文章目录
- 一、前言
- 二、深入了解存算一体技术
- 2.1 什么是存算一体
- 2.2 存算一体技术发展历程
- 2.3 基于不同存储介质的存内计算芯片性能比较
- 三、国产存算一体,重大进展
- 3.1 知存科技:我国存算一体领域的研发领导者
- 四、知存科技新型 WTM2101 SOC 评估板使用评测
- 4.1 WTMDK2101-ZT1 实验评测目标概述
- 4.2 WTMDK2101-ZT1 评估板介绍与安装
- 4.2.1 WTMDK2101-ZT1 评估板介绍
- 4.2.2 评估板组件安装
- 4.3 评估板调试
- 4.4 啸叫音识别测试
- 4.5 啸叫音抑制测试
- 五、文末总结
一、前言
随着当今数据迅速增长,传统的冯诺依曼架构内存墙正在成为计算性能进一步提升的阻碍。新一代的存内计算(IMC)和近存计算(NMC)架构有望突破这一瓶颈,显著提升计算能力和能源效率。本文将探讨存算一体芯片的发展历程、当前研究状态,以及基于多种存储介质(例如传统的DRAM、SRAM和Flash,以及新型的非易失性存储器如ReRAM、PCM、MRAM、FeFET等)的存内计算基本原理、优势与面临的挑战。通过对知存科技WTM2101量产芯片的深入解析与评测,重点展示存内计算芯片的电路结构及其应用现状。最后,将对存算一体芯片未来的发展前景和挑战进行详细分析。
二、深入了解存算一体技术
2.1 什么是存算一体
存算一体是指在计算机体系结构中将存储和计算功能整合到一起的概念。这种结合旨在减少数据在处理器和存储单元之间的频繁传输,从而提高数据处理速度和效率。
存算一体的两个主要形式是近存计算和存内计算:
- 近存计算:在近存计算中,计算单元与高速存储单元(如高速缓存)紧密集成。这意味着处理器和高速存储单元之间的距离很近,可以快速访问数据并进行计算,减少了数据从内存传输到处理器的时间。
- 存内计算:存内计算是将计算功能直接放置在存储单元内部的概念。这意味着存储单元本身具有一定的计算能力,可以在存储位置进行部分计算任务,避免了数据在存储和处理单元之间的频繁移动。存内计算的核心理念是在存储单元内部完成部分计算任务,避免频繁的数据传输,从而提高效率。这种方式允许处理器直接访问存储单元,将计算任务和数据处理在存储内部进行,而不是在传统的分离存储和处理的架构中进行。