一、集群规划
三台硬件资源,部署hadoop版本,hadoop-3.3.5 ,部署后配置文件。
Hadoop配置文件分两类:默认配置文件和自定义配置文件。
| hadoop102 | hadoop103 | hadoop104 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
需要知道的知识点
1-HDFS 进行了GFS 的开源实现,Hadoop 的 MapReduce 是 Google 的 MapReduce 分布式处理的开源实现,而 HBase 作为一种 Hadoop 生态系统的分布式数据库,是 BigTable 的开源实现。
2-Hadoop 2.0以上版本有4个重要组成部分: HDFS (Hadoop Distributed File System)、 MapReduce、YARN( Yet Another Resource Negotiator)、COMMON (Hadoop 生态圈).
3-Hadoop 最突出的两个特点是分布式和容错机制。
4-Hadoop 的分布式体现在它是主从结构,不管是进行计算还是存储,都采用主从结构。
1)任务调度中的分布式特点—YARN,YARN机制,主节点接受一个由客户端发起的作业请求之后便选择一个普通节点,也称为从节点或工作节点,在该节点上成立对于作业的执行机构,再由这个执行机构操办和管理作业的从节点运行,而主节点则专门负责资源分配。
2)文件存储中的分布式特点—HDFS,HDFS是Hadoop的分布式文件系统。HDFS的目录服务器主节点上并不存储数据块备份,而是存储所有文件和目录的“元数据”。
存储着数据块的从节点称为DataNode。应用程序需要访问某个文件中某个位置上的数据时,首先需要向主节点询问该数据位于第几个从节点上,然后去该从节点访问数据。
5-Hadoop的容错机制主要体现在两个里面:HDFS 和 MapReduce。
---------------------------------
二、默认配置文件
hadoop安装包解压以后,到目录:hadoop-3.3.5\share\hadoop 寻找下面的jar包:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
| [core-default.xml] | hadoop-common-3.3.5.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.3.5.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.3.5.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.3.5.jar/mapred-default.xml |
三、自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
按照hadoop路径为opt/module/hadoop-3.3.5 所以配置文件在这个路径下继续/etc/hadoop
四、配置集群
4-1-核心配置文件
按之前设定的配置方案配置core-site.xml
[antares@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[antares@hadoop102 hadoop]$ vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.5/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为antares -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>antares</value>
</property>
</configuration>
4-2-配置hdfs-site.xml
[antares@hadoop102 hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- namenode web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- secondary namenode web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
4-3-YARN配置文件
[antares@hadoop102 hadoop]$ vim yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4-4-MapReduce配置文件
[antares@hadoop102 hadoop]$ vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4-5在集群上分发配置好的Hadoop配置文件
可以自己创建统一分发命令,或是使用scp拷贝的方式,不过需要删除其他资源上原来的文件或是重命名原文件。这里不再累述。关于文件分发命令需要单独做个自定义的命令。
确认资源103和104上已有配置文件
cat /opt/module/hadoop-3.3.5/etc/hadoop/core-site.xml
五、配置worker
[antares@hadoop102 hadoop]$ vim /opt/module/hadoop-3.3.5/etc/hadoop/workers
文件中添加下述内容:
hadoop102
hadoop103
hadoop104
同步所有节点配置文件 :Hadoop103 & hadoop104 都需要配置上worker.
