1 模型转换
从github上下载官方yolov8版本,当前使用的版本是2023年9月份更新的版本,作者一直在更新。官网地址
2 加载模型
模型的训练和测试在官方文档上,有详细的说明,yolov8中文文档这里不做过多说明,v8现在训练是真的方便了,环境部署好之后,几行代码就跑起来了,例如:
from ultralytics import YOLO
from setproctitle import setproctitle
setproctitle("python|yolov8-seg 20231211")
# 载入一个模型
model = YOLO('yolov8n-seg.yaml') # 从YAML构建一个新模型
# model = YOLO('/data/siping/preweights/yolov8n-seg.pt') # 载入预训练模型(推荐用于训练)
# model = YOLO('yolov8m-seg.yaml').load('/data/siping/preweights/yolov8m.pt') # 从YAML构建并传递权重
# 训练模型
model.train(task='segment',
data='/ultralytics/cfg/datasets/coco128-seg.yaml ',
epochs=200,
batch=32,
imgsz=320,
device=1,
translate=0
) # 训练模型
model.val()
# Export the model
model.export(format='onnx',imgsz=(320,320),opset=12)
模型训练完成后,对保存下来的best.pt模型转换为onnx模型,由于后期会部署到NX和其他不同类型的显卡上,因此先转换为通用的onnx模型。导出onnx代码:
# Export the model
model.export(format='onnx',imgsz=(384,640),opset=12)
导出的操作可以直接在训练的代码最后面加入一行即可。
onnx模型导出成功后,将模型拷贝到需要运行的机器上,使用tensorrt转换为trt模型,后缀可以是trt或者engine,转换代码这里总结了两个版本的转换代码:
Tensotrt 7.1:
# -*- coding: utf-8 -*-
import tensorrt as trt
import sys
import os
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
def printShape(engine):
for i in range(engine.num_bindings):
if engine.binding_is_input(i):
print("input layer: {}, shape is: {} ".format(i, engine.get_binding_shape(i)))
else:
print("output layer: {} shape is: {} ".format(i, engine.get_binding_shape(i)))
def onnx2trt(onnx_path, engine_path):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 28 # 256MB
#builder.set_fp16_mode(True)
#builder.precision = trt.BuilderFlag.FP16
#builder.config.set_flag(trt.BuilderFlag.FP16)
with open(onnx_path, 'rb') as model:
parser.parse(model.read())
engine = builder.build_cuda_engine(network)
printShape(engine)
with open(engine_path, "wb") as f:
f.write(engine.serialize())
if __name__ == "__main__":
#onnx文件路径设置
model_name = "20240115_yolov8Seg_Person"
input_path = model_name+".onnx"
#引擎文件保存路径设置
root_dir = "/ai/good_model/"
output_path = root_dir + model_name + '.engine'
onnx2trt(input_path, output_path)
一般是在NX上做模型转换,NX初始化的tensorrt版本较低,这个代码成功导出和部署使用。
tensorrt8.4.0.6版本转换代码:
# 导入必用依赖
import tensorrt as trt
#onnx文件路径设置
onnx_path="./repvgg.onnx"
#引擎文件保存路径设置
engine_path=r"classify.engine"
# 创建logger:日志记录器
logger = trt.Logger(trt.Logger.WARNING)
# 创建构建器builder
builder = trt.Builder(logger)
# 预创建网络
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
# 加载onnx解析器
parser = trt.OnnxParser(network, logger)
success = parser.parse_from_file(onnx_path)
for idx in range(parser.num_errors):
print(parser.get_error(idx))
if not success:
print("failed----------------")
pass # Error handling code here
# builder配置
config = builder.create_builder_config()
# 分配显存作为工作区间,一般建议为显存一半的大小
config.max_workspace_size = 12 << 30 # 1 Mi
builder.max_batch_size = 1
serialized_engine = builder.build_serialized_network(network, config)
# 序列化生成engine文件
with open(engine_path, "wb") as f:
f.write(serialized_engine)
print("generate file success!")
