理解线程的概念
引入线程的背景
多进程模型的缺点
①、创建进程的过程会给操作系统带来相当沉重的复旦
②、为了完成进程间数据交换,需要特殊的IPC技术
③、每秒少则数十次、多则数千次的“上下文切换”是创建进程时最大的开销(主要)

线程和进程的差异

如果以获得多个代码执行流为主要目的,只需分离栈区域,即通过线程。这种方法的优势如下:
①、上下文切换时不需要切换数据区和堆
②、可以利用数据区和堆交换数据
线程为了保持多条代码执行流而隔开了栈区域:
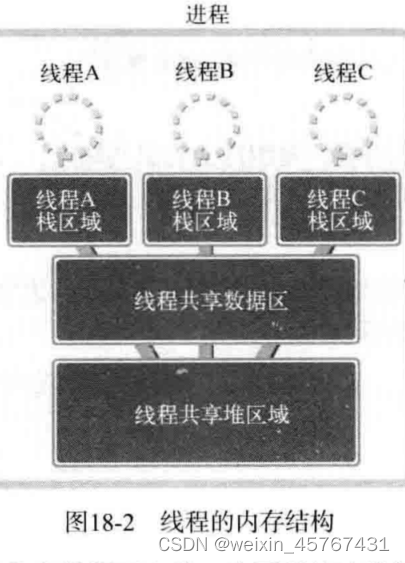
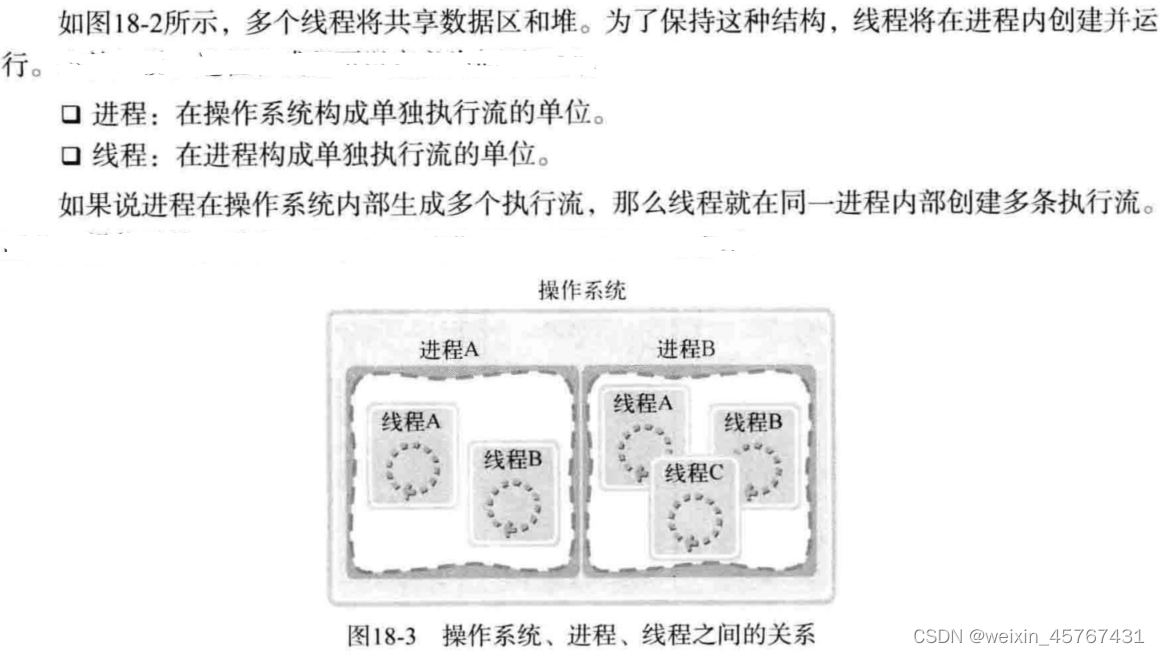
进程是资源分配的最小单位,线程是操作系统调度执行的最小单位。CPU分配时间片的单位是线程。
线程创建及运行
线程的创建和执行流程
每一个线程都有一个唯一的线程 ID,ID 类型为 pthread_t,这个 ID 是一个无符号长整形数,如果想要得到当前线程的线程 ID,可以调用如下函数:
pthread_t pthread_self(void); // 返回当前线程的线程ID在一个进程中调用线程创建函数,可以得到一个子线程,需要给每一个创建出的线程指定一个处理函数,否则这个线程无法工作。
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
// Compile and link with -pthread, 线程库的名字叫pthread, 全名: libpthread.so libptread.a参数:
thread: 传出参数,是无符号长整形数,线程创建成功,会将线程 ID 写入到这个指针指向的内存中
attr: 线程的属性,一般情况下使用默认属性即可,写 NULL
start_routine: 函数指针,创建出的子线程的处理动作,也就是该函数在子线程中执行。
arg: 作为实参传递到 start_routine 指针指向的函数内部
返回值:线程创建成功返回 0,创建失败返回对应的错误号
示例:thread1.c:
#include <stdio.h>
#include<unistd.h>
#include <pthread.h>
void* thread_main(void *arg);
int main(int argc, char *argv[])
{
pthread_t t_id;
int thread_param=5;
if(pthread_create(&t_id, NULL, thread_main, (void*)&thread_param)!=0)
{
puts("pthread_create() error");
return -1;
};
sleep(10); puts("end of main");
return 0;
}
void* thread_main(void *arg)
{
int i;
int cnt=*((int*)arg);
for(i=0; i<cnt; i++)
{
sleep(1); puts("running thread");
}
return NULL;
}![]()
线程相关代码在编译时需要添加-lpthread选项声明需要连接线程库,只有这样才能调用头文件pthread.h中声明的函数。
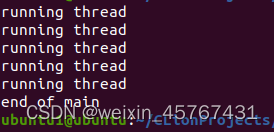
进程终止时会终止内部创建的线程,所以代码中增加了sleep语句

