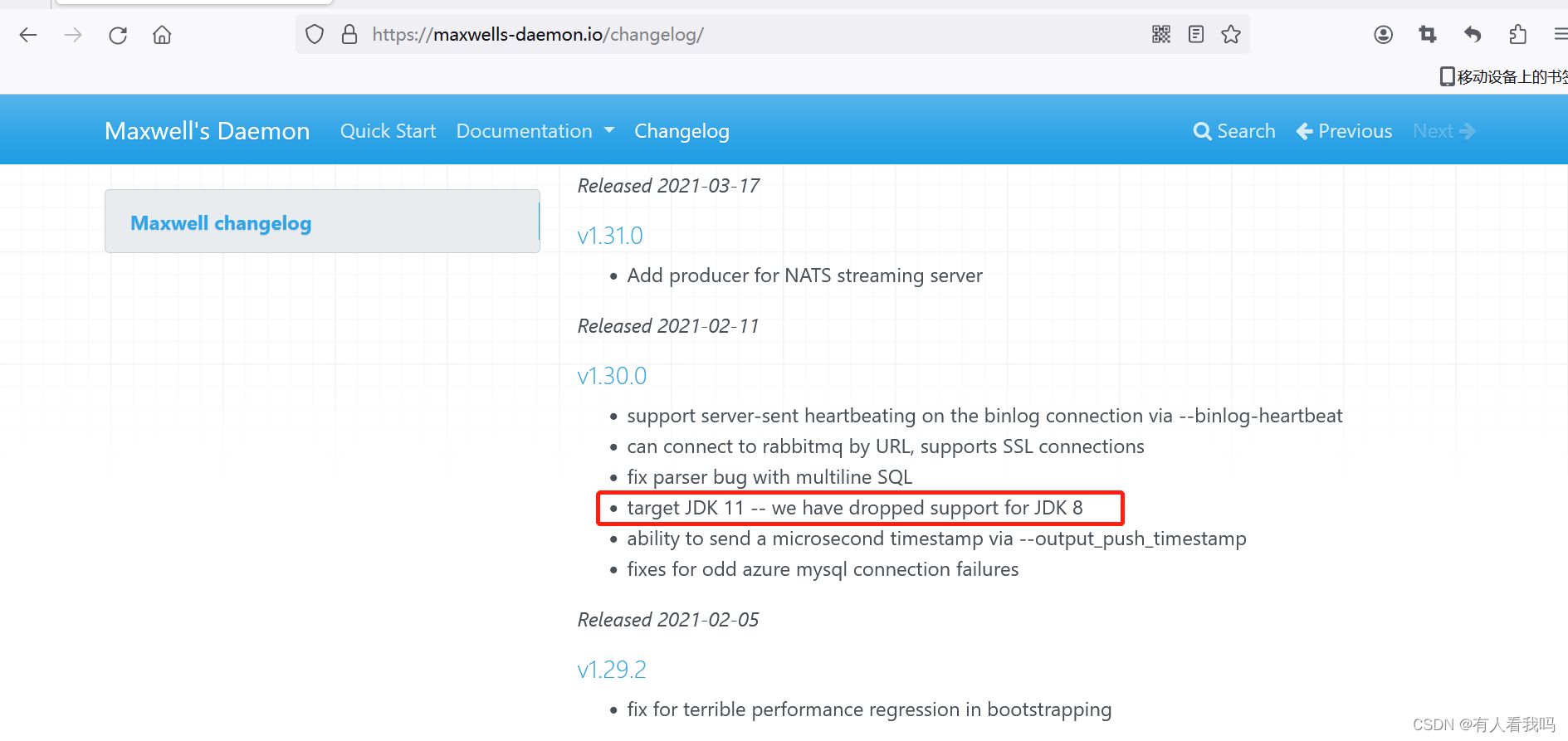
内存模型
因为
TaskManager
是负责执行用户代码的角色,一般配置
TaskManager
内存的情况会比较多,所以本文当作重点讲解。根据实际需求为 TaskManager
配置内存将有助于减少
Flink
的资源占用,增强作业运行的稳定性。
TaskManager
内存模型如下。
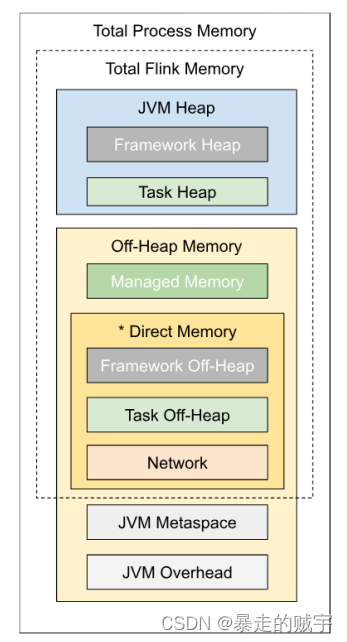
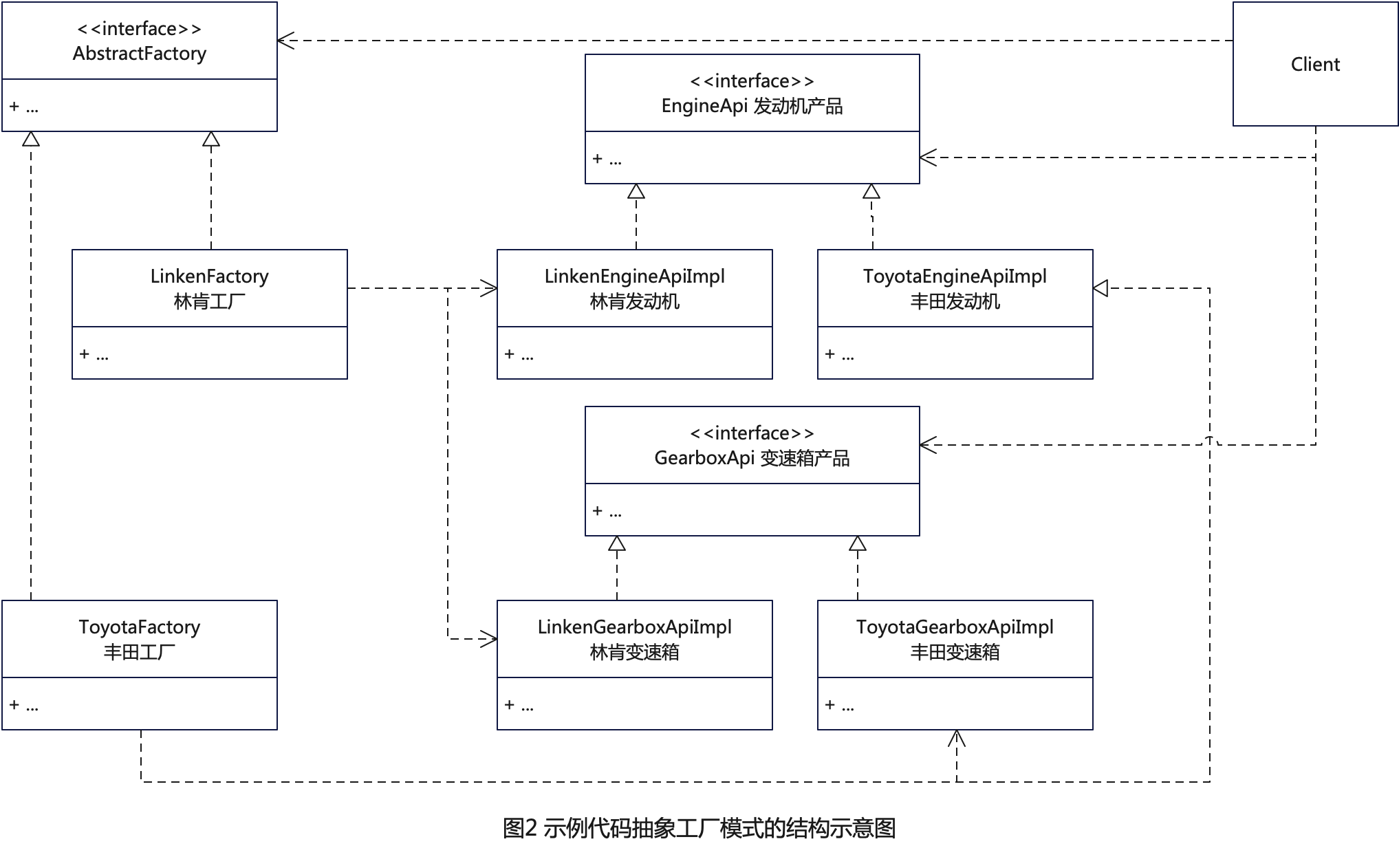
如上图所示,下表中列出了
Flink TaskManager
内存模型的所有组成部分,以及影响其大小的相关配置参数。

我们可以看到,有些内存部分的大小可以直接通过一个配置参数进行设置,有些则需要根据多个参数进行调整。
接下来,我们详细来看一下各个内存区域的含义、技术原理,以及
Flink
对它的默认值在什么场景下需要调整。
内存配置
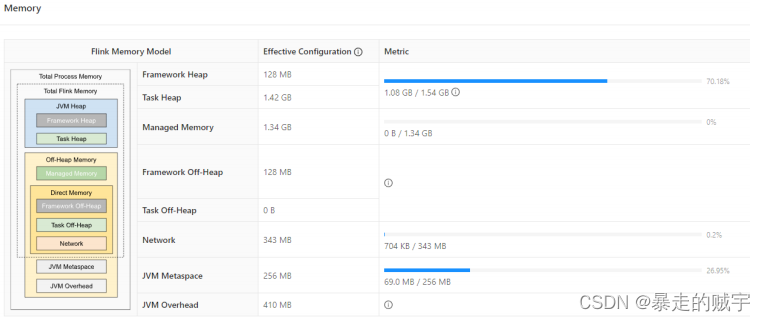
下图的左边标注了每个区域的配置参数名,右边则是一个调优后的、使用
HashMapStateBackend
的作业内存各区域的 容量限制:它和默认配置的区别在于 Managed Memory
部分被主动调整为
0
,后面我们会讲解何时需要调整各区域的大小,以最大化利用内存空间。

JVM 进程总内存(Total Process Memory)
该区域表示在容器环境下,
TaskManager
所在
JVM
的最大可用的内存配额,超用时可能被强制结束进程。我们可以通 过
taskmanager.memory.process.size
参数控制它的大小。
例如我们设置
JVM
进程总内存为
4G
,
TaskManager
运行在
YARN
平台,如果
yarn.nodemanager.pmem
-
check-
enabled
设为
true
,则也会在运行时定期检查容器内的进程是否超用内存。
如果进程总内存用量超出配额,容器平台通常会直接发送最严格的
SIGKILL
信号(相当于
kill
-
9
)来中止 TaskManager,此时不会有任何延期退出的机会,可能会造成作业崩溃重启、外部系统资源无法释放等严重后果。
因此,在有硬性资源配额检查
的容器环境下,请务必妥善设置该参数,对作业充分压测后,尽可能预留一部分安全余量,避免 TaskManager
频繁被
KILL
而导致的作业频繁重启。
Flink 总内存(Total Flink Memory)
该内存区域指的是
Flink
可以控制的内存区域,即上述提到的
JVM
进程总内存
减去
Flink
无法控制的
Metaspace
(元空 间)和 Overhead
(运行时开销)区域。
Flink
随后又把这部分内存区域划分为堆内、堆外(
Direct
)、堆外(
Managed
)等 不同子区域,后面我们会逐一讲解他们的配置指南。
对于没有硬性资源限制的环境,我们建议使用
taskmanager.memory.flink.size
参数来配置
Flink
总内存的大 小,然后 Flink
自己也会自动根据参数,计算得到各个子区域的配额。如果作业运行正常,则无需单独调整。