通过存内计算,数据不必在存储和处理单元之间频繁传输,减少了数据移动的时间和能耗。这种方式对于处理大规模数据和计算密集型任务特别有利,能够提高计算效率和响应速度。在人工智能、机器学习等领域,存内计算技术能够加速模型训练和推理过程。研究一些资料后博主自己总结:存内计算技术的发展对于提高计算设备的整体性能、降低能耗并改善数据处理效率具有重要意义。值得一提的是,我国知存科技推出的 WTM2101 芯片即采用存内计算这种方式。
近存计算和存内计算都是存算一体架构的重要组成部分,目的是在硬件层面上优化数据处理流程,使得计算机系统能够更快速、更有效地处理大规模数据和计算密集型任务。这些技术的发展对于越发火热的人工智能、大数据处理等领域的发展具有重要意义。
2.2 存算一体技术发展历程
个人查阅了相关的很多资料,大致总结出来下面的存算一体技术发展历程,方便我们更加深入的了解存算一体技术的发展
1969年: 存算一体的概念最早提出。
1997年: 展示了智能内存(Intelligent RAM)方案,将处理器和DRAM集成在单颗芯片上,算力达到Cray T-90的5倍。
1999年: 提出了灵活内存(FlexRAM)方案,仿真结果表明该芯片架构可使计算性能提升25~40倍。但由于缺少大数据处理需求、昂贵的制造成本和复杂的设计,技术仍然停留在研究阶段。
2015年以后: 随着摩尔定律逐渐失效和冯诺依曼架构的局限性明显,大数据应用的驱动,工艺水平不断提高,存算一体技术重新受到关注。
2016年,郭昕婕博士(知存科技联合创始人及首席科学家)终于研发出全球第一个3层神经网络的浮栅存内计算深度学习芯片(PRIME架构),首次验证了基于浮栅晶体管的存内计算在深度学习应用中的效用。相较于传统冯诺伊曼架构的传统方案,PRIME可以实现功耗降低约20倍、速度提升约50倍,引起产业界广泛关注。随着人工智能等大数据应用的兴起,存算一体技术得到国内外学术界与产业界的广泛研究与应用。
