lc 606 根据二叉树创建字符串
给你二叉树的根节点 root ,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
空节点使用一对空括号对 “()” 表示,转化后需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
题目描述:
从根开始,只要是儿子,就加一层(),**父节点和儿子之间一定要加()**如果2有单独的孩子3,4,则是:2(3)(4),而如果没有左孩子而有右孩子,则:2()(4)。不加()不能区分是左孩子还是右孩子。
看图:是一个dfs的感觉,只要有左孩子或右孩子,都该加()。因为就算只有右孩子,也要区分当前是右孩子。
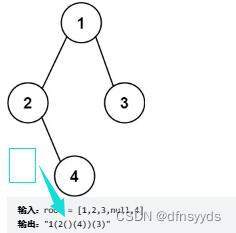
分析:
有两种情况,我们都需要给左边加:()。当左边有值,需要加一圈(),当左边无值而右边有值,也需要多加(),不然只加不加()不能辨别是右边的()。
所以思路:
- 若二叉树不为空,则先根结点的值放入字符串。
- 若左子树不为空,或者左子树为空但右子树不为空,则需要将左子树的值放入字符串。
- 若右子树不为空,则需要将右子树的值放入字符串。
做法一:效率低,因为return字符串做拷贝构造。
string tree2str(TreeNode* root) {
string res = "";
if (root == nullptr)
return "";
// 先把当前放入
res += to_string(root->val);
// 左不空 或 左为空但右不空 :都需要放左边的值或只给左边加()。这两个可以放一起
if (root->left || root->right)
{
res += '(';
res += tree2str(root->left);
res += ')';
}
// 右不空 右子树放字符串
if (root->right)
{
res += '(';
res += tree2str(root->right);
res += ')';
}
return res;
}
做法二:
将值放入参数上,就可以不用传值而不断让它变长。注意过程中,别漏加每个节点上的本身值到字符串。
string tree2str(TreeNode* root) {
if (root == nullptr)
return "";
string res = "";
dfs(root, res);
return res;
}
void dfs(TreeNode* root, string& res)
{
if (root == nullptr)
return;
// 把当前先加上
res += to_string(root->val);
// 左树有或右树有,都加
if (root->left || root->right)
{
res += '(';
dfs(root->left, res);
res += ')';
}
// 右树存在,就加上右树值
if (root->right)
{
res += '(';
dfs(root->right, res);
res += ')';
}
}
二叉树的非递归遍历
- 前序遍历:
前序遍历的访问顺序是:根、左、右。
做法:
- 根节点和根的左孩子都是在左路节点上,如下图所示,我们先挨着根、左孩子一直访问, 这样把左路节点都拿到了,再依次拿每个节点的右子树上所有节点。比如:8、3、1,再拿1、3、8的右子树上所有节点,这种顺序符合栈结构,所以具体做法看2。
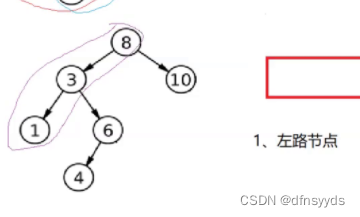
- 具体做法:
- 创建栈,初始化cur为根,依次拿根和根的左孩子入栈。
- 依次出栈每个节点,如果节点存在右孩子,则更新cur为右孩子。
- 整体需要一层循环(循环a),条件是:cur不为空或栈不为空。cur不为空,则循环(循环b while(cur))着,去把当前和左孩子入栈。循环b如果做完了,说明局部子树的左路节点都拿完了,我们需要弹栈首,更新cur,因为我们需要访问每个节点的右子树。
cur = top->right;- 遍历的值存入vector,我们可以开始就申请一个vector。关于存vector:在左路节点遍历过程中,先序遍历是优先根原则,所以每次遇到一个根,就可以push。对于每个节点都会经过内存的循环,所以都会放到vector中去。
- 记忆好该解题模板条件:while(cur || !st.empty())。
- 代码
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> v;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur || !st.empty())
{
// 左路节点需要每次一股脑全加进来
while(cur)
{
st.push(cur);
v.push_back(cur->val);
cur = cur->left;
}
// 当前走至最深的左节点的右路
// 这里巧妙在每次右路节点,只能最深的一个右来更新cur
TreeNode* top = st.top();
st.pop();
// cur可能不存在,但st可能还存在,就利用下次循环。
cur = top->right;
}
return v;
}
};
- 中序遍历
中序遍历需要先左再根再右,比如下面的树,8、3、1,在这个过程中,不能先按8、3、1去存,当没有左孩子时,才可以考虑去存。所以和先序的区别在于,存vector得在第二层while()之后存值入vector。也就是说:
- 每次到当前节点没有左孩子,说明到达最左端,此时出栈顶,可以push该值。再转cur至当前节点的右孩子。因为左和根是在一路的,push当前,其实也相当于push了根。
- 中序其实是先序的微调整。
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> v;
TreeNode* cur = root;
while (cur || !st.empty())
{
// 左路节点入栈
while (cur)
{
// 中序和前序的区别在出栈才能访问
st.push(cur);
cur = cur->left;
}
// 当左路节点从栈中出来,表示左路节点已经访问过了,应该访问根 这个节点和他的右子树
TreeNode* top = st.top();
st.pop();
v.push_back(top->val);
cur = top->right; // 子问题访问右子树
}
return v;
}
};
- 后序遍历
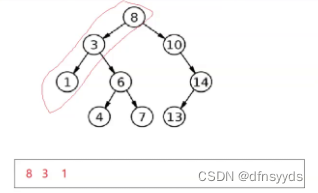
如图,后续遍历的访问顺序是左、右、根,所以访问一个节点时遵守的规则是:左右孩子均无,则访问,如果有左孩子,则继续深入。有右孩子,且访问过,才能访问当前。
所以这里的做法是:前两个的模板大体写法不变,存一个prev记录上一次访问的节点。
步骤:
- 有左孩子则不断深入更新cur,且放入栈st中,并更新prev。
- 出循环更新cur,直到cur不存在,说明当前是局部最左孩子。
- 然后出栈当前节点,当前节点如果有右孩子,则说明当前节点节点是个根,是根就不能访问,不能存vector。但是还需要判断,我们是第一次到达还是第二次到达这个根,所以判断:top->right == nullptr或top->right == prev即:顶的右为空或顶的右访问过,则可以直接push当前值,并更新prev,如果这两个条件不满足,说明第一次来,或有右孩子,则更新cur到cur->right。
- prev的更新只在push值之后,我们的真正访问只有在push:val时,才算真正访问。
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> v;
TreeNode* cur = root;
TreeNode* prev = nullptr;
while (cur || !st.empty())
{
// 左路节点入栈
while (cur)
{
// 中序和前序的区别在出栈才能访问
st.push(cur);
cur = cur->left;
}
// 当左路节点从栈中出来,表示左路节点已经访问过了,再访问根这个节点的右子树
// 只要能下到这里来,就说明节点左孩子都访问完了,可以访问右孩子了
TreeNode* top = st.top();
// 当前节点没有右子树或访问过了 可以入当前节点
if (top->right == nullptr || top->right == prev)
{
v.push_back(top->val);
// 且可以出栈当前
prev = top; // 更新prev 说明这个节点访问过了
st.pop();
}
else
{
cur = top->right;
}
}
return v;
}
};
JZ36. 二叉搜索树与双向链表
- 分析:二叉搜索树变双向链表,需要升序,所以以中序遍历为模板,之前我们输出节点放在inorder(root->left)和inorder(root->right)之间,而现在把输出节点变为做链接。
- 思路:
中序递归过程中,我们会最终先到最左节点,此时理论为头节点,利用传的参prev使得最左节点的left为prev,(prev初始为nullptr,正好使第一个节点前驱为nullptr)。在中间原本输出的位置,判断如果prev存在,则让prev->right = cur(也就是root),不管prev存在不存在,prev都再需要变为cur。中序继续往后走,递归去当前右子树。
#include<iostream>
using namespace std;
struct TreeNode {
int val;
struct TreeNode* left;
struct TreeNode* right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
class Solution {
public:
TreeNode* Convert(TreeNode* pRootOfTree) {
TreeNode* prev = nullptr;
inOrder(pRootOfTree, prev);
TreeNode* head = pRootOfTree;
while (head->left)
{
head = head->left;
}
return head;
}
void inOrder(TreeNode* root, TreeNode* prev)
{
if (root == nullptr)
return;
inOrder(root->left, prev);
// op
root->left = prev;
if (prev)
{
prev->right = root;
}
prev = root;
inOrder(root->left, prev);
}
};
最近公共祖先
普通二叉树:leetcode236. 二叉树的最近公共祖先
思路: 寻找从根到两个节点的路径,都放入栈中,栈顶是当前节点,栈底是根。找出两个栈的高度差,栈深的先出栈差个节点,再依次比较两个栈顶,第一个相等的节点就是最近祖先。
