh-keygen: command not found
# 1.ssh-keygen失败
[root@b0c0fe56c048 /]# ssh-keygen
bash: ssh-keygen: command not found
# 2.安装openssh
[root@b0c0fe56c048 /]# yum install openssh
# 3.再次进行生成密钥操作,不用输入,直接点击enter键即可
[root@b0c0fe56c048 /]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
......
1.4.2 拷贝密钥
如果在执行ssh-copy-id失败的话,使用yum手动安装openssh-clients即可
bash: ssh-copy-id: command not found
# 1.拷贝失败
[root@b0c0fe56c048 /]# ssh-copy-id 125.22.95.188
bash: ssh-copy-id: command not found
# 2.安装openssh-clients
[root@b0c0fe56c048 /]# yum install openssh-clients
# 3.再次拷贝,进行免密
[root@b0c0fe56c048 /]# ssh-copy-id 125.22.95.188
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '125.22.95.188 (125.22.95.188)' can't be established.
ECDSA key fingerprint is SHA256:uvxqg9O/HlNw5Y3FNToE/llF8GeZQy/p+GXlIS3N6cY.
ECDSA key fingerprint is MD5:d4:15:a9:ea:f9:26:8f:2f:b4:dd:8a:42:3b:58:29:3b.
Are you sure you want to continue connecting (yes/no)? yes
.....
1.5 安装ssh服务和网络必须应用
[root@b0c0fe56c048 /]# yum -y install net-tools.x86_64
[root@b0c0fe56c048 /]# yum -y install openssh-server
[root@b0c0fe56c048 /]# systemctl restart sshd
1.6 容器设置root密码
1.6.1 安装passwd应用
安装passwd应用,可以给容器的用户设置密码,方便对本机进行免密操作
[root@b0c0fe56c048 /]# yum -y install passwd
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: ftp.sjtu.edu.cn
* extras: ftp.sjtu.edu.cn
* updates: ftp.sjtu.edu.cn
Package passwd-0.79-6.el7.x86_64 already installed and latest version
Nothing to do
1.6.2 容器本机root设置密码
[root@b0c0fe56c048 /]# passwd root
Changing password for user root.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
1.7 容器本机免密
[root@b0c0fe56c048 /]# ssh-copy-id localhost
...
Are you sure you want to continue connecting (yes/no)? yes
...
root@localhost's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'localhost'"
and check to make sure that only the key(s) you wanted were added.
2.安装GreenPlum
2.1 准备安装包
[root@zxy ~]# docker cp /zxy/software/greenplum-db-6.4.0-rhel6-x86_64.rpm b0c0fe56c048:/
2.2 创建用户及用户组
[root@b0c0fe56c048 /]# groupadd gpadmin
[root@b0c0fe56c048 /]# useradd gpadmin -g gpadmin
[root@b0c0fe56c048 /]# passwd gpadmin
2.3 离线安装
2.3.1 检查安装包并yum安装
安装包
官网
官方推荐使用yum的方式安装,yum安装的饿好处是,会自动帮我们下载安装依赖包。默认将greenplum软件安装到/usr/local目录下,并创建软连接。但是如果不能自动联网下载就会比较麻烦。
[root@b0c0fe56c048 /]# ls | grep greenplum
greenplum-db-6.4.0-rhel6-x86_64.rpm
[root@b0c0fe56c048 /]# yum install localhost greenplum-db-6.4.0-rhel6-x86_64.rpm
2.3.2 查看安装路径
[root@b0c0fe56c048 /]# ll /usr/local/ | grep greenplum
lrwxrwxrwx 1 root root 29 Mar 22 02:29 greenplum-db -> /usr/local/greenplum-db-6.4.0
drwxr-xr-x 12 root root 4096 Mar 22 02:29 greenplum-db-6.4.0
2.3.3 将greenplum目录权限授予gpadmin用户
[root@b0c0fe56c048 /]# chown -Rf gpadmin:gpadmin /usr/local/greenplum*
[root@b0c0fe56c048 /]# ll /usr/local/ | grep greenplum
lrwxrwxrwx 1 gpadmin gpadmin 29 Mar 22 02:29 greenplum-db -> /usr/local/greenplum-db-6.4.0
drwxr-xr-x 12 gpadmin gpadmin 4096 Mar 22 02:29 greenplum-db-6.4.0
2.3.4 创建数据目录和配置目录
创建数据目录gpdata有master和primary等节点
创建配置目录gpconfigs
[root@b0c0fe56c048 /]# mkdir -p /data/gpdata/master
[root@b0c0fe56c048 /]# mkdir -p /data/gpdata/primary
[root@b0c0fe56c048 /]# mkdir -p /data/gpconfigs
[root@b0c0fe56c048 /]# chown -Rf gpadmin:gpadmin /data/
2.3.5 切换gpadmin用户
[root@b0c0fe56c048 /]# su gpadmin
2.3.6 查看gpadmin用户环境变量
在~/.bashrc文件中添加source /usr/local/greenplum-db/greenplum_path.sh
这样在root用户下修改了环境后,一旦切换到gpadmin用户,会自动加载。
后续还有其他变量需要添加时,也添加在该文件中
[gpadmin@b0c0fe56c048 /]$ cat ~/.bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# Uncomment the following line if you don't like systemctl's auto-paging feature:
# export SYSTEMD_PAGER=
# User specific aliases and functions
source /usr/local/greenplum-db/greenplum_path.sh
刚修改好,可以手动source一下。source ~/.bashrc
2.3.7 SSH互信设置
[gpadmin@b0c0fe56c048 /]$ gpssh-exkeys -h b0c0fe56c048
[STEP 1 of 5] create local ID and authorize on local host
[STEP 2 of 5] keyscan all hosts and update known_hosts file
[STEP 3 of 5] retrieving credentials from remote hosts
[STEP 4 of 5] determine common authentication file content
[STEP 5 of 5] copy authentication files to all remote hosts
[INFO] completed successfully
2.3.8 配置初始化文件
2.3.8.1 拷贝文件到配置目录
[gpadmin@b0c0fe56c048 /]$ cp /usr/local/greenplum-db/docs/cli_help/gpconfigs/gpinitsystem_config /data/gpconfigs/
2.3.8.2 创建host文件
[gpadmin@b0c0fe56c048 /]$ touch /data/gpconfigs/hostfile
[gpadmin@b0c0fe56c048 /]$ echo "b0c0fe56c048" > /data/gpconfigs/hostfile
2.3.8.3 修改初始化文件
主要关注master和segment的目录,主机名和数据库端口
[gpadmin@b0c0fe56c048 /]$ vi /data/gpconfigs/gpinitsystem_config
[gpadmin@b0c0fe56c048 /]$ cat /data/gpconfigs/gpinitsystem_config
# FILE NAME: gpinitsystem_config
# Configuration file needed by the gpinitsystem
################################################
#### REQUIRED PARAMETERS
################################################
#### Name of this Greenplum system enclosed in quotes.
ARRAY_NAME="Greenplum Data Platform"
#### Naming convention for utility-generated data directories.
SEG_PREFIX=gpseg
#### Base number by which primary segment port numbers
#### are calculated.
PORT_BASE=6000
#### File system location(s) where primary segment data directories
#### will be created. The number of locations in the list dictate
#### the number of primary segments that will get created per
#### physical host (if multiple addresses for a host are listed in
#### the hostfile, the number of segments will be spread evenly across
#### the specified interface addresses).
declare -a DATA_DIRECTORY=(/data/gpdata/primary /data/gpdata/primary)
#### OS-configured hostname or IP address of the master host.
MASTER_HOSTNAME=b0c0fe56c048
#### File system location where the master data directory
#### will be created.
MASTER_DIRECTORY=/data/gpdata/master
#### Port number for the master instance.
MASTER_PORT=5432
#### Shell utility used to connect to remote hosts.
TRUSTED_SHELL=ssh
#### Maximum log file segments between automatic WAL checkpoints.
CHECK_POINT_SEGMENTS=8
#### Default server-side character set encoding.
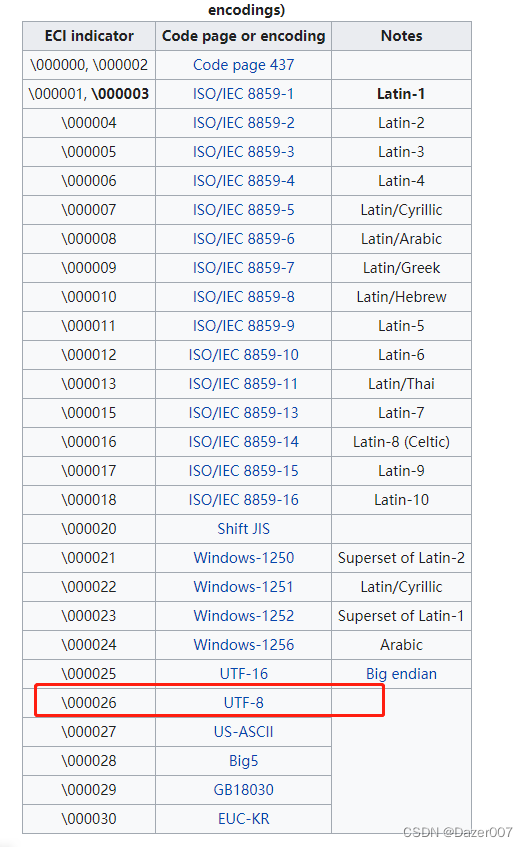
ENCODING=UNICODE
2.3.9 初始化数据库
[gpadmin@b0c0fe56c048 /]$ gpinitsystem -c /data/gpconfigs/gpinitsystem_config -h /data/gpconfigs/hostfile
2.3.10 连接数据库
[gpadmin@b0c0fe56c048 /]$ psql -p 5432 -d postgres
psql (9.4.24)
Type "help" for help.