2017年: 微处理器顶级年会(Micro2017)上,多所高校和企业推出了存算一体芯片或系统原型,包括苏黎世联邦理工学院、加利福尼亚大学圣巴巴拉分校、英伟达、英特尔、微软、三星等。当提及圣巴巴拉分校时,值得关注的是他们在基于 RRAM 的存内计算领域的突破。这种新型存储技术具有高密度、低功耗和快速读写等优势,非常适合存内计算需求。研究团队专注于将RRAM与计算过程结合,实现内部存储和计算的融合。这项技术有望提高人工智能和其他计算密集型应用的效率,通过在芯片内部集成存储和计算功能,加速数据处理速度、降低能耗,并提供更快速、更灵活的计算解决方案。他们的研究成果可能为未来计算设备和系统带来革命性变革,使其更加智能、高效和可靠。
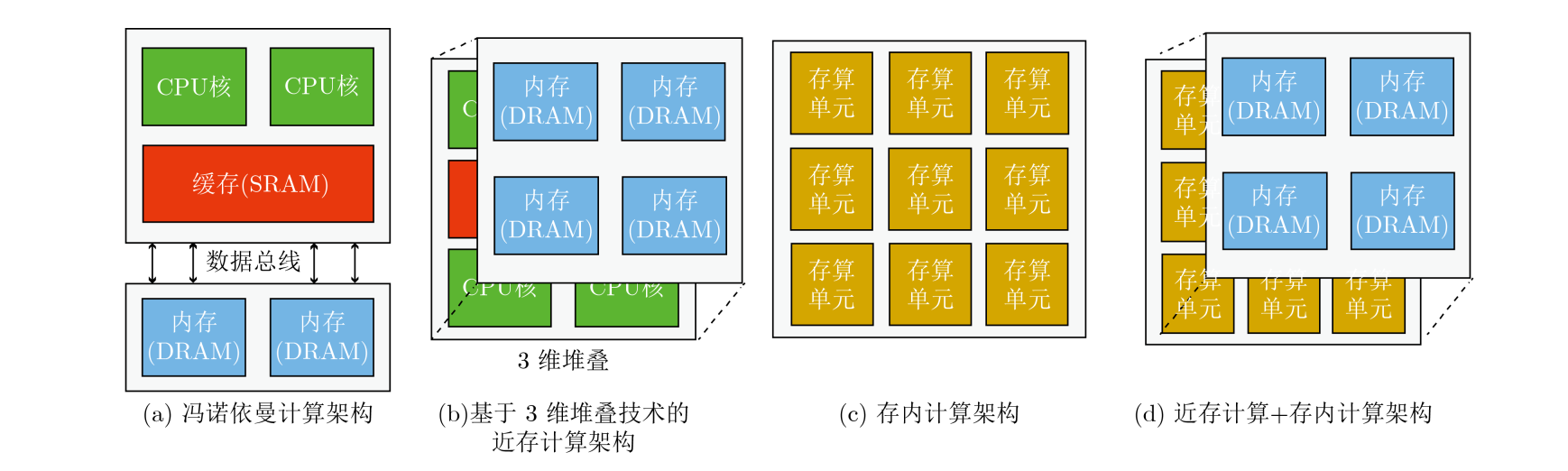
这些年里,基于不同存储介质的存算一体芯片研究不断涌现,包括 SRAM、DRAM、Flash、ReRAM、PCM、FeFET、MRAM 等各类存储介质。国内外企业积极研发,其中台积电、Mythic 和知存科技最接近产业化,已经推出了一系列基于不同存储介质的存算一体芯片研究成果。
与此同时,全球首个存内计算社区创立,涵盖最丰富的存内计算内容,以存内计算技术为核心,绝无仅有存内技术开源内容,囊括云/边/端侧商业化应用解析以及新技术趋势洞察等, 邀请业内大咖定期举办线下存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。传送门:https://bbs.csdn.net/forums/computinginmemory?category=10003;
社区最新活动存内计算大使招募中,享受社区资源倾斜,打造属于你的个人品牌,点击下方一键加入。
https://bbs.csdn.net/topics/617915760

2.3 基于不同存储介质的存内计算芯片性能比较
目前,用于存算一体的成熟存储器类型包括 NOR FLASH、SRAM、DRAM、RRAM 和 MRAM 等 NVRAM。
广泛使用的 FLASH 是一种非易失性存储介质,具有低成本和高可靠性的优势,但其工艺制程方面存在明显的瓶颈。
SRAM 在速度和能效方面具有优势,尤其在存内逻辑技术发展之后,展现出了高能效和高精度的特点。
DRAM 具有低成本和大容量的优点,但速度较慢,并且需要持续供电进行刷新。
新型适用于存算一体的存储器类型包括 PCAM、MRAM、RRAM 和 FRAM 等。其中,忆阻器 RRAM 在神经网络计算中具有特殊优势,被视为除了 SRAM 存算一体之外的下一代主流研究方向。尽管 RRAM 目前仍需 2-5 年的工艺成熟期,而且材料稳定性尚不确定,但其高速和简单结构的特点,使其有望成为未来发展速度最快的新型存储器。