这个可以成功导出8.4以上版本的onnx模型,包括CNN的分类模型等。
如果是在windows下做模型导出和测试,可以直接去官网下载一个Tensorrt对应版本的包,直接使用trtexec导出也可以。
3 算法部署
yolov8的分割模型部署代码参考yolov8 github的测试代码
3.1 加载trt模型
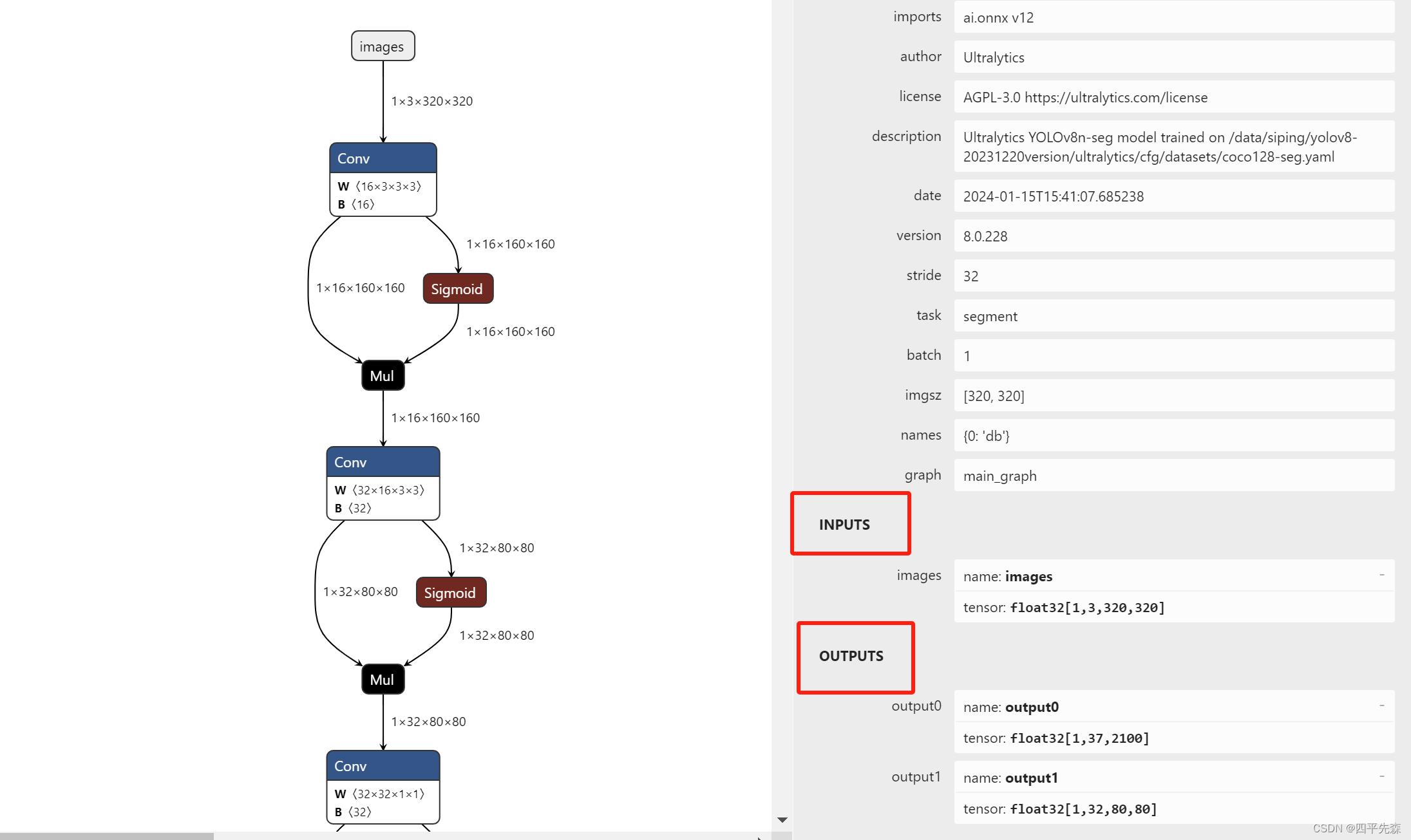
加载分割模型的trt模型需要注意的是模型的输入和输出的名称是否对应,可以将onnx模型通过netron查看模型的结构:
3.2 部署代码
部署是加载分割模型的代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cv2
import os
import torch
import numpy as np
import tensorrt as trt
from utils import ops
def select_device(device='', apex=False, batch_size=None):
# device = 'cpu' or '0' or '0,1,2,3'
cpu_request = str(device).lower() == 'cpu'
if str(device) and not cpu_request: # if device requested other than 'cpu'
os.environ['CUDA_VISIBLE_DEVICES'] = str(device) # set environment variable
assert torch.cuda.is_available(), 'CUDA unavailable, invalid device %s requested' % device # check availablity
cuda = False if cpu_request else torch.cuda.is_available()
if cuda:
c = 1024 ** 2 # bytes to MB
ng = torch.cuda.device_count()
if ng > 1 and batch_size: # check that batch_size is compatible with device_count
assert batch_size % ng == 0, 'batch-size %g not multiple of GPU count %g' % (batch_size, ng)
x = [torch.cuda.get_device_properties(i) for i in range(ng)]
s = 'Using CUDA ' + ('Apex ' if apex else '') # apex for mixed precision https://github.com/NVIDIA/apex
for i in range(0, ng):
if i == 1:
s = ' ' * len(s)
print("%sdevice%g _CudaDeviceProperties(name='%s', total_memory=%dMB)" %
(s, i, x[i].name, x[i].total_memory / c))
else:
print('Using CPU')
print('') # skip a line
return torch.device('cuda:0' if cuda else 'cpu')
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
DEVICE = select_device('0')
SEGLABELS = ['dbseg']
SEGWEIGHT = '20240115_yolov8Seg_lift.engine'
class TrtModelSeg():
def __init__(self, engine_path, device,shapes=(1, 3, 320, 320)):
"""
:param engine_path: Trt model path
:param device: torch.device
"""
self.device = device
from collections import OrderedDict, namedtuple
Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
logger = trt.Logger(trt.Logger.INFO)
with open(engine_path, 'rb') as f, trt.Runtime(logger) as runtime:
model = runtime.deserialize_cuda_engine(f.read())
self.context = model.create_execution_context()
self.bindings = OrderedDict()
dynamic = False
self.input_name = model.get_binding_name(0)
self.output_name = model.get_binding_name(1)
self.output_name1 = model.get_binding_name(2)
for index in range(model.num_bindings):
name = model.get_binding_name(index)
dtype = trt.nptype(model.get_binding_dtype(index))
# print(model.get_binding_shape(index))
if -1 in tuple(model.get_binding_shape(index)) and index == 0:
self.context.set_binding_shape(index, shapes)
shape = tuple(self.context.get_binding_shape(index))
data = torch.from_numpy(np.empty(shape, dtype=np.dtype(dtype))).to(select_device(device))
self.bindings[name] = Binding(name, dtype, shape, data, int(data.data_ptr()))
self.binding_addrs = OrderedDict((n, d.ptr) for n, d in self.bindings.items())
self.batch_size = self.bindings[self.input_name].shape[0]
def __call__(self, img):
"""
:param img: 输入Tensor 图片
:return:
"""
# assert img.shape == self.bindings['input'].shape, (img.shape, self.bindings['input'].shape)
if img.device == torch.device('cpu'):
img = img.float().to(select_device(self.device))
# print('in trt dynamic def----input shape is ----',img.shape)
self.binding_addrs[self.input_name] = int(img.data_ptr())
self.context.execute_v2(list(self.binding_addrs.values()))
return [self.bindings['output0'].data, self.bindings['output1'].data]
# 定义图片预处理函数
def get_input_img(image, img_size=[320, 320]):
# Padded resize
img,ratio,(dw,dh) = letterbox(image, img_size, stride=32, auto=False)