2.3.11 修改密码
[gpadmin@b0c0fe56c048 /]$ psql -p 5432 -d postgres
psql (9.4.24)
Type "help" for help.
postgres=# \password gpadmin
Enter new password:
Enter it again:
3.远程连接
3.1 开放端口
通过指令查询任务进程,以及端口。
容器的6000,6001,5432,分别对应服务器的6000,6001,5432端口,主要开放5432端口允许外部访问即可
[gpadmin@b0c0fe56c048 /]$ ps -ef | grep greenplum
gpadmin 3560 1 0 02:39 ? 00:00:00 /usr/local/greenplum-db-6.4.0/bin/postgres -D /data/gpdata/primary/gpseg0 -p 6000
gpadmin 3561 1 0 02:39 ? 00:00:00 /usr/local/greenplum-db-6.4.0/bin/postgres -D /data/gpdata/primary/gpseg1 -p 6001
gpadmin 3582 0 0 02:39 ? 00:00:00 /usr/local/greenplum-db-6.4.0/bin/postgres -D /data/gpdata/master/gpseg-1 -p 5432 -E
gpadmin 3725 405 0 02:43 pts/1 00:00:00 grep --color=auto greenplum
3.2 修改pg_hba.conf
#添加如下一行即可,所有用户,所有IP均可访问
#生产环境中可自行选择配置
[gpadmin@b0c0fe56c048 /]$ vi /data/gpdata/master/gpseg-1/pg_hba.conf
host all all all trust
3.3 重启greenplum
3.3.1 gpstop关闭失败
20230322:02:45:30:003728 gpstop:b0c0fe56c048:gpadmin-[CRITICAL]:-gpstop failed. (Reason='Environment Variable MASTER_DATA_DIRECTORY not set!') exiting...
在使用gpstop的时候,提示关闭失败,提示你设置MASTER_DATA_DIRECTORY
[gpadmin@b0c0fe56c048 /]$ gpstop
20230322:02:45:30:003728 gpstop:b0c0fe56c048:gpadmin-[INFO]:-Starting gpstop with args:
20230322:02:45:30:003728 gpstop:b0c0fe56c048:gpadmin-[INFO]:-Gathering information and validating the environment...
20230322:02:45:30:003728 gpstop:b0c0fe56c048:gpadmin-[CRITICAL]:-gpstop failed. (Reason='Environment Variable MASTER_DATA_DIRECTORY not set!') exiting...
3.3.2 设置MASTER_DATA_DIRECTORY
在~/.bashrc文件中添加如下两行记录即可
[gpadmin@b0c0fe56c048 /]$ vi ~/.bashrc
MASTER_DATA_DIRECTORY=/data/gpdata/master/gpseg-1
export MASTER_DATA_DIRECTORY
[gpadmin@b0c0fe56c048 /]$ source ~/.bashrc
3.4 关闭gp
[gpadmin@b0c0fe56c048 /]$ gpstop
.....
20230322:02:46:57:003750 gpstop:b0c0fe56c048:gpadmin-[INFO]:-Cleaning up leftover shared memory
3.5 启动gp
[gpadmin@b0c0fe56c048 /]$ gpstart
......
20230322:02:47:21:003933 gpstart:b0c0fe56c048:gpadmin-[INFO]:-Database successfully started
3.6 远程连接
Dbeaver使用GreenPlum驱动连接数据库

第三章 GreenPlum系统管理
1.关于GreenPlum数据库发布版本号
GreenPlum的版本号和其组织方式的改变,界定了从一个版本到下一个版本做了哪些修改。
GreenPlum数据库的发布版本号采用格式:x.y.z,含义为:
-
x表示主版本号
-
y表示小版本号
-
z表示补丁版本号
1)具有相同主版本号的GP数据库保证在该版本下具有向后兼容性;2)当GP数据库的元数据目录修改或不适配的特性改变出现或新特性被引入时,才会增加主版本号;3)之前版本中被注释掉的功能在新的主版本发布时可能被移除;4)当出现向后兼容的问题修复时,GP数据库会在某一小版本号的基础上增加补丁版本号;
2.启动和停止GreenPlum数据库
在一个GreenPlum数据库管理系统中,所有主机上的数据库实例(Master和所有的Sgement)一起被启动或停止,启停操作统一由Master实例发起,它们步调一致,在外界看来是一个完成的数据库管理系统。
由于常规的GreenPlum数据库系统分布在很多的机器上,启停与普通的PostgreSQL略有不同。需要分别使用GreenPlum的Master节点&GPHOME/bin目录下的gpstart和gpstop实现。
注意:不要使用kill命令来关闭任何后台的数据库进程,可能会损坏数据库且不利于数据库问题分析。可以使用数据库内的命令pg_cancel_backend()来处理
2.1 启动数据库
在Master实例上,通过执行gpstart可以启动一个初始化好的GreenPlum数据库系统。前提是该数据库系统已经被gpstop工具停止。gpstart通过启动整个GreenPlum数据库集群中的所有Postgres数据库实例来启动GreenPlum数据库。gpstart会精心安排这一过程并且以并行的方式执行。
$ gpstart
2.2 重启数据库
停止GreenPlum数据库系统然后重启。执行gpstop工具并带有-r选项,会停止GreenPlum数据库并在数据库完全关闭后重新启动它。
$ gpstop -r
2.3 仅重新载入配置文件更改
重新载入对GreenPlum数据库配置文件更改而不中断系统。gpstop工具可以在不中断服务的前提下重新载入对pg_hba.conf配置文件和Master上postgresql.conf、pg_hba.conf文件中运行参数进行更改。
$ gpstop -u
2.4 停止GreenPlum数据库
gpstop工具可以停止或者重启GreenPlum数据库系统,它总是运行在Master主机上。当被激活时,gpstop会停止系统中所有的postgres进程,包括Master和所有Segment实例。
-
常规停止GreenPlum数据库
$ gpstop -
快速模式停止GreenPlum数据库
$ gpstop -M fast
默认情况下,如果有任何客户端连接存在,就不允许关闭GreenPlum数据库。使用-M fast选项可以在关闭前回滚所有正在进行中的事务并且中断所有连接。
2.5 停止客户端进程
GreenPlum数据库会为每个客户端连接唤起一个后台进程。具有superuser权限的用户可以取消或直接终止这些客户端进程。使用pg_cancel_backend()函数可以取消某个活动查询或队列中的后台进程;使用pg_terminate_backend()函数可以直接终断GreenPlum数据库的客户端连接。
pg_cancel_backend()函数有两种表现形式:
pg_cancel_backend(pid int4)pg_cancel_backend(pid int4, msg text)
pg_terminate_backend()函数有两种表现形式:
pg_terminate_backend(pid int4)pg_terminate_backend(pid int4, msg text)
如果提供了msg信息,GreenPlum数据库会将取消的msg内容一并返回给客户端。msg最大为128字节;任何超出该长度的信息都会被GreenPlum数据库直接截断。执行成功返回true,否则返回false。
1)pg_stat_activity查询后台进程
查询到的结果中,可以根据pid取消进程

2)取消后台进程
如下所示,取消进程并返回msg提示客户端
postgres=# select pg_cancel_backend(28743,'admin cancel the query');
ERROR: canceling statement due to user request: "admin cancel the query"
3.GreenPlum数据库状态查询
gpstate :显示数据库运行状态,详细配置等信息
该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
- -c:primary instance 和 mirror instance 的对应关系
- -m:只列出mirror 实例的状态和配置信息
- -f:显示standby master 的详细信息
- -Q:显示状态综合信息
4.访问GreenPlum数据库
4.1 数据库会话参数
用户可以通过使用一种PostgreSQL兼容的客户端程序连接到GreenPlum数据库,例如psql。用户和管理员总是通过master连接到GreenPlum数据库,Segment不能接受客户端连接。
为了建立一个到GreenPlum数据库Master的连接,用户将需要知道下列连接信息并且相应的配置用户的客户端程序。
| 连接参数 | 描述 | 环境变量 |
|---|---|---|
| 应用名称 | 连接数据库的应用名称,保存在application_name连接参数中,默认psql。 | $PGAPPNAME |
| 数据库名 | 用户想要连接数据库的名称,初始化系统,第一次可使用postgres数据库连接。 | $PGDATABASE |
| 主机名 | GreenPlum数据库Master主机名,默认是本地主机。 | $PGHOST |
| 端口 | GreenPlum数据库Master实力端口号,默认是5432。 | $PGPORT |
| 用户名 | 连接用户的数据库用户。 | $PGUSER |
4.2 支持客户端应用
用户可以使用多种客户端连接到数据库:
1)用户的GreenPlum安装中已经提供了一些GreenPlum数据库客户端应用psql客户端应用提供了一种对GreenPlum数据库的交互式命令行接口。
2)使用标准的数据库应用接口,如ODBC和JDBC,用户可以创建他们自己的客户端来连接到GreenPlum数据库。因为GreenPlum数据库基于PostgreSQL开发,所以它使用标准的PostgreSQL数据库驱动。
3)大部分使用ODBC和JDBC等标准数据库接口的客户端工具都可以被配置来连接到GreenPlum数据库。
4.3 psql连接
如果是刚安装的数据库,可以连接到Postgres数据库来访问系统,例如:
[gpadmin@b0c0fe56c048 /]$ psql postgres
psql (9.4.24)
Type "help" for help.