从工业界的研发趋势来看,SRAM 和 RRAM 均被认为是未来主流存算一体的存储介质,下面基于不同存储介质的存内计算芯片性能进行一个比较,方便大家更加了解内存芯片的性能。
| 标准 | SRAM | DRAM | Flash | ReRAM | PCM | FeFET | MRAM |
|---|---|---|---|---|---|---|---|
| 非易失性 | 否 | 否 | 是 | 是 | 是 | 是 | 是 |
| 多比特存储能力 | 否 | 否 | 是 | 是 | 是 | 是 | 否 |
| 面积效率 | 低 | 一般 | 高 | 高 | 高 | 高 | 高 |
| 功耗效率 | 低 | 低 | 高 | 高 | 高 | 高 | 高 |
| 工艺微缩性 | 好 | 好 | 较差 | 好 | 较好 | 好 | 好 |
| 成本 | 高 | 较高 | 低 | 低 | 较低 | 低 | 低 |
三、国产存算一体,重大进展
国产存算一体技术的重大进展已在新一轮算力攻坚赛中得到彰显。存算一体架构的突破传统冯·诺依曼架构的范式探索成为重要趋势。这种架构改变了存算分离的局面,类似于“在家办公”一样,消除了数据“往返通勤”的能量消耗和时间延迟,大大提高了AI算力的能效比。近期,清华大学团队研制的全球首款支持高效片上学习的忆阻器存算一体芯片引发关注。这一突破展示了存算一体技术的能效潜力和算力潜力,并为本地数据处理和动态更新带来可能,减少了对云端算力和网络带宽的依赖。
在存算一体领域,全球参与者可分为国际巨头和新兴企业两大阵营。国际巨头如英特尔、IBM、特斯拉等早已布局存算技术,并推出代表未来趋势的产品。而新兴企业则更灵活选择存内计算路线,如国内的知存科技、九天睿芯等,希望实现更高性能、更通用的算力场景。
这些公司在三个主要差异上有所体现:
技术路径: 近存计算和存内计算是两种主要路径。前者保留了经典冯·诺依曼架构的数据处理特点,而后者通过存储器件参与计算操作,实现存算真正融合。