pthread_exit线程退出
在编写多线程程序的时候,如果想要让线程退出,但是不会导致虚拟地址空间的释放(针对于主线程),我们就可以调用线程库中的线程退出函数,只要调用该函数当前线程就马上退出了,并且不会影响到其他线程的正常运行,不管是在子线程或者主线程中都可以使用。
#include <pthread.h>
void pthread_exit(void *retval);参数:线程退出的时候携带的数据,当前子线程的主线程会得到该数据。如果不需要使用,指定为 NULL
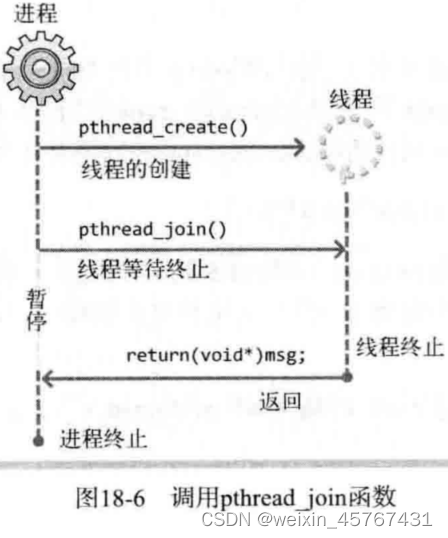
pthread_join线程回收
线程和进程一样,子线程退出的时候其内核资源主要由主线程回收,线程库中提供的线程回收函叫做 pthread_join(),这个函数是一个阻塞函数,如果还有子线程在运行,调用该函数就会阻塞,子线程退出函数解除阻塞进行资源的回收,函数被调用一次,只能回收一个子线程,如果有多个子线程则需要循环进行回收。
另外通过线程回收函数还可以获取到子线程退出时传递出来的数据
#include <pthread.h>
// 这是一个阻塞函数, 子线程在运行这个函数就阻塞
// 子线程退出, 函数解除阻塞, 回收对应的子线程资源, 类似于回收进程使用的函数 wait()
int pthread_join(pthread_t thread, void **retval);参数:
thread: 要被回收的子线程的线程 ID
retval: 二级指针,指向一级指针的地址,是一个传出参数,这个地址中存储了 pthread_exit () 传递出的数据,如果不需要这个参数,可以指定为 NULL
返回值:线程回收成功返回 0,回收失败返回错误号。
在子线程退出的时候可以使用 pthread_exit() 的参数将数据传出,在回收这个子线程的时候可以通过 phread_join() 的第二个参数来接收子线程传递出的数据。接收数据有很多种处理方式:
使用子线程栈
此种方式无法正确接收子线程传递出的数据。原因:如果多个线程共用一个虚拟地址空间,每个线程在栈区都有一块属于自己的内存,相当于栈区被这几个线程平分了,当线程退出时线程在栈区的数据也就被回收了,因此随着子线程的退出,写入到栈区的数据也就被释放了。例如:
// pthread_join.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
// 定义结构
struct Persion
{
int id;
char name[36];
int age;
};
// 子线程的处理代码
void* working(void* arg)
{
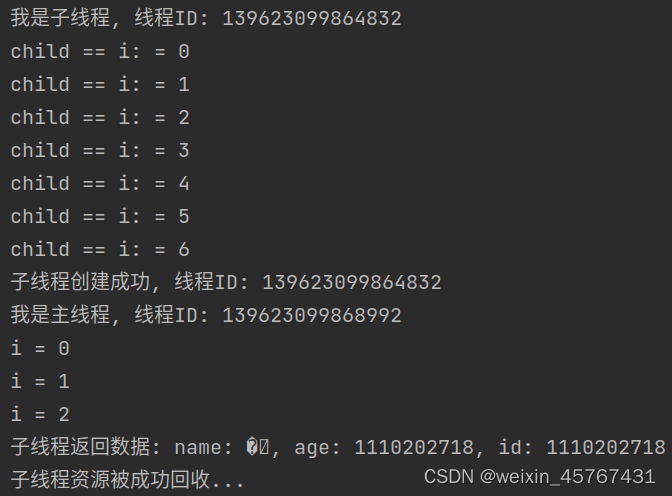
printf("我是子线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<9; ++i)
{
printf("child == i: = %d\n", i);
if(i == 6)
{
struct Persion p;
p.age =12;
strcpy(p.name, "tom");
p.id = 100;
// 该函数的参数将这个地址传递给了主线程的pthread_join()
pthread_exit(&p);
}
}
return NULL; // 代码执行不到这个位置就退出了
}
int main()
{
// 1. 创建一个子线程
pthread_t tid;
pthread_create(&tid, NULL, working, NULL);
printf("子线程创建成功, 线程ID: %ld\n", tid);
// 2. 子线程不会执行下边的代码, 主线程执行
printf("我是主线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<3; ++i)
{
printf("i = %d\n", i);
}
// 阻塞等待子线程退出
void* ptr = NULL;
// ptr是一个传出参数, 在函数内部让这个指针指向一块有效内存
// 这个内存地址就是pthread_exit() 参数指向的内存
pthread_join(tid, &ptr);
// 打印信息
struct Persion* pp = (struct Persion*)ptr;
printf("子线程返回数据: name: %s, age: %d, id: %d\n", pp->name, pp->age, pp->id);
printf("子线程资源被成功回收...\n");
return 0;
}
使用全局变量、静态变量或堆内存
位于同一虚拟地址空间中的线程,虽然不能共享栈区数据,但是可以共享全局数据区和堆区的数据,因此在子线程退出的时候可以将传出数据存储到全局变量、静态变量或者堆内存中。
使用全局变量的例子如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