postgres=#
-
psql
[gpadmin@b0c0fe56c048 /]$ psql psql (9.4.24) Type "help" for help. postgres=# -
psql database
[gpadmin@b0c0fe56c048 /]$ psql zxy psql (9.4.24) Type "help" for help. zxy=# -
psql -d database -h host -p port -U user
[gpadmin@b0c0fe56c048 /]$ psql -d zxy -h localhost -p 5432 -U gpadmin psql (9.4.24) Type "help" for help. zxy=#
4.4 常见的连接问题
1)没有用于主机或者用户的pg_hba.conf配置
要允许GreenPlum数据库接受远程客户端连接,用户需配置用户的GreenPlum数据库的Master实例,这样主机客户端和数据库用户连接才会被连接到GreenPlum数据库。可以通过pg_hba.conf配置文件中增加合适的条目。
2)GreenPlum数据库没有运行
GreennPlum数据库的Master实例没有运行,用户将无法连接。用户可以通过在GreenPlum的Master主机上运行gpstate工具来验证GreenPlum数据库系统是否正常运行。
3)网络问题Interconnect超时
如果用户从一个远程客户端连接到GreenPlum的Master主机,网络问题可能阻止连接。为了确认网络问题等原因,可以尝试从远程客户端连接到GreenPlum的Master主机。
4)有太多客户端连接
默认情况下,GreenPlum数据库被配置在Master和每个Segement上分别最多250和750个并发用户连接。导致该限制会被超过的连接尝试将被拒绝。这个限制由GreenPlum数据库Master的postgresql.conf配置文件中的max_connections参数控制。如果用户为master更改了这个设置,用户还必须在Segment上做出适当的更改。
第四章 GreenPlum数据类型
1.基本数据类型
1.1 数值类型
| 类型名称 | 存储空间 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2字节 | 小范围整数 | -32768 ~ 32767 |
| integer | 4字节 | 常用的整数 | -2147483648~+2147483647 |
| bigint | 8字节 | 大范围的整数 | -9223372036 854 ~9223372036854 |
| decimal | 变长 | 用户声明精度,精确 | 无限制 |
| numeric | 变长 | 用户声明精度,精确 | 无限制 |
| real | 4字节 | 变精度,不精确 | 6位十进制数字精度 |
| double precision | 8字节 | 变精度,不精确 | 15位十进制数字精度 |
| serial | 4字节 | 自增整数 | 1 - 2147483 647 |
| bigserial | 8字节 | 大范围的自增整数 | 1 - 9223372036854775807 |
| smallserial | 字节 | 小范围的自增整数 | 1 - 32767 |
1.2 字符类型
| 类型名称 | 描述 |
|---|---|
| character varying(n),varchar(n) | 变长,有长度限制 |
| character(n),char(n) | 定长,不足补空白 |
| text | 变长,无长度限制 |
1.3 时间类型
| 类型名称 | 存储空间 | 描述 | 最低值 | 最高值 | 时间精度 |
|---|---|---|---|---|---|
| timestamp[§][without time zone] | 8字节 | 日期和时间 | 4713BC | 5874897AD | 1毫秒 |
| timestamp[§] with time zone | 8字节 | 日期和时间,带时区 | 4713BC | 5874897AD | 1毫秒 |
| interval[§] | 12字节 | 时间间隔 | -178 000 000年 | 178 000 000年 | 1毫秒 |
| date | 4字节 | 只用于表示日期 | 4713BC | 5 874 897AD | 1天 |
| time[§][without time zone] | 8字节 | 只用于表示一日内的时间 | 00:00:00 | 24:00:00 | 1毫秒 |
| time[§] with time zone | 12字节 | 只用于表示一日内时间,带时区 | 00:00:00+1459 | 24:00:00-1459 | 1毫秒 |
2.复杂数据类型
2.1 枚举类型
枚举类型是一个包含静态和值的有序集合的数据类型,类似于Java中的enum类型,需要使用create type命令创建。
1)创建枚举类型
zxy=# create type ods.enumtype as enum('Mon','Tue','Wed','Thu','Fri','Sat','Sun');
CREATE TYPE
2)创建表引用枚举
zxy=# create table ods.enum_table(
zxy(# id int,
zxy(# week ods.enumtype
zxy(# );
3)插入数据
zxy=# insert into ods.enum_table values(1,'Mon');
INSERT 0 1
4)查询数据
zxy=# select * from ods.enum_table;
id | week
----+------
1 | Mon
(1 row)
2.2 几何类型
几何类型标识二维的平面物体,如下列出GreenPlum支持的几何类型:
| 类型 | 大小 | 描述 | 表现形式 |
|---|---|---|---|
| point | 16字节 | 平面中的点 | (x,y) |
| line | 32字节 | 直线 | ((x1,y1),(x2,y2)) |
| lseg | 32字节 | 线段 | ((x1,y1),(x2,y2)) |
| box | 32字节 | 矩形 | ((x1,y1),(x2,y2)) |
| path | 16+16n字节 | 路径(与多边形相似) | ((x1,y1),…) |
| polygon | 40+16n字节 | 多边形 | ((x1,y1),…) |
| circle | 24字节 | 圆 | <(x,y),r> (圆心和半径) |
1)创建表,存储点
zxy=# create table ods.point_table(
zxy(# id serial primary key,
zxy(# point1 point
zxy(# );
CREATE TABLE
2)插入数据
zxy=# insert into ods.point_table(point1) values(point(1,2));
INSERT 0 1
3)查询数据
zxy=# select * from ods.point_table;
id | point1
----+--------
1 | (1,2)
(1 row)
2.3 网络地址类型
GreenPlum提供用户存储IPV4、IPV6、MAC地址的数据类型。用这些数据类型存储网络地址比用纯文本好,因为提供输入错误检查和特殊的操作和功能。
| 类型 | 描述 | 说明 |
|---|---|---|
| cidr | 7或19字节 | IPv4 或 IPv6 网络 |
| inet | 7或19字节 | IPv4 或 IPv6 主机和网络 |
| macaddr | 6字节 | MAC 地址 |
1)创建表,存储网络地址
zxy=# create table ods.network_table (
zxy(# id serial primary key,
zxy(# network cidr,
zxy(# ipaddress inet,
zxy(# macaddress macaddr
zxy(# );
CREATE TABLE
2)插入数据
zxy=# insert into ods.network_table(network,ipaddress,macaddress) values('192.168.1.1','192.168.1.0/24','07:01:2b:03:02:03');
INSERT 0 1
3)查询数据
zxy=# select * from ods.network_table;
id | network | ipaddress | macaddress
----+----------------+----------------+-------------------
1 | 192.168.1.1/32 | 192.168.1.0/24 | 07:01:2b:03:02:03
2.4 JOSN类型
json数据类型可以用来JSON(JavaScript Object Notation)数据,这样的数据也可以存储为text,但是json数据类型更有利于检查每个存储的数值是可用的JSON值。
1)创建表,存储Json数据
zxy=# create table ods.json_table(
zxy(# id serial primary key,
zxy(# data json
zxy(# );
CREATE TABLE
2)插入Json数据
zxy=# insert into ods.json_table(data) values('{"name":"zxy","age":18,"city":"SH"}');
INSERT 0 1
3)查询数据
zxy=# select * from ods.json_table;
id | data
----+-------------------------------------
1 | {"name":"zxy","age":18,"city":"SH"}
(1 row)
4)提取json数据
zxy=# select data ->>'name' as name from ods.json_table;
name
------
zxy
(1 row)
2.5 数组类型
GreenPlum允许将字段定义成变长的多为的数组,数组可以是任何基本类型或用户定义类型,枚举类型或复合类型。
1)创建表,存储数组
zxy=# create table ods.array_table(
zxy(# id serial primary key,
zxy(# numbers int[]
zxy(# );
CREATE TABLE
2)向数组中插入数据,数组使用{},使用逗号分隔
zxy=# insert into ods.array_table(numbers) values ('{1,2,3,4,5}');
INSERT 0 1
3)查询数据
zxy=# select * from ods.array_table;
id | numbers
----+-------------
1 | {1,2,3,4,5}
(1 row)
4)根据数组下标取数组数据
zxy=# select numbers[1] from ods.array_table;
numbers
---------
1
(1 row)
5)使用unnest函数展开数组列
zxy=# select unnest(numbers) from ods.array_table;
unnest
--------
1
2
3
4
5
(5 rows)
2.6 复合类型
复合类型表示一行或者一条记录的结构;它实际上只是一个字段名和他们的数据类型的列表。GreenPlum允许像简单数据类型那样使用复合类型。比如,一个表的某个字段可以声明为一个复合类型。
定义复合类型,语法类似于create table,只是这里可以声明字段名字和类型。
1)创建一个复合类型表
zxy=# create table ods.complex_type(
zxy(# name text,
zxy(# age int,
zxy(# city text
zxy(# );
CREATE TABLE
2)创建表,存储复合类型
zxy=# create table ods.complex_table(
zxy(# id serial primary key,
zxy(# complex_column ods.complex_type
zxy(# );
CREATE TABLE
3)插入复合数据
zxy=# insert into ods.complex_table(complex_column) values (ROW('zxy',18,'SH'));
INSERT 0 1
4)查询数据
zxy=# select * from ods.complex_table;
id | complex_column
----+----------------
1 | (zxy,18,SH)
(1 row)
2.7 位串类型
位串是1和0的字符串。可用于存储和可视化掩码。有两种SQL位类型,【bit(n)】、【bit varying(n)】。
bit类型数据必须与长度n完全匹配;尝试存储较短或者较长的位串都是错误的。
bit varying类型数据是可变长度的,直到最大长度n;较长的字符串将被拒接,没有指定长度的bit,将被认为等同于Bit(1)。而bit varying没有指定长度,就被认为是无限长。
1)创建表,存储位串类型
zxy=# create table ods.bit_table(
zxy(# a bit(3),
zxy(# b bit varying(5)
zxy(# );
CREATE TABLE
2)插入数据
# 插入字段a大小为3,符合条件
# 插入字段b大小为3,符合条件
zxy=# insert into ods.bit_table values(B'100',B'100');
INSERT 0 1
# 插入字段a大小为2,不符合条件
# 插入字段b大小为3,符合条件
zxy=# insert into ods.bit_table values(B'10',B'100');
ERROR: bit string length 2 does not match type bit(3)
# 插入字段a大小为3,符合条件
# 插入字段b大小为6,不符合条件
zxy=# insert into ods.bit_table values(B'100',B'100000');
ERROR: bit string too long for type bit varying(5)
第五章 DDL&DML&DQL
1.DDL(Data Definition Language)数据定义语言
1.1 创建数据库
1)语法
CREATE DATABASE name [ [WITH] [OWNER [=] dbowner]
[TEMPLATE [=] template]
[ENCODING [=] encoding]
[TABLESPAC [=] tablespace]
[CONNECTIONE LIMIT [=] connlimit ] ]
-
CREATE DATABASE name;
CREATE DATABASE是SQL命令,用于创建一个新的数据库。
name是自定义的数据库名称。这个名称是必须要填写的,而且在当前数据库服务器上必须是唯一的。
-
[WITH] [OWNER [=] dbowner]
这是一个可选项。OWNER指定了新数据库的所有者。如果未指定,新数据库的所有者默认是执行该命令的用户。
dbowner是数据库所有者的用户名。
-
[TEMPLATE [=] template]