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
# img = img.transpose((2, 0, 1))[::-1]
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(DEVICE)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img,ratio,(dw,dh)
#分割模型
class YoloSeg(object):
def __init__(self,classes=[]):
self.conf_thr = 0.4 # conf阈值
self.iou_thr = 0.4 # iou阈值
self.model = self._load_model()
try:
self.labels = self.model.labels
print("Seg Using meta model ! ")
except:
self.labels = SEGLABELS
print("Seg Using no meta model ! ")
self.classes = self._get_display_class(classes) if classes and isinstance(classes, list) else None
self._warm_up(size=[320, 320])
def _load_model(self):
# Load seg model
print("Load seg model! ",SEGWEIGHT)
self.model = TrtModelSeg(SEGWEIGHT, DEVICE)
return self.model
def _get_display_class(self, classes):
"""只计算classes中包含的类别
Args:
classes (list): 只显示classes中包含的类别,其他类别将被遗弃
"""
return [self.labels.index(c) for c in classes if c in self.labels]
def _warm_up(self, size=[320, 320]):
x = torch.randn((1, 3, *size)).float().to(DEVICE)
self.model(x)
#参考yolov8 segment/predict.py文件
def detect_image(self, image):
# 预处理
img, ratio, (dw, dh) = get_input_img(image)
# Inference
preds = self.model(img)
detpred = preds[0]
masks = image
#1.经过置信度和非极大值筛选的数值 NMS
pred_nms = ops.non_max_suppression(detpred, self.conf_thr, self.iou_thr,nc=len(SEGLABELS))
retina_masks = True
proto = preds[1][-1] if len(preds[1]) == 3 else preds[1] # second output is len 3 if pt, but only 1 if exported
# print("proto: ",len(preds[1]),proto.shape)
print("pred_nms: ",len(pred_nms))
#从预测输出中提取结果
#pred_nms是掩码信息,如果有多个mask,选择面积最大的mask,因为是吊臂
for i, pred in enumerate(pred_nms):
print("len(pred): ", len(pred))
#获取原图像的大小
shape = image.shape
# print("image: ",shape)
if not len(pred): # save empty boxes
masks = None
elif retina_masks:
n_class = int(pred[:,5].item())
print("n_class: ",n_class,SEGLABELS[n_class])
#如果标签不等于db
if(n_class!=0):
continue
#对框坐标进行处理。
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], shape)
# print("pred[:, :4]: ",pred[:, :4])
# 对分割结果进行后处理,输入的是proto、pred:,6:,pred[:,:4]为框坐标img.shape[:2]为(320,320)四个数据
s_masks = ops.process_mask_native(proto[i], pred[:, 6:], pred[:, :4], shape[:2]) # HWC
# 从(batch_size, height, width)的形状转换为(height, width, batch_size)的形状,并将结果存储在NumPy数组中。
s_masks = (s_masks.cpu().numpy() * 255).astype(np.uint8)
masks = s_masks.transpose(1, 2, 0)
else:
masks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWC
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], shape)
print("pred,masks: ", masks.shape)
#返回预测结果和mask
return pred_nms,masks
def detect(yolo, image_path):
image = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), cv2.IMREAD_COLOR)
pred_nms, masks = yolo.detect_image(image)
return pred_nms, masks
if __name__ == '__main__':
image_path = r"1.jpg"
model = TrtModelSeg(SEGWEIGHT, DEVICE,shapes=(1, 3, 320, 320))
yoloseg = YoloSeg(SEGLABELS)
pred_nms, masks = detect(yoloseg,image_path)
cv2.imwrite("mask.jpg",masks)
ops.py文件:
# -*- coding: utf-8 -*-
# Ultralytics YOLO 🚀, AGPL-3.0 license
import contextlib
import math
import re
import time
import cv2
import numpy as np
import torch
import torch.nn.functional as F
import torchvision
class Profile(contextlib.ContextDecorator):
"""
YOLOv8 Profile class. Use as a decorator with @Profile() or as a context manager with 'with Profile():'.
Example:
```python
from ultralytics.utils.ops import Profile
with Profile() as dt:
pass # slow operation here
print(dt) # prints "Elapsed time is 9.5367431640625e-07 s"
```
"""
def __init__(self, t=0.0):
"""
Initialize the Profile class.