存储介质: 不同存储介质如SRAM、DRAM等各有优缺点,影响着算力的性能和成本。目前,多数公司选择成熟的SRAM以及Flash设计存算一体芯片,但也在投入新兴存储介质的研发,如MRAM、RRAM等,以期获得更大竞争优势。
数字或模拟: 存算一体的计算可分为数字存算和模拟存算。数字存算更灵活适用于通用性场景,而模拟存算在能量效率方面具有优势,但其扩展性相对不足;模拟存算的优势在于其能够更有效地处理大规模、复杂的问题,尤其是涉及到实时数据处理和复杂模型的情况。相比传统的计算方式,模拟存算能够更快速地进行计算并解决问题,因为它模拟了物理系统的行为,能够并行处理数据和任务。知存科技采用模拟存算的方法可能意味着他们更有可能处理复杂的任务并加快问题解决的速度。这种方法可能在处理大规模数据、复杂模型和实时计算方面有很大的优势。值得一提的是,我们国内知存科技目前用的是模拟存算。
这些技术突破正迎合市场需求,使存算一体技术迎来了产业化的拐点。新兴企业在探索新技术应用和大算力布局方面更具前瞻性。随着技术和应用的不断成熟,这些企业势必在存算一体领域发挥重要作用。
3.1 知存科技:我国存算一体领域的研发领导者
存算一体技术作为解决冯诺依曼架构下存储墙问题的重要方案,吸引了国内外众多企业的研发投入,其中知存科技成为这一领域的引领者之一。
在全球范围内,存算一体技术的研究和实践正由传统芯片巨头如三星电子、SK海力士、台积电、美光、IBM、英特尔等主导。SK海力士也展示了其基于GDDR的存内计算产品,大幅提高了计算速度并降低了功耗。其他如台积电、美光、IBM、英特尔等也都在存内计算领域取得了积极进展,探索将存储与计算紧密结合的创新方案。
在国内,新兴AI和存储企业的蓬勃发展也为存算一体技术注入了新的活力。知存科技作为其中一员,在存内计算芯片的研发和推广方面处于领先地位。他们的WTM2101基于nor flash存储介质,40nm的制程实现了超低功耗以及高算力。特别适用于智能语音和智能健康等领域。该公司不仅在技术上取得了突破,2023年1月还获得了2亿元的B2轮融资,显示了市场对其发展的认可和期待。
知存科技的成就不仅在于技术上的创新,更在于其成功将存算一体技术落地并投入量产。这种领先地位使得知存科技成为国内存算一体领域的重要代表之一,为未来的技术发展和产业进步贡献着不可或缺的力量。
国产存算一体进展统计(收集自企业官网、新闻报道等公开信息,仅供参考)