这是一个可选项。TEMPLATE指定了用户创建新数据库的模板。在PostgreSQL和GreenPlum中,通常有一个名为template1的默认模板。如果不指定,就会使用这个默认模板。
template是模板数据库的名称。
-
[ENCODING [=] encoding]
ENCODING指定了新数据库的字符编码。这个设置决定了数据库可以存储哪些字符。
encoding是字符编码的名称,例如UTF8
-
[TABLESPAC [=] tablespace]
这是可选项。TABLSPACE指定了新数据库的存储位置。表空间是数据库中存储文件的物理位置。
tablespace是表空间名称。
-
[CONNECTIONE LIMIT [=] connlimit ]
这是可选项。
CONNECTON LIMIT限制了可以同时连接到数据库的最大客户端数量。
connlimit是允许的最大连接数。如果设置为-1,则表示没有限制。
2)创建一个数据库
create database gpdb
with owner gpadmin
encoding 'utf-8'
tablespace pg_default
connection limit 10;
postgres=# create database gpdb
postgres-# with owner gpadmin
postgres-# encoding 'utf-8'
postgres-# tablespace pg_default
postgres-# connection limit 10;
CREATE DATABASE
3)创建schema
schema本质上就是一个分组管理工具,它允许您将相关性质或类型的多个表和其他数据库对象(如试图、索引、存储过程等)组织在一起。也可以把schema看作是数据库内部一个"文件夹"或"命名空间",用于逻辑上组织和隔离数据,以实现更好数据管理和安全控制。
一个database下可以有多个schema。schema在gp中也叫做namespace。
- 1.连接创建完成的数据库
\c gpdb - 2.创建schema
create schema ods;
postgres=# \c gpdb
You are now connected to database "gpdb" as user "gpadmin".
gpdb=# create schema ods;
CREATE SCHEMA
1.2 查询数据库
1)切换当前数据库
-
数据库服务器命令行操作\c gpdb
postgres=# \c gpdb You are now connected to database "gpdb" as user "gpadmin".
2)显示数据库
-
数据库服务器命令行操作查看所有数据库:\l
查看所有schema:\dngpdb=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+---------+----------+------------+------------+--------------------- gpdb | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | gpperfmon | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | postgres | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | template0 | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | =c/gpadmin + | | | | | gpadmin=CTc/gpadmin template1 | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | =c/gpadmin + | | | | | gpadmin=CTc/gpadmin zxy | gpadmin | UTF8 | en_US.utf8 | en_US.utf8 | (6 rows) gpdb=# \dn List of schemas Name | Owner ------------+--------- gp_toolkit | gpadmin ods | gpadmin public | gpadmin (3 rows) -
SQL查询操作查看所有数据库:select datname from pg_database;
查看所有schema:select schema_name from information_schema.schemata;gpdb=# select datname from pg_database; datname ----------- template1 template0 postgres gpperfmon zxy gpdb (6 rows) gpdb=# select schema_name from information_schema.schemata; schema_name -------------------- pg_toast pg_aoseg pg_bitmapindex pg_catalog public information_schema gp_toolkit ods (8 rows)
1.3 删除数据库
drop database会删除数据库的系统的目录并且删除包含数据的文件目录。可以使用if exists判断数据库是否存在,存在则删除;
drop database if exists yyds
1.4 创建表
1)创建语法说明
CREATE [EXTERNAL] TABLE table_name(
column1 datatype [NOT NULL] [DEFAULT] [CHECK] [UNIQUE],
column2 datatype,
.....
columnN datatype,
[PRIMARY KEY()]
)[ WITH ()]
[LOCATION()]
[FORMAT]
[COMMENT]
[PARTITION BY]
[DISTRIBUTE BY ()];
-
create table
创建一个指定名字的表,如果相同名字的表已经存在,则抛出异常。
-
external
external关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(location)
-
not null
非空约束
-
default
默认值
-
check
为表字段添加检查约束
-
unique
唯一约束,一个表中唯一和主键只能存在一个
-
primary key
主键设置,可以是一个或多个列
-
with
可以添加数据追加方式,压缩格式,压缩级别,行列压缩等
-
location
指定外部表数据存储位置
-
format
存储数据的文本类型
-
partition by
支持两种分区方式,范围分区(range)和列表分区(list)
-
distributed by
为表添加分布键,其必须为主键的子键
-
comment
为表或列添加注释。
2)内部表和外部表介绍
内部表和外部表是两种不同类型的表,它们在数据存储和处理方式上有明细的区别。了解这些区别对于合理的设计和优化GP数据库非常重要。
内部表和外部表在操作和用途上的主要区别。内部表适合存储和管理数据库内的数据,而外部表适用于从外部数据源临时读取数据。
-
内部表
- 数据存储:内部表的数据直接存储在GP数据库的数据文件中,这意味着数据被物理存储在数据库服务器上。
- 事务管理:内部表完全支持事务管理,这包括ACID属性(原子性、一致性、隔离性和持久性),确保数据完整性和可靠性。
- 索引和约束:可以在内部表上创建索引和约束,这有助于提高查询性能和维护数据完整性。
- 管理和维护:内部表可以使用数据库的全部管理和维护功能,如备份和恢复。
- 适用性:适用于需要高性能查询和事务完整性的数据。
1) 创建内部表 gpdb=# CREATE TABLE ods.test ( id SERIAL PRIMARY KEY, name VARCHAR(100)); CREATE TABLE 2) 插入数据 gpdb=# INSERT INTO ods.test (name) VALUES ('zxy'); INSERT 0 1 gpdb=# INSERT INTO ods.test (name) VALUES ('zxy2'); INSERT 0 1 3) 查询结果 gpdb=# select * from ods.test; id | name ----+------ 2 | zxy2 1 | zxy (2 rows) -
外部表
- 数据存储:外部表的数据存储在数据库外部,如在文件系统、HDFS或任何可以通过SQL/MED(SQL Management of External Data)访问的数据源。外部表仅存储数据的元数据和位置信息。
- 事务管理:外部表不支持事务管理,它们主要用于读取和加载操作,不保证ACID属性。
- 索引和约束:由于数据实际存储在外部,,不能在外部表上创建索引或强制指向数据库级别的约束。
- 管理和维护:外部表的管理相对简单,因为只是对外部数据源的引用。备份和恢复不适用于外部表本身,而是应用于数据源。
- 适用性:适用于ETL操作,即从外部数据源提取数据,然后可能将其转换和加载到内部表中进一步处理。
1)启动gpfdist [gpadmin@sdw1 ~]$ gpfdist -d /home/gpadmin/ -p 8081 -l /home/gpadmin/gpAdminLogs/gpfdist.log & [1] 3232 2)/home/gpadmin/目录下,创建txt目录 1,zxy,18 2,zxy2,20 3)mdw创建外部表 create external table ods.test2 ( id int, name varchar(100), age int ) location ('gpfdist://sdw1:8081/test.txt') format 'text' (delimiter ','); 4)查询外部表 zxy=# select * from ods.test2; id | name | age ----+------+----- 1 | zxy | 18 2 | zxy2 | 20 (2 rows)
1.5 修改表
1)重命名表
alter table table_name rename to new_table_name;
zxy=# alter table ods.test rename to test3;
ALTER TABLE
2)增加列
alter table table_name add column col_name column_type;
zxy=# alter table ods.test3 add column age int;
ALTER TABLE
3)修改列类型
alter table table_name alter column column_name type column_type [using column::column_type]
zxy=# alter table ods.test3 alter column age type varchar(20);
ALTER TABLE
4)删除列
alter table table_name drop column col_name;
zxy=# alter table ods.test3 drop column age;
ALTER TABLE
1.6 清除表
truncate table table_name;
zxy=# truncate table ods.test3;
TRUNCATE TABLE
1.7 删除表
drop table table_name;
zxy=# drop table ods.test3;
DROP TABLE
2.DML(Data Manipulation Language)数据操作语言
2.1 数据导入
1)向表中装在数据(copy)
copy tablename from file_path delimiter '分隔符';
copy:表示加载数据,仅追加;
delimiter:表示读取的数据字段之间的分隔符;
1)创建表
create table ods.test4 (
id int null,
name varchar(10),
age int null
);
2)准备数据
1,zxy,18
2,zxy2,20
3)导入数据
copy ods.test4 from '/home/gpadmin/test.txt' delimiter ',';
4)查询数据
zxy=# select * from ods.test4;
id | name | age
----+------+-----
1 | zxy | 18
2 | zxy2 | 20
(2 rows)
2)向表中插入数据(insert)
insert into tablename(column1,column2...) values(....);
insert into tablename select * from tablename2;
1)insert into tablename(column1,column2...) values(....);
zxy=# insert into ods.test4 values(3,'zxy3',20);
INSERT 0 1
2)insert into tablename select * from tablename2;
zxy=# insert into ods.test4 select * from ods.test2;
INSERT 0 2
3)查询数据
zxy=# select * from ods.test4;
id | name | age
----+------+-----
3 | zxy3 | 20
2 | zxy2 | 20
2 | zxy2 | 20
1 | zxy | 18
1 | zxy | 18
(5 rows)
2.2 数据更新和删除
1)数据更新
update tablename set column1=value1,column2=value2... where [condition];
1)准备数据
zxy=# select * from ods.test4 where id = 1;
id | name | age
----+------+-----
1 | zxy | 18
1 | zxy | 18
(2 rows)
2)修改数据
zxy=# update ods.test4 set name='aaa' where id = 1;
UPDATE 2
3)查询数据
zxy=# select * from ods.test4 where id = 1;
id | name | age
----+------+-----
1 | aaa | 18
1 | aaa | 18
(2 rows)
2)数据删除
delete from tablename where [condition];
1)删除id为1的数据
zxy=# delete from ods.test4 where id = 1;
DELETE 2
2)查询数据
zxy=# select * from ods.test4 where id = 1;
id | name | age
----+------+-----
(0 rows)
2.3 数据导出
外部表数据无法导出。
copy tablename to filepath;
3.DQL(Data Query Language)数据查询语言
3.1 基础语法及执行顺序
SELECT [DISTINCT] colum1, column2, ...