例如 4G
的
进程总内存
配置下,
JVM
运行时开销(
Overhead
)占
进程总内存
的
10%
但最多
1G
(下图是
409.6M
),元 空间(Metaspace
)占
256M
;堆外直接(
Direct
)内存网络缓存占
Flink
总内存
的
10%
但最多
1G
(下图是
343M
),框架堆 和框架堆外各占 128M
,堆外管控(
Managed
)内存占
Flink
总内存
的
40%
(下图是
1372M
即
1.34G
),其他空间留给任务堆,即用户程序代码可以使用的内存空间(1459M
即
1.42G
)。
JVM 堆内存(JVM Heap Memory)
堆内存大家想必都不陌生,它是由
JVM
提供给用户程序运行的内存区域,
JVM
会按需运行
GC
(垃圾回收器),协助 清理失效对象。
当任务启动时,
ProcessMemoryUtils#generateJvmParametersStr
方法会通过
-
Xmx
,
-
Xms
参数设置堆内存的最大容量。
Flink
将堆内存从逻辑上划分为
”
框架堆
“
、
”
任务堆
“
两个子区域,分别是:
框架堆内存(
Framework Heap Memory
)
:
taskmanager.memory.framework.heap.size
:默认是
128m
;
任务堆内存(
Task Heap Memory
)
:
taskmanager.memory.task.heap.size
:如果未显式设置其大小,则会通过 扣减其他区域配额来计算得到。例如对于 4G
的进程总内存,扣除了其他区域后,任务堆可用的只有不到
1.5G
。
但需要注意的是,
Flink
自身并不能精确控制框架自身及任务会用多少堆内存,因此上述配置项只提供理论上的计算依 据。如果实际用量超出配额,且 JVM
难以回收对象释放空间,则会抛出
OutOfMemoryError
,此时
Flink TaskManager
会退 出,导致作业崩溃重启。因此对于堆内存的监控是必须要配置的,当堆内存用量超过一定比率,或者 Full GC
时长和次数明显增长时,需要尽快介入并考虑扩容。
对于使用 HashMapStateBackend
(旧版本称之为
FileSystem StateBackend
)的流作业用户,如果在进程总内存固定的 前提下,希望尽可能提升任务堆的空间,则可以减少托管内存(
Managed Memory
)
的比例。
JVM 堆外内存(JVM Off-Heap Memory)
广义上的
堆外内存
指的是
JVM
堆之外的内存空间,而我们这里特指
JVM
进程总内存除了元空间(
Metaspace
)和运行 时开销(Overhead
)以外的内存区域。因为上述两个区域是
JVM
自行管理,
Flink
无法介入,我们后面单独划分和讲解。
托管内存(Managed Memory)
文章开头的总览图中,我们把托管内存区域设为
0
,此时任务堆空间约
3G
;而使用
Flink
默认配置时,任务堆只有 1.5G。这是因为默认情况下,托管内存占了
40%
的
Flink
总内存,导致堆内存可用的量变的相当少。因此我们非常有必要 了解什么是托管内存。
从官方文档和
Flink
源码上来看,托管内存主要有三大使用场景:
- 批处理算法,例如排序、HashJoin 等。他们会从 Flink 的 MemoryManager 请求内存片段(MemorySegment),而 MemoryManager 则会调用 UNSAFE.allocateMemory 分配堆外内存。
- RocksDB StateBackend,Flink 只会预留一部分空间并扣除预算,但是不介入实际内存分配。因此该类型的内存资源被 称为 OpaqueMemoryResource ,实际的内存分配还是由 JNI 调用的 RocksDB 自己通过 malloc 函数申请。
- PyFlink。与 JNI 类似,在与 Python 进程交互的过程中,也会用到一部分托管内存。
显然,对于普通的流式
SQL
作业,如果启用了
RocksDB
状态后端时,才会大量使用托管内存。因此如果您的
业务场
景并未用到
RocksDB
,那么可以
调小托管内存的相对比例
(
taskmanager.memory.managed.fraction
)
或绝对大小 (
taskmanager.memory.managed.size
),以
增大任务堆的空间
。
直接内存(Direct Memory)
直接内存是
JVM
堆外的一类内存,它提供了相对安全可控但又不受
GC
影响的空间,
JVM
参数是
- XX:MaxDirectMemorySize
。它主要用于:
- 框架堆外内存(Framework Off-heap Memory): taskmanager.memory.framework.off-heap.size 参数,默认 128M,例如 Sort-Merge Shuffle 算法所需的内存;
- 任务堆外内存(Task Off-heap Memory): taskmanager.memory.task.off-heap.size 参数,默认为 0,用于用户任务;
- 网络内存(Network Memory):Netty 对 Network Buffer 的网络传输,taskmanager.memory.network.fraction
等参数,默认
0.1
即
10%
的
Flink
总内存。该值必须在
taskmanager.memory.network.min=64mb
和
taskmanager.memory.network.max=infinite
之间。
在生产环境中,如果作业并行度非常大(例如大于
500
甚至
1000
),则需要调大
taskmanager.network.memory.floating
-
buffers
-
per
-
gate
和
taskmanager.network.memory.max
-
buffers
-
per-
channel
(例如从
8
调整到
1000
)和
taskmanager.network.memory.buffers
-
per
-
channel
(例如从
2
调整到 500),避免
Network Buffer
不足导致作业报错。
JVM 元空间(JVM Metaspace)
JVM Metaspace
主要保存了加载的类和方法的元数据,
Flink
配置的参数是
taskmanager.memory.jvm-
metaspace.size
,默认大小为
256M
,