Args:
t (float): Initial time. Defaults to 0.0.
"""
self.t = t
self.cuda = torch.cuda.is_available()
def __enter__(self):
"""Start timing."""
self.start = self.time()
return self
def __exit__(self, type, value, traceback): # noqa
"""Stop timing."""
self.dt = self.time() - self.start # delta-time
self.t += self.dt # accumulate dt
def __str__(self):
"""Returns a human-readable string representing the accumulated elapsed time in the profiler."""
return f'Elapsed time is {self.t} s'
def time(self):
"""Get current time."""
if self.cuda:
torch.cuda.synchronize()
return time.time()
def segment2box(segment, width=640, height=640):
"""
Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy).
Args:
segment (torch.Tensor): the segment label
width (int): the width of the image. Defaults to 640
height (int): The height of the image. Defaults to 640
Returns:
(np.ndarray): the minimum and maximum x and y values of the segment.
"""
# Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
x, y = segment.T # segment xy
inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
x, y, = x[inside], y[inside]
return np.array([x.min(), y.min(), x.max(), y.max()], dtype=segment.dtype) if any(x) else np.zeros(
4, dtype=segment.dtype) # xyxy
def scale_boxes(img1_shape, boxes, img0_shape, ratio_pad=None, padding=True):
"""
Rescales bounding boxes (in the format of xyxy) from the shape of the image they were originally specified in
(img1_shape) to the shape of a different image (img0_shape).
Args:
img1_shape (tuple): The shape of the image that the bounding boxes are for, in the format of (height, width).
boxes (torch.Tensor): the bounding boxes of the objects in the image, in the format of (x1, y1, x2, y2)
img0_shape (tuple): the shape of the target image, in the format of (height, width).
ratio_pad (tuple): a tuple of (ratio, pad) for scaling the boxes. If not provided, the ratio and pad will be
calculated based on the size difference between the two images.
padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
rescaling.
Returns:
boxes (torch.Tensor): The scaled bounding boxes, in the format of (x1, y1, x2, y2)
"""
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = round((img1_shape[1] - img0_shape[1] * gain) / 2 - 0.1), round(
(img1_shape[0] - img0_shape[0] * gain) / 2 - 0.1) # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
if padding:
boxes[..., [0, 2]] -= pad[0] # x padding
boxes[..., [1, 3]] -= pad[1] # y padding
boxes[..., :4] /= gain
return clip_boxes(boxes, img0_shape)
def make_divisible(x, divisor):
"""
Returns the nearest number that is divisible by the given divisor.
Args:
x (int): The number to make divisible.
divisor (int | torch.Tensor): The divisor.
Returns:
(int): The nearest number divisible by the divisor.
"""
if isinstance(divisor, torch.Tensor):
divisor = int(divisor.max()) # to int
return math.ceil(x / divisor) * divisor
#NMS
def non_max_suppression(
prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300,
nc=0, # number of classes (optional)
max_time_img=0.05,
max_nms=30000,
max_wh=7680,
):
"""
Perform non-maximum suppression (NMS) on a set of boxes, with support for masks and multiple labels per box.
Args:
prediction (torch.Tensor): A tensor of shape (batch_size, num_classes + 4 + num_masks, num_boxes)
containing the predicted boxes, classes, and masks. The tensor should be in the format
output by a model, such as YOLO.
conf_thres (float): The confidence threshold below which boxes will be filtered out.
Valid values are between 0.0 and 1.0.
iou_thres (float): The IoU threshold below which boxes will be filtered out during NMS.
Valid values are between 0.0 and 1.0.
classes (List[int]): A list of class indices to consider. If None, all classes will be considered.
agnostic (bool): If True, the model is agnostic to the number of classes, and all
classes will be considered as one.
multi_label (bool): If True, each box may have multiple labels.
labels (List[List[Union[int, float, torch.Tensor]]]): A list of lists, where each inner
list contains the apriori labels for a given image. The list should be in the format
output by a dataloader, with each label being a tuple of (class_index, x1, y1, x2, y2).
max_det (int): The maximum number of boxes to keep after NMS.
nc (int, optional): The number of classes output by the model. Any indices after this will be considered masks.
max_time_img (float): The maximum time (seconds) for processing one image.
max_nms (int): The maximum number of boxes into torchvision.ops.nms().
max_wh (int): The maximum box width and height in pixels
Returns:
(List[torch.Tensor]): A list of length batch_size, where each element is a tensor of
shape (num_boxes, 6 + num_masks) containing the kept boxes, with columns
(x1, y1, x2, y2, confidence, class, mask1, mask2, ...).