| 序号 | 企业 | 存储器介质 | 产品型号 | 量产进程 | 应用场景 | 融资 |
|---|---|---|---|---|---|---|
| 1 | 知存科技 | Flash | WTM-2系列 WTM-8系列 | WTM2101已量产商用;WTM-8系列已完成投片 | 智能语音、智能健康、高性能图像、空间计算等 | B2轮 |
| 2 | 后摩智能 | SRAM/RRAM | 鸿途™H30 | 2021年8月完成首款芯片验证流片 | 智能驾驶、泛机器人、边缘端等 | Pre-A+轮 |
| 3 | 苹芯科技 | SRAM | S200 | 已完成流片,处于外部测试阶段 | 可穿戴设备、无人机、摄像头、安防领域 | Pre-A轮 |
| 4 | 亿铸科技 | ReRAM | 未公布 | 未公布 | 数据中心和自动驾驶 | 天使轮 |
| 5 | 智芯科 | SRAM | AT680X | 已量产,2021年9月推向市场 | 针对超低功耗智能语音AIOT市场 | 天使轮 |
| 6 | 千芯科技 | SRAM | 未公布 | 产品己完成样机验证,处于小批量验证优化阶段 | 云计算、自动驾驶、智能安防等 | 已完成数千万人民币融资 |
| 7 | 九天睿芯 | 未知 | ADA100、ADA200 | ADA 100己量产 | 应用于AIoT等对低功耗延时需求强烈的领域 | A轮 |
| 8 | 恒烁半导体 | NOR Flash | CiNOR V1、CiNOR V2 | 流片成功,完成系统演示; CiNOR V2,在研发中 | 物联网领域 | 上市公司 |
四、知存科技新型 WTM2101 SOC 评估板使用评测
非常有幸能够体验使用知存科技 WTM2101 SOC 评估板 WTMDK2101-ZT1,下面我会对该评估板进行详细的评测。
4.1 WTMDK2101-ZT1 实验评测目标概述
我们主要是使用WTMDK2101-ZT1 评估板,在准备安装好后,我们会在测试环境模拟正常人说话声音大小的声音(2_0-30分贝_)连接耳机完成后,会出现高分贝的杂音啸叫(30分贝左右);当板子被启用后,这些杂音立即消失(时间延迟<1ms),这展示了ZT1开发板成功抑制啸叫的效果。