六、启动集群
6-1 如果集群是第一次启动
根据上述的部署规划,102资源上 部署的是NameNode,需要在hadoop102节点格式化NameNode。
这里有个必坑指南:(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
回到hadoop根目录,在hadoop102节点格式化NameNode
[antares@hadoop102 hadoop-3.3.5]$ pwd
/opt/module/hadoop-3.3.5
[antares@hadoop102 hadoop-3.3.5]$ hdfs namenode -format
# 查看data中的namenode信息hdfs namenode -format
[antares@hadoop102 hadoop-3.3.5]$ ls data/dfs/name/current/

6-2 启动HDFS
[antares@hadoop102 hadoop-3.3.5]$ sbin/start-dfs.sh
6-3 启动YARN
在配置了ResourceManager的节点(hadoop103)启动YARN
[antares@hadoop103 hadoop-3.3.5]$ sbin/start-yarn.sh
6-4 Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息(顶部导航栏Utilities下拉菜单)
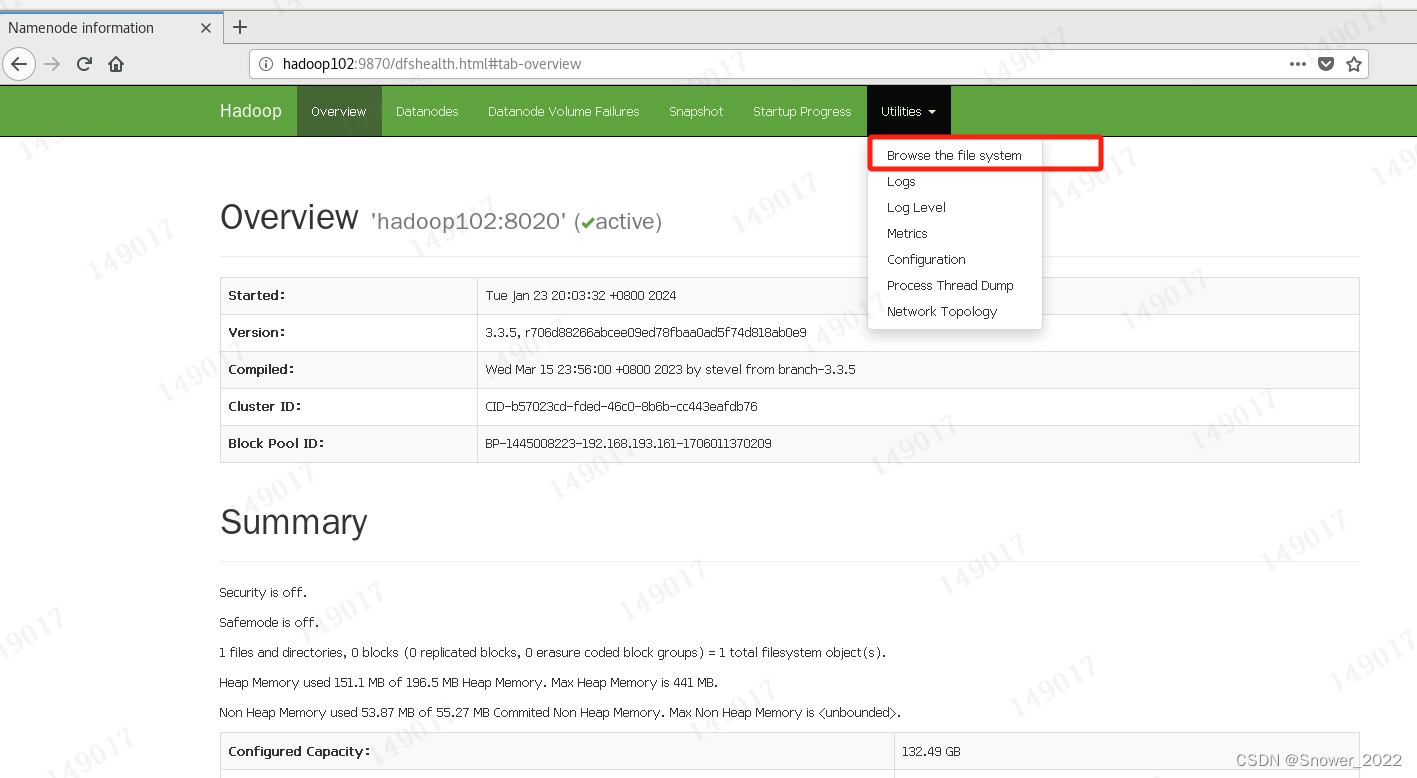
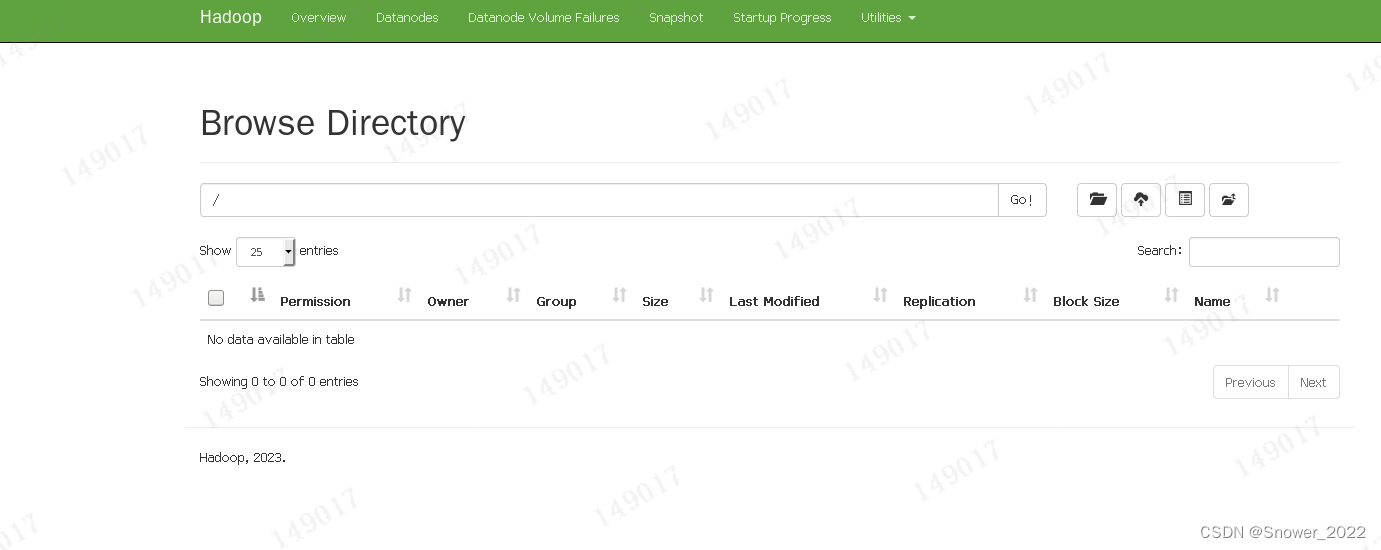
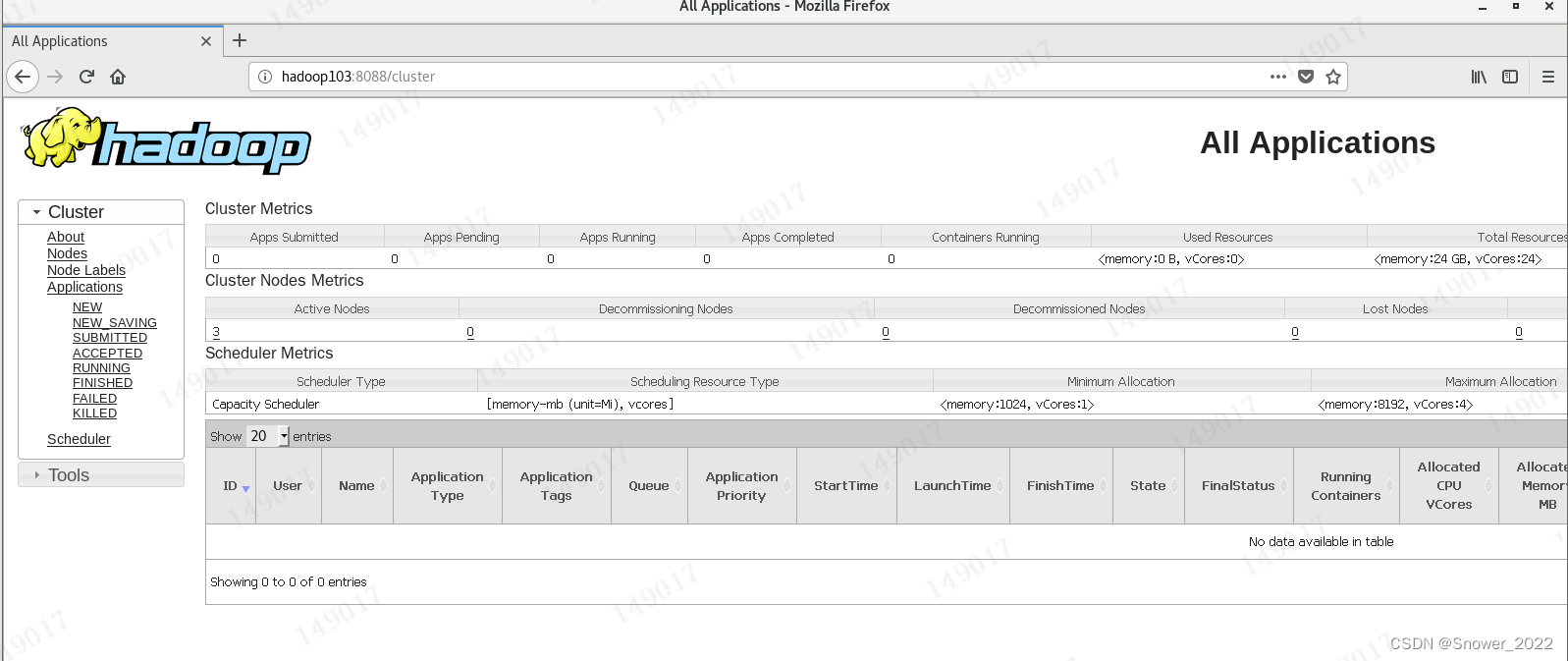
6-5 Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
七、集群基本测试
(1)上传文件到集群
Ø 上传小文件,在浏览器中查看文件内容
