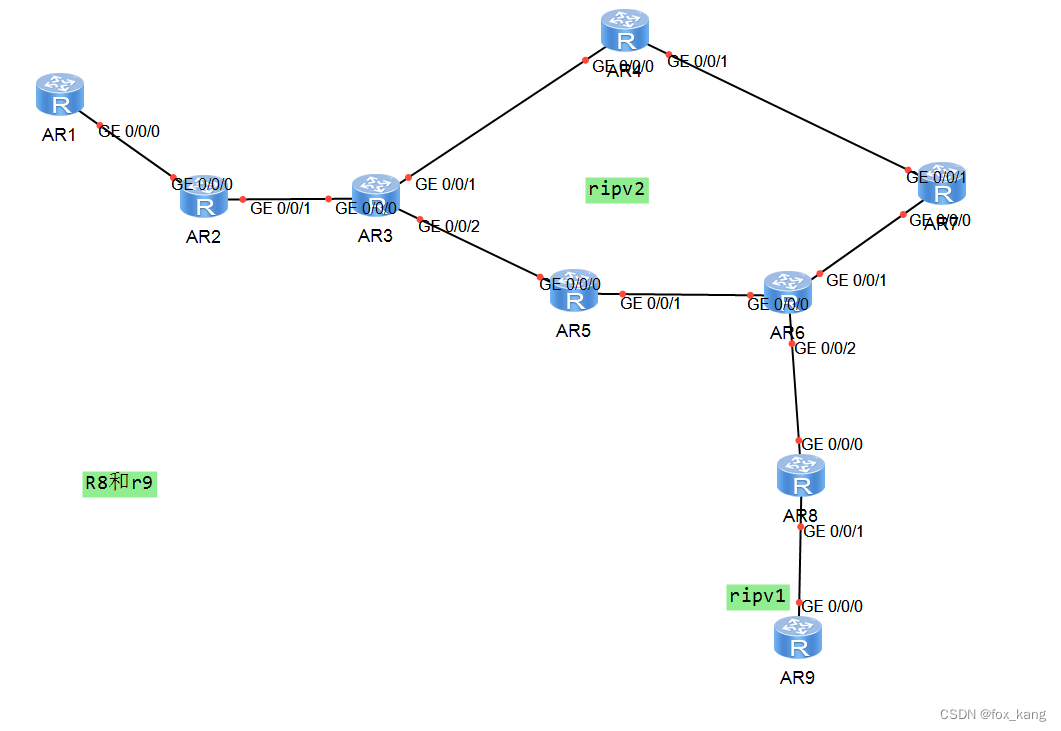
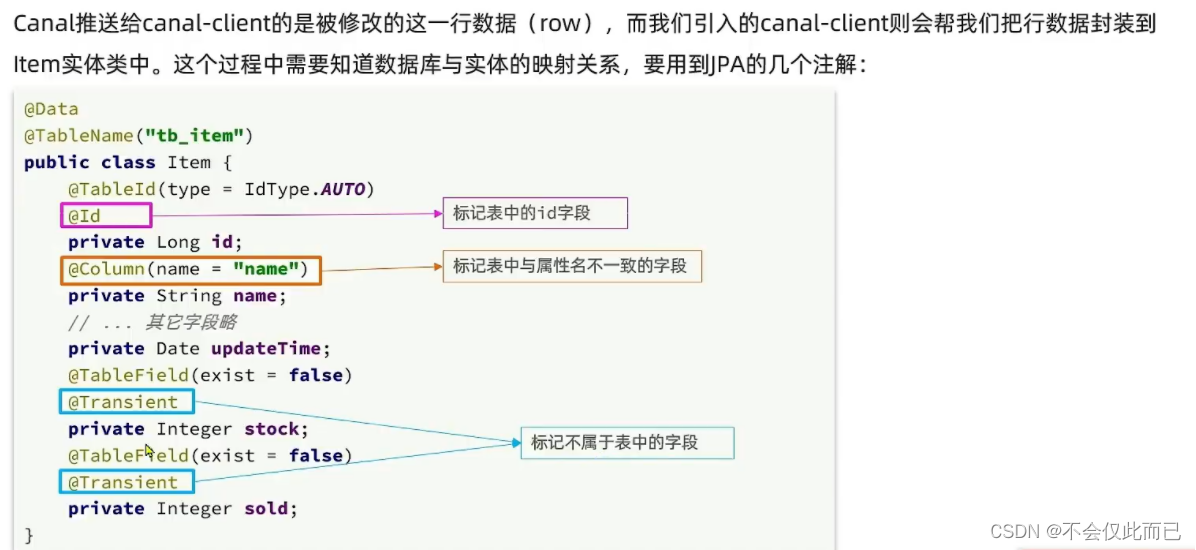
阿丹-需求/场景:
在项目场景中涉及到数据二次加工。需要将单个对象数据转为按照规定的数据字典的转换。以及需要转换数据结构。从对象转换为按照规定的值和规则的数组。
因为要写入csv文件,涉及到文件的输出流。
之前讨论针对的解决方案:
1、分页
2、流式数据读取加工
技术栈选择-原因(个人理解)
分页:
1、分页查询涉及到查询的效率
2、并且也存在内存问题,只是将一个大的内存改变成了小的任务
流式:
流式查询指的是查询成功后不是返回一个集合而是返回一个迭代器,应用每次从迭代器取一条查询结果。流式查询的好处是能够降低内存使用。
阿丹:所以直接使用流式查询直接一步到位。
实践!:
第一次尝试:
第一次尝试失败告终。
使用了单纯的流式查询,确实对于内存比较友好,但是出现问题为。
因为是流式的读取导致处理的速度太慢,并且因为是流式读取在大数据集的情况下有时间效率非常低。所以还是有点鸡肋的。
所以尝试看能不能在流式处理的过程中也考虑一下使用异步的方式多任务并行来处理。那么久涉及到了分页。于是有方案二。
第二次方式:
首先先解释一下流式查询是如何使用的:
我会将代码和逻辑展示出来其实逻辑还是比较简单的
流式查询使用:
//流式
dorisMapper.dorisjdbExportDownSQL(recordId,cDates,userId,saleIds,userName,taskId,status,sendMode,productId,checkTask,beginTime,endTime,parent,intercept,phoneCount,title,attribution_up,offset,limit,new ResultHandler<SmsDownEn>(){
/**
* 处理回调逻辑
*/
@Override
public void handleResult(ResultContext<? extends SmsDownEn> resultContext){
resultContext.getResultObject()//这里就可以获得数据对象
}
}
}); 解释:这里的handleResult为拿到的数据的指针也是拿到数据的回调函数,我们可以在这里来将数据一条一条拿出来并加工。
重点1:需要将整个流式读取使用数据库的事件来限制
StopWatch watch = new StopWatch();
watch.start();
/**
*这里写流式读取的代码块
*/
watch.stop();
重点2:mapper的xml中写法配置
一、构建映射resultmap

在指定resultmap的时候一定注意实体类的位置,要映射正确
二、查询语句添加配置
在MyBatis框架中,resultSetType属性用于配置结果集的读取方式。对于给出的 <select> 标签中的 resultSetType="FORWARD_ONLY" 配置:
"FORWARD_ONLY"表示结果集是只进向前类型的,也就是只能从前往后读取一次,不支持滚动和回溯操作。这是JDBC ResultSet默认的行为。
然而,这并不是配置流式读取(Streaming)的属性。MyBatis本身并不直接支持完全意义上的流式处理数据,因为它的设计目标更多在于将数据库查询结果映射到对象模型上。
若想实现类似流式读取的效果以提高大数据量下的内存效率,可以采用分页查询、延迟加载或者结合自定义的数据读取策略来避免一次性加载大量数据导致内存溢出。在某些特定场景下,可以通过逐行处理数据并及时释放资源的方式达到类似流式处理的目的,但这通常需要在具体的业务代码逻辑中进行控制和优化。
重点3:mapper中接口的方法携带必要参数
这个是必要的携带参数,其中的泛型类写成要映射的就可以了。
ResultHandler<SmsDownEn> resultHandler 这个是一个参数
并且注意在mapper的接口层面的时候,这个方法是没有返回值的,因为我们获取数据是从
resultContext中拿的所以不需要返回值。
展示一下接口代码:

这个参数是必须要带的,如果需要其他的条件查询等,和基础的一样直接在这里添加参数就可以了。
重点4:接口方法的使用
先看代码:
StopWatch watch = new StopWatch();
watch.start();
// 调用dorisMapper中的dorisjdbExportDownSQL方法并传入自定义的ResultHandler实现类
dorisMapper.dorisjdbExportDownSQL(new ResultHandler<SmsDownEn>() {
/**
* 处理回调逻辑
*/
@Override
public void handleResult(ResultContext<? extends SmsDownEn> resultContext) {
// 在这里获取并处理每一条查询结果
SmsDownEn smsDownEn = resultContext.getResultObject();
// 根据实际业务需求对smsDownEn进行处理
// ...
// 例如简单的打印处理
System.out.println(smsDownEn);
}
});
// 停止计时器
watch.stop();
解释:
其实就是在参数中直接new ResultHandler并重写handleResult方法。
使用resultContext获取流式的返回值上下文。
至此流式结束。
第二版逻辑说明:
1、先使用sql使用相同的导出条件来完成返回需要导出多少条数据
2、计算导出数据的分页信息,可以通过固定一个文件多少条数据的方式。通过需要导出的总条数计算每个分页开始的索引值。
3、使用多线程的方式来并行导出
总结:
方案二使用了分页和流式读取的两种方法来解决问题,希望可以解决一些同志们的工作问题。