"""
# Checks
#先判断设置的置信度和iou阈值是否在0和1之间,如不在,则报错是不符合要求的阈值。
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
#判读那输入的prediction类型,如果之前没有进行提取,则此处再进行提取,如提取过,则直接跳过。
if isinstance(prediction, (list, tuple)): # YOLOv8 model in validation model, output = (inference_out, loss_out)
prediction = prediction[0] # select only inference output
bs = prediction.shape[0] # batch size
nc = nc or (prediction.shape[1] - 4) # number of classes 获取类别数目nc,本文是1,其中nm为32是mask的数量
nm = prediction.shape[1] - nc - 4
mi = 4 + nc # mask start index mi为读取mask开始的位置,即数组前边是框、类别置信度,然后是mask
xc = prediction[:, 4:mi].amax(1) > conf_thres
# candidates xc为根据置信度分数从结果中筛选结果,即分数大于置信度的为True,小于的为False
# Settings
# min_wh = 2 # (pixels) minimum box width and height
time_limit = 0.5 + max_time_img * bs # seconds to quit after
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
prediction = prediction.transpose(-1, -2) # shape(1,84,6300) to shape(1,6300,84)
prediction[..., :4] = xywh2xyxy(prediction[..., :4]) # xywh to xyxy
t = time.time()
output = [torch.zeros((0, 6 + nm), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[:, 2:4] < min_wh) | (x[:, 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + nm + 4), device=x.device)
v[:, :4] = xywh2xyxy(lb[:, 1:5]) # box
v[range(len(lb)), lb[:, 0].long() + 4] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Detections matrix nx6 (xyxy, conf, cls)
box, cls, mask = x.split((4, nc, nm), 1)
if multi_label:
i, j = torch.where(cls > conf_thres)
x = torch.cat((box[i], x[i, 4 + j, None], j[:, None].float(), mask[i]), 1)
else: # best class only
conf, j = cls.max(1, keepdim=True)
x = torch.cat((box, conf, j.float(), mask), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
if n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence and remove excess boxes
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
i = i[:max_det] # limit detections
# # Experimental
# merge = False # use merge-NMS
# if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# # Update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
# from .metrics import box_iou
# iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
# weights = iou * scores[None] # box weights
# x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
# redundant = True # require redundant detections
# if redundant:
# i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING ⚠️ NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
"""
到此处,此幅图像经过了置信度阈值判断和非极大值抑制处理,确定了图像中的目标类别、分数和框的位置。
"""
return output
def clip_boxes(boxes, shape):
"""
Takes a list of bounding boxes and a shape (height, width) and clips the bounding boxes to the shape.
Args:
boxes (torch.Tensor): the bounding boxes to clip
shape (tuple): the shape of the image
Returns:
(torch.Tensor | numpy.ndarray): Clipped boxes
"""
if isinstance(boxes, torch.Tensor): # faster individually (WARNING: inplace .clamp_() Apple MPS bug)
boxes[..., 0] = boxes[..., 0].clamp(0, shape[1]) # x1
boxes[..., 1] = boxes[..., 1].clamp(0, shape[0]) # y1
boxes[..., 2] = boxes[..., 2].clamp(0, shape[1]) # x2
boxes[..., 3] = boxes[..., 3].clamp(0, shape[0]) # y2
else: # np.array (faster grouped)
boxes[..., [0, 2]] = boxes[..., [0, 2]].clip(0, shape[1]) # x1, x2
boxes[..., [1, 3]] = boxes[..., [1, 3]].clip(0, shape[0]) # y1, y2
return boxes
def clip_coords(coords, shape):
"""
Clip line coordinates to the image boundaries.
Args:
coords (torch.Tensor | numpy.ndarray): A list of line coordinates.
shape (tuple): A tuple of integers representing the size of the image in the format (height, width).
Returns:
(torch.Tensor | numpy.ndarray): Clipped coordinates
"""
if isinstance(coords, torch.Tensor): # faster individually (WARNING: inplace .clamp_() Apple MPS bug)
coords[..., 0] = coords[..., 0].clamp(0, shape[1]) # x
coords[..., 1] = coords[..., 1].clamp(0, shape[0]) # y
else: # np.array (faster grouped)
coords[..., 0] = coords[..., 0].clip(0, shape[1]) # x
coords[..., 1] = coords[..., 1].clip(0, shape[0]) # y
return coords
def scale_image(masks, im0_shape, ratio_pad=None):
"""
Takes a mask, and resizes it to the original image size.
Args:
masks (np.ndarray): resized and padded masks/images, [h, w, num]/[h, w, 3].
im0_shape (tuple): the original image shape
ratio_pad (tuple): the ratio of the padding to the original image.
Returns:
masks (torch.Tensor): The masks that are being returned.
"""
# Rescale coordinates (xyxy) from im1_shape to im0_shape
im1_shape = masks.shape
if im1_shape[:2] == im0_shape[:2]:
return masks
if ratio_pad is None: # calculate from im0_shape
gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
top, left = (int(round(pad[1] - 0.1)), int(round(pad[0] - 0.1))) # y, x
bottom, right = (int(round(im1_shape[0] - pad[1] + 0.1)), int(round(im1_shape[1] - pad[0] + 0.1)))
if len(masks.shape) < 2:
raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
masks = masks[top:bottom, left:right]
masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
if len(masks.shape) == 2:
masks = masks[:, :, None]
return masks
def xyxy2xywh(x):
"""
Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height) format where (x1, y1) is the
top-left corner and (x2, y2) is the bottom-right corner.
Args:
x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x1, y1, x2, y2) format.
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in (x, y, width, height) format.
"""
assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
y[..., 2] = x[..., 2] - x[..., 0] # width
y[..., 3] = x[..., 3] - x[..., 1] # height
return y
def xywh2xyxy(x):
"""
Convert bounding box coordinates from (x, y, width, height) format to (x1, y1, x2, y2) format where (x1, y1) is the
top-left corner and (x2, y2) is the bottom-right corner.
Args:
x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x, y, width, height) format.
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in (x1, y1, x2, y2) format.