JVM
参数是 -
XX:MaxMetaspaceSize
。
如果用户编写的
Flink
程序中,有大量的动态类加载的需求,例如一个用户作业,动态编译并加载了
44
万个类,此时 就容易出现元空间用量远超预期,发生 OOM
报错。此时就需要适当调大元空间的大小,或者优化用户程序,及时卸载无用的 Classloader
。
JVM 运行时开销(JVM Overhead)
除了上述描述的内存区域外,
JVM
自己还有一小块
”
自留地
“
,用来存放线程栈、编译的代码缓存、
JNI
调用的库所分 配的内存等等,Flink
配置参数是
taskmanager.memory.jvm
-
overhead.fraction
,默认是
JVM
总内存的
10%
。该值范 围必须在
taskmanager.memory.jvm
-
overhead.min=196mb
和
taskmanager.memory.jvm
-
overhead.max=1gb
之间。
对于旧版本(
1.9
及之前)的
Flink
,
RocksDB
通过
malloc
分配的内存也属于
Overhead
部分,而新版
Flink
把这部分归 类到托管内存(Managed
),因此在生产环境下,如果
RocksDB
频繁造成内存超用,除了调大
Managed
托管内存外,也可以考虑调大 Overhead
区空间,以留出更多的安全余量。
总结
JVM
进程总内存(
Total Process Memory
):
TaskManager
所在
JVM
的最大可用的内存配额。
- taskmanager.memory.process.size ,无默认值。
Flink
总内存(
Total Flink Memory
):用于
Flink
框架的
JVM
堆内存。
JVM
进程总内存减去
Flink
无法控制的
Metaspace 和 Overhead
区域。
JVM
堆内存(
JVM Heap Memory
):由
JVM
提供给用户程序运行的内存区域。
- 框架堆内存(Framework Heap Memory):
- taskmanager.memory.framework.heap.size ,默认 128mb
- 任务堆内存(Task Heap Memory):用于 Flink 应用的算子及用户代码的 JVM 堆内存。
- taskmanager.memory.task.heap.size ,无默认值,一般由计算得到。
JVM
堆外内存(
JVM Off-Heap Memory
):
- 托管内存(Managed Memory):由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地 内存。
- taskmanager.memory.managed.fraction ,按比例分配,默认 0.4(JVM 进程总内存的 40%);
- taskmanager.memory.managed.size , 按大小分配,无默认值。
直接内存(
Direct Memory
):
- 框架堆外内存(Framework Off-heap Memory):例如 Sort-Merge Shuffle 算法所需的内存。