FROM table_name -- 从什么表查
[WHERE condition] -- 过滤
[GROUP BY column_list] -- 分组查询
[HAVING column_list] -- 分组后过滤
[ORDER BY column_list] -- 排序
[LIMIT number] -- 限制输出的行数
3.2 基本查询
1)准备数据
[gpadmin@mdw ~]$ cat dept.txt
10,行政部,1700
20,财务部,1800
30,教学部,1900
40,销售部,1700
50,后勤部,1800
[gpadmin@mdw ~]$ cat emp.txt
7369,张三,研发,800.00,30
7499,李四,财务,1600.00,20
7521,王五,行政,1250.00,10
7566,赵六,销售,2975.00,40
7654,侯七,研发,1250.00,30
7698,马八,研发,2850.00,30
7782,金九,,2450.0,30
7788,银十,行政,3000.00,10
7839,小芳,销售,5000.00,40
7844,小明,销售,1500.00,40
7876,小李,行政,1100.00,10
7900,小元,讲师,950.00,30
7902,小海,行政,3000.00,10
7934,小红明,讲师,1300.00,30
7999,小八,行政,4000.00,10
2)准备表
create table ods.dept (
deptno int, --部门编号
dname text, --部门名称
loc int --部门位置id
) ;
create table ods.emp (
empno int, -- 员工编号
ename text, -- 员工姓名
job text, -- 员工岗位(大数据工程师、前端工程师、java工程师)
sal double precision, -- 员工薪资
deptno int -- 部门编号
) ;
3)导入数据
copy ods.dept from '/home/gpadmin/dept.txt' delimiter ',';
copy ods.emp from '/home/gpadmin/emp.txt' delimiter ',';
1)直接查询
# 使用*,查询所有数据
zxy=# select * from ods.dept;
deptno | dname | loc
--------+--------+------
30 | 教学部 | 1900
20 | 财务部 | 1800
40 | 销售部 | 1700
10 | 行政部 | 1700
(4 rows)
# 查询指定列
zxy=# select deptno,dname from ods.dept;
deptno | dname
--------+--------
20 | 财务部
40 | 销售部
10 | 行政部
30 | 教学部
(4 rows)
2)查询取别名
# 可以使用as,可以不使用
zxy=# select deptno as no1,deptno no2 from ods.dept;
no1 | no2
-----+-----
20 | 20
40 | 40
30 | 30
10 | 10
(4 rows)
3)limit查询
# 1.查询并取三条数据
zxy=# select * from ods.emp limit 3;
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7654 | 侯七 | 研发 | 1250 | 30
7876 | 小李 | 行政 | 1100 | 10
7521 | 王五 | 行政 | 1250 | 10
(3 rows)
# 2.根据empno升序排序,并取三条记录
zxy=# select * from ods.emp order by empno limit 3;
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7369 | 张三 | 研发 | 800 | 30
7499 | 李四 | 财务 | 1600 | 20
7521 | 王五 | 行政 | 1250 | 10
(3 rows)
# 3.根据empno升序排序,从第3行开始取3条数据
zxy=# select * from ods.emp order by empno limit 3 offset 2;
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7521 | 王五 | 行政 | 1250 | 10
7566 | 赵六 | 销售 | 2975 | 40
7654 | 侯七 | 研发 | 1250 | 30
(3 rows)
4)条件查询
zxy=# select * from ods.emp where ename = '王五';
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7521 | 王五 | 行政 | 1250 | 10
(1 row)
5)关系运算符
| 操作符 | 支持的数据类型 | 描述 |
|---|---|---|
| A=B | 基本数据类型 | 如果A等于B则返回true,反之返回false |
| A<=>B | 基本数据类型 | 如果A和B都为null,则返回true,如果一边为null,返回false |
| A<>B, A!=B | 基本数据类型 | A或者B为null则返回null;如果A不等于B,则返回true,反之返回false |
| A <B | 基本数据类型 | A或者B为null,则返回null;如果A小于B,则返回true,反之返回false |
| A<=B | 基本数据类型 | A或者B为null,则返回null;如果A小于等于B,则返回true,反之返回false |
| A>B | 基本数据类型 | A或者B为null,则返回null;如果A大于B,则返回true,反之返回false |
| A>=B | 基本数据类型 | A或者B为null,则返回null;如果A大于等于B,则返回true,反之返回false |
| A [not] between B and C | 基本数据类型 | 如果A,B或者C任一为null,则结果为null。如果A的值大于等于B而且小于或等于C,则结果为true,反之为false。如果使用not关键字则可达到相反的效果。 |
| A is null | 所有数据类型 | 如果A等于null,则返回true,反之返回false |
| A is not null | 所有数据类型 | 如果A不等于null,则返回true,反之返回false |
| in(数值1,数值2) | 所有数据类型 | 使用 in运算显示列表中的值 |
| A [not] like B | string 类型 | B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回true;反之返回false。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母‘x’结尾,而‘%x%’表示A包含有字母‘x’,可以位于开头,结尾或者字符串中间。如果使用not关键字则可达到相反的效果。 |
| A rlike B, A regexp B | string 类型 | B是基于java的正则表达式,如果A与其匹配,则返回true;反之返回false。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
# 1.查询sal等于1500
zxy=# select * from ods.emp where sal = 1500;
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7844 | 小明 | 销售 | 1500 | 40
(1 row)
# 2.查询sal大于等于1500
zxy=# select * from ods.emp where sal >= 1500;
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7566 | 赵六 | 销售 | 2975 | 40
7844 | 小明 | 销售 | 1500 | 40
7788 | 银十 | 行政 | 3000 | 10
7839 | 小芳 | 销售 | 5000 | 40
7499 | 李四 | 财务 | 1600 | 20
7698 | 马八 | 研发 | 2850 | 30
7782 | 金九 | | 2450 | 30
7902 | 小海 | 行政 | 3000 | 10
7999 | 小八 | 行政 | 4000 | 10
(8 rows)
# 3.查询sql小于1500
zxy=# select * from ods.emp where sal < 1500;
empno | ename | job | sal | deptno
-------+--------+------+------+--------
7521 | 王五 | 行政 | 1250 | 10
7900 | 小元 | 讲师 | 950 | 30
7369 | 张三 | 研发 | 800 | 30
7934 | 小红明 | 讲师 | 1300 | 30
7654 | 侯七 | 研发 | 1250 | 30
7876 | 小李 | 行政 | 1100 | 10
(6 rows)
# 4.查询sal在1000和1500之间的
zxy=# select * from ods.emp where sal between 1000 and 1500;
empno | ename | job | sal | deptno
-------+--------+------+------+--------
7654 | 侯七 | 研发 | 1250 | 30
7876 | 小李 | 行政 | 1100 | 10
7521 | 王五 | 行政 | 1250 | 10
7844 | 小明 | 销售 | 1500 | 40
7934 | 小红明 | 讲师 | 1300 | 30
(5 rows)
# 5.查询job为null的
zxy=# select * from ods.emp where job is null;
empno | ename | job | sal | deptno
-------+-------+-----+------+--------
7782 | 金九 | | 2450 | 30
(1 row)
# 6.通配符"_"查询明结尾
zxy=# select * from ods.emp where ename like '_明';
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7844 | 小明 | 销售 | 1500 | 40
(1 row)
# 7.通配符"%"查询明结尾
zxy=# select * from ods.emp where ename like '%明';
empno | ename | job | sal | deptno
-------+--------+------+------+--------
7844 | 小明 | 销售 | 1500 | 40
7934 | 小红明 | 讲师 | 1300 | 30
(2 rows)
6)逻辑运算符
| 操作符 | 含义 |
|---|---|
| and | 逻辑并 |
| or | 逻辑或 |
| not | 逻辑否 |
# 1.查询研发岗位,工资大于1000
zxy=# select * from ods.emp where job = '研发' and sal > 1000;
empno | ename | job | sal | deptno
-------+-------+------+------+--------
7654 | 侯七 | 研发 | 1250 | 30
7698 | 马八 | 研发 | 2850 | 30
(2 rows)
# 2.查询研发岗位,或者工资大于1000
zxy=# select * from ods.emp where job = '研发' or sal > 1000;
empno | ename | job | sal | deptno
-------+--------+------+------+--------
7654 | 侯七 | 研发 | 1250 | 30
7876 | 小李 | 行政 | 1100 | 10
7521 | 王五 | 行政 | 1250 | 10
7566 | 赵六 | 销售 | 2975 | 40
7844 | 小明 | 销售 | 1500 | 40
7788 | 银十 | 行政 | 3000 | 10
7839 | 小芳 | 销售 | 5000 | 40