"""
assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
dw = x[..., 2] / 2 # half-width
dh = x[..., 3] / 2 # half-height
y[..., 0] = x[..., 0] - dw # top left x
y[..., 1] = x[..., 1] - dh # top left y
y[..., 2] = x[..., 0] + dw # bottom right x
y[..., 3] = x[..., 1] + dh # bottom right y
return y
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
"""
Convert normalized bounding box coordinates to pixel coordinates.
Args:
x (np.ndarray | torch.Tensor): The bounding box coordinates.
w (int): Width of the image. Defaults to 640
h (int): Height of the image. Defaults to 640
padw (int): Padding width. Defaults to 0
padh (int): Padding height. Defaults to 0
Returns:
y (np.ndarray | torch.Tensor): The coordinates of the bounding box in the format [x1, y1, x2, y2] where
x1,y1 is the top-left corner, x2,y2 is the bottom-right corner of the bounding box.
"""
assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
y[..., 0] = w * (x[..., 0] - x[..., 2] / 2) + padw # top left x
y[..., 1] = h * (x[..., 1] - x[..., 3] / 2) + padh # top left y
y[..., 2] = w * (x[..., 0] + x[..., 2] / 2) + padw # bottom right x
y[..., 3] = h * (x[..., 1] + x[..., 3] / 2) + padh # bottom right y
return y
def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
"""
Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height, normalized) format. x, y,
width and height are normalized to image dimensions.
Args:
x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x1, y1, x2, y2) format.
w (int): The width of the image. Defaults to 640
h (int): The height of the image. Defaults to 640
clip (bool): If True, the boxes will be clipped to the image boundaries. Defaults to False
eps (float): The minimum value of the box's width and height. Defaults to 0.0
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in (x, y, width, height, normalized) format
"""
if clip:
x = clip_boxes(x, (h - eps, w - eps))
assert x.shape[-1] == 4, f'input shape last dimension expected 4 but input shape is {x.shape}'
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
y[..., 0] = ((x[..., 0] + x[..., 2]) / 2) / w # x center
y[..., 1] = ((x[..., 1] + x[..., 3]) / 2) / h # y center
y[..., 2] = (x[..., 2] - x[..., 0]) / w # width
y[..., 3] = (x[..., 3] - x[..., 1]) / h # height
return y
def xywh2ltwh(x):
"""
Convert the bounding box format from [x, y, w, h] to [x1, y1, w, h], where x1, y1 are the top-left coordinates.
Args:
x (np.ndarray | torch.Tensor): The input tensor with the bounding box coordinates in the xywh format
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in the xyltwh format
"""
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[..., 0] = x[..., 0] - x[..., 2] / 2 # top left x
y[..., 1] = x[..., 1] - x[..., 3] / 2 # top left y
return y
def xyxy2ltwh(x):
"""
Convert nx4 bounding boxes from [x1, y1, x2, y2] to [x1, y1, w, h], where xy1=top-left, xy2=bottom-right.
Args:
x (np.ndarray | torch.Tensor): The input tensor with the bounding boxes coordinates in the xyxy format
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in the xyltwh format.
"""
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[..., 2] = x[..., 2] - x[..., 0] # width
y[..., 3] = x[..., 3] - x[..., 1] # height
return y
def ltwh2xywh(x):
"""
Convert nx4 boxes from [x1, y1, w, h] to [x, y, w, h] where xy1=top-left, xy=center.
Args:
x (torch.Tensor): the input tensor
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in the xywh format.
"""
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[..., 0] = x[..., 0] + x[..., 2] / 2 # center x
y[..., 1] = x[..., 1] + x[..., 3] / 2 # center y
return y
def xyxyxyxy2xywhr(corners):
"""
Convert batched Oriented Bounding Boxes (OBB) from [xy1, xy2, xy3, xy4] to [xywh, rotation].
Args:
corners (numpy.ndarray | torch.Tensor): Input corners of shape (n, 8).
Returns:
(numpy.ndarray | torch.Tensor): Converted data in [cx, cy, w, h, rotation] format of shape (n, 5).
"""
is_numpy = isinstance(corners, np.ndarray)
atan2, sqrt = (np.arctan2, np.sqrt) if is_numpy else (torch.atan2, torch.sqrt)
x1, y1, x2, y2, x3, y3, x4, y4 = corners.T
cx = (x1 + x3) / 2
cy = (y1 + y3) / 2
dx21 = x2 - x1
dy21 = y2 - y1
w = sqrt(dx21 ** 2 + dy21 ** 2)
h = sqrt((x2 - x3) ** 2 + (y2 - y3) ** 2)
rotation = atan2(-dy21, dx21)
rotation *= 180.0 / math.pi # radians to degrees
return np.vstack((cx, cy, w, h, rotation)).T if is_numpy else torch.stack((cx, cy, w, h, rotation), dim=1)
def xywhr2xyxyxyxy(center):
"""
Convert batched Oriented Bounding Boxes (OBB) from [xywh, rotation] to [xy1, xy2, xy3, xy4].
Args:
center (numpy.ndarray | torch.Tensor): Input data in [cx, cy, w, h, rotation] format of shape (n, 5).
Returns:
(numpy.ndarray | torch.Tensor): Converted corner points of shape (n, 8).