步骤:
- find()求路径函数:
- 当前为空,返回false,说明走到了空节点位置还没找到,就该返回,但是return false,因为发现找到时要返回true,停止去别的路径递归。所以空节点位置是个出口。
- 当前节点存在,就给栈:path中加入当前节点,如果当前值是所寻找,就返回true。
- 否则继续往左边递归,但是加上判断,如果在左边递归能返回true,这里也返回true,不必往下递归去右。
- 递归去右寻找。
- 如果之前左右都找过,也没能返回true而终止,说明当前节点不在路径上。pop()当前节点,再返回false。 这里的false,返回后会返回到之前某一有孩子的节点上,继续往别的方向走。
- 求最近祖先:
- 找两个节点的路径
- 看哪个stack_size大,让大的先出栈差个。
- 挨个比较栈顶,不等就一直出栈。
- 停下的时候必定相等, 此时哪个栈顶都正确。
bool findPath(TreeNode* root, TreeNode* x, stack<TreeNode*>& path)
{
if(root == nullptr)
return false;
path.push(root);
if(root->val == x->val)
return true;
// 左树找到,就返回了,不去右树
if(findPath(root->left, x, path))
return true;
if(findPath(root->right, x, path))
return true;
path.pop(); // 节点左右子树均没有,该节不是路径上节点
return false;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
stack<TreeNode*> ppath, qpath;
findPath(root, p, ppath);
findPath(root, q, qpath);
// 找到了路径,然后都是倒着的,让多的先删掉差个
stack<TreeNode*> lpath = ppath, spath=qpath; // 区分长短路径
if(lpath.size() < spath.size())
{
stack<TreeNode*> t = lpath;
lpath = spath;
spath = t;
}
int plus = lpath.size() - spath.size();
while(plus--)
lpath.pop();
while(lpath.top()!=spath.top())
{
lpath.pop();
spath.pop();
}
return lpath.top();
}
};
- 搜索二叉树:
思路:
寻找p、q,在BST树中,最近祖先有两种情况:(特殊情况)其中之一是根,则根是最近公共祖先,因为从上往下访问。(普通情况)最近公共祖先一定是大于其中之一而小于另外一个。
特殊情况如下:遍历按从上往下,先根再次根,比如m和n或p和q,都是一个根,而另外一个处于一个根的情况,如果我们访问到当前节点是p、q中某一个,说明某个节点处于另外一个节点的局部根位置。
普通情况下,如0、3的最近祖先1或0、6的最近祖先5,也或者0、4的最近祖先1,都满足大于其中一个、小于另外一个。
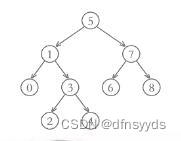
所以步骤如下:
- 当前节点是p或q中某一个,则当前就是答案
- 当前节点比两个都小,cur去当前的左边;当前节点比两个都大,cur去当前的右边。
- 当前节点比一个大,比另一个小,就是最小公共祖先。
注意
- 上面过程不会运行到某个不存在的节点,因为BST按上面的规则不会走到空。
- 每组情况,都要返回,不管是全大还是全小,都得返回
- 代码
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root->val == p->val || root->val == q->val) // 如果某个节点是其中之一,其实比本身值也可以
{
return root;
}
// 不会当前不存在的节点上
if(root->val < p->val && root->val < q->val)
return lowestCommonAncestor(root->right, p, q);
else if(root->val > p->val && root->val > q->val)
return lowestCommonAncestor(root->left, p, q);
else
return root;
}
};
重建二叉树
- 思路:
用一个函数即可,当前函数就行。
去创建树,参数是2个vector顺序,然后两个数组的4个边界。
在前序中,确定根值,再去中序找根位置,每次创建当前节点,然后再递归链去左和右,递归链接左右。
class Solution {
public:
TreeNode* createMyTree(vector<int>& pre, int pleft, int pright, vector<int>& in, int inleft, int inright)
{
//cout << "pleft = " << pleft << " , pright = " << pright << " , inleft = " << inleft << " , inright = " << inright << endl;
// 出口一定要记好:等于的话,也需要建一个节点 大于才停止
if (pleft> pright )
