目录
一、 ElasticSearch的定位
二、 什么是倒排索引
三、 什么是全文检索
四、 ElasticSearch的数据存储原理
4.1 ElasticSearch与关系型数据库的数据结构对比
4.2 ElasticSearch的倒排索引原理
一、 ElasticSearch的定位
ElasticSearch是一款开源的分布式 搜索和数据分析引擎,它专门设计用于处理大规模的文本数据和实现高性能的全文检索,业内简称为es。es使用 倒排索引 和 缓存 等技术,在海量数据中能做到快速的搜索和高效的查询。它的设计目标为:一切为了查询。
二、 什么是倒排索引
倒排索引是指将文档记录按照分词与文档对应位置的映射关系进行存储,查询时也将查询条件按规则进行分词,用单个分词去查找文档,即根据文档内容查找文档Id,最后将结果按得分评估汇总返回。
倒排索引的使用分为以下几步:
- 将文档内容按照规则进行分词
- 建立分词与文档Id的映射关系
- 查询时将查询条件进行分词
- 利用分词与文档Id的映射关系,根据查询条件的分词去查找结果
- 根据查询结果中每个分词出现的频率进行排名、汇总,返回结果
三、 什么是全文检索
顾名思义,全文检索是根据查询条件在整个文档中进行搜索,例如百度、谷歌的搜索。在全文检索中,首先需要对文本数据进行处理,包括分词、去除停用词等。然后,对处理后的文本数据建立索引,索引会记录每个单词在文档中的位置信息以及其他相关的元数据,如词频、权重等。这个过程通常使用倒排索引(inverted index)来实现,倒排索引将单词映射到包含该单词的文档列表中,以便快速定位相关文档。当用户发起搜索请求时,搜索引擎会根据用户提供的关键词或短语,在建立好的索引中查找匹配的文档。搜索引擎会根据索引中的信息计算文档的相关性,并按照相关性排序返回搜索结果。用户可以通过不同的搜索策略和过滤条件来精确控制搜索结果的质量和范围。
四、 ElasticSearch的数据存储原理
4.1 ElasticSearch与关系型数据库的数据结构对比
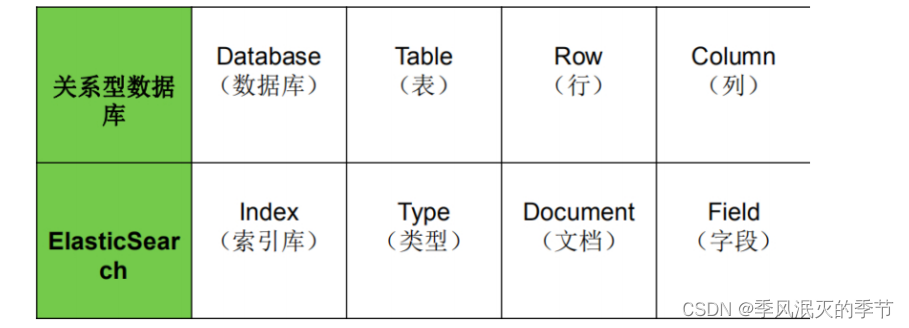
索引:es的最大数据隔离单位称为 索引,类似于关系型数据库的数据库概念。ElasticSearch底层是基于Lucene的封装,每一个索引都是一个Lucene实例。
类型:索引下面的隔离单位称为类型,类似与关系型数据库的”表“。如有一个“人类”的索引,下面类型有“黄种人”、”黑种人“这些类型。在es6以及前的版本中,一个es索引可以有多个类型,在es7中一个索引只能有一个默认的类型"_doc"。到了es8的版本中,已经完全弃用了类型的概念。
文档:文档可以理解为一条条的记录,在同一个索引中,每个文档都有一个唯一的id。
字段: 字段可以理解为关系型数据库中的"列"
4.2 ElasticSearch的倒排索引原理
当数据写入 ES 时,数据将会通过 分词 被切分为不同的 term(词项),ES 将 term 与其对应的文档列表建立一种映射关系,这种结构就是 倒排索引。如下图所示:

为了进一步提升索引的效率,ES 在 term 的基础上利用 term 的前缀或者后缀构建了 term index, 用于对 term 本身进行索引,ES 实际的索引结构如下图所示:

倒排索引中有三个重要部分:
- term index:词项索引,它是树状结构,决定了倒排索引的物理顺序,存的是分词前缀。因为分词后的词项词典很大,无法全部放入内存,因此设计了一个可以放入内存中的树状结构,提升查询性能
- term dictionary: 词项词典,分词器分词后的所有词语,按顺序排列
- posting index: 倒排记录表,里面记录了原始数据表中的记录id,该单词在文档中出现的次数、位置,以及单词开始结束的偏移量
默认情况下,es的每个字段都会生成一个倒排索引。也可以指定某个字段不生成倒排索引,以节省存储空间,以及提升存储性能,但是这个字段就无法被索引查询。






![[论文精读]Few-shot domain-adaptive anomaly detection for cross-site brain images](https://img-blog.csdnimg.cn/direct/6f1a7a7666b0464b81a4ad32f6b2a9a4.png)