电影评论的情感分析
案例背景
很多同学对电影系列的数据都比较喜欢,那我就补充一下这个最经典的文本分类数据集,电影情感评论分析。用神经网络做。对国外的英文评论文本进行分类,看是正面还是负面情感。
数据集介绍
数据集:IMDb网站的电影评论数据集.
这个数据集包含评论文本和标签,标签表示该评论是“正面的”(positive)还是“负面的”(negative).
数据集包括两个独立文件夹,一个是训练数据train, 另一个是测试数据test. 每个文件夹又都有两个子文件夹,一个叫做pos, 另一个叫做neg。pos文件夹包含所有正面的评论, 每条评论都是一个单独的文本文件, neg文件夹与之类似。
说实话,搞这么多文件夹和这么多txt文件看着麻烦,我还是一样,自己清洗和整理后,直接用excel装起来了,如下:

两个excel文件,一个训练集一个测试集,每个里面有25000条评论,其中又分为12500条正面和12500条负面,是一个很平衡的样本。
需要这个数据的全部代码的同学可以参考:电影数据
代码实现
预处理
导入包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'读取数据,合并,展示前五行:
df_train=pd.read_csv('train.csv')
df_test=pd.read_csv('test.csv')
df=pd.concat([df_train,df_test]).reset_index(drop='True')
df.head()
可以看到里面有一些“b”这种二进制留下的解码前缀,我们需要简单处理一下:
import re
def preprocess_text(s):
# 解码字节字符串
if isinstance(s, bytes):
s = s.decode('utf-8')
# 替换转义字符
s = re.sub(r"\\n", " ", s)
s = re.sub(r"\\'", "'", s)
return s.strip().replace("b'",'').replace('b"','')
#应用预处理
df['text'] = df['text'].apply(preprocess_text)
df.head()
查看种类分布:
df['label'].value_counts().plot(kind='bar')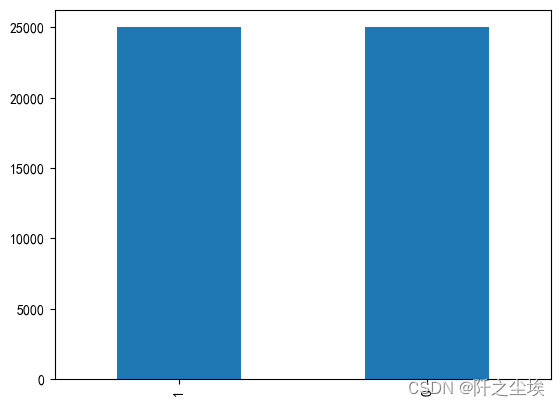
0是负面文本评论,1是正面,可以看到很均衡。
词向量转化
英文词汇自带空格,所以不需要向中文一样的去分词,直接构建词表,然后词向量化:
from os import listdir
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# 将文件分割成单字, 建立词索引字典
tok = Tokenizer(num_words=10000)
tok.fit_on_texts(df['text'].to_numpy())
print("样本数 : ", tok.document_count)
查看词表前10 的词汇:
print({k: tok.word_index[k] for k in list(tok.word_index)[:10]})将其变为数组,然后查看其长度分布:
X= tok.texts_to_sequences(df['text'].to_numpy())
#查看x的长度的分布
v_c=pd.Series([len(i) for i in X]).value_counts()
print(v_c[v_c>150])
v_c[v_c>150].plot(kind='bar',figsize=(12,5))
可以看到大部分评论长度都在120左右,我们选择将X统一到长度为200,多的去掉,少的用0补起来。
# 将序列数据填充成相同长度
X= sequence.pad_sequences(X, maxlen=200)
Y=df['label'].to_numpy()
print("X.shape: ", X.shape)
print("Y.shape: ", Y.shape)
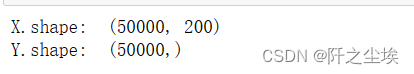
然后我们再将训练集和测试集分开,前面是直接拼接的,那这里我们直接顺序分割就行。
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, shuffle=False)
X_train.shape,X_test.shape,Y_train.shape, Y_test.shape
y进行独立热编码:
Y_test_original=Y_test.copy()
Y_train = to_categorical(Y_train)
Y_test = to_categorical(Y_test)
Y= to_categorical(Y)查看X和y的其中三个:
print(X_train[100:103])
print(Y_test[:3])
Y_test_original[:3]
数据没什么问题,我们可以构建神经网络进行训练了。
构建神经网络
导入包,自定义Transformer层和位置编码层。
from tensorflow.keras import layers
import tensorflow as tf
from tensorflow import keras
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),layers.Dense(embed_dim),] )
