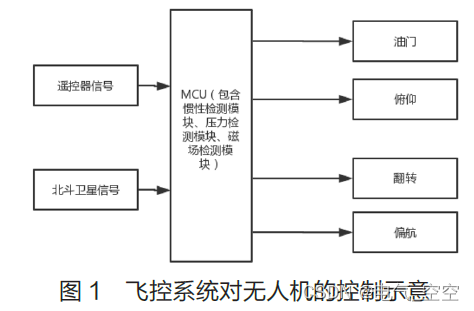
2019年认证杯SPSSPRO杯数学建模
基于统计建模的车险业数字变革研究
C题 保险业的数字化变革
原题再现:
车险,即机动车辆保险。保险自身是一种分散风险、消化损失的经济补偿制度,车险即为分散机动车辆在行驶过程中可能发作的未知风险和损失的一种保障机制。
目前国际车险分为国家强制的交强险和商业险,商业险中的根本险种有第三者责任事故险和车辆损失险。除此之外还有玻璃独自破碎险、车上人员责任险、全车盗抢险、自燃损失险和不计免赔特约条款等附加险种。
近年来,国际保险行业稳步开展,机动车辆保险在我国的财险保费中所占比重最大,以千亿元计。并且,由于我国汽车保有辆的继续增加和相关车险的政策出台,投保率也呈继续上升趋向。
车险一般可占财险公司业务的 70% 到 80%,所以车险市场历来是财险公司的兵家必争之地。以往,财险公司为了赢得市场,往往采取低价、折扣来争抢客户。但是激烈的市场竞争也带来了利润率的下降,甚至有些企业在亏本经营。大多数车企为了提高利润率开始重视承保车辆的质量。重投保车辆质量的做法,其实是险企科学发展的重要体现,是市场竞争下的企业合理行为。
中国目前的车险费率制度,大多数符合“从车主义”。即车险保费多少,主要取决于这辆车本身的各项情况,如车的购置价、座位数、排量、购车年限等,根据这些数据计算出一个基本的车险保费价格,再根据这辆车的上年理赔次数来打不同的折扣。这就导致了中国的车险定价模式非常的单调,相似情况的车型,保费也都差不多。
可以预见未来车险行业的几大发展趋势:
1. 车险价格与驾驶行为密切相关
未来的车险定价将逐渐转变为“从人主义”。车险的定价因素将直接与驾驶人的驾驶习惯与行驶里程挂钩,通过驾驶行为来判定车险价格,可能会使车险由原来的一年买一次变成可以一个月买一次。一个具有良好驾驶习惯的车主,可能只需要支付原本保费的 30% 左右,而驾驶习惯不佳的车主,则会在原本保费的基础上继续上涨。
2. 同价位车型车险价格完全不同
国内传统的汽车保险定价,通常是以车型和其购置价为主要依据。未来中国车险业,同样的一款车,不同的人开,保费价格会完全不同。这个不同可能是取决于投保人本身的驾驶行为,还可能会以投保人本身的年龄、职业、家庭状况等信息为标准。
信息时代的到来,为车险企业提供了一个更加有力的武器,可以通过数字化技术来更加精准地了解客户,制定营销和服务方案。
第二阶段问题:
1. 考虑到渠道和代理商为了保护自身利益,经常隐瞒一些客户信息,所以很多保险公司开始大力推进电销和网销,这样可以直接面对客户,获取一手信息。为了能够提高销售效率,降低客户等待时间,每次销售只能搜集客户三个方面的驾驶习惯信息。请结合第一阶段问题建立数学模型,讨论我们应该搜集哪三个方面的信息(当然是客户愿意提供的)?