7369 | 张三 | 研发 | 800 | 30
7499 | 李四 | 财务 | 1600 | 20
7698 | 马八 | 研发 | 2850 | 30
7902 | 小海 | 行政 | 3000 | 10
7934 | 小红明 | 讲师 | 1300 | 30
7782 | 金九 | | 2450 | 30
7999 | 小八 | 行政 | 4000 | 10
(13 rows)
# 3.查询岗位不是研发,行政的
zxy=# select * from ods.emp where job not in ('研发','行政');
empno | ename | job | sal | deptno
-------+--------+------+------+--------
7839 | 小芳 | 销售 | 5000 | 40
7566 | 赵六 | 销售 | 2975 | 40
7844 | 小明 | 销售 | 1500 | 40
7900 | 小元 | 讲师 | 950 | 30
7499 | 李四 | 财务 | 1600 | 20
7934 | 小红明 | 讲师 | 1300 | 30
(6 rows)
7)聚合函数
| 聚合函数 | 含义 |
|---|---|
| count() | 表示统计行数 |
| max() | 求最大值,不含null,除非所有值都是null |
| min() | 求最小值,不包含null,除非所有值都是null |
| sum() | 求和,不包含null |
| avg() | 求平均值,不包含null |
# 统计emp表有多少条数据,最大sal、最小sal、sal合计、sal平均值
zxy=# select count(*),max(sal) max_sal,min(sal) min_sal,sum(sal) sum_sal,avg(sal) avg_sal from ods.emp;
count | max_sal | min_sal | sum_sal | avg_sal
-------+---------+---------+---------+------------------
14 | 5000 | 800 | 29025 | 2073.21428571429
(1 row)
3.3 分组查询
1)Group By语句
Group By语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后执行对应的聚合操作。查询时如果使用Group BY,那么Select查询的字段只能包括Group By后的字段。
# 1.查看各岗位总工资多少
zxy=# select job,sum(sal) sal from ods.emp group by job;
job | sal
------+------
行政 | 8350
讲师 | 2250
| 2450
销售 | 9475
研发 | 4900
财务 | 1600
(6 rows)
# 2.查看各岗位最大工资、最小工资、平均工资
zxy=# select job,max(sal),min(sal),avg(sal) from ods.emp group by job;
job | max | min | avg
------+------+------+------------------
销售 | 5000 | 1500 | 3158.33333333333
研发 | 2850 | 800 | 1633.33333333333
财务 | 1600 | 1600 | 1600
行政 | 3000 | 1100 | 2087.5
讲师 | 1300 | 950 | 1125
| 2450 | 2450 | 2450
(6 rows)
2)Having语句
where后面不能跟分组聚合函数,而having后面可以且只能使用分组聚合函数,不可以使用聚合函数的别名。
having只用于group by分组统计语句。
# 1.查询岗位人数大于3的岗位
zxy=# select job,count(*) from ods.emp group by job having count(*) > 3;
job | count
------+-------
行政 | 4
(1 row)
3.4 联合查询
1)等值JSON
只有两个表中都符合条件的数据才能保留下来;
查询行政部有哪些人?
select *
from ods.dept
join ods.emp on dept.deptno = emp.deptno
where dept.dname = '行政部';
zxy=# select *
zxy-# from ods.dept
zxy-# join ods.emp on dept.deptno = emp.deptno
zxy-# where dept.dname = '行政部';
deptno | dname | loc | empno | ename | job | sal | deptno
--------+--------+------+-------+-------+------+------+--------
10 | 行政部 | 1700 | 7521 | 王五 | 行政 | 1250 | 10
10 | 行政部 | 1700 | 7788 | 银十 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7902 | 小海 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7876 | 小李 | 行政 | 1100 | 10
(4 rows)
2)内连接
只有两个表中都符合条件的数据才能保留下来,默认的join即为inner join内连接。
查询行政部有哪些人?
select *
from ods.dept
join ods.emp on dept.deptno = emp.deptno
where dept.dname = '行政部';
zxy=# select *
zxy-# from ods.dept
zxy-# join ods.emp on dept.deptno = emp.deptno
zxy-# where dept.dname = '行政部';
deptno | dname | loc | empno | ename | job | sal | deptno
--------+--------+------+-------+-------+------+------+--------
10 | 行政部 | 1700 | 7521 | 王五 | 行政 | 1250 | 10
10 | 行政部 | 1700 | 7788 | 银十 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7902 | 小海 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7876 | 小李 | 行政 | 1100 | 10
10 | 行政部 | 1700 | 7999 | 小八 | 行政 | 4000 | 10
(4 rows)
3)左外连接
左外连接:left join操作符,左边的所有记录将会返回,右表匹配不到的返回空。
select *
from ods.dept
left join ods.emp on dept.deptno = emp.deptno
where dept.dname = '后勤部';
zxy=# select *
zxy-# from ods.dept
zxy-# left join ods.emp on dept.deptno = emp.deptno
zxy-# where dept.dname = '后勤部';
deptno | dname | loc | empno | ename | job | sal | deptno
--------+--------+------+-------+-------+-----+-----+--------
50 | 后勤部 | 1800 | | | | |
(1 row)
4)右外连接
右外连接:right join操作符,右边的所有记录返回,左边匹配不到的为空。
select *
from ods.emp
right join ods.dept on emp.deptno = dept.deptno
where dept.dname = '后勤部';
zxy=# select *
zxy-# from ods.emp
zxy-# right join ods.dept on emp.deptno = dept.deptno
zxy-# where dept.dname = '后勤部';
empno | ename | job | sal | deptno | deptno | dname | loc
-------+-------+-----+-----+--------+--------+--------+------
| | | | | 50 | 后勤部 | 1800
(1 row)
5)全连接
全连接:full join操作符,返回两个表中所有数据,如果有不符合条件的返回空。
select *
from ods.dept
full join ods.emp on dept.deptno = emp.deptno;
zxy=# select *
zxy-# from ods.dept
zxy-# full join ods.emp on dept.deptno = emp.deptno;
deptno | dname | loc | empno | ename | job | sal | deptno
--------+--------+------+-------+--------+------+------+--------
10 | 行政部 | 1700 | 7788 | 银十 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7902 | 小海 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7521 | 王五 | 行政 | 1250 | 10
10 | 行政部 | 1700 | 7876 | 小李 | 行政 | 1100 | 10
10 | 行政部 | 1700 | 7999 | 小八 | 行政 | 4000 | 10
30 | 教学部 | 1900 | 7369 | 张三 | 研发 | 800 | 30
30 | 教学部 | 1900 | 7698 | 马八 | 研发 | 2850 | 30
30 | 教学部 | 1900 | 7934 | 小红明 | 讲师 | 1300 | 30
30 | 教学部 | 1900 | 7782 | 金九 | | 2450 | 30
30 | 教学部 | 1900 | 7900 | 小元 | 讲师 | 950 | 30
30 | 教学部 | 1900 | 7654 | 侯七 | 研发 | 1250 | 30
20 | 财务部 | 1800 | 7499 | 李四 | 财务 | 1600 | 20
40 | 销售部 | 1700 | 7844 | 小明 | 销售 | 1500 | 40
40 | 销售部 | 1700 | 7839 | 小芳 | 销售 | 5000 | 40
40 | 销售部 | 1700 | 7566 | 赵六 | 销售 | 2975 | 40
50 | 后勤部 | 1800 | | | | |
(15 rows)
6)笛卡尔积
无条件关联两个表,会产生笛卡尔积,两边数据互相连接。
例如查询行政部,笛卡尔积可以匹配到所有的员工名单
zxy=# select *
zxy-# from ods.dept,ods.emp
zxy-# where dname = '行政部';
deptno | dname | loc | empno | ename | job | sal | deptno
--------+--------+------+-------+--------+------+------+--------
10 | 行政部 | 1700 | 7521 | 王五 | 行政 | 1250 | 10
10 | 行政部 | 1700 | 7566 | 赵六 | 销售 | 2975 | 40
10 | 行政部 | 1700 | 7844 | 小明 | 销售 | 1500 | 40
10 | 行政部 | 1700 | 7900 | 小元 | 讲师 | 950 | 30
10 | 行政部 | 1700 | 7788 | 银十 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7839 | 小芳 | 销售 | 5000 | 40
10 | 行政部 | 1700 | 7654 | 侯七 | 研发 | 1250 | 30