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None):
if mask is not None:
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim, })
return config
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(input_dim=sequence_length, output_dim=output_dim)
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
def get_config(self):
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,})
return config导入层,和定义一些参数:
from keras.preprocessing import sequence
from keras.models import Sequential,Model
from keras.layers import Dense,Input, Dropout, Embedding, Flatten,MaxPooling1D,Conv1D,SimpleRNN,LSTM,GRU,Multiply,GlobalMaxPooling1D
from keras.layers import Bidirectional,Activation,BatchNormalization,GlobalAveragePooling1D,MultiHeadAttention
from keras.callbacks import EarlyStopping
from keras.layers.merge import concatenate
np.random.seed(0) # 指定随机数种子
#单词索引的最大个数10000,单句话最大长度200
top_words=10000
max_words=200 #序列长度
embed_dim=128 #嵌入维度
num_labels=2 #2分类构建模型:构建了14种模型
def build_model(top_words=top_words,max_words=max_words,num_labels=num_labels,mode='LSTM',hidden_dim=[64]):
if mode=='RNN':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(SimpleRNN(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='MLP':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))#, mask_zero=True
model.add(Flatten())
model.add(Dropout(0.25))
model.add(Dense(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='LSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='GRU':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(GRU(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN': #一维卷积
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(hidden_dim[0], activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN+LSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(hidden_dim[0]))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='BiLSTM':
model = Sequential()
model.add(Embedding(top_words, input_length=max_words, output_dim=embed_dim))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(hidden_dim[0], activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation='softmax'))
#下面的网络采用Funcional API实现
elif mode=='TextCNN':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
## 词嵌入使用预训练的词向量
layer = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
## 词窗大小分别为3,4,5
cnn1 = Conv1D(32, 3, padding='same', strides = 1, activation='relu')(layer)
cnn1 = MaxPooling1D(pool_size=2)(cnn1)