[antares@hadoop102 ~]$ hadoop fs -mkdir /test
[antares@hadoop102 ~]$ hadoop fs -put $HADOOP_HOME/testinput/kk.txt /test
put: `/opt/module/hadoop-3.3.5/testinput/kk.txt': No such file or directory若出现上述报错,可以找到$HADOOP_HOME 看下面有哪些目录有小文件
可以利用现有的文件夹重新上传小文件,建立了两个小文件:
[antares@hadoop102 ~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
[antares@hadoop102 ~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /test
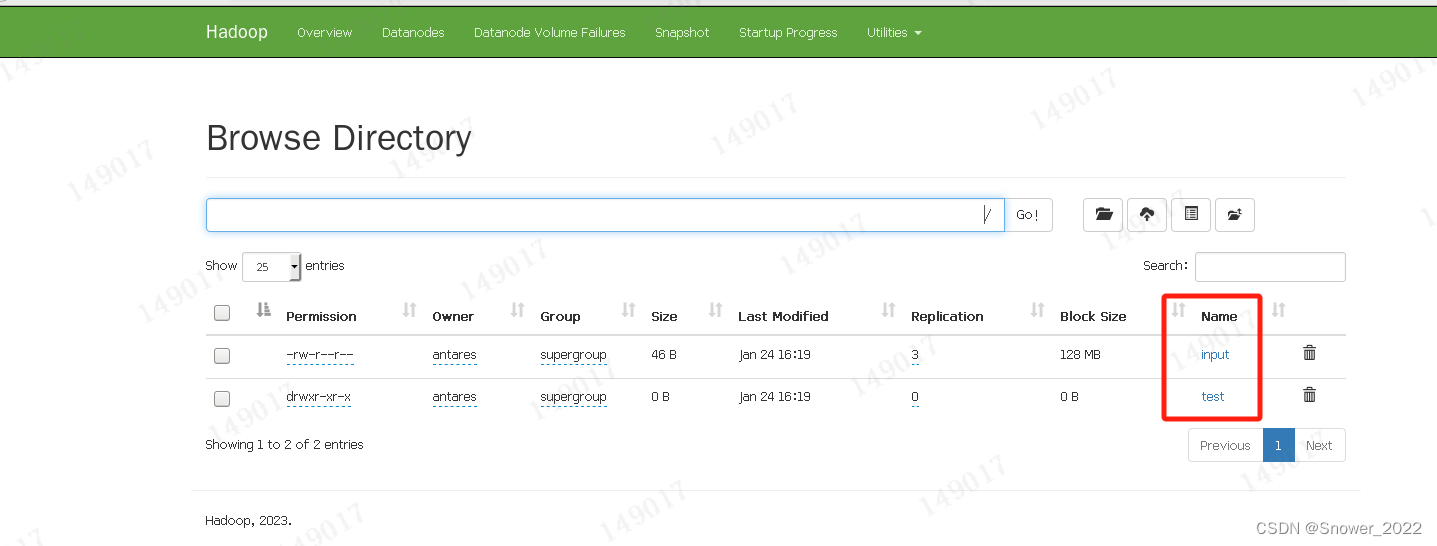
进入102资源的浏览器下查看上传的小文件情况
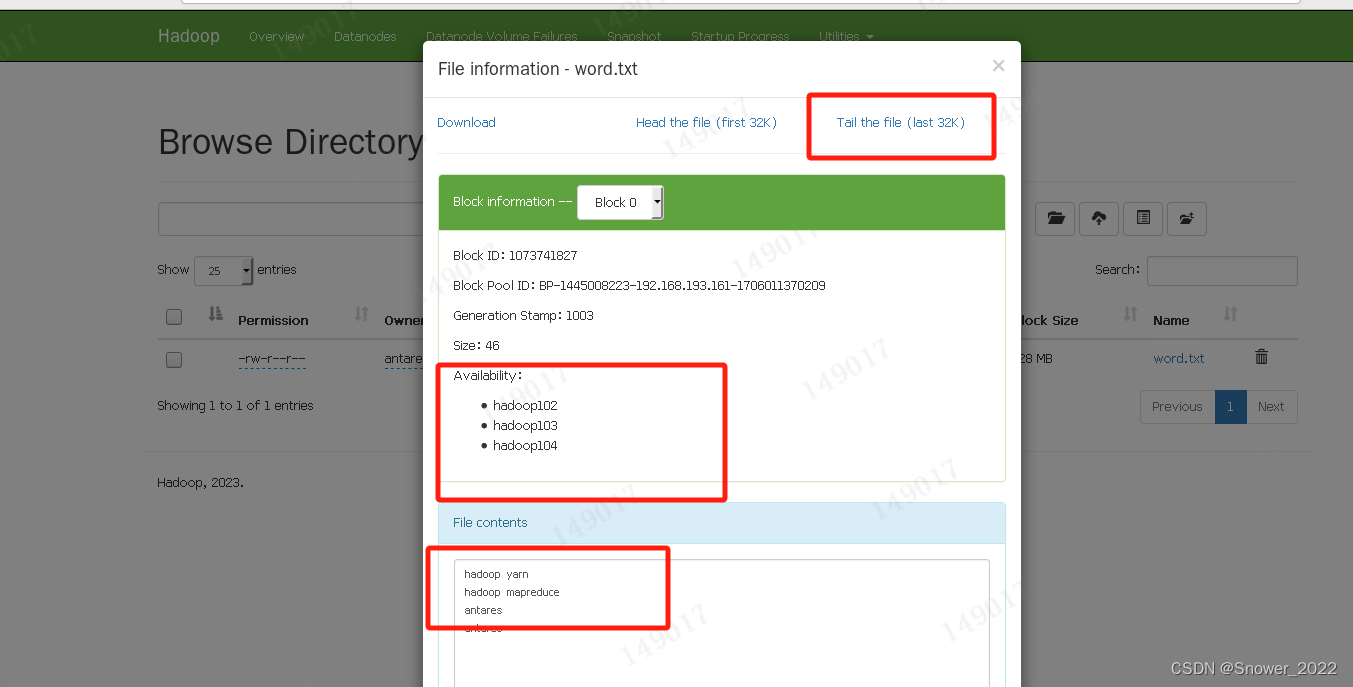
Ø 上传大文件,在浏览器中查看文件内容
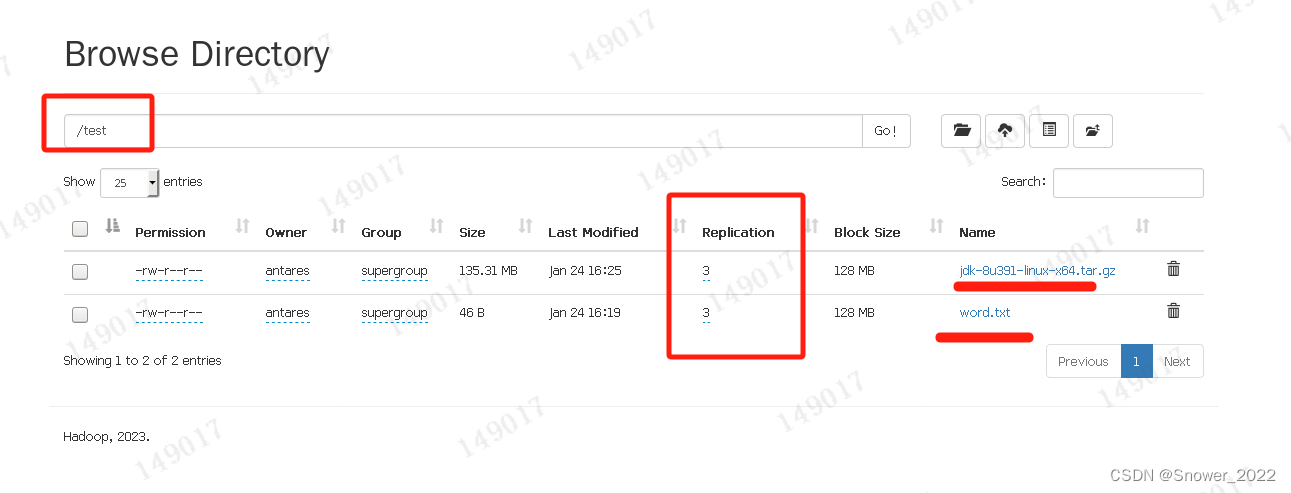
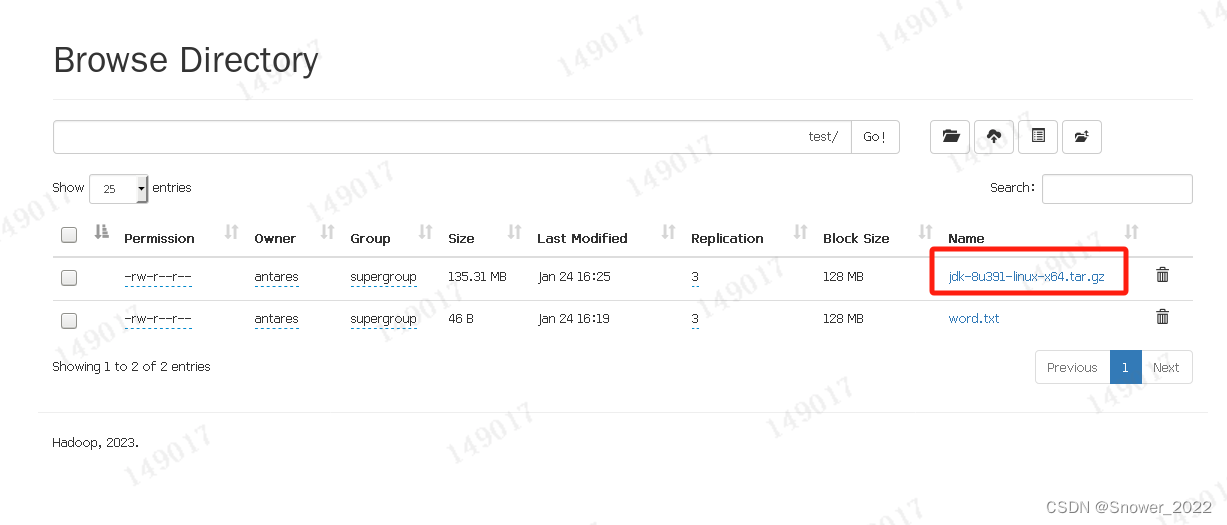
