1、请描述HBse的?
答:
- Memstore级别:当MemStore的大小达到设置阈值(默认128M),会触发flush操作。
1、HBase中Memstore在何时进行数据的flush操作?
答:
- Memstore级别:当MemStore的大小达到设置阈值(默认128M),会触发flush操作。
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
- Region级别:为了避免当前region中某个memstore数据量较少,无法触发flush;当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 2* 128M = 256M),会触发memstore刷新。
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>4</value>
</property>
- RegionServer级别:当一个Region Server中所有Memstore的大小总和超过低水位阈值hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size(前者默认值0.95),RegionServer开始强制flush;先Flush Memstore最大的Region,再执行次大的,依次执行;如写入速度大于flush写出的速度,导致总MemStore大小超过高水位阈值hbase.regionserver.global.memstore.size(默认为JVM内存的40%),此时RegionServer会阻塞更新并强制执行flush,直到总MemStore大小低于低水位阈值。
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
- 当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
- 定期刷新Memstore:默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000ms(20s)左右的随机延时。
- 手动刷新:用户可以通过shell命令
flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
2、请描述HBase的flush流程
答:
- HBase flush分为三个阶段,prepare、flush、commit。
- prepare阶段:添加updateLock锁,阻塞写请求。遍历MemStore,将MemStore中的数据集CellSkipSet做一个快照Snapshot。然后新建CellSkipListSet,用于保存后续的写入数据。阶段结束,释放updateLock锁。
- flush阶段:遍历所有的Memstore,将prepare阶段生成的snapshot文件持久化到.tmp目录下,生成临时文件,此过程相对耗时。
- commit阶段:遍历memstore,将临时文件移动到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。
3、请说出常见的HBase Shell使用命令
答:
- 帮助命令
# 所有命令
help
# 具体某个命令
help 'create'
- 数据定义命令
| 命令 | 描述 |
|---|---|
| create | 创建表 |
| alter | 修改表结构 |
| describe | 描述表结构 |
| exist | 确认表是否存在 |
| list | 显示所有表名列表 |
| disable/enable | 禁用/解禁一个表 |
| disable_all/enable_all | 禁用/解禁所有表 |
| is_disabled | 确认表是否被禁用 |
| drop/drop_all | 删除一个或全部表 |
| truncate | 禁用、删除并重建一个表 |
- 数据操作命令
| 命令 | 描述 |
|---|---|
| put | 添加一个值到单元格中 |
| get | 通过表名、行键等参数获取行或单元格数据 |
| scan | 遍历表并输出满足指定条件的行记录 |
| count | 计算表中的逻辑行数 |
| delete | 删除表中列族或列的数据 |
4、请描述HBase的布隆过滤器
答:
- 布隆过滤器可以用于快速判断一个数据是否存在一个集合中。它的原理是,创建一个长度为n的二进制数组,初始状态下值均为0;然后将当前集合中的数据进行哈希计算后,将数组中的对应位置变为1。比如,字符串"hbase"经过哈希计算后,值为3,那么将原数组[0,0,0,0,0]更改为[0,0,0,1,0]。那么,要查询的数据也会先经过哈希计算,在数组中快速寻找,如果已经置为1,说明数据可能在这个集合中,如果为0,说明一定不在集合中。
- 所以布隆过滤器是一种粗略的过滤手段。但因为它算法简单,使用的存储开销小,在大数据场景中是一种很不错的优化方式。
- 而且为了增加数据查询的准确性,一般会使用多个不同的哈希函数进行计算。比如,h1、h2、h3,这样会得到3个不同的位置,同时将其置为1。如果在查询数据时,同时发现这3个位置均为1,则说明很大的概率可以在当前集合中找到期望的数据,否则一定不在当前集合中。
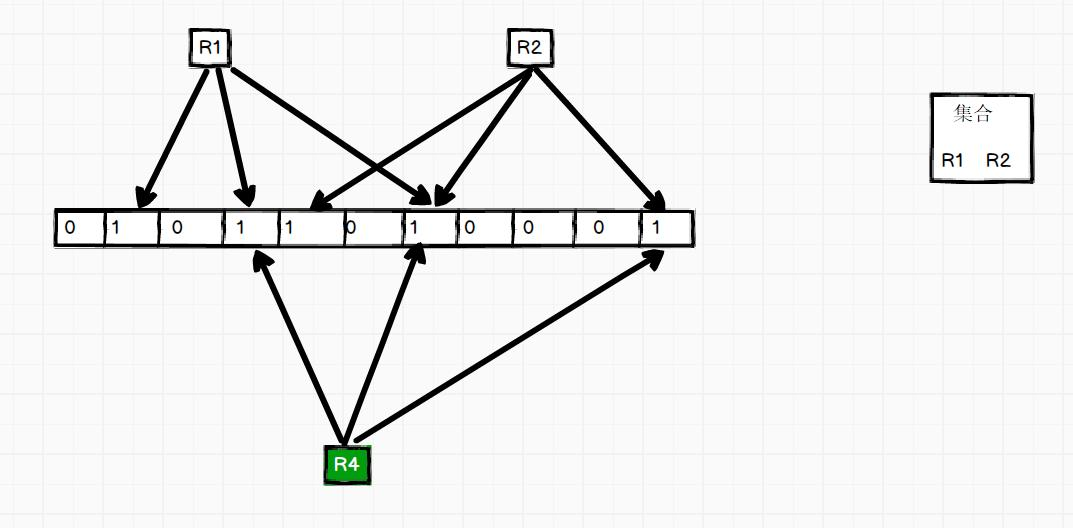
- 从HBase 0.96以来,默认启用基于行的Bloom Filters。在查询某行数据时,使用布隆过滤器可以快速排除一些HFile,以减少数据的读取量。
- 当然HBase除了默认的行级别(row)的布隆过滤器,也支持行+列级别(row+column)的。
- 如果经常扫描整行数据,可以使用row方式的布隆过滤器,此时也可以加快行+列的查询速度。
- 如果经常查询某行某列的数据,可以使用row+column方式的布隆过滤器,但它不会加快对整行数据的查询效率。而且除非这一行只有一列,否则row+column的布隆过滤器会占用较多的存储空间。所以,当每个数据至少为几千字节时,它的效果最好。
- 布隆过滤器需要在数据删除后重建,因此不适合有大量删除的环境。
- 可以使用命令,在列族上开启布隆过滤器。
create 'mytable',{NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
- 布隆过滤器存储在HFile的元数据中,当Region被部署到某个RegionServer中时,HFile会被读取,将布隆过滤器加载到内存中。
- 布隆过滤器开启后,在生产环境中是否有效,此时可以查看RegionServer中的blockCacheHitRatio值,如果开启后值增加,说明是正优化。
- 以上内容参考自官网,对应HBase 2.3版本。



![[Android]序列化原理Serializable](https://img-blog.csdnimg.cn/c096e680339c41f48b76798685da4b9b.png)