// 定义结构
struct Persion
{
int id;
char name[36];
int age;
};
struct Persion p; // 定义全局变量
// 子线程的处理代码
void* working(void* arg)
{
printf("我是子线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<9; ++i)
{
printf("child == i: = %d\n", i);
if(i == 6)
{
// 使用全局变量
p.age =12;
strcpy(p.name, "tom");
p.id = 100;
// 该函数的参数将这个地址传递给了主线程的pthread_join()
pthread_exit(&p);
}
}
return NULL;
}
int main()
{
// 1. 创建一个子线程
pthread_t tid;
pthread_create(&tid, NULL, working, NULL);
printf("子线程创建成功, 线程ID: %ld\n", tid);
// 2. 子线程不会执行下边的代码, 主线程执行
printf("我是主线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<3; ++i)
{
printf("i = %d\n", i);
}
// 阻塞等待子线程退出
void* ptr = NULL;
// ptr是一个传出参数, 在函数内部让这个指针指向一块有效内存
// 这个内存地址就是pthread_exit() 参数指向的内存
pthread_join(tid, &ptr);
// 打印信息
struct Persion* pp = (struct Persion*)ptr;
printf("name: %s, age: %d, id: %d\n", pp->name, pp->age, pp->id);
printf("子线程资源被成功回收...\n");
return 0;
}
使用主线程栈
虽然每个线程都有属于自己的栈区空间,但是位于同一个地址空间的多个线程是可以相互访问对方的栈空间上的数据的。由于很多情况下还需要在主线程中回收子线程资源,所以主线程一般都是最后退出,基于这个原因在下面的程序中将子线程返回的数据保存到了主线程的栈区内存中。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
// 定义结构
struct Persion
{
int id;
char name[36];
int age;
};
// 子线程的处理代码
void* working(void* arg)
{
struct Persion* p = (struct Persion*)arg;
printf("我是子线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<9; ++i)
{
printf("child == i: = %d\n", i);
if(i == 6)
{
// 使用主线程的栈内存
p->age =12;
strcpy(p->name, "tom");
p->id = 100;
// 该函数的参数将这个地址传递给了主线程的pthread_join()
pthread_exit(p);
}
}
return NULL;
}
int main()
{
// 1. 创建一个子线程
pthread_t tid;
struct Persion p;
// 主线程的栈内存传递给子线程
pthread_create(&tid, NULL, working, &p);
printf("子线程创建成功, 线程ID: %ld\n", tid);
// 2. 子线程不会执行下边的代码, 主线程执行
printf("我是主线程, 线程ID: %ld\n", pthread_self());
for(int i=0; i<3; ++i)
{
printf("i = %d\n", i);
}
// 阻塞等待子线程退出
void* ptr = NULL;
// ptr是一个传出参数, 在函数内部让这个指针指向一块有效内存
// 这个内存地址就是pthread_exit() 参数指向的内存
pthread_join(tid, &ptr);
// 打印信息
printf("name: %s, age: %d, id: %d\n", p.name, p.age, p.id);
printf("子线程资源被成功回收...\n");
return 0;
}
在临界区内调用的函数
临界区的概念
临界区是指包含有共享数据的一段代码,这些代码可能被多个线程访问或修改。临界区的存在就是为了保证当有一个线程在临界区执行的时候,不能有其他任何线程被允许在临界区执行。
每个临界区都有相应的进入区和退出区。