cnn2 = Conv1D(32, 4, padding='same', strides = 1, activation='relu')(layer)
cnn2 = MaxPooling1D(pool_size=2)(cnn2)
cnn3 = Conv1D(32, 5, padding='same', strides = 1, activation='relu')(layer)
cnn3 = MaxPooling1D(pool_size=2)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
x = Flatten()(cnn)
x = Dense(hidden_dim[0], activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=inputs, outputs=output)
elif mode=='Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = MultiHeadAttention(1, key_dim=embed_dim)(x, x,x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(32, activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='MultiHeadAttention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = MultiHeadAttention(8, key_dim=embed_dim)(x, x,x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.2)(x)
x = Dense(32, activation='relu')(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Attention+BiLSTM':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
x = MultiHeadAttention(2, key_dim=embed_dim)(x, x,x)
x = Bidirectional(LSTM(hidden_dim[0]))(x)
x = Dense(64, activation='relu')(x)
x = Dropout(0.2)(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=inputs, outputs=output)
elif mode=='BiGRU+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim)(inputs)
x = Bidirectional(GRU(32,return_sequences=True))(x)
x = MultiHeadAttention(2, key_dim=embed_dim)(x,x,x)
x = Bidirectional(GRU(32))(x)
x = Dropout(0.2)(x)
output = Dense(num_labels, activation='softmax')(x)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Transformer':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x = Embedding(top_words, input_length=max_words, output_dim=embed_dim, mask_zero=True)(inputs)
x = TransformerEncoder(embed_dim, 32, 4)(x)
x = GlobalMaxPooling1D()(x)
x = Dropout(0.25)(x)
outputs = Dense(num_labels, activation='softmax')(x)
model = Model(inputs, outputs)
elif mode=='PositionalEmbedding+Transformer':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
x= PositionalEmbedding(sequence_length=max_words, input_dim=top_words, output_dim=embed_dim)(inputs)
x = TransformerEncoder(embed_dim, 32, 4)(x)
x = GlobalMaxPooling1D()(x)
x = Dropout(0.5)(x)
outputs = Dense(num_labels, activation='softmax')(x)
model = Model(inputs, outputs)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model这里构建了:“['MLP', 'CNN', 'RNN', 'LSTM', 'GRU', 'CNN+LSTM', 'BiLSTM', 'TextCNN', 'Attention', 'MultiHeadAttention', 'Attention+BiLSTM', 'BiGRU+Attention', 'Transformer', 'PositionalEmbedding+Transformer']” 14种模型,大家还可以任意组合自己想要的模型。