2. 很多时候出险后的数据对于评价客户非常重要,简单地根据出险保费的额度来进行保费的调整显然缺少灵活性。如果我们在出险时能够抓住机会详细了解客户的驾驶习惯,势必更有价值。请结合前面的问题设计调查问卷,并建立数学模型阐述如何利用这个问卷的数据来提高续保概率。
3. 给保险公司的 CEO 写一封 1–2 页长短的信,陈述你对车险业在大数据环境下应如何发展的建议(与论文独立)。
整体求解过程概述(摘要)
保险的本质是对未来可能发生事故的风险做对冲,以起到分散风险的作用。车险作为保险的一种,它可以分散机动车辆在行驶过程中可能发生的未知风险和损失。现如今,车险已占据保险市场的重要份额,且随着大数据技术的发展,车险行业也开始了新一轮变革。如何利用销售机会和出险时机收集客户的驾驶习惯相关数据,大力推进电销和网销,提高销售效率和减少客户等待时间,进一步提高客户的续保概率就变得越来越重要。因此,本文在研读大量相关文献的基础上,对驾驶习惯信息的研究做了以下工作:
(1)针对问题一,首先在文献研读的基础上,从汽车使用量、驾驶表现和出行行为三个方面选取出 11 个客户驾驶习惯的指标;然后,基于 R 聚类分析方法对驾驶习惯指标进行分类,并运用 K-W检验方法检验分类的合理性;最后,对各个类别里的指标进行因子分析,建立基于 R 聚类-因子分析的驾驶人车险评价的指标筛选模型,筛选出三个方面的主要驾驶习惯指标,从而更加精准的为客户快速精准的提供相应的保单,增加客户的满意度,有效地提高汽车保险的销售效率。
(2)针对问题二,首先我们针对出险的客户,根据问题一中三个方面的驾驶习惯指标来设计调查问卷,收集客户的驾驶习惯相关数据,同时,本问卷加入是否愿意续保的问题;然后,通过建立卡方检验模型,对所有问题进行两两相互相关性分析,找出影响保险费率的因子,调整保险费率来进一步调整保费;最后,我们同理分析愿意续保的客户的驾驶习惯特征,通过通过降低保费和精准的找出客户群体两种销售手段来提高客户的续保概率。
(3)针对问题三,我们通过阅读大量相关文献与经典案例,总结出大数据环境下车险市场存在的问题,并进行详细的分析,对车险公司的 CEO 提出具有针对性的建议。
问题分析:
随着车联网技术的发展和我国汽车保险费率改革的不断深化调整,有关驾驶行为习惯的保险研究越来越受到关注。如何有效地通过搜集客户少量的驾驶行为习惯信息,使保险公司提高汽车保险销售的效率,同时降低客户等待时间,增加客户的满意度这一问题,已成为汽车保险公司目前所关注的重点。
近年来,汽车保险业务在财产保险公司中一直占据着十分重要的地位。按照同一车辆购买保险次数可以分为新增保单业务或者续保业务,续保业务有延续性,能够给保险公司带来更多的利益,所以对已购买车险的客户进行续保概率分析就比较重要。由于激烈的市场竞争导致车险业务的经营成本居高不下之外,车险费率厘定结果不够合理,从而导致根据出险的保费额度来进行保费的调整缺少灵活性,需要我们结合客户的驾驶习惯来提高客户的续保概率。针对汽车保险现在存在的现象进行如下分析:
问题一需要根据汽车保险的实际情况和阅读大量相关文献,结合第一阶段问题的所选取的驾驶习惯因子,利用 R 聚类分析法对涉及的驾驶习惯因子进行分类,再通过因子分析法对选取的驾驶行为习惯因子进行综合评价,建立基于 R 聚类-因子分析的驾驶人车险评价指标筛选模型。
问题二需要我们在问题一得出客户的驾驶行为习惯因子的基础上,合理设计客户在出险后的问卷调查表,以此来进一步提高客户的续保概率。因此,我们采用大量的文献研究法,设计合理的问卷调查,回收客户的驾驶习惯因子的相关数据,应用卡方检验模型对问卷的问题进行两两相关性分析,并利用建立的卡方检验模型得到影响保险率相关性较强的因子,通过对保费进行调整及精准营销,提高客户的续保率。
问题三需要我们对保险公司的 CEO 以信的形式,通过分析大数据技术在车险经营中所存在的问题,针对此现状,给出相对应的建议。
模型假设:
(1)假设所筛选的因子都满足模型建立的前提条件。
(2)假设筛选后的客户的特征能够反映总样本客户总体特征。
论文缩略图:


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
%macro consistn(where,part);
%let
var_list=dpt\sex_age\model\channel\ncd_renew\PL\seat1\accyr\combination
1;
data var(drop=va i);
va="&var_list.";
i=1;
do while (scan(va , i , "\")^="");
var=scan(va , i , "\");
call symputx(catt('var',i),var);
output;
i+1;
end;
i=i-1;
call symputx('var_num',i);
run;
proc summary data=temp&where. nway missing;
var EE ult_loss1 ep eg claimcount1;
output out=result(drop=_type_ _freq_)
sum=;
run;
data total;
set result;
format class $50.;