{
return nullptr;
}
// 每次根节点和根节点的左右边界
TreeNode* root = new TreeNode(pre[pleft]);
// 前序中的第一个是根,根在中序中位置
int root_Inorder_Index = 0;
for (int i = inleft; i <= inright; i++)
{
if (pre[pleft] == in[i])
{
root_Inorder_Index = i;
break;
}
}
// 因为前面就错了,没找到。
// cout << "当前前序根:" << pre[pleft] << " , 中序中是:" << in[root_Inorder_Index] << " , 位置:" << root_Inorder_Index << endl;
// 左子树个数:
int Lnums = root_Inorder_Index-inleft;
// 右子树个数:
//int Rnums = inright - root_Inorder_Index;
//cout << "左子树:" << Lnums << ", 右子树:" << Rnums<< endl;
// 利用左右子树的数量,分别拿节点
root->left = createMyTree(pre, pleft+1, pleft+Lnums, in, inleft, root_Inorder_Index-1);
root->right = createMyTree(pre, pleft+Lnums+1, pright, in, root_Inorder_Index+1, inright);
return root;
}
// 递归建树 另用递归函数
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (preorder.size() == 0)
return nullptr;
TreeNode* root = createMyTree(preorder, 0, preorder.size()-1, inorder, 0, inorder.size()-1);
return root;
}
};
中序和后续遍历构造二叉树
leetcode 106. 从中序与后序遍历序列构造二叉树
class Solution {
public:
TreeNode* create(vector<int>& in, int s1, int e1, vector<int>& post, int s2, int e2)
{
if (s1 > e1 || s2 > e2)
return nullptr;
TreeNode* root = new TreeNode(post[e2]);
int rootOfIn = 0;
for (int i = s1; i <= e1; i++)
{
if (post[e2] == in[i])
{
rootOfIn = i;
break;
}
}
int Lnums = rootOfIn-s1;
root->left = create(in, s1, rootOfIn-1, post, s2, s2+Lnums-1);
root->right = create(in, rootOfIn+1, e1, post, s2+Lnums, e2-1);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (inorder.size() == 0)
return nullptr;
TreeNode* root = create(inorder, 0, inorder.size()-1, postorder, 0, postorder.size()-1);
return root;
}
};
二叉搜索树与双向链表
错的
class Solution {
public:
void Inorder(TreeNode* root, TreeNode* prev)
{
// 访问到空 就返回
if(root == nullptr)
return;
Inorder(root->left, prev);
// 原本输出值的地方,我们给它换成做链接:一左一右
root->left = prev;
if(prev) // 除了中序第一个节点时,prev是null,其它prev都有值
{
prev->right = root;
}
// 只有当前节点的左,全访问完,才能轮到当前做prev,且它是以它为根,右孩子的prev。
prev = root;
Inorder(root->right, prev);
}
TreeNode* Convert(TreeNode* pRootOfTree) {
if(pRootOfTree == nullptr)
return nullptr;
// 按中序遍历走
TreeNode* prev = nullptr;
TreeNode* head = pRootOfTree;
Inorder(head, prev);
while(head)
{
head = head->left;
}
return head;
}
};
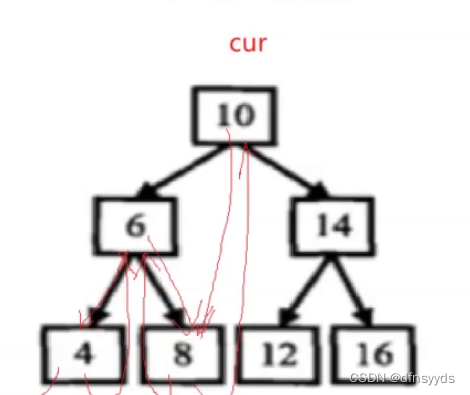
以上错了,错在prev在不断改变,比如cur在10时,prev = 10, cur递归去了14,而cur在14时,会不断递归去12,prev是10正确,但是当回到14的时候,prev还是10,prev应该随着递归而改变成12,所以为了让prev随着递归改变,prev应该用指针的引用。,而cur的指向不需要随着递归深入做改变。