定义评价函数和画损失图函数:
#定义损失和精度的图,和混淆矩阵指标等等
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
def plot_loss(history):
# 显示训练和验证损失图表
plt.subplots(1,2,figsize=(10,3))
plt.subplot(121)
loss = history.history["loss"]
epochs = range(1, len(loss)+1)
val_loss = history.history["val_loss"]
plt.plot(epochs, loss, "bo", label="Training Loss")
plt.plot(epochs, val_loss, "r", label="Validation Loss")
plt.title("Training and Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.subplot(122)
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "b-", label="Training Acc")
plt.plot(epochs, val_acc, "r--", label="Validation Acc")
plt.title("Training and Validation Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
def plot_confusion_matrix(model,X_test,Y_test_original):
#预测概率
prob=model.predict(X_test)
#预测类别
pred=np.argmax(prob,axis=1)
#数据透视表,混淆矩阵
pred=pd.Series(pred)
Y_test_original=pd.Series(Y_test_original)
table = pd.crosstab(Y_test_original, pred, rownames=['Actual'], colnames=['Predicted'])
#print(table)
sns.heatmap(table,cmap='Blues',fmt='.20g', annot=True)
plt.tight_layout()
plt.show()
#计算混淆矩阵的各项指标
print(classification_report(Y_test_original, pred))
#科恩Kappa指标
print('科恩Kappa'+str(cohen_kappa_score(Y_test_original, pred)))
def evaluation(y_test, y_predict):
accuracy=classification_report(y_test, y_predict,output_dict=True)['accuracy']
s=classification_report(y_test, y_predict,output_dict=True)['weighted avg']
precision=s['precision']
recall=s['recall']
f1_score=s['f1-score']
#kappa=cohen_kappa_score(y_test, y_predict)
return accuracy,precision,recall,f1_score #, kappa定义训练函数
#定义训练函数
df_eval=pd.DataFrame(columns=['Accuracy','Precision','Recall','F1_score'])
def train_fuc(max_words=max_words,mode='BiLSTM+Attention',batch_size=64,epochs=10,hidden_dim=[64],show_loss=True,show_confusion_matrix=True):
#构建模型
model=build_model(max_words=max_words,mode=mode,hidden_dim=hidden_dim)
print(model.summary())
es = EarlyStopping(patience=3)
history=model.fit(X_train, Y_train,batch_size=batch_size,epochs=epochs,validation_split=0.1, verbose=1,callbacks=[es])
print('——————————-----------------——训练完毕—————-----------------------------———————')
# 评估模型
#loss, accuracy = model.evaluate(X_test, Y_test) ; print("测试数据集的准确度 = {:.4f}".format(accuracy))
prob=model.predict(X_test) ; pred=np.argmax(prob,axis=1)