class= "Total";
format line_name $30. ;
line_name = "&line_list.";
call symputx("RP_TOTAL", ult_loss1/EE);
call symputx("LR_TOTAL", ult_loss1/ep);
call symputx("GR_TOTAL", ult_loss1/eg);
run;
%macro line(var_number);
data &line_list.;
set _null_;
run;
%do j=1%to&var_number.;
proc summary data=temp&where. nway missing;
class &&var&j;
var EE eg claimcount1 ult_loss1 ep;
output out=&&var&j (drop=_type_ _freq_)
sum=;
run;
data &&var&j;
format class $50.;
format class1 $50.;
set &&var&j;
class1=&&var&j;
class= "&&var&j";
drop &&var&j;
run;
data &line_list.;
set &line_list.&&var&j;
run;
%end;
proc sort data=&line_list. out=allfactor;
by class class1;
quit;
%mend line;
%line(&var_num.)
procgenmoddata=temp&where.ORDER=FREQ;
class&var_list_fre./desc;
model frequency = &var_list_fre. /dist=poisson link=log Type1Type3
SCALE=deviance ;
odsoutput parameterEstimates=frequency
ModelFit=aic_fre
type1 = type1_fre
type3 = type3_fre;
weight EE;
run;
procgenmoddata=temp&where.ORDER=FREQ;
class&var_list_sev./desc;
model severity = &var_list_sev. /dist=Gamma link=log Type1Type3
SCALE=deviance ;
odsoutput parameterEstimates=severity
ModelFit=aic_sev
type1 = type1_sev
type3 = type3_sev;
weight claimcount1 ;
run;
procexport data=frequency
dbms=excel2000 replace
OUTFILE="&path.\1117glm_result_&Vehicle_type..xls ";
sheet=" &line_list.fre_est&part. ";
run;
procexport data=severity
dbms=excel2000 replace
OUTFILE="&path.\1117glm_result_&Vehicle_type..xls ";
sheet=" &line_list.sev_est&part. ";
run;
data frequency(keep=class class1 frequency_opt frequency_low
frequency_high);
set frequency;
format class1 $50.;
format class $50.;
class=parameter;
class1=level1;
frequency_opt=exp(Estimate);
frequency_low=exp(LowerWaldCL);
frequency_high=exp(UpperWaldCL);
drop parameter level1;
if class="Intercept"then class="AA_Intercept";
run;
data severity(keep=class class1 severity_opt severity_low severity_high);
set severity;
format class1 $50.;
format class $50.;
class=parameter;
class1=level1;
severity_opt=exp(Estimate);
severity_low=exp(LowerWaldCL);
severity_high=exp(UpperWaldCL);
drop parameter level1;
if class="Intercept"then class="AA_Intercept";
run;
procsortdata=frequency;
by class class1;
quit;
procsortdata=severity;
by class class1;
quit;