"""
is_numpy = isinstance(center, np.ndarray)
cos, sin = (np.cos, np.sin) if is_numpy else (torch.cos, torch.sin)
cx, cy, w, h, rotation = center.T
rotation *= math.pi / 180.0 # degrees to radians
dx = w / 2
dy = h / 2
cos_rot = cos(rotation)
sin_rot = sin(rotation)
dx_cos_rot = dx * cos_rot
dx_sin_rot = dx * sin_rot
dy_cos_rot = dy * cos_rot
dy_sin_rot = dy * sin_rot
x1 = cx - dx_cos_rot - dy_sin_rot
y1 = cy + dx_sin_rot - dy_cos_rot
x2 = cx + dx_cos_rot - dy_sin_rot
y2 = cy - dx_sin_rot - dy_cos_rot
x3 = cx + dx_cos_rot + dy_sin_rot
y3 = cy - dx_sin_rot + dy_cos_rot
x4 = cx - dx_cos_rot + dy_sin_rot
y4 = cy + dx_sin_rot + dy_cos_rot
return np.vstack((x1, y1, x2, y2, x3, y3, x4, y4)).T if is_numpy else torch.stack(
(x1, y1, x2, y2, x3, y3, x4, y4), dim=1)
def ltwh2xyxy(x):
"""
It converts the bounding box from [x1, y1, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right.
Args:
x (np.ndarray | torch.Tensor): the input image
Returns:
y (np.ndarray | torch.Tensor): the xyxy coordinates of the bounding boxes.
"""
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[..., 2] = x[..., 2] + x[..., 0] # width
y[..., 3] = x[..., 3] + x[..., 1] # height
return y
def segments2boxes(segments):
"""
It converts segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
Args:
segments (list): list of segments, each segment is a list of points, each point is a list of x, y coordinates
Returns:
(np.ndarray): the xywh coordinates of the bounding boxes.
"""
boxes = []
for s in segments:
x, y = s.T # segment xy
boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
return xyxy2xywh(np.array(boxes)) # cls, xywh
def resample_segments(segments, n=1000):
"""
Inputs a list of segments (n,2) and returns a list of segments (n,2) up-sampled to n points each.
Args:
segments (list): a list of (n,2) arrays, where n is the number of points in the segment.
n (int): number of points to resample the segment to. Defaults to 1000
Returns:
segments (list): the resampled segments.
"""
for i, s in enumerate(segments):
s = np.concatenate((s, s[0:1, :]), axis=0)
x = np.linspace(0, len(s) - 1, n)
xp = np.arange(len(s))
segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)],
dtype=np.float32).reshape(2, -1).T # segment xy
return segments
#裁剪掩码mask 输入的是masks和downsampled_bboxes
def crop_mask(masks, boxes):
"""
It takes a mask and a bounding box, and returns a mask that is cropped to the bounding box.
Args:
masks (torch.Tensor): [n, h, w] tensor of masks
boxes (torch.Tensor): [n, 4] tensor of bbox coordinates in relative point form
Returns:
(torch.Tensor): The masks are being cropped to the bounding box.
确保masks的值在图像大小范围之内。
masks.gt_(0.5)判断masks中的值是否大于0.5,大于则为true。
"""
n, h, w = masks.shape
# print("n, h, w :",masks.shape)
#然后对boxes的内容进行拆分,torch.chunk(),拆分为四个,x1, y1, x2, y2
x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(n,1,1)
r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,1,w)
c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(1,h,1)
return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
def process_mask_upsample(protos, masks_in, bboxes, shape):
"""
Takes the output of the mask head, and applies the mask to the bounding boxes. This produces masks of higher quality
but is slower.
Args:
protos (torch.Tensor): [mask_dim, mask_h, mask_w]
masks_in (torch.Tensor): [n, mask_dim], n is number of masks after nms
bboxes (torch.Tensor): [n, 4], n is number of masks after nms
shape (tuple): the size of the input image (h,w)
Returns:
(torch.Tensor): The upsampled masks.
"""
c, mh, mw = protos.shape # CHW
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
masks = crop_mask(masks, bboxes) # CHW
#判断masks中的值是否大于0.5,大于则为true
return masks.gt_(0.5)
def process_mask(protos, masks_in, bboxes, shape, upsample=False):
"""
Apply masks to bounding boxes using the output of the mask head.
Args:
protos (torch.Tensor): A tensor of shape [mask_dim, mask_h, mask_w].
masks_in (torch.Tensor): A tensor of shape [n, mask_dim], where n is the number of masks after NMS.
bboxes (torch.Tensor): A tensor of shape [n, 4], where n is the number of masks after NMS.
shape (tuple): A tuple of integers representing the size of the input image in the format (h, w).
upsample (bool): A flag to indicate whether to upsample the mask to the original image size. Default is False.
Returns:
(torch.Tensor): A binary mask tensor of shape [n, h, w], where n is the number of masks after NMS, and h and w
are the height and width of the input image. The mask is applied to the bounding boxes.
"""
c, mh, mw = protos.shape # CHW
ih, iw = shape
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
downsampled_bboxes = bboxes.clone()
downsampled_bboxes[:, 0] *= mw / iw
downsampled_bboxes[:, 2] *= mw / iw
downsampled_bboxes[:, 3] *= mh / ih
downsampled_bboxes[:, 1] *= mh / ih
masks = crop_mask(masks, downsampled_bboxes) # CHW
if upsample:
masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
return masks.gt_(0.5)
def process_mask_native(protos, masks_in, bboxes, shape):
"""
It takes the output of the mask head, and crops it after upsampling to the bounding boxes.