4.2 WTMDK2101-ZT1 评估板介绍与安装
4.2.1 WTMDK2101-ZT1 评估板介绍
收到评估板后,马上开箱打开,我们可以看下图来仔细看一下 WTMDK2101-ZT1 评估板实物:

可以看到中心区域就是我们的 WTM2101 芯片,在两测分别有 IO 接口,其中右侧包括:两个 Flash,一个 I2S接口和 J Tag 接口,还有一个音频模块的耳机接口;在测试板的下方的 IO 接口中包括 3个按键,两排 LED,一级一组主控芯片接口。
我们接下来的实验中就会用到音频模块的耳机接口。
为了方便我们了解开发板构造,我们可以详细参看下面的开发板系统框图:
4.2.2 评估板组件安装
这里测试的 WTMDK2101-ZT1 评估板有3个组件
- 含有 WTMDK2101 芯片的主测试版
- 啸叫测试耳机
- 测试子板(用于测试版烧录时使用)
测试主板图以及接口说明参照如下:

测试耳机,可以按照上图标注部分进行连接耳机。

测试子板,可以看到我们测试子板有六根连接线,并且不同线有其不同标注,如果需要链接测试主板,需要依据线类型进行链接。

4.3 评估板调试
我们依次将评估板耳机与子板链接到测试主板,并且接通USB电源到 Windows操作系统的电脑中。这里可以注意,我们使用的是USB接入电源连接在电脑中,你也可以是用其他的电源接入即可。

如下图所示,将拔码开关打开到USB一侧,代表使用USB连接供电,当然如果我们直接使用电池供电,则需要将拔码开关拨到右侧。当我们成功供电后,会看到LED3的灯已经亮起。

4.4 啸叫音识别测试
我们先进行第一个测试,使用开发板来识别啸叫音
我们在模拟测试环境后,在播放音乐进行耳机监听测试的时候,耳机会传出声音迅速被放大的识别后杂音被抑制,这个时间非常短暂。
首先是我们模拟环境,我们找到了同事的电脑,直接播放一个大约和人声分贝大小的一段音乐,之后我们的麦克风进行识别,这样的时候我们的开发板回对啸叫音进行识别。
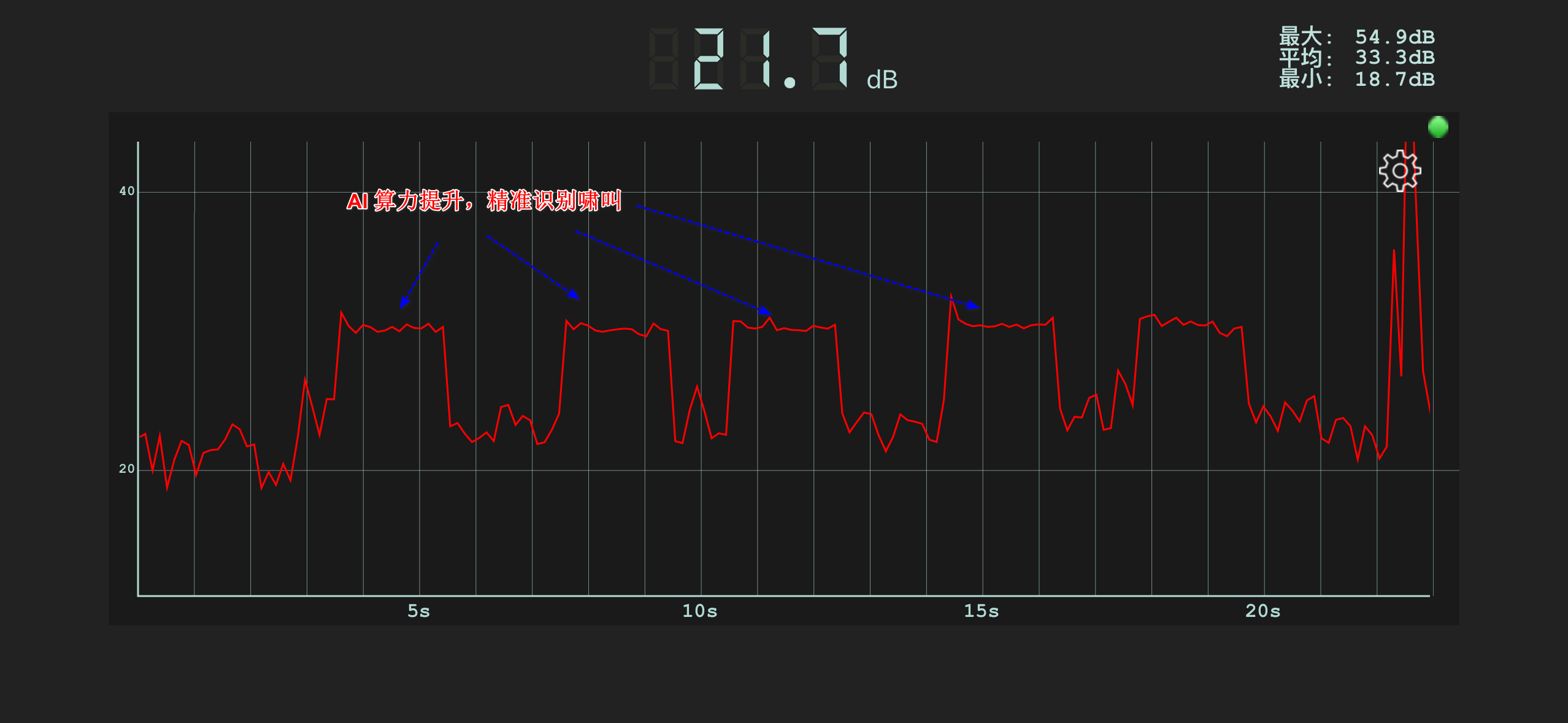
当我们播放音乐后,使用音频频谱检测软件进行监听啸叫的声音一段时间,经过测试后从下面测试图中可以明显看到,当出现啸叫音的时候,我们的开发主板能够精准的检测出来。这个测试给我个人的感受是知存科技的 WTMDK2101的强大之处是精准识别出啸叫,并且能够无声处理,精准度非常高且速度快。