为了保证临界资源的正确使用,可以把临界资源的访问过程分成四个部分:
进入区。为了进入临界区使用临界资源,在进入区要检查可否进入临界区,如果可以进入临界区,则应设置正在访问临界区的标志,以阻止其他进程同时进入临界区。
临界区。进程中访问临界资源的那段代码,又称临界段。
退出区。将正在访问临界区的标志清除。
剩余区。代码中的其余部分。
do {
entry section; //进入区
critical section; //临界区
exit section; //退出区
remainder section;
//剩余区
} while (true)根据临界区是否引起问题,函数可分为以下2类:
①线程安全函数
②非线程安全函数

可以在编译时通过添加-D_REENTRANT选项定义宏。
![]()
_REENTRANT的作用之一是对部分函数重新定义它们的可安全重入的版本,这些函数名字一般不会发生改变,只是会在函数名后面添加_r字符串,如函数名gethostbyname变成gethostbyname_r。
线程存在的问题和临界区
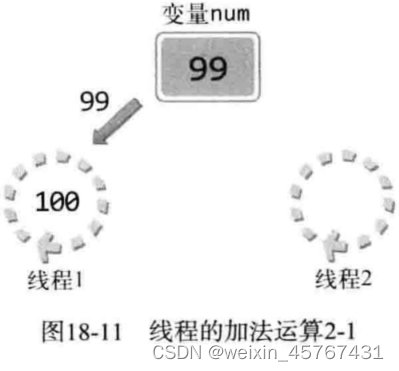
加法运算的理想情况
理想情况下每个线程轮流对变量进行加法运算