10 | 行政部 | 1700 | 7876 | 小李 | 行政 | 1100 | 10
10 | 行政部 | 1700 | 7369 | 张三 | 研发 | 800 | 30
10 | 行政部 | 1700 | 7499 | 李四 | 财务 | 1600 | 20
10 | 行政部 | 1700 | 7698 | 马八 | 研发 | 2850 | 30
10 | 行政部 | 1700 | 7902 | 小海 | 行政 | 3000 | 10
10 | 行政部 | 1700 | 7934 | 小红明 | 讲师 | 1300 | 30
10 | 行政部 | 1700 | 7782 | 金九 | | 2450 | 30
10 | 行政部 | 1700 | 7999 | 小八 | 行政 | 4000 | 10
(14 rows)
7)联合查询
union 和 union all都是上下拼接SQL的结果,union会去重,union all不去重。
# 1.union all不去重
zxy=# select empno,ename from ods.emp where ename = '王五'
zxy-# union all select empno,ename from ods.emp where ename = '王五';
empno | ename
-------+-------
7521 | 王五
7521 | 王五
(2 rows)
# 2.union去重
zxy=# select empno,ename from ods.emp where ename = '王五'
zxy-# union select empno,ename from ods.emp where ename = '王五';
empno | ename
-------+-------
7521 | 王五
(1 row)
3.5 排序
Order By全局排序,默认是asc升序排序,可以指定desc降序排序。
# 1.默认根据deptno升序查询表
zxy=# select deptno,dname,loc from ods.dept order by deptno;
deptno | dname | loc
--------+--------+------
10 | 行政部 | 1700
20 | 财务部 | 1800
30 | 教学部 | 1900
40 | 销售部 | 1700
50 | 后勤部 | 1800
(5 rows)
# 2.根据deptno升序查询表
zxy=# select deptno,dname,loc from ods.dept order by deptno asc;
deptno | dname | loc
--------+--------+------
10 | 行政部 | 1700
20 | 财务部 | 1800
30 | 教学部 | 1900
40 | 销售部 | 1700
50 | 后勤部 | 1800
(5 rows)
# 3.根据deptno降序查询表
zxy=# select deptno,dname,loc from ods.dept order by deptno desc;
deptno | dname | loc
--------+--------+------
50 | 后勤部 | 1800
40 | 销售部 | 1700
30 | 教学部 | 1900
20 | 财务部 | 1800
10 | 行政部 | 1700
(5 rows)
第六章 函数
1.函数介绍
GreenPlum会将常用的逻辑封装成函数给用户进行使用,类似于Java中方法。好处就是不用重复写逻辑,直接用即可。所以为了在使用更快速便捷的入手,需要了解下GP数据库提供了哪些内置函数,然后根据需要选择对应的函数进行使用。
2.单行函数
单行函数的特点就是一进一出,输入一行,输出一行。
2.1 算术运算符
| 运算符 | 描述 |
|---|---|
| A+B | A和B 相加 |
| A-B | A减去B |
| A*B | A和B 相乘 |
| A/B | A除以B |
| A%B | A对B取余 |
| A&B | A和B按位取与 |
| A|B | A和B按位取或 |
| A^B | A和B按位取异或 |
| ~A | A按位取反 |
2.2 数值函数
| 函数 | 返回类型 | 描述 | 例子 | 结果 |
|---|---|---|---|---|
| abs(x) | (与x相同) | 绝对值 | - | - |
| ceil(dp或numeric)\ceiling | (与输入相同) | 不小于参数的最小整数 | - | - |
| exp(dp或numeric) | (与输入相同) | 自然指数 | - | - |
| ln(dp或numeric) | (与输入相同) | 自然对数 | - | - |
| log(dp或numeric) | (与输入相同) | 以10 为底的对数 | - | - |
| log(b numeric,x numeric) | numeric | 以b为底的对数 | - | - |
| mod(y,x) | (与参数类型相同) | y/x的余数 | - | - |
| pi() | dp | π | - | - |
| power(a numeric,b numeric) | numeric | a的b次幂 | - | - |
| radians(dp) | dp | 把角度转为弧度 | - | - |
| random() | dp | 0~1之间的随机数 | ||
| floor(dp或numeric) | (与输入相同) | 不大于参数的最大整数 | - | - |
| round(v numeric,s int) | numeric | 圆整为s位小数 | round(42.4382,2) | 42.44 |
| sign(dp或numeric) | (与输入相同) | 参数的符号(-1,0,+1) | sing(-8,4) | -1 |
| sqrt(dp或numeric) | (与输入相同) | 平方根 | - | - |
| cbrt(dp) | dp | 立方根 | - | - |
| trunc(v numeric,s int) | numeric | 截断为s位小数 | - | - |
# 1.random随机0-1之间的数值
zxy=# select random();
random
------------------
0.89662363845855
(1 row)
# 2.ceil向上取整
zxy=# select ceil(3.14);
ceil
------
4
(1 row)
# 3.floor向下取整
zxy=# select floor(3.14);
floor
-------
3
(1 row)
# 4.保留两位小数
zxy=# select round(3.1415926,2);
round
-------
3.14
(1 row)
2.3 字符串函数
| 函数 | 返回类型 | 描述 | 例子 | 结果 |
|---|---|---|---|---|
| string||string | text | 字符串连接 | ||
| length(string) | int | string中字符的数目 | length(‘jose’) | 4 |
| position(substring in string) | int | 指定的子字符串的位置 | position(‘om’in’Tomas’) | 3 |
| substring(string[from int][for int]) | text | 抽取子字符串 | substring(‘Thomas’from 2 for 3) | hom |
| trim([leading|trailing|both][characters]from string) | text | 从字符串string的开头/结尾/两边删除只包含characters中字符(默认是空白)的最长的字符串 | trim(both ‘x’ from ‘xTomxx’) | Tom |
| lower(string) | text | 把字符串转化为小写 | ||
| upper(string) | text | 把字符串转化为大写 | ||
| overlay(string placing string from int [for int]) | text | 替换子字符串 | overlay(‘Txxxxas’ placing ‘hom’ from 2 for 4) | Thomas |
| replace(string text,from text,to text) | text | 把字符串string中出现的所有子字符串from替换成子字符串to | replace(‘abcdefabcdef’,’cd,’XX’) | abXXefabXXef |
| split_part(string text, delimiter text,filed int) | text | 根据delimiter分隔string返回生成的第field个子字符串(1开始) | split_part(‘abc|def|ghi’,’|’,2) | def |
| concat_ws(string text,string text…) | text | 使用分隔符A拼接多个字符串,或者一个数组的所有元素。 | concat_ws(‘-’,‘a’,‘b’,‘c’) | a-b-c |
# 1.拼接字符串
zxy=# select 'a'||'b';
?column?
----------
ab
(1 row)
# 2.使用连接符连接字符串
zxy=# select concat_ws('-','a','b','c');
concat_ws
-----------
a-b-c
(1 row)
# 3.根据指定符号分割字符串
zxy=# select split_part('a-b-c','-',1);
split_part
------------
a
(1 row)
2.4 时间函数
使用interval类型可以直接对事件类型进行计算,用来计算时间的加减
| 函数 | 返回类型 | 描述 | 例子 | 结果 |
|---|---|---|---|---|
| age(timestamp,timestamp) | interval | 减去参数后的”符号化”结果 | age(timestamp’2001-04-10’,timestamp’1957-06-13) | 43 years 9 mons 27 das |
| age(timestam) | interval | 从current_date减去参数中的日期 | age(timestam’1957-06-13) | - |
| current_date | date | 当前的日期 | - | - |
| current_time | time with time zone | 当日时间 | - | - |
| current_timestamp | timestamp with time zone | 当前事务开始时的事件戳 | - | - |
| date_part(text,timestamp) | double precision | 获取子域(等效于extract) | date_part(‘hour’,timestamp’2001-02-16 20:38:40) | 20 |
| date_trunc(text,timestamp) | timestamp | 截断成指定的精度 | date_trunc(‘hour’,timestamp ‘2001-02-16 20:38:40’) | 2001/2/16 20:00 |
| extract(field from timestamp) | double precision | 获取子域 | (同date_part) | (同date_part) |
| now() | timestampe with time zone | 当前事务开始的时间戳 | - |
# 1.求日期相差的年龄
zxy=# select age('2002-01-01'::timestamp,'2000-02-13'::timestamp);
age
------------------------
1 year 10 mons 17 days
(1 row)
# 2.从日期中提取年
zxy=# select extract(year from current_date);
date_part
-----------
2024
(1 row)
# 3.从日期中提取年
zxy=# select date_part('year',current_date);
date_part
-----------
2024
(1 row)
# 4.interval日期相加
zxy=# select '2000-01-01'::timestamp + interval '1 days';
?column?