[antares@hadoop102 ~]$ hadoop fs -put /opt/software/jdk-8u391-linux-x64.tar.gz /test
下述浏览器可以看到该文件做了3个副本,相当于备份了3份。
上传文件后查看文件存放在什么位置-查看HDFS文件存储路径
[antares@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.3.5/data/dfs/data/current/BP-1445008223-192.168.193.161-1706011370209/current/finalized/subdir0/subdir0
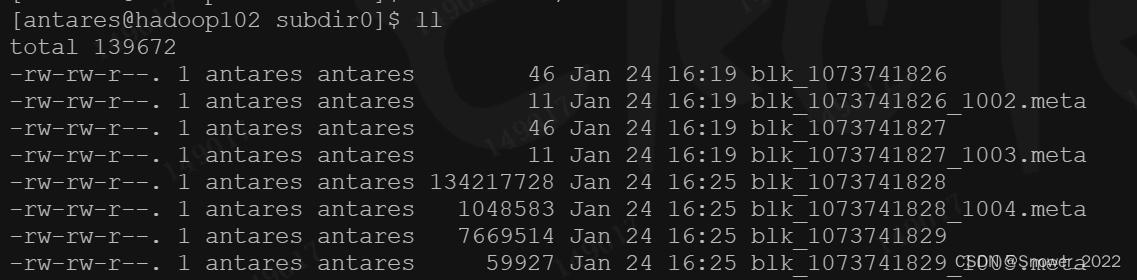
[antares@hadoop102 subdir0]$ cat blk_1073741826
小文件得时候不做切片,大文件会出现切片:
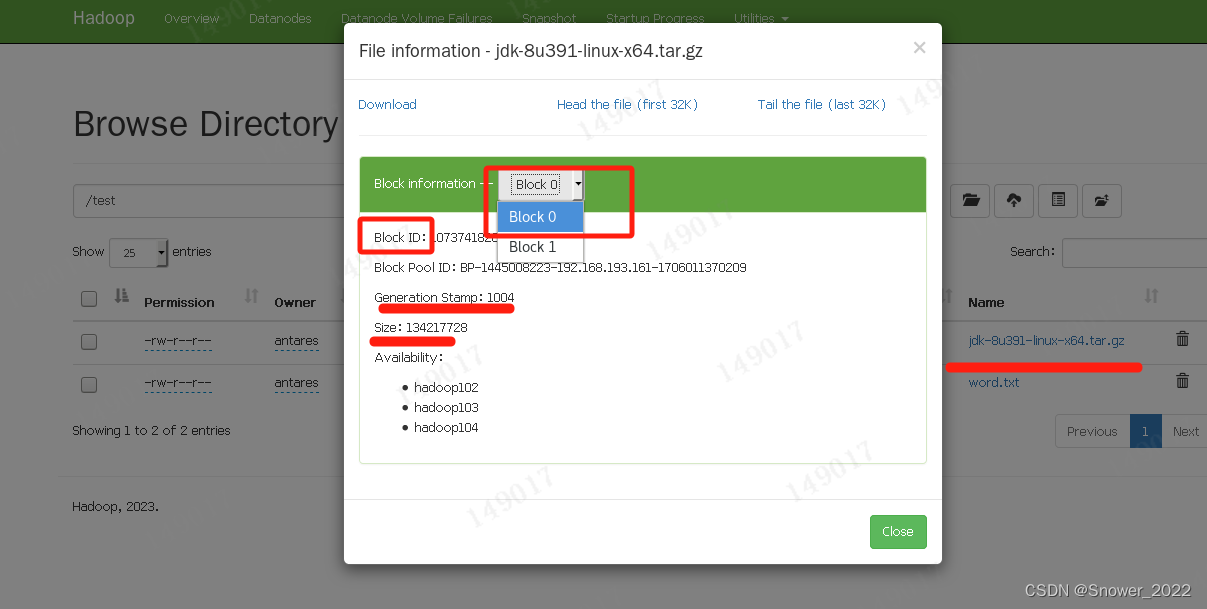

检查103 和 104 资源上的备份情况如下:
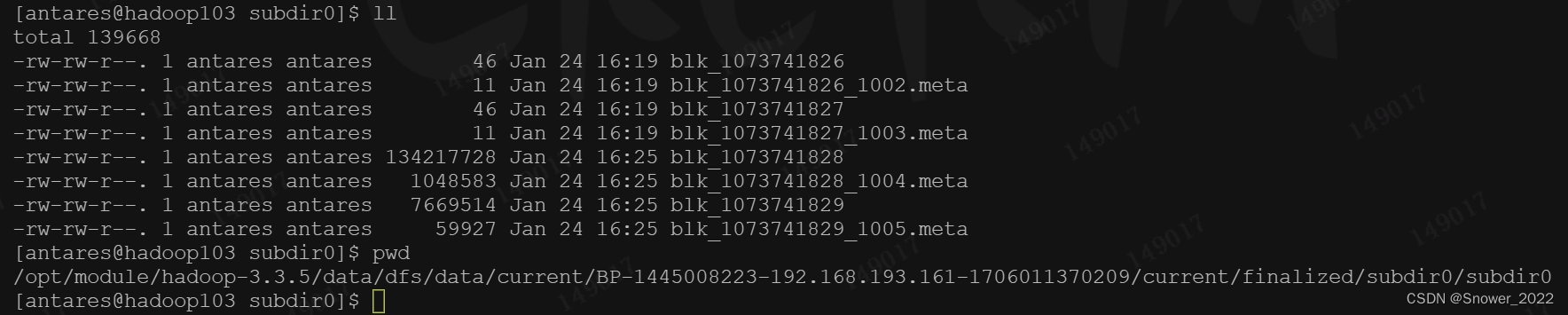
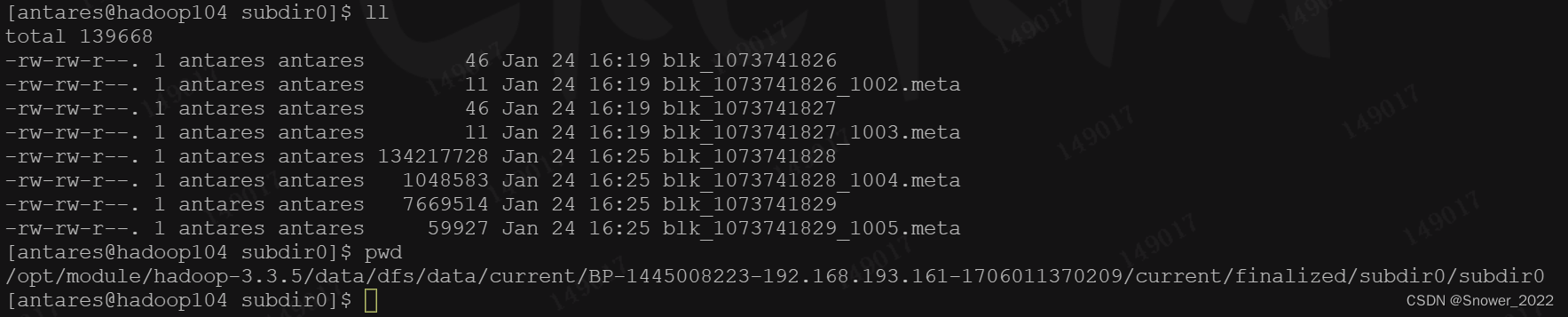
测试通过,集群搭建完成。