实际上可能出现的问题
可能在线程1完全增加num值之前,线程2有可能通过切换得到CPU资源


临界区位置
临界区的形式:函数内同时运行多个线程时引起问题的多条语句构成的代码块。
全局变量num是否应该视为临界区?不是!因为它不是引起问题的语句。该变量并非同时运行的语句,只是代表内存区域的声明。临界区通常位于由线程运行的函数内部。如下是两个由线程执行的函数:
void * thread_inc(void * arg)
{
int i;
for(i=0; i<50000000; i++)
num+=1;
return NULL;
}
void * thread_des(void * arg)
{
int i;
for(i=0; i<50000000; i++)
num-=1;
return NULL;
}

线程同步
线程同步用于解决线程访问顺序引发的问题,需要同步的情况从如下两方面考虑:
①同时访问同一内存空间
②需要指定访问同一内存空间的线程执行顺序

互斥量





线程退出临界区时,如果忘了调用pthread_mutex_unlock函数,那么其他为了进入临界区而调用pthread_mutex_unlock函数的线程就无法摆脱阻塞状态,这种情况称为“死锁”。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREAD 100
void * thread_inc(void * arg);
void * thread_des(void * arg);
long long num=0;
pthread_mutex_t mutex;
int main(int argc, char *argv[])
{
pthread_t thread_id[NUM_THREAD];
int i;
pthread_mutex_init(&mutex, NULL);
for(i=0; i<NUM_THREAD; i++)
{
if(i%2)
pthread_create(&(thread_id[i]), NULL, thread_inc, NULL);
else
pthread_create(&(thread_id[i]), NULL, thread_des, NULL);
}
for(i=0; i<NUM_THREAD; i++)
pthread_join(thread_id[i], NULL);
printf("result: %lld \n", num);
pthread_mutex_destroy(&mutex);
return 0;
}
void * thread_inc(void * arg)
{
int i;
pthread_mutex_lock(&mutex);
for(i=0; i<50000000; i++)
num+=1;
pthread_mutex_unlock(&mutex);
return NULL;
}
void * thread_des(void * arg)
{
int i;
for(i=0; i<50000000; i++)
{
pthread_mutex_lock(&mutex);
num-=1;
pthread_mutex_unlock(&mutex);
}
return NULL;
}