score=list(evaluation(Y_test_original, pred))
df_eval.loc[mode,:]=score
if show_loss:
plot_loss(history)
if show_confusion_matrix:
plot_confusion_matrix(model=model,X_test=X_test,Y_test_original=Y_test_original)我首先命名了一个df_eval的数据框,用来存放模型预测的效果的评价指标。我们采用准确率,精确值,召回率,F1值四个分类问题常用的指标来进行评价。
我这个训练函数里面包括了很多东西,可以打印模型的信息,然后展示模型的训练,对模型训练过程的训练集和验证集的损失变化都画了图,然后对于预测结果的混淆矩阵和其热力图都进行了展示,还储存了评价指标。
初始化参数
top_words=10000
max_words=200
batch_size=64
epochs=10
hidden_dim=[64]
show_confusion_matrix=True
show_loss=True上面构建这么多函数,是方便下面进行训练的,下面的训练代码就很简单了,一行代码就全有。
train_fuc(mode='MLP',batch_size=batch_size,epochs=epochs)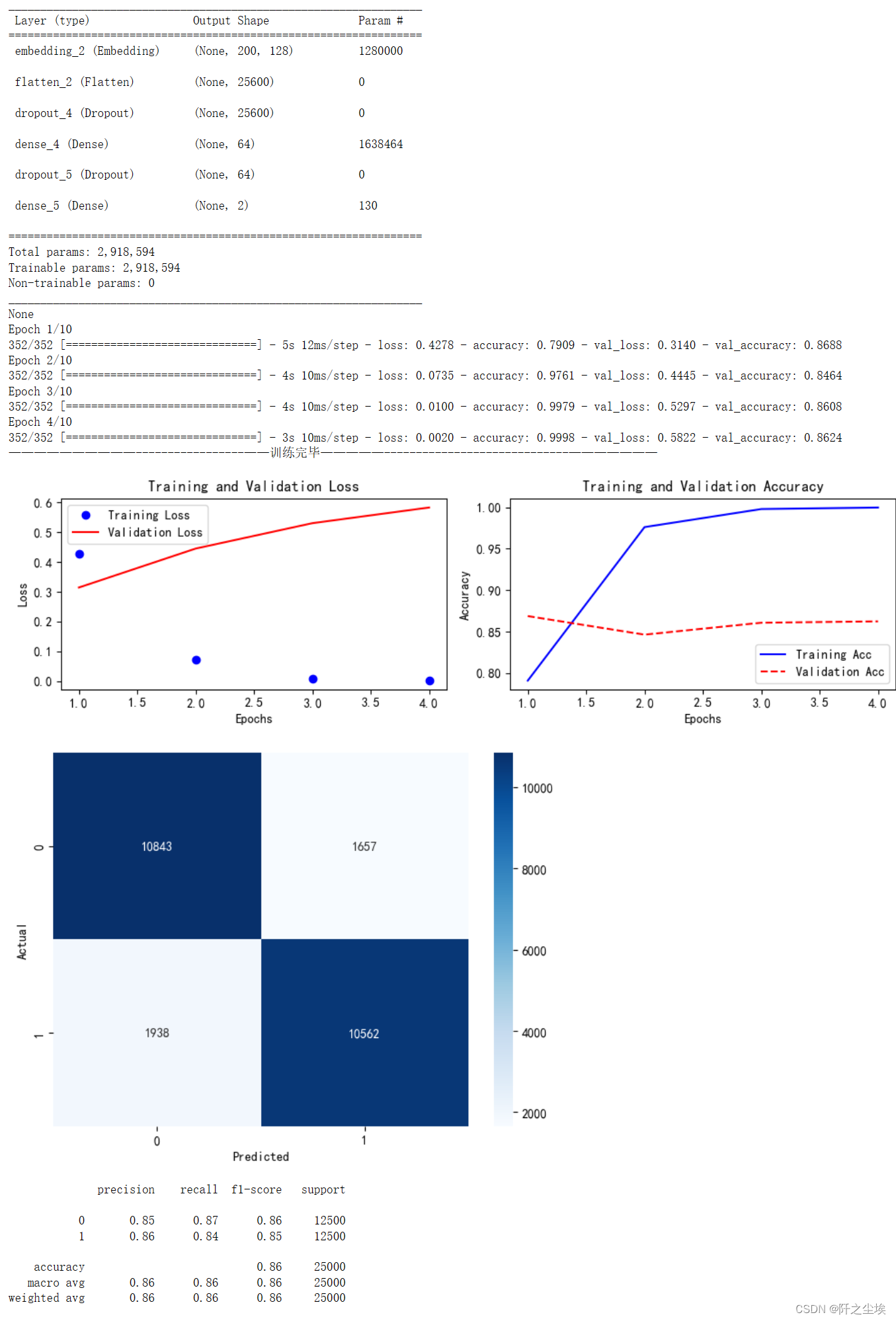
训练其他模型只需要改mode参数就行
train_fuc(mode='CNN',batch_size=batch_size,epochs=epochs)
这里太多了,就不一一展示了,直接一起训练,然后看看所有模型的效果对比:
train_fuc(mode='RNN',batch_size=batch_size,epochs=8)
train_fuc(mode='LSTM',epochs=epochs)
train_fuc(mode='GRU',epochs=epochs)
train_fuc(mode='CNN+LSTM',epochs=epochs)
train_fuc(mode='BiLSTM',epochs=epochs)
train_fuc(mode='TextCNN',epochs=3)
train_fuc(mode='Attention',epochs=4)
train_fuc(mode='MultiHeadAttention',epochs=3)
train_fuc(mode='Attention+BiLSTM',epochs=8)
train_fuc(mode='BiGRU+Attention',epochs=4)
train_fuc(mode='Transformer',epochs=3)
train_fuc(mode='PositionalEmbedding+Transformer',batch_size=batch_size,epochs=3)模型评价
df_eval.assign(s=df_eval.sum(axis=1))#['s'].idxmax()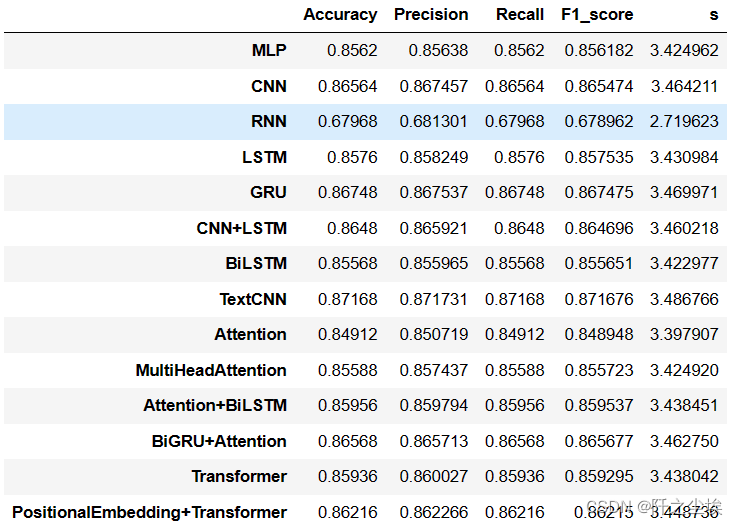
可以看到这个数据集上,TextCNN模型效果较为优良。
- 多层感知机 (MLP) 的表现在所有指标上都是相对均衡的。
- 卷积神经网络 (CNN) 在精确度和F1分数上稍微高于其他指标。
- 递归神经网络 (RNN) 在所有指标上的表现都不是很好,尤其是在准确度和召回率上。
- 长短期记忆网络 (LSTM) 在准确度和F1分数上表现良好。
- 门控循环单元 (GRU) 在所有指标上的表现都很均衡,是性能较好的模型之一。
- CNN+LSTM 组合模型在准确度和F1分数上表现较好。
- 双向LSTM (BiLSTM) 的表现和单向的LSTM类似,但是在所有指标上略有下降。
- TextCNN 在精确度和F1分数上表现出色,说明它在分类正确的同时也保持了较高的相关性。
- Attention 机制的加入提供了相对较高的精确度,但在其他指标上的提升不是很显著。
- MultiHeadAttention 相比单一的Attention机制在准确度和召回率上略有下降。
- Attention+BiLSTM 的组合模型在所有指标上均有较好的表现,尤其是在F1分数上,这表明它在精确度和召回率之间取得了很好的平衡。
- BiGRU+Attention 在所有指标上也显示出良好的性能,尤其是在准确度和F1分数上,这表明它有效地结合了GRU的时序处理能力和Attention机制的聚焦能力。
- Transformer 模型在所有指标上都有不错的表现,尤其是在F1分数上,表明它在精确度和召回率之间取得了良好的平衡。
- PositionalEmbedding+Transformer 在所有指标上有较好的表现,这可能表明它在捕捉长距离依赖和上下文信息方面非常有效。
画出对应的柱状图:
bar_width = 0.4
colors=['c', 'b', 'g', 'tomato', 'm', 'y', 'lime', 'k','orange','pink','grey','tan','gold','r']
fig, ax = plt.subplots(2,2,figsize=(10,8),dpi=128)
for i,col in enumerate(df_eval.columns):
n=int(str('22')+str(i+1))
plt.subplot(n)
df_col=df_eval[col]
m =np.arange(len(df_col))
plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)
#plt.xlabel('Methods',fontsize=12)
names=df_col.index
plt.xticks(range(len(df_col)),names,fontsize=10)
plt.xticks(rotation=40)
plt.ylabel(col,fontsize=14)
plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()
其实模型们都差不了太多,大概都在85%左右,就RNN离谱一些。。。
模型预测
我们单独拿Transformer模型进行训练,我们选择使用它,单独拿出来在所有的数据集上进行训练,然后对新来的新闻进行预测看看效果。然后去预测新文本。
model=build_model(max_words=max_words,mode='PositionalEmbedding+Transformer',hidden_dim=hidden_dim)
history=model.fit(X,Y,batch_size=batch_size,epochs=3,verbose=0)再来一个新的电影评论的文本,怎么预测呢?
new_txt='''This latest movie is a cinematic masterpiece! It brilliantly blends stunning visuals with a captivating storyline.
The performances are exceptional, capturing the essence of each character beautifully.
It's a rare film that not only entertains but also provokes deep thought and emotional engagement.
A must-see for movie lovers!'''这么多感叹号和love,一看就是正面情感。。
我们来试试,要先转化为和前面一样的向量。
自定义一个类别处理函数
def predict_newkind(new_txt,token=tok):
dic={0: '负面', 1: '正面'}
new_text_seq = tok.texts_to_sequences([new_txt])
new_text_seq_padded = sequence.pad_sequences(new_text_seq, maxlen=200)
predictions = model.predict(new_text_seq_padded)
predicted_class = np.argmax(predictions, axis=1)
return dic[predicted_class[0]]预测看看
predict_newkind(new_txt)
没问题,很准确!
再来个负面评论 看看:
new_txt='''Unfortunately, this recent film falls short of expectations. Despite a promising premise, the plot is poorly executed and lacks
depth. The performances feel forced and fail to connect with the audience. Additionally, the over-reliance on special effects over substance
makes it a forgettable experience. It's a disappointing entry in what could have been an exciting film series.
'''predict_newkind(new_txt)
不错!
模型储存
可以把构建的模型和词表进行保存,下次就不用再训练了,可以直接用。
import pickle
from tensorflow.keras.models import save_model
# 保存Tokenizer
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
model.save('my_model.h5') # 保存模型到HDF5文件下次要用的话,直接载入:
from tensorflow.keras.models import load_model
import pickle
with open('tokenizer.pickle', 'rb') as handle:
tok = pickle.load(handle)
model = load_model('my_model.h5', custom_objects={'PositionalEmbedding': PositionalEmbedding,'TransformerEncoder':TransformerEncoder})大家还可以用自己的想法构建更多的模型,说不定可以得到更好的准确率。
我本人也测试过 KNN, 决策树,逻辑回归这种传统机器学习学的方法,效果比神经网络差多了....而且训练时间也长很多。
当然,这是英文的案例,不用分词什么的,想做中文的评论情感分类就可以参考我上一篇文章:新闻文本主题多分类
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制代码可私信)