- taskmanager.memory.framework.off-heap.size ,默认 128mb。
- 任务堆外内存(Task Off-heap Memory):用于用户任务。
- taskmanager.memory.task.off-heap.size ,默认 0 bytes。
- 网络内存(Network Memory):Netty 对 Network Buffer 的网络传输。
- taskmanager.memory.network.fraction ,默认 0.1(JVM 总内存的 10%)。该值必须在 taskmanager.memory.network.min=64mb 和 taskmanager.memory.network.max=infinite 之间。
JVM 元空间(JVM Metaspace):主要保存加载的类和方法的元数据。 taskmanager.memory.jvm-metaspace.size :默认 256mb。
JVM
运行时开销(
JVM Overhead
):
JVM
自己还有一小块
”
自留地
“
,用来存放线程栈、编译的代码缓存、
JNI
调用的库所分配的内存等等。
taskmanager.memory.jvm-
overhead.fraction
,默认
0.1
(
JVM
进程总内存的
10%
)。该值范围必须在
taskmanager.memory.jvm-
overhead.min=196mb
和
taskmanager.memory.jvm
-
overhead.max=1gb
之间。
调整建议
通常情况下,不建议对
框架堆内存
和
框架堆外内存
进行调整。除非你非常肯定
Flink
的内部数据结构及操作需要更多的内存
配置
Flink
内存最简单的方法就是配置总内存。此外,
Flink
也支持更细粒度的内存配置方式。
Flink
会根据默认值或其他配置参数自动调整剩余内存部分的大小。
运行命令时配置
JobManager
和
TaskManager
内存的方式如下。
bin/flink run-application -d \
-t yarn-application \
-Dyarn.application.queue=default \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=4096mb \
-Dtaskmanager.memory.managed.size=0mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.mrhelloworld.flink.java.wordcount.WordCountDemo \
/root/flink-quickstart-demo.jar
yarn.application.queue
:指定
YARN
队列;
jobmanager.memory.process.size
:指定
JobManager
总进程内存大小;
taskmanager.memory.process.size
:指定
TaskManager
的总进程内存大小,一般
2-8G
,
YARN
默认最大给
8G
;
taskmanager.numberOfTaskSlots
:指定
TaskManager
的
Slot
数。