信号量



![]() 上述代码结构中,调用sem_wait函数进入临界区的线程在调用sem_post函数前不允许其他线程进入临界区,信号量的值在0和1之前,具有此种特性的机制称为“二进制信号量”。以下代码通过两个信号量控制线程对临界区的访问顺序:
上述代码结构中,调用sem_wait函数进入临界区的线程在调用sem_post函数前不允许其他线程进入临界区,信号量的值在0和1之前,具有此种特性的机制称为“二进制信号量”。以下代码通过两个信号量控制线程对临界区的访问顺序:
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
void * read(void * arg);
void * accu(void * arg);
static sem_t sem_one;
static sem_t sem_two;
static int num;
int main(int argc, char *argv[])
{
pthread_t id_t1, id_t2;
sem_init(&sem_one, 0, 0);
sem_init(&sem_two, 0, 1);
pthread_create(&id_t1, NULL, read, NULL);
pthread_create(&id_t2, NULL, accu, NULL);
pthread_join(id_t1, NULL);
pthread_join(id_t2, NULL);
sem_destroy(&sem_one);
sem_destroy(&sem_two);
return 0;
}
void * read(void * arg)
{
int i;
for(i=0; i<5; i++)
{
fputs("Input num: ", stdout);
sem_wait(&sem_two);
scanf("%d", &num);
sem_post(&sem_one);
}
return NULL;
}
void * accu(void * arg)
{
int sum=0, i;
for(i=0; i<5; i++)
{
sem_wait(&sem_one);
sum+=num;
sem_post(&sem_two);
}
printf("Result: %d \n", sum);
return NULL;
}线程的销毁和多线程并发服务器端的实现

多线程并发服务器端的实现
书上的代码有一些问题,做了些修改,放在这里作个参考
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <pthread.h>
#define BUF_SIZE 100
#define MAX_CLNT 256
void * handle_clnt(void * arg);
void send_msg(char * msg, int len);
void error_handling(char * msg);
int clnt_cnt=0;
int clnt_socks[MAX_CLNT];
pthread_mutex_t mutx;
int main(int argc, char *argv[])
{
int serv_sock, clnt_sock;
struct sockaddr_in serv_adr, clnt_adr;
int clnt_adr_sz;
pthread_t t_id;
if(argc!=2) {
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
pthread_mutex_init(&mutx, NULL);
serv_sock=socket(PF_INET, SOCK_STREAM, 0);
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family=AF_INET;
serv_adr.sin_addr.s_addr=htonl(INADDR_ANY);
serv_adr.sin_port=htons(atoi(argv[1]));
if(bind(serv_sock, (struct sockaddr*) &serv_adr, sizeof(serv_adr))==-1)
error_handling("bind() error");
if(listen(serv_sock, 5)==-1)
error_handling("listen() error");
while(1)
{
clnt_adr_sz=sizeof(clnt_adr);
clnt_sock=accept(serv_sock, (struct sockaddr*)&clnt_adr,&clnt_adr_sz);
pthread_mutex_lock(&mutx);
clnt_socks[clnt_cnt++]=clnt_sock;
pthread_mutex_unlock(&mutx);
pthread_create(&t_id, NULL, handle_clnt, (void*)&clnt_sock);
pthread_detach(t_id);
printf("Connected client IP: %s \n", inet_ntoa(clnt_adr.sin_addr));
}
close(serv_sock);
return 0;
}
void * handle_clnt(void * arg)
{
int clnt_sock=*((int*)arg);
int str_len=0, i;
char msg[BUF_SIZE];
while((str_len=read(clnt_sock, msg, sizeof(msg)))!=0)
send_msg(msg, str_len);
pthread_mutex_lock(&mutx);
for(i=0; i<clnt_cnt; i++) // remove disconnected client
{
if(clnt_sock==clnt_socks[i])
{
// while(i++<clnt_cnt-1)
// clnt_socks[i]=clnt_socks[i+1];
while(i<clnt_cnt-1) {
clnt_socks[i] = clnt_socks[i + 1];
i++;
}
break;
}
}
clnt_cnt--;
pthread_mutex_unlock(&mutx);
close(clnt_sock);
return NULL;
}
void send_msg(char * msg, int len) // send to all
{
int i;
pthread_mutex_lock(&mutx);
for(i=0; i<clnt_cnt; i++)
write(clnt_socks[i], msg, len);
pthread_mutex_unlock(&mutx);
}
void error_handling(char * msg)
{
fputs(msg, stderr);
fputc('\n', stderr);
exit(1);
}