Args:
protos (torch.Tensor): [mask_dim, mask_h, mask_w]
masks_in (torch.Tensor): [n, mask_dim], n is number of masks after nms
bboxes (torch.Tensor): [n, 4], n is number of masks after nms
shape (tuple): the size of the input image (h,w)
Returns:
masks (torch.Tensor): The returned masks with dimensions [h, w, n]
"""
c, mh, mw = protos.shape # CHW
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
masks = scale_masks(masks[None], shape)[0] # CHW
masks = crop_mask(masks, bboxes) # CHW
return masks.gt_(0.5)
def scale_masks(masks, shape, padding=True):
"""
Rescale segment masks to shape.
Args:
masks (torch.Tensor): (N, C, H, W).
shape (tuple): Height and width.
padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
rescaling.
"""
mh, mw = masks.shape[2:]
gain = min(mh / shape[0], mw / shape[1]) # gain = old / new
pad = [mw - shape[1] * gain, mh - shape[0] * gain] # wh padding
if padding:
pad[0] /= 2
pad[1] /= 2
top, left = (int(round(pad[1] - 0.1)), int(round(pad[0] - 0.1))) if padding else (0, 0) # y, x
bottom, right = (int(round(mh - pad[1] + 0.1)), int(round(mw - pad[0] + 0.1)))
masks = masks[..., top:bottom, left:right]
masks = F.interpolate(masks, shape, mode='bilinear', align_corners=False) # NCHW
return masks
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None, normalize=False, padding=True):
"""
Rescale segment coordinates (xy) from img1_shape to img0_shape.
Args:
img1_shape (tuple): The shape of the image that the coords are from.
coords (torch.Tensor): the coords to be scaled of shape n,2.
img0_shape (tuple): the shape of the image that the segmentation is being applied to.
ratio_pad (tuple): the ratio of the image size to the padded image size.
normalize (bool): If True, the coordinates will be normalized to the range [0, 1]. Defaults to False.
padding (bool): If True, assuming the boxes is based on image augmented by yolo style. If False then do regular
rescaling.
Returns:
coords (torch.Tensor): The scaled coordinates.
"""
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
if padding:
coords[..., 0] -= pad[0] # x padding
coords[..., 1] -= pad[1] # y padding
coords[..., 0] /= gain
coords[..., 1] /= gain
coords = clip_coords(coords, img0_shape)
if normalize:
coords[..., 0] /= img0_shape[1] # width
coords[..., 1] /= img0_shape[0] # height
return coords
def masks2segments(masks, strategy='largest'):
"""
It takes a list of masks(n,h,w) and returns a list of segments(n,xy)
Args:
masks (torch.Tensor): the output of the model, which is a tensor of shape (batch_size, 160, 160)
strategy (str): 'concat' or 'largest'. Defaults to largest
Returns:
segments (List): list of segment masks
"""
segments = []
for x in masks.int().cpu().numpy().astype('uint8'):
c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
if c:
if strategy == 'concat': # concatenate all segments
c = np.concatenate([x.reshape(-1, 2) for x in c])
elif strategy == 'largest': # select largest segment
c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
else:
c = np.zeros((0, 2)) # no segments found
segments.append(c.astype('float32'))
return segments
def convert_torch2numpy_batch(batch: torch.Tensor) -> np.ndarray:
"""
Convert a batch of FP32 torch tensors (0.0-1.0) to a NumPy uint8 array (0-255), changing from BCHW to BHWC layout.
Args:
batch (torch.Tensor): Input tensor batch of shape (Batch, Channels, Height, Width) and dtype torch.float32.
Returns:
(np.ndarray): Output NumPy array batch of shape (Batch, Height, Width, Channels) and dtype uint8.
"""
return (batch.permute(0, 2, 3, 1).contiguous() * 255).clamp(0, 255).to(torch.uint8).cpu().numpy()
def clean_str(s):
"""
Cleans a string by replacing special characters with underscore _
Args:
s (str): a string needing special characters replaced
Returns:
(str): a string with special characters replaced by an underscore _
"""
return re.sub(pattern='[|@#!¡·$€%&()=?¿^*;:,¨´><+]', repl='_', string=s)
#mask处理
def masks(img,masks, colors, im_gpu, alpha=0.5, retina_masks=False):
"""save masks at once.
Args:
masks (tensor): predicted masks on cuda, shape: [n, h, w]
colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
"""
if len(masks) == 0:
img = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
colors = colors[:, None, None] # shape(n,1,1,3)
masks = masks.unsqueeze(3) # shape(n,h,w,1)
masks_color = masks * (colors * alpha) # shape(n,h,w,3)
inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
im_gpu = im_gpu.flip(dims=[0]) # flip channel
im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
im_gpu = im_gpu * inv_alph_masks[-1] + mcs
im_mask = (im_gpu * 255)
im_mask_np = im_mask.byte().cpu().numpy()
img = im_mask_np if retina_masks else scale_image(im_gpu.shape, im_mask_np, img.shape)
其中上面代码中的opt是官方代码,在models/utils/ops.py中,直接拿过来用就行了,以上的推理代码也是参考的训练模型的代码中的models/segments/predict.py函数,最终完成模型的部署。
4 测试结果






![[HTML]Web前端开发技术9(HTML5、CSS3、JavaScript )——喵喵画网页](https://img-blog.csdnimg.cn/direct/784e413e30e5482d846131130665c21d.png)