4.5 啸叫音抑制测试
接下来我们验证啸音抑制功能,不知道你是否有在 KTV 唱歌或者参加会议拿着话筒讲话的经历,如果有的话,你一定会遇到过你讲话的时候突然出现了啸音,那种特别鸣的声音,下面我们使用WTMDK2101-ZT1 评估板来测试一下知存科技产品的啸音抑制功能。
我们首先在一台电脑中准备好知存科技助听控制台程序,该程序可以打开或者关闭降噪(NR)功能,这样方便我们进行对比。
首先我们准备啸音进行检测,我们的做法是先将助听器测试控制台的算法开关处于关闭状态。
调整好,来检测耳机中的测试音,显示的图谱如图所示:
因为测试环境的原因,中间可能有部分的干扰音,如果小伙伴们进行测试的时候建议清晨或者晚上比较安静的地方进行测试。
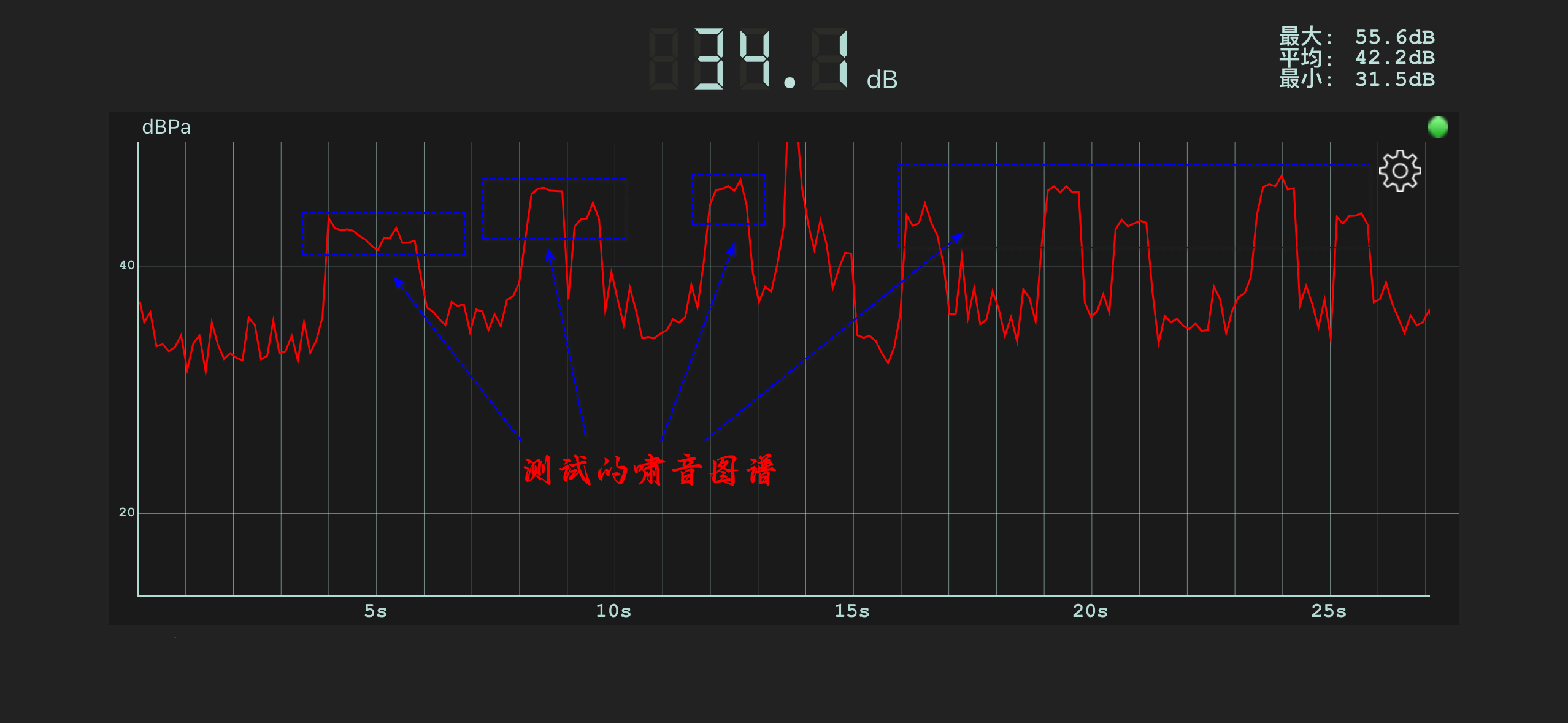
之后我们将开发板的算法开关相应的开关打开,之后在进行监听耳机音频,并输出音频图谱。
注意:其中的 NR 开关就包括了抑制啸音的算法功能。
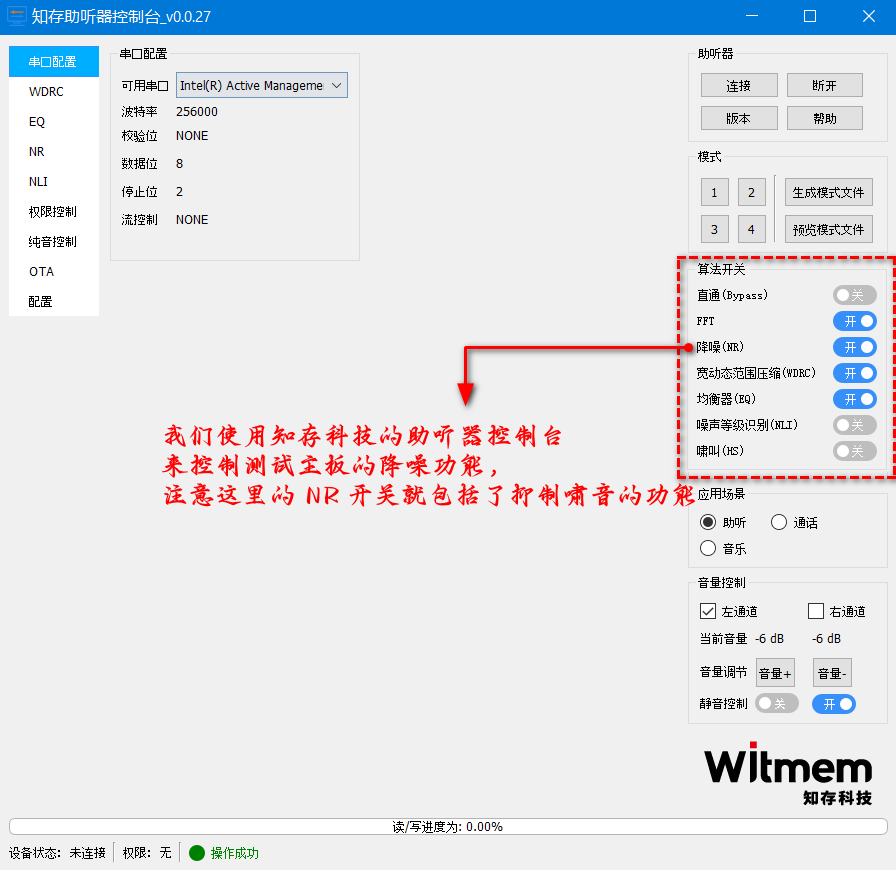
开发板开启啸音抑制功能后的音频图谱。
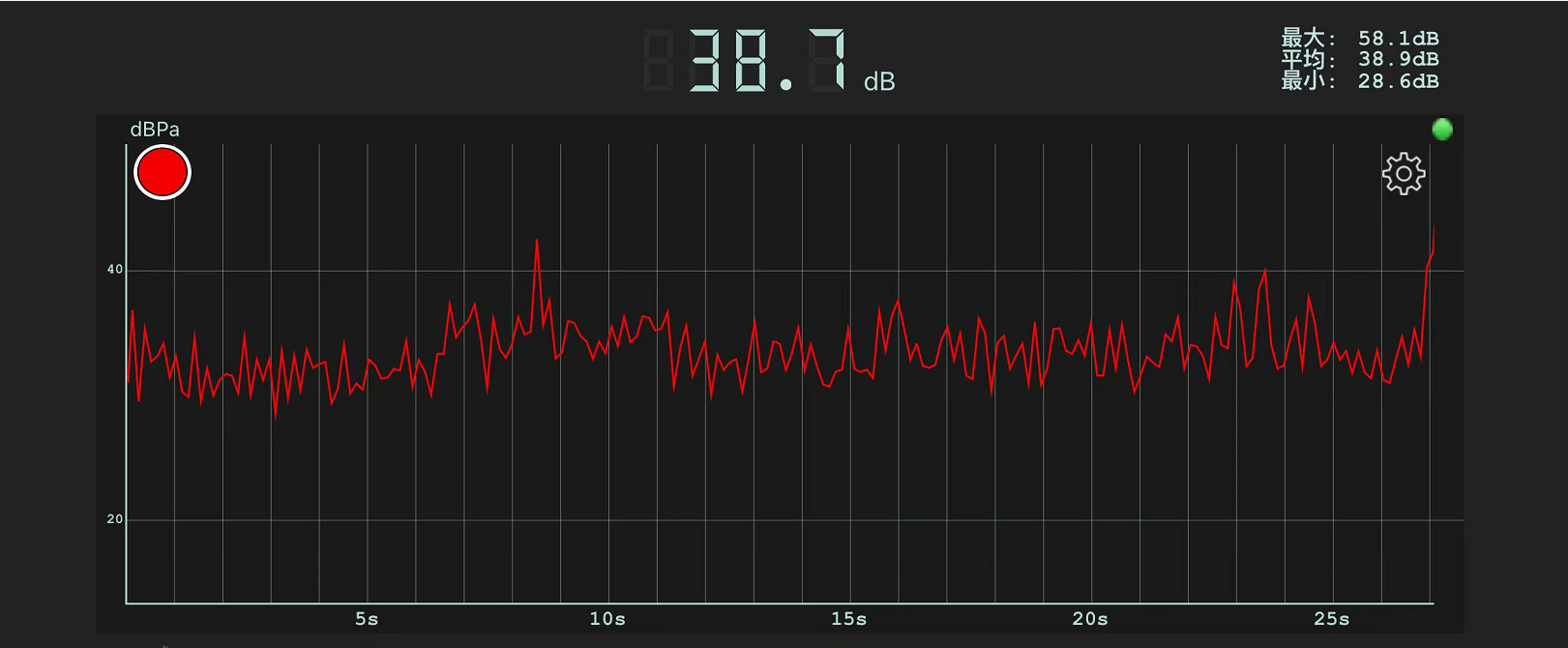
从我们前后啸音抑制后的图谱对比中可以看出,在开启降噪(啸音抑制)功能前,从图谱中可以看到啸音明显,并且其平均的声音分贝是:42.2分贝;当我们开启开发板的啸音抑制功能后,啸音得到明显的抑制,并且平均分贝为:38.9分贝。可以分析得出知存科技的对啸音抑制功能非常显著。
五、文末总结
我回顾调查资料以及动手进行实验的过程中,深刻的感受到存内计算对数据处理的强大,也期待下次可以加入知存的线下实操训练营,更深度的体验存内计算技术。知存科技的成就代表着存算一体技术迈向产业化的重要一步。然而,技术和市场仍需面对挑战,需要更多创新和探索。整体来看,存算一体技术发展前景广阔,但仍需持续关注并推动其朝着更高效、智能的方向发展。




![[linux]同步缓冲区数据到flash](https://img-blog.csdnimg.cn/direct/7e21dd9af1a049d5b288152ed0041fd0.png)