---------------------
2000-01-02 00:00:00
(1 row)
2.5 流程控制函数
case when:条件判断函数
case when a then b [when c then d]* [else e] end
如果a为true,则返回b;如果c为true,则返回d;否则返回e;
# 1.查看emp表
zxy=# select * from ods.emp;
empno | ename | job | sal | deptno
-------+--------+------+------+--------
7521 | 王五 | 行政 | 1250 | 10
7566 | 赵六 | 销售 | 2975 | 40
7844 | 小明 | 销售 | 1500 | 40
7900 | 小元 | 讲师 | 950 | 30
7369 | 张三 | 研发 | 800 | 30
7499 | 李四 | 财务 | 1600 | 20
7698 | 马八 | 研发 | 2850 | 30
7902 | 小海 | 行政 | 3000 | 10
7934 | 小红明 | 讲师 | 1300 | 30
7782 | 金九 | | 2450 | 30
7654 | 侯七 | 研发 | 1250 | 30
7876 | 小李 | 行政 | 1100 | 10
7788 | 银十 | 行政 | 3000 | 10
7839 | 小芳 | 销售 | 5000 | 40
7999 | 小八 | 行政 | 4000 | 10
(14 rows)
# 2.case when匹配对应deptno
zxy=# select empno,ename,job,sal,
zxy-# case deptno when 10 then '行政部'
zxy-# when 20 then '财务部'
zxy-# when 30 then '教学部'
zxy-# when 40 then '销售部'
zxy-# end as dname
zxy-# from ods.emp;
empno | ename | job | sal | dname
-------+--------+------+------+--------
7788 | 银十 | 行政 | 3000 | 行政部
7839 | 小芳 | 销售 | 5000 | 销售部
7369 | 张三 | 研发 | 800 | 教学部
7499 | 李四 | 财务 | 1600 | 财务部
7698 | 马八 | 研发 | 2850 | 教学部
7902 | 小海 | 行政 | 3000 | 行政部
7934 | 小红明 | 讲师 | 1300 | 教学部
7782 | 金九 | | 2450 | 教学部
7521 | 王五 | 行政 | 1250 | 行政部
7566 | 赵六 | 销售 | 2975 | 销售部
7844 | 小明 | 销售 | 1500 | 销售部
7900 | 小元 | 讲师 | 950 | 教学部
7654 | 侯七 | 研发 | 1250 | 教学部
7876 | 小李 | 行政 | 1100 | 行政部
7999 | 小八 | 行政 | 4000 | 行政部
(14 rows)
3.行列转换函数
3.1 行转列函数
string_agg(column,parten)
zxy=# select string_agg(ename,',') from ods.emp;
string_agg
-------------------------------------------------------------------------
侯七,小李,银十,小芳,张三,李四,马八,小海,小红明,金九,王五,赵六,小明,小元,小八
(1 row)
3.2 列转行函数
regexp_split_to_table(column,parten)
zxy=# select regexp_split_to_table('侯七,小李,银十,小芳,张三,李四,马八,小海,小红明,金九,王五,赵六,小明,小元,小八',',');
regexp_split_to_table
-----------------------
侯七
小李
银十
小芳
张三
李四
马八
小海
小红明
金九
王五
赵六
小明
小元
小八
(14 rows)
4.窗口函数
4.1 概述
窗口函数,能为每行数据划分一个窗口,然后对窗口范围内数据进行计算,最后将计算结果返回给该行数据。
4.2 常用窗口函数
1)聚合函数
-
max:最大值
zxy=# select empno,ename,job,max(sal) over(partition by job) from ods.emp; empno | ename | job | max -------+--------+------+------ 7521 | 王五 | 行政 | 4000 7788 | 银十 | 行政 | 4000 7902 | 小海 | 行政 | 4000 7876 | 小李 | 行政 | 4000 7999 | 小八 | 行政 | 4000 7934 | 小红明 | 讲师 | 1300 7900 | 小元 | 讲师 | 1300 7782 | 金九 | | 2450 7654 | 侯七 | 研发 | 2850 7698 | 马八 | 研发 | 2850 7369 | 张三 | 研发 | 2850 7844 | 小明 | 销售 | 5000 7566 | 赵六 | 销售 | 5000 7839 | 小芳 | 销售 | 5000 7499 | 李四 | 财务 | 1600 (14 rows) -
min:最小值
zxy=# select empno,ename,job,min(sal) over(partition by job) from ods.emp; empno | ename | job | min -------+--------+------+------ 7499 | 李四 | 财务 | 1600 7369 | 张三 | 研发 | 800 7698 | 马八 | 研发 | 800 7654 | 侯七 | 研发 | 800 7844 | 小明 | 销售 | 1500 7566 | 赵六 | 销售 | 1500 7839 | 小芳 | 销售 | 1500 7902 | 小海 | 行政 | 1100 7521 | 王五 | 行政 | 1100 7876 | 小李 | 行政 | 1100 7788 | 银十 | 行政 | 1100 7999 | 小八 | 行政 | 1100 7934 | 小红明 | 讲师 | 950 7900 | 小元 | 讲师 | 950 7782 | 金九 | | 2450 (14 rows) -
sum:求和
zxy=# select empno,ename,job,sum(sal) over(partition by job) from ods.emp; empno | ename | job | sum -------+--------+------+------- 7876 | 小李 | 行政 | 12350 7999 | 小八 | 行政 | 12350 7521 | 王五 | 行政 | 12350 7902 | 小海 | 行政 | 12350 7788 | 银十 | 行政 | 12350 7900 | 小元 | 讲师 | 2250 7934 | 小红明 | 讲师 | 2250 7782 | 金九 | | 2450 7499 | 李四 | 财务 | 1600 7698 | 马八 | 研发 | 4900 7369 | 张三 | 研发 | 4900 7654 | 侯七 | 研发 | 4900 7839 | 小芳 | 销售 | 9475 7844 | 小明 | 销售 | 9475 7566 | 赵六 | 销售 | 9475 (15 rows) -
avg:平均值
zxy=# select empno,ename,job,avg(sal) over(partition by job) from ods.emp; empno | ename | job | avg -------+--------+------+------------------ 7698 | 马八 | 研发 | 1633.33333333333 7369 | 张三 | 研发 | 1633.33333333333 7654 | 侯七 | 研发 | 1633.33333333333 7844 | 小明 | 销售 | 3158.33333333333 7566 | 赵六 | 销售 | 3158.33333333333 7839 | 小芳 | 销售 | 3158.33333333333 7788 | 银十 | 行政 | 2470 7902 | 小海 | 行政 | 2470 7999 | 小八 | 行政 | 2470 7876 | 小李 | 行政 | 2470 7521 | 王五 | 行政 | 2470 7934 | 小红明 | 讲师 | 1125 7900 | 小元 | 讲师 | 1125 7782 | 金九 | | 2450 7499 | 李四 | 财务 | 1600 (15 rows) -
count:计数
zxy=# select empno,ename,job,count(sal) over(partition by job) from ods.emp; empno | ename | job | count -------+--------+------+------- 7499 | 李四 | 财务 | 1 7521 | 王五 | 行政 | 5 7788 | 银十 | 行政 | 5 7902 | 小海 | 行政 | 5 7999 | 小八 | 行政 | 5 7876 | 小李 | 行政 | 5 7900 | 小元 | 讲师 | 2 7934 | 小红明 | 讲师 | 2 7782 | 金九 | | 1 7698 | 马八 | 研发 | 3 7369 | 张三 | 研发 | 3 7654 | 侯七 | 研发 | 3 7839 | 小芳 | 销售 | 3 7844 | 小明 | 销售 | 3 7566 | 赵六 | 销售 | 3 (15 rows)
2)跨行取值函数
-
lag和lead
lag(column,offset,default)获取当前行的上某行,某个字段的值
lead(column,offset,default)获取当前行的下某行,某个字段的值
- column是指定字段
- offset是指定偏移量
- default指定找不到符合条件后的默认值
zxy=# select empno,ename,job,lag(empno,1,'1') over(partition by job order by empno) lagno,lead(empno,1,'9999') over(partition by job order by empno) leadno from ods.emp; empno | ename | job | lagno | leadno -------+--------+------+-------+-------- 7521 | 王五 | 行政 | 1 | 7788 7788 | 银十 | 行政 | 7521 | 7876 7876 | 小李 | 行政 | 7788 | 7902 7902 | 小海 | 行政 | 7876 | 7999 7999 | 小八 | 行政 | 7902 | 9999 7900 | 小元 | 讲师 | 1 | 7934 7934 | 小红明 | 讲师 | 7900 | 9999 7782 | 金九 | | 1 | 9999 7499 | 李四 | 财务 | 1 | 9999 7369 | 张三 | 研发 | 1 | 7654 7654 | 侯七 | 研发 | 7369 | 7698 7698 | 马八 | 研发 | 7654 | 9999 7566 | 赵六 | 销售 | 1 | 7839 7839 | 小芳 | 销售 | 7566 | 7844 7844 | 小明 | 销售 | 7839 | 9999 (15 rows)
3)排名函数
-
row_number
连续不重复
zxy=# select job,ename,sal,row_number() over(partition by job order by sal) from ods.emp where job = '行政'; job | ename | sal | row_number ------+-------+------+------------ 行政 | 小李 | 1100 | 1 行政 | 王五 | 1250 | 2 行政 | 小海 | 3000 | 3 行政 | 银十 | 3000 | 4 行政 | 小八 | 4000 | 5 (5 rows) -
rank
不连续不重复
zxy=# select job,ename,sal,rank() over(partition by job order by sal) from ods.emp where job = '行政'; job | ename | sal | rank ------+-------+------+------ 行政 | 小李 | 1100 | 1 行政 | 王五 | 1250 | 2 行政 | 银十 | 3000 | 3 行政 | 小海 | 3000 | 3 行政 | 小八 | 4000 | 5 (5 rows) -
dense_rank
连续重复
zxy=# select job,ename,sal,dense_rank() over(partition by job order by sal) from ods.emp where job = '行政'; job | ename | sal | dense_rank ------+-------+------+------------ 行政 | 小李 | 1100 | 1 行政 | 王五 | 1250 | 2 行政 | 小海 | 3000 | 3 行政 | 银十 | 3000 | 3 行政 | 小八 | 4000 | 4 (5 rows)
5.其他函数
1)序列号生成函数-generate_series(x,y,t)
生成多行数据从x到y,步长为t,默认步长是1
zxy=# select generate_series(1,10,1);
generate_series
-----------------
1
2
3
4
5
6
7
8
